/SKILL.md` + its assets.\r\n3. **Schema layer** — a single `AGENT.md` (or `CLAUDE.md`), holding only routing + contract, zero domain knowledge.\r\n\r\nWrites are mutually exclusive: Execute is read-only on skills; only Distill writes skills; only Guide writes the schema. Plus a Hook protocol with a default `should-distill` that every task must evaluate before finishing — so the loop doesn't rely on the agent \"remembering\" to close it.\r\n\r\nThe whole thing is designed to drop into any agent framework as a skill plugin (or even sit in the system prompt); the LLM decides when to invoke it, and action-capability iterates on its own.\r\n\r\nWould love your thoughts if this resonates.\r\n\r\n \r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130180",
"id": 6130180,
"node_id": "GC_lADOAFM_9doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdigQ",
"user": {
"login": "a-a-k",
"id": 5455861,
"node_id": "MDQ6VXNlcjU0NTU4NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/5455861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/a-a-k",
"html_url": "https://github.com/a-a-k",
"followers_url": "https://api.github.com/users/a-a-k/followers",
"following_url": "https://api.github.com/users/a-a-k/following{/other_user}",
"gists_url": "https://api.github.com/users/a-a-k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/a-a-k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/a-a-k/subscriptions",
"organizations_url": "https://api.github.com/users/a-a-k/orgs",
"repos_url": "https://api.github.com/users/a-a-k/repos",
"events_url": "https://api.github.com/users/a-a-k/events{/privacy}",
"received_events_url": "https://api.github.com/users/a-a-k/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T10:19:51Z",
"updated_at": "2026-05-02T10:19:51Z",
"body": "This is a nice personal workflow, but the hype is way ahead of the evidence.\r\n\r\nThere is no benchmark, no task definition, no scale curve, and no comparison against serious baselines. We do not know whether this is better than hybrid RAG, BM25 plus reranking, vector search, GraphRAG, hierarchical summaries, long-context prompting, NotebookLM, Perplexity Spaces, or ChatGPT Projects. Calling it a new architecture without that evidence is premature.\r\n\r\nThe core problem is that an LLM Wiki is lossy compression. You take raw documents and rewrite them into derived wiki pages. That may be useful for a small curated corpus, but it can also drop caveats, dates, minority views, exact wording, edge cases, and source context. Once people start querying the wiki instead of the original material, summary errors become part of the knowledge base.\r\n\r\nUpdates are also not solved. Adding one new source can affect many entity pages, concept pages, timelines, summaries, and indexes. At scale, this becomes graph maintenance: detecting what changed, resolving conflicts, avoiding duplicates, preserving provenance, preventing stale claims, and not silently breaking old pages. “Ask the LLM to maintain it” is not an engineering solution unless there are validators, source hashes, span-level citations, regression tests, and human review.\r\n\r\nIt also does not remove retrieval. Once the wiki grows beyond a modest size, you still need search, ranking, indexing, reranking, chunking, and access control. At that point the markdown wiki is just another indexed corpus, not a replacement for RAG.\r\n\r\nThe production issues are mostly ignored: permissions, multi-user edits, audit logs, rollback, deletion, sensitive data, source versioning, concurrency, compliance, cost, latency, and update frequency. These are not small details; they are exactly where knowledge-base systems fail.\r\n\r\nSo the reasonable claim is narrow: this can be a useful workflow for small-to-medium, slow-moving, human-curated research folders. It is much less convincing for large, fast-changing, high-stakes, multi-user, or enterprise knowledge bases.\r\n\r\nThe idea is fine. The framing is the problem. Without benchmarks, baselines, provenance guarantees, update-evaluation tests, and clear boundary conditions, “LLM Wiki” is mostly a good name for a familiar pattern, not proof that RAG is obsolete.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130189",
"id": 6130189,
"node_id": "GC_lADOA-n88NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdig0",
"user": {
"login": "tuirk",
"id": 65666288,
"node_id": "MDQ6VXNlcjY1NjY2Mjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/65666288?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuirk",
"html_url": "https://github.com/tuirk",
"followers_url": "https://api.github.com/users/tuirk/followers",
"following_url": "https://api.github.com/users/tuirk/following{/other_user}",
"gists_url": "https://api.github.com/users/tuirk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuirk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuirk/subscriptions",
"organizations_url": "https://api.github.com/users/tuirk/orgs",
"repos_url": "https://api.github.com/users/tuirk/repos",
"events_url": "https://api.github.com/users/tuirk/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuirk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T10:32:25Z",
"updated_at": "2026-05-02T10:32:25Z",
"body": "This gist became Kompl for us, the knowledge compiler. \r\n\r\nKompl turns scattered links, files, bookmarks, notes into a living wiki that compounds with every new source.\r\nThe basis of it is: thesis (traditional wikis), antithesis (Karpathy's LLM wiki gist), synthesis (Kompl). Basically we Hegeled the wiki based on the gist + our backgrounds.\r\n\r\n
\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130180",
"id": 6130180,
"node_id": "GC_lADOAFM_9doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdigQ",
"user": {
"login": "a-a-k",
"id": 5455861,
"node_id": "MDQ6VXNlcjU0NTU4NjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/5455861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/a-a-k",
"html_url": "https://github.com/a-a-k",
"followers_url": "https://api.github.com/users/a-a-k/followers",
"following_url": "https://api.github.com/users/a-a-k/following{/other_user}",
"gists_url": "https://api.github.com/users/a-a-k/gists{/gist_id}",
"starred_url": "https://api.github.com/users/a-a-k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/a-a-k/subscriptions",
"organizations_url": "https://api.github.com/users/a-a-k/orgs",
"repos_url": "https://api.github.com/users/a-a-k/repos",
"events_url": "https://api.github.com/users/a-a-k/events{/privacy}",
"received_events_url": "https://api.github.com/users/a-a-k/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T10:19:51Z",
"updated_at": "2026-05-02T10:19:51Z",
"body": "This is a nice personal workflow, but the hype is way ahead of the evidence.\r\n\r\nThere is no benchmark, no task definition, no scale curve, and no comparison against serious baselines. We do not know whether this is better than hybrid RAG, BM25 plus reranking, vector search, GraphRAG, hierarchical summaries, long-context prompting, NotebookLM, Perplexity Spaces, or ChatGPT Projects. Calling it a new architecture without that evidence is premature.\r\n\r\nThe core problem is that an LLM Wiki is lossy compression. You take raw documents and rewrite them into derived wiki pages. That may be useful for a small curated corpus, but it can also drop caveats, dates, minority views, exact wording, edge cases, and source context. Once people start querying the wiki instead of the original material, summary errors become part of the knowledge base.\r\n\r\nUpdates are also not solved. Adding one new source can affect many entity pages, concept pages, timelines, summaries, and indexes. At scale, this becomes graph maintenance: detecting what changed, resolving conflicts, avoiding duplicates, preserving provenance, preventing stale claims, and not silently breaking old pages. “Ask the LLM to maintain it” is not an engineering solution unless there are validators, source hashes, span-level citations, regression tests, and human review.\r\n\r\nIt also does not remove retrieval. Once the wiki grows beyond a modest size, you still need search, ranking, indexing, reranking, chunking, and access control. At that point the markdown wiki is just another indexed corpus, not a replacement for RAG.\r\n\r\nThe production issues are mostly ignored: permissions, multi-user edits, audit logs, rollback, deletion, sensitive data, source versioning, concurrency, compliance, cost, latency, and update frequency. These are not small details; they are exactly where knowledge-base systems fail.\r\n\r\nSo the reasonable claim is narrow: this can be a useful workflow for small-to-medium, slow-moving, human-curated research folders. It is much less convincing for large, fast-changing, high-stakes, multi-user, or enterprise knowledge bases.\r\n\r\nThe idea is fine. The framing is the problem. Without benchmarks, baselines, provenance guarantees, update-evaluation tests, and clear boundary conditions, “LLM Wiki” is mostly a good name for a familiar pattern, not proof that RAG is obsolete.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130189",
"id": 6130189,
"node_id": "GC_lADOA-n88NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdig0",
"user": {
"login": "tuirk",
"id": 65666288,
"node_id": "MDQ6VXNlcjY1NjY2Mjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/65666288?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuirk",
"html_url": "https://github.com/tuirk",
"followers_url": "https://api.github.com/users/tuirk/followers",
"following_url": "https://api.github.com/users/tuirk/following{/other_user}",
"gists_url": "https://api.github.com/users/tuirk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuirk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuirk/subscriptions",
"organizations_url": "https://api.github.com/users/tuirk/orgs",
"repos_url": "https://api.github.com/users/tuirk/repos",
"events_url": "https://api.github.com/users/tuirk/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuirk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T10:32:25Z",
"updated_at": "2026-05-02T10:32:25Z",
"body": "This gist became Kompl for us, the knowledge compiler. \r\n\r\nKompl turns scattered links, files, bookmarks, notes into a living wiki that compounds with every new source.\r\nThe basis of it is: thesis (traditional wikis), antithesis (Karpathy's LLM wiki gist), synthesis (Kompl). Basically we Hegeled the wiki based on the gist + our backgrounds.\r\n\r\n \r\n\r\n\r\n\r\n
\r\n\r\n\r\n\r\n
\r\n\r\n40-second demo is below, click to watch on Youtube and full details on GitHub: https://github.com/tuirk/Kompl \r\n\r\n\r\n[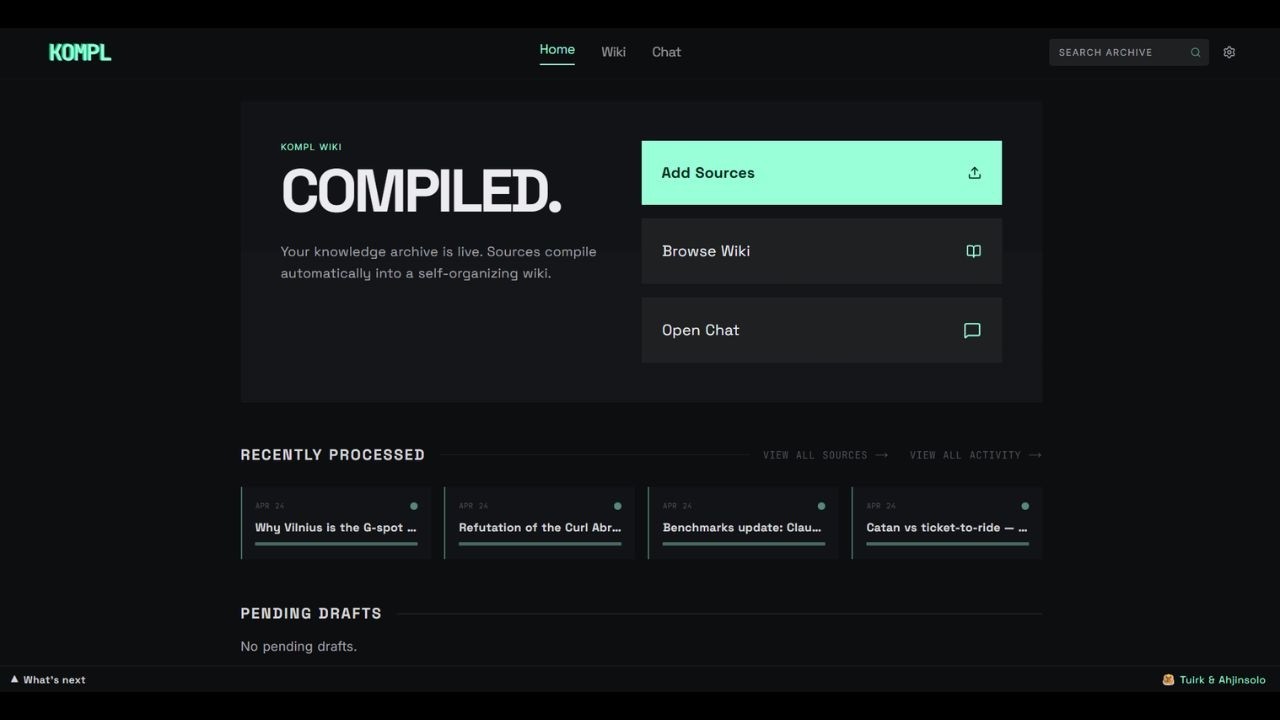](https://youtu.be/OjLRpnpeFYY)\r\n\r\n\r\n\r\n**What goes in Kompl:**\r\n\r\n- URLs (web pages, articles, YouTube videos, GitHub repos, anything Firecrawl can reach)\r\n- Files (PDF, DOCX, PPTX, XLSX, TXT, MD, HTML, CSV, images, audio)\r\n- Browser bookmark, Twitter/X bookmark, Apple Notes/Upnote exports\r\n\r\nHere's what that looks like after a few sessions; new overviews, comparisons, entity pages, contradictions surfacing, fresh cross-links between everything.\r\n \r\n\r\n### **A few specific bets we made on top of the pattern:**\r\n\r\n- **NLP before LLM.** spaCy NER + a 4-way keyphrase fanout (RAKE, KeyBERT, TextRank, YAKE) runs first; Gemini gets pre-resolved entities, not raw markdown. Cheaper and less noisy.\r\n- **Batch ingest, async compile.** Drop sources, close the tab, come back to a wiki. Server-side pipeline with rate limits, a customizable daily USD cap, and other settings (entity promotion threshold, draft length floor, model tier per session, schema-driven tone — more in the repo).\r\n- **Three layers of entity resolution** (fuzzy, embedding, LLM disambiguation) collapse variations like \"GPT 4\", \"GPT-4\", and \"gpt4\" into one canonical.\r\n- **Comparison pages** surface when sources disagree across three or more sources.\r\n- **Wikilinks** get injected deterministically by regex, not by an LLM.\r\n- **MCP-native.** Stdio MCP server (`search_wiki`, `read_page`, `list_pages`, `wiki_stats`) so Claude Code, Claude Desktop, Cursor can use the wiki as a knowledge source out of the box. That's our favorite feature.\r\n- **For UI** the gist mentions Obsidian as the IDE. Kompl runs in its own UI but ships an Obsidian-compatible export, so you're not locked in either way.\r\n- **Local Docker, single-tenant**, BYO Gemini + Firecrawl keys. Open-sourced with Apache-2.0.\r\n\r\n\r\nClone it, run it on your own sources, let me know how it goes 🥸\r\n\r\nRepo: https://github.com/tuirk/Kompl\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130309",
"id": 6130309,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdioU",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T12:28:36Z",
"updated_at": "2026-05-02T12:28:36Z",
"body": "**The problem SwarmVault solves, explained simply.** Figured it's worth stepping back from the release notes and just saying what this thing is.\r\n\r\nEvery time you start a new chat with an AI coding agent, it knows nothing. You paste in files, re-explain context, re-describe your architecture. Next session, same thing. Your knowledge resets to zero every time the context window clears.\r\n\r\nSwarmVault fixes that. It's a compiler for knowledge.\r\n\r\nYou point it at your sources: a codebase, a folder of research papers, meeting transcripts, YouTube videos, Slack exports, whatever. It ingests everything, builds a persistent markdown wiki and a knowledge graph, and maintains a search index over all of it. The wiki lives on your machine as plain files. It compounds every time you add sources or recompile.\r\n\r\nThen instead of feeding your AI agent 200k tokens of raw files, you give it a curated context pack with exactly the evidence it needs, bounded to a token budget you control. The agent queries the graph, not your raw source tree. It gets better answers with fewer tokens.\r\n\r\nThe key ideas:\r\n1. **The wiki is the artifact, not the chat.** This is Karpathy's original insight from this gist. Chats are ephemeral. The wiki persists and grows.\r\n2. **Compile once, query forever.** Stop re-processing the same sources every session.\r\n3. **Your agent gets memory.** Task ledger tracks goals, decisions, and outcomes across sessions. Your agent picks up where it left off.\r\n4. **Everything stays local.** Nothing leaves your machine unless you explicitly choose a cloud provider. Works fully offline with the built-in heuristic provider or local Ollama/Whisper.\r\n\r\nWorks with any LLM provider. Integrates with 48 coding agents. Has an Obsidian plugin. MIT licensed. One command to try it:\r\n\r\n`npx @swarmvaultai/cli demo`\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130374",
"id": 6130374,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdisY",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T13:12:21Z",
"updated_at": "2026-05-02T13:12:21Z",
"body": "ΩmegaWiki(440⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\nhttps://github.com/skyllwt/OmegaWiki\r\n\r\n
\r\n\r\n### **A few specific bets we made on top of the pattern:**\r\n\r\n- **NLP before LLM.** spaCy NER + a 4-way keyphrase fanout (RAKE, KeyBERT, TextRank, YAKE) runs first; Gemini gets pre-resolved entities, not raw markdown. Cheaper and less noisy.\r\n- **Batch ingest, async compile.** Drop sources, close the tab, come back to a wiki. Server-side pipeline with rate limits, a customizable daily USD cap, and other settings (entity promotion threshold, draft length floor, model tier per session, schema-driven tone — more in the repo).\r\n- **Three layers of entity resolution** (fuzzy, embedding, LLM disambiguation) collapse variations like \"GPT 4\", \"GPT-4\", and \"gpt4\" into one canonical.\r\n- **Comparison pages** surface when sources disagree across three or more sources.\r\n- **Wikilinks** get injected deterministically by regex, not by an LLM.\r\n- **MCP-native.** Stdio MCP server (`search_wiki`, `read_page`, `list_pages`, `wiki_stats`) so Claude Code, Claude Desktop, Cursor can use the wiki as a knowledge source out of the box. That's our favorite feature.\r\n- **For UI** the gist mentions Obsidian as the IDE. Kompl runs in its own UI but ships an Obsidian-compatible export, so you're not locked in either way.\r\n- **Local Docker, single-tenant**, BYO Gemini + Firecrawl keys. Open-sourced with Apache-2.0.\r\n\r\n\r\nClone it, run it on your own sources, let me know how it goes 🥸\r\n\r\nRepo: https://github.com/tuirk/Kompl\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130309",
"id": 6130309,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdioU",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T12:28:36Z",
"updated_at": "2026-05-02T12:28:36Z",
"body": "**The problem SwarmVault solves, explained simply.** Figured it's worth stepping back from the release notes and just saying what this thing is.\r\n\r\nEvery time you start a new chat with an AI coding agent, it knows nothing. You paste in files, re-explain context, re-describe your architecture. Next session, same thing. Your knowledge resets to zero every time the context window clears.\r\n\r\nSwarmVault fixes that. It's a compiler for knowledge.\r\n\r\nYou point it at your sources: a codebase, a folder of research papers, meeting transcripts, YouTube videos, Slack exports, whatever. It ingests everything, builds a persistent markdown wiki and a knowledge graph, and maintains a search index over all of it. The wiki lives on your machine as plain files. It compounds every time you add sources or recompile.\r\n\r\nThen instead of feeding your AI agent 200k tokens of raw files, you give it a curated context pack with exactly the evidence it needs, bounded to a token budget you control. The agent queries the graph, not your raw source tree. It gets better answers with fewer tokens.\r\n\r\nThe key ideas:\r\n1. **The wiki is the artifact, not the chat.** This is Karpathy's original insight from this gist. Chats are ephemeral. The wiki persists and grows.\r\n2. **Compile once, query forever.** Stop re-processing the same sources every session.\r\n3. **Your agent gets memory.** Task ledger tracks goals, decisions, and outcomes across sessions. Your agent picks up where it left off.\r\n4. **Everything stays local.** Nothing leaves your machine unless you explicitly choose a cloud provider. Works fully offline with the built-in heuristic provider or local Ollama/Whisper.\r\n\r\nWorks with any LLM provider. Integrates with 48 coding agents. Has an Obsidian plugin. MIT licensed. One command to try it:\r\n\r\n`npx @swarmvaultai/cli demo`\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6130374",
"id": 6130374,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdisY",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-02T13:12:21Z",
"updated_at": "2026-05-02T13:12:21Z",
"body": "ΩmegaWiki(440⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\nhttps://github.com/skyllwt/OmegaWiki\r\n\r\n \r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131138",
"id": 6131138,
"node_id": "GC_lADOAO_nE9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjcI",
"user": {
"login": "gowtham0992",
"id": 15722259,
"node_id": "MDQ6VXNlcjE1NzIyMjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/15722259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gowtham0992",
"html_url": "https://github.com/gowtham0992",
"followers_url": "https://api.github.com/users/gowtham0992/followers",
"following_url": "https://api.github.com/users/gowtham0992/following{/other_user}",
"gists_url": "https://api.github.com/users/gowtham0992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gowtham0992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gowtham0992/subscriptions",
"organizations_url": "https://api.github.com/users/gowtham0992/orgs",
"repos_url": "https://api.github.com/users/gowtham0992/repos",
"events_url": "https://api.github.com/users/gowtham0992/events{/privacy}",
"received_events_url": "https://api.github.com/users/gowtham0992/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T04:45:59Z",
"updated_at": "2026-05-03T04:45:59Z",
"body": "## Link v1.0.5 is live\r\n\r\nReleased `link-mcp` v1.0.5 on PyPI and the MCP Registry.\r\n\r\nWhat changed:\r\n- Added `link.py demo` for a pre-ingested first-run wiki.\r\n- Added `link.py doctor` to check wiki health, graph integrity, source hygiene, and secret-looking files.\r\n- Added `link.py rebuild-backlinks` for local graph repair.\r\n- Hardened `/api/context` and MCP context behavior.\r\n- Added CI trust gates for tests, demo health, package build, release hygiene, and version consistency.\r\n- Improved GitHub install docs for macOS/Homebrew Python environments.\r\n\r\n```bash\r\ngit clone https://github.com/gowtham0992/link.git\r\ncd link\r\npython3 link.py demo\r\ncd link-demo\r\npython3 serve.py\r\n```\r\n\r\nMCP:\r\n\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nIf macOS/Homebrew blocks pip with externally-managed-environment, use a venv:\r\n\r\n```\r\npython3 -m venv ~/.link-mcp-venv\r\n~/.link-mcp-venv/bin/python -m pip install --upgrade pip link-mcp\r\n```\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nPyPI: https://pypi.org/project/link-mcp/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131263",
"id": 6131263,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjj8",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T08:36:00Z",
"updated_at": "2026-05-03T08:36:00Z",
"body": " I built Aura: a local-first AI daemon that gives your tools persistent memory, claim verification, and MCP observability\r\n\r\nI kept running into the same frustration with AI coding tools: every session felt like starting from zero.\r\n\r\nLocal AI, Claude Code, Cursor, Gemini CLI, ChatGPT, Codex - they all remember things differently, if at all. Decisions get lost, context gets scattered, and when an AI says “I created the file” or “I installed the package,” you still have to double-check it yourself. So I built Aura - a local-first daemon that gives AI tools persistent memory, claim verification, MCP traffic observability, OWASP compliance scoring, and a self-improving knowledge wiki. It is designed to work across tools, with one binary and zero cloud dependency.\r\n\r\nThe core idea is simple: make AI sessions compound instead of reset. Aura lets you store memory once and reuse it across tools, verify whether agent claims are actually true, track what your AI sessions cost, inspect MCP traffic, and keep a knowledge base that grows over time instead of disappearing with the session.\r\n\r\nA few things Aura currently does:\r\nAura can verify claims like file creation or package installation, share memory across tools, compress context before it hits the model, scan for phantom or unused dependencies, track token/cost usage, and gate destructive actions with approval. It also includes a wiki mode for ingesting docs, URLs, and folders, then querying and visualizing the resulting knowledge graph.\r\n\r\nIt is still early - it is in v1.0-dev am sharing it now because I want feedback from people who feel the same pain: fragmented AI context, unreliable agent actions, and no real observability into what the tool is doing.\r\n\r\nIf this problem sounds familiar, I would love feedback, ideas, and brutal honesty.\r\n\r\nhttps://github.com/ojuschugh1/aura \r\n\r\nIf you try it, a ⭐ helps with discoverability - and bug reports are welcome since this is v1.0-dev so rough edges exist.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131265",
"id": 6131265,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjkE",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T08:38:29Z",
"updated_at": "2026-05-03T08:38:29Z",
"body": "
\r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131138",
"id": 6131138,
"node_id": "GC_lADOAO_nE9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjcI",
"user": {
"login": "gowtham0992",
"id": 15722259,
"node_id": "MDQ6VXNlcjE1NzIyMjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/15722259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gowtham0992",
"html_url": "https://github.com/gowtham0992",
"followers_url": "https://api.github.com/users/gowtham0992/followers",
"following_url": "https://api.github.com/users/gowtham0992/following{/other_user}",
"gists_url": "https://api.github.com/users/gowtham0992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gowtham0992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gowtham0992/subscriptions",
"organizations_url": "https://api.github.com/users/gowtham0992/orgs",
"repos_url": "https://api.github.com/users/gowtham0992/repos",
"events_url": "https://api.github.com/users/gowtham0992/events{/privacy}",
"received_events_url": "https://api.github.com/users/gowtham0992/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T04:45:59Z",
"updated_at": "2026-05-03T04:45:59Z",
"body": "## Link v1.0.5 is live\r\n\r\nReleased `link-mcp` v1.0.5 on PyPI and the MCP Registry.\r\n\r\nWhat changed:\r\n- Added `link.py demo` for a pre-ingested first-run wiki.\r\n- Added `link.py doctor` to check wiki health, graph integrity, source hygiene, and secret-looking files.\r\n- Added `link.py rebuild-backlinks` for local graph repair.\r\n- Hardened `/api/context` and MCP context behavior.\r\n- Added CI trust gates for tests, demo health, package build, release hygiene, and version consistency.\r\n- Improved GitHub install docs for macOS/Homebrew Python environments.\r\n\r\n```bash\r\ngit clone https://github.com/gowtham0992/link.git\r\ncd link\r\npython3 link.py demo\r\ncd link-demo\r\npython3 serve.py\r\n```\r\n\r\nMCP:\r\n\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nIf macOS/Homebrew blocks pip with externally-managed-environment, use a venv:\r\n\r\n```\r\npython3 -m venv ~/.link-mcp-venv\r\n~/.link-mcp-venv/bin/python -m pip install --upgrade pip link-mcp\r\n```\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nPyPI: https://pypi.org/project/link-mcp/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131263",
"id": 6131263,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjj8",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T08:36:00Z",
"updated_at": "2026-05-03T08:36:00Z",
"body": " I built Aura: a local-first AI daemon that gives your tools persistent memory, claim verification, and MCP observability\r\n\r\nI kept running into the same frustration with AI coding tools: every session felt like starting from zero.\r\n\r\nLocal AI, Claude Code, Cursor, Gemini CLI, ChatGPT, Codex - they all remember things differently, if at all. Decisions get lost, context gets scattered, and when an AI says “I created the file” or “I installed the package,” you still have to double-check it yourself. So I built Aura - a local-first daemon that gives AI tools persistent memory, claim verification, MCP traffic observability, OWASP compliance scoring, and a self-improving knowledge wiki. It is designed to work across tools, with one binary and zero cloud dependency.\r\n\r\nThe core idea is simple: make AI sessions compound instead of reset. Aura lets you store memory once and reuse it across tools, verify whether agent claims are actually true, track what your AI sessions cost, inspect MCP traffic, and keep a knowledge base that grows over time instead of disappearing with the session.\r\n\r\nA few things Aura currently does:\r\nAura can verify claims like file creation or package installation, share memory across tools, compress context before it hits the model, scan for phantom or unused dependencies, track token/cost usage, and gate destructive actions with approval. It also includes a wiki mode for ingesting docs, URLs, and folders, then querying and visualizing the resulting knowledge graph.\r\n\r\nIt is still early - it is in v1.0-dev am sharing it now because I want feedback from people who feel the same pain: fragmented AI context, unreliable agent actions, and no real observability into what the tool is doing.\r\n\r\nIf this problem sounds familiar, I would love feedback, ideas, and brutal honesty.\r\n\r\nhttps://github.com/ojuschugh1/aura \r\n\r\nIf you try it, a ⭐ helps with discoverability - and bug reports are welcome since this is v1.0-dev so rough edges exist.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131265",
"id": 6131265,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjkE",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T08:38:29Z",
"updated_at": "2026-05-03T08:38:29Z",
"body": "I got tired of watching Coding sessions re-read the same files over and over. A 2,000-token file read 5 times = 10,000 tokens gone. So I built sqz.
The key insight: most token waste isn't from verbose content - it's from repetition. sqz keeps a SHA-256 content cache. First read compresses normally. Every subsequent read of the same file returns a 13-token inline reference instead of the full content. The LLM still understands it.
Real numbers from my sessions:
\r\nScenario | Savings | How\r\n-- | -- | --\r\n | | \r\n | | \r\nRepeated file reads (5x) | 86% | Dedup cache: 13-token ref after first read\r\nJSON API responses with nulls | 7–56% | Strip nulls + TOON encoding (varies by null density)\r\nRepeated log lines | 58% | Condense stage collapses duplicates\r\nLarge JSON arrays | 77% | Array sampling + collapse\r\nStack traces | 0% | Intentional - error content is sacred\r\n\r\nThat last row is the whole philosophy. Aggressive compression can save more tokens on paper, but if it strips context from your error messages or drops lines from your diffs, the LLM gives you worse answers and you end up spending more tokens fixing the mistakes. sqz compresses what's safe to compress and leaves critical content untouched.
Works across 4 surfaces:
- Shell hook (auto-compresses CLI output)
- MCP server (compiled Rust, not Node)
- Browser extension - Firefox approved. Works on ChatGPT, Claude, Gemini, Grok, Perplexity, Github Copilot
- IDE plugins (JetBrains, VS Code)
Install:
cargo install sqz-cli
sqz init
Also available via npm (npm i -g sqz-cli) and pip (pip install sqz).
Track your savings:
sqz gain # ASCII chart of daily token savings
sqz stats # cumulative compression report
Single Rust binary. Zero telemetry. 1000+ tests including 57 property-based correctness proofs.
GitHub: https://github.com/ojuschugh1/sqz
Docs: https://ojuschugh1.github.io/sqz/
If you try it, a ⭐ helps with discoverability - and bug reports are welcome since this is v1.0.4 so rough edges exist.
Have anyone else facing this problem ? Happy to answer questions about the architecture or benchmarks.
\r\n\r\nCurrently got 176 stars"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131298",
"id": 6131298,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjmI",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T10:01:03Z",
"updated_at": "2026-05-03T10:01:03Z",
"body": "**Who SwarmVault is actually for (and how people are using it).** Different angle this time.\r\n\r\nThe LLM Wiki concept from this gist resonates with a lot of different workflows. Here's who's getting the most out of SwarmVault:\r\n\r\n**Developers with large codebases.** You have a monorepo or multi-repo setup. Your AI agent can't hold the whole thing in context. SwarmVault compiles it into a knowledge graph with cross-file call edges, import resolution, and module-level pages. Your agent queries the graph instead of grepping through raw source. `swarmvault scan .` and you're running in under a minute.\r\n\r\n**Researchers and students.** You're reading 50 papers, watching conference talks, collecting notes across tools. SwarmVault ingests PDFs, transcripts, EPUBs, YouTube videos, and audio recordings into one searchable wiki with contradiction detection across sources. The graph shows you connections you didn't notice. Guided ingest sessions help you process sources one at a time with evolving summaries.\r\n\r\n**People building second brains.** If you use Obsidian, SwarmVault has a native plugin and exports with Dataview dashboards, typed links for Breadcrumbs/Juggl, and graph metrics in frontmatter. The wiki it produces is plain markdown. It works with whatever note-taking setup you already have.\r\n\r\n**Teams using AI coding agents.** `swarmvault install --agent` covers 48 tools (Claude Code, Cursor, Copilot, Cline, Kiro, Codex, and 42 more). The agent memory ledger means context carries across sessions. Context packs give your agent bounded, relevant evidence instead of a full context window dump.\r\n\r\n**Anyone tired of re-explaining things to AI.** That's really what it comes down to. You build a vault once and it remembers. The wiki compounds. The graph gets richer. Your agent gets smarter without you repeating yourself.\r\n\r\nEverything local. Every provider supported. Fully offline capable. MIT licensed.\r\n\r\n`npx @swarmvaultai/cli demo`\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131474",
"id": 6131474,
"node_id": "GC_lADOAgoZ99oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdjxI",
"user": {
"login": "VeniVeci",
"id": 34216439,
"node_id": "MDQ6VXNlcjM0MjE2NDM5",
"avatar_url": "https://avatars.githubusercontent.com/u/34216439?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VeniVeci",
"html_url": "https://github.com/VeniVeci",
"followers_url": "https://api.github.com/users/VeniVeci/followers",
"following_url": "https://api.github.com/users/VeniVeci/following{/other_user}",
"gists_url": "https://api.github.com/users/VeniVeci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/VeniVeci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/VeniVeci/subscriptions",
"organizations_url": "https://api.github.com/users/VeniVeci/orgs",
"repos_url": "https://api.github.com/users/VeniVeci/repos",
"events_url": "https://api.github.com/users/VeniVeci/events{/privacy}",
"received_events_url": "https://api.github.com/users/VeniVeci/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T13:59:44Z",
"updated_at": "2026-05-03T13:59:44Z",
"body": "This idea is fantastic! Inspired by it, I recently built a VLM Wiki and added multimodal capabilities—it doesn't just process text, it also understands photos and videos, automatically extracting scenes, locations, people, and generating a wiki with bidirectional links.\r\n\r\nProject here: [ VLM-wiki ](https://github.com/VeniVeci/VLM-wiki)\r\n\r\nKey additions:\r\n\r\n1. Expanded the raw/ directory to support images, videos, and audio;\r\n2. Added a VLM-based image analysis pipeline;\r\n3. Processed videos by extracting keyframes for understanding and generating summaries;\r\n\r\nCurrently, I've tested it with a trip's media and it works quite well!\r\n\r\n "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131689",
"id": 6131689,
"node_id": "GC_lADODv9qJtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdj-k",
"user": {
"login": "superimpactful",
"id": 251619878,
"node_id": "U_kgDODv9qJg",
"avatar_url": "https://avatars.githubusercontent.com/u/251619878?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/superimpactful",
"html_url": "https://github.com/superimpactful",
"followers_url": "https://api.github.com/users/superimpactful/followers",
"following_url": "https://api.github.com/users/superimpactful/following{/other_user}",
"gists_url": "https://api.github.com/users/superimpactful/gists{/gist_id}",
"starred_url": "https://api.github.com/users/superimpactful/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/superimpactful/subscriptions",
"organizations_url": "https://api.github.com/users/superimpactful/orgs",
"repos_url": "https://api.github.com/users/superimpactful/repos",
"events_url": "https://api.github.com/users/superimpactful/events{/privacy}",
"received_events_url": "https://api.github.com/users/superimpactful/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T16:12:43Z",
"updated_at": "2026-05-03T16:12:43Z",
"body": "This is awesome and great that it blew up. \r\n\r\nI think two things are missing to make it scale: routing tables and non-hierarchical taxonomies.\r\n\r\nThe first problem is the words. Your index.md is AI-organized, which means it's categorized the way the AI sees it –– not necessarily how the user would look for things. If I've always called a spatula \"the flat flippy thing,\" the best AI-organized index doesn't help me. Language is shared but also personal.\r\n\r\nThe second problem is scale. Once the index grows large enough, you've traded one context dump for a slightly smaller one. Routing tables fix that. Instead of searching 1,000 lines, the AI follows 2 or 3 hops before it ever touches the content. The search surface stays manageable as the dataset grows.\r\n\r\nThe organizing logic should come from the user. User designs the structure, the AI maintains it. That's the part that makes the whole thing actually work.\r\n\r\nI did a more thorough breakdown here: https://jgibbard.com/karpathy-llm-wiki-missing-pieces/"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6131973",
"id": 6131973,
"node_id": "GC_lADOAYFfBdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdkQU",
"user": {
"login": "killerra",
"id": 25255685,
"node_id": "MDQ6VXNlcjI1MjU1Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/25255685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/killerra",
"html_url": "https://github.com/killerra",
"followers_url": "https://api.github.com/users/killerra/followers",
"following_url": "https://api.github.com/users/killerra/following{/other_user}",
"gists_url": "https://api.github.com/users/killerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/killerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/killerra/subscriptions",
"organizations_url": "https://api.github.com/users/killerra/orgs",
"repos_url": "https://api.github.com/users/killerra/repos",
"events_url": "https://api.github.com/users/killerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/killerra/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-03T22:07:10Z",
"updated_at": "2026-05-03T22:07:45Z",
"body": "> **Who SwarmVault is actually for (and how people are using it).** Different angle this time.\r\n> \r\n> The LLM Wiki concept from this gist resonates with a lot of different workflows. Here's who's getting the most out of SwarmVault:\r\n> \r\n> **Developers with large codebases.** You have a monorepo or multi-repo setup. Your AI agent can't hold the whole thing in context. SwarmVault compiles it into a knowledge graph with cross-file call edges, import resolution, and module-level pages. Your agent queries the graph instead of grepping through raw source. `swarmvault scan .` and you're running in under a minute.\r\n> \r\n> **Researchers and students.** You're reading 50 papers, watching conference talks, collecting notes across tools. SwarmVault ingests PDFs, transcripts, EPUBs, YouTube videos, and audio recordings into one searchable wiki with contradiction detection across sources. The graph shows you connections you didn't notice. Guided ingest sessions help you process sources one at a time with evolving summaries.\r\n> \r\n> **People building second brains.** If you use Obsidian, SwarmVault has a native plugin and exports with Dataview dashboards, typed links for Breadcrumbs/Juggl, and graph metrics in frontmatter. The wiki it produces is plain markdown. It works with whatever note-taking setup you already have.\r\n> \r\n> **Teams using AI coding agents.** `swarmvault install --agent` covers 48 tools (Claude Code, Cursor, Copilot, Cline, Kiro, Codex, and 42 more). The agent memory ledger means context carries across sessions. Context packs give your agent bounded, relevant evidence instead of a full context window dump.\r\n> \r\n> **Anyone tired of re-explaining things to AI.** That's really what it comes down to. You build a vault once and it remembers. The wiki compounds. The graph gets richer. Your agent gets smarter without you repeating yourself.\r\n> \r\n> Everything local. Every provider supported. Fully offline capable. MIT licensed.\r\n> \r\n> `npx @swarmvaultai/cli demo`\r\n> \r\n> Repo: **https://github.com/swarmclawai/swarmvault**\r\n\r\n@waydelyle Stop spamming this. This specific style of AI-generated ad—especially one asking users to pipe a command to their terminal—looks incredibly suspicious. In a climate of constant supply chain attacks, you are making your project look like malware. If SwarmVault is a legitimate MIT-licensed tool, let the code speak for itself instead of using bot-like marketing tactics."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6132340",
"id": 6132340,
"node_id": "GC_lADOAHm7a9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdknQ",
"user": {
"login": "zhurudong",
"id": 7977835,
"node_id": "MDQ6VXNlcjc5Nzc4MzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7977835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhurudong",
"html_url": "https://github.com/zhurudong",
"followers_url": "https://api.github.com/users/zhurudong/followers",
"following_url": "https://api.github.com/users/zhurudong/following{/other_user}",
"gists_url": "https://api.github.com/users/zhurudong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhurudong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhurudong/subscriptions",
"organizations_url": "https://api.github.com/users/zhurudong/orgs",
"repos_url": "https://api.github.com/users/zhurudong/repos",
"events_url": "https://api.github.com/users/zhurudong/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhurudong/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T06:15:48Z",
"updated_at": "2026-05-04T06:15:48Z",
"body": "Tried building a minimal instantiation of this pattern — just two layers (raw/ immutable + wiki/ LLM-compiled), one CLAUDE.md file as the entire \"program\", no vector DB or ingest pipeline. The same file works across Claude Code / Codex / OpenCode by symlinking to AGENTS.md, so switching tools requires zero migration.\r\n\r\nSharing in case it's useful as a starting point: https://github.com/zhurudong/andrej-karpathy-llm-wiki\r\n\r\nGenuinely curious if the two-layer schema (raw vs wiki) holds up, or if I'm missing a category that should live elsewhere. Open to feedback."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133115",
"id": 6133115,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdlXs",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T15:46:07Z",
"updated_at": "2026-05-04T15:46:07Z",
"body": "**What a SwarmVault workflow actually looks like, start to finish.** No feature lists this time, just the actual steps.\r\n\r\nLet's say you have a codebase, a handful of research papers, and some meeting transcripts you want your AI agent to actually understand.\r\n\r\n**Step 1: Init a vault.**\r\n```\r\nnpx @swarmvaultai/cli init\r\n```\r\nTakes 10 seconds. Creates `raw/`, `wiki/`, and a schema file. No API key needed.\r\n\r\n**Step 2: Point it at your sources.**\r\n```\r\nswarmvault source add ./my-project --repo\r\nswarmvault source add ./papers/\r\nswarmvault source add https://youtube.com/watch?v=...\r\nswarmvault ingest meeting-recording.mp3\r\n```\r\nCode gets parser-backed AST analysis. PDFs, transcripts, YouTube, and audio get extracted and structured. 50+ formats supported.\r\n\r\n**Step 3: Compile.**\r\n```\r\nswarmvault compile\r\n```\r\nThis builds the wiki pages, the knowledge graph, the search index, contradiction detection across sources, and a share card you can post anywhere. The output is plain markdown files in `wiki/`.\r\n\r\n**Step 4: Your agent uses it.**\r\n```\r\nswarmvault context build \"refactor the auth module\" --budget 8000\r\nswarmvault query \"what do the research papers say about X\"\r\nswarmvault graph path auth-module payment-service\r\n```\r\nYour agent gets bounded, relevant context instead of reading the entire source tree. The task ledger remembers what it was working on across sessions.\r\n\r\n**Step 5: It compounds.**\r\n```\r\nswarmvault source reload --all\r\nswarmvault compile\r\n```\r\nNew sources get added, existing ones get refreshed, the wiki grows, the graph gets richer. `swarmvault watch` does this automatically on git commits.\r\n\r\nThat's it. Everything stays on your machine. Works with any LLM provider or fully offline. The vault is just files you own.\r\n\r\n`swarmvault doctor` tells you if anything needs attention. `swarmvault graph serve` opens the visual workbench. `swarmvault install --agent` wires it into your coding tool.\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133116",
"id": 6133116,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdlXw",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T15:46:33Z",
"updated_at": "2026-05-04T15:46:33Z",
"body": "**What a SwarmVault workflow actually looks like, start to finish.** No feature lists this time, just the actual steps.\r\n\r\nLet's say you have a codebase, a handful of research papers, and some meeting transcripts you want your AI agent to actually understand.\r\n\r\n**Step 1: Init a vault.**\r\n```\r\nnpx @swarmvaultai/cli init\r\n```\r\nTakes 10 seconds. Creates `raw/`, `wiki/`, and a schema file. No API key needed.\r\n\r\n**Step 2: Point it at your sources.**\r\n```\r\nswarmvault source add ./my-project --repo\r\nswarmvault source add ./papers/\r\nswarmvault source add https://youtube.com/watch?v=...\r\nswarmvault ingest meeting-recording.mp3\r\n```\r\nCode gets parser-backed AST analysis. PDFs, transcripts, YouTube, and audio get extracted and structured. 50+ formats supported.\r\n\r\n**Step 3: Compile.**\r\n```\r\nswarmvault compile\r\n```\r\nThis builds the wiki pages, the knowledge graph, the search index, contradiction detection across sources, and a share card you can post anywhere. The output is plain markdown files in `wiki/`.\r\n\r\n**Step 4: Your agent uses it.**\r\n```\r\nswarmvault context build \"refactor the auth module\" --budget 8000\r\nswarmvault query \"what do the research papers say about X\"\r\nswarmvault graph path auth-module payment-service\r\n```\r\nYour agent gets bounded, relevant context instead of reading the entire source tree. The task ledger remembers what it was working on across sessions.\r\n\r\n**Step 5: It compounds.**\r\n```\r\nswarmvault source reload --all\r\nswarmvault compile\r\n```\r\nNew sources get added, existing ones get refreshed, the wiki grows, the graph gets richer. `swarmvault watch` does this automatically on git commits.\r\n\r\nThat's it. Everything stays on your machine. Works with any LLM provider or fully offline. The vault is just files you own.\r\n\r\n`swarmvault doctor` tells you if anything needs attention. `swarmvault graph serve` opens the visual workbench. `swarmvault install --agent` wires it into your coding tool.\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133117",
"id": 6133117,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdlX0",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T15:46:51Z",
"updated_at": "2026-05-04T15:46:51Z",
"body": "**What a SwarmVault workflow actually looks like, start to finish.** No feature lists this time, just the actual steps.\r\n\r\nLet's say you have a codebase, a handful of research papers, and some meeting transcripts you want your AI agent to actually understand.\r\n\r\n**Step 1: Init a vault.**\r\n```\r\nnpx @swarmvaultai/cli init\r\n```\r\nTakes 10 seconds. Creates `raw/`, `wiki/`, and a schema file. No API key needed.\r\n\r\n**Step 2: Point it at your sources.**\r\n```\r\nswarmvault source add ./my-project --repo\r\nswarmvault source add ./papers/\r\nswarmvault source add https://youtube.com/watch?v=...\r\nswarmvault ingest meeting-recording.mp3\r\n```\r\nCode gets parser-backed AST analysis. PDFs, transcripts, YouTube, and audio get extracted and structured. 50+ formats supported.\r\n\r\n**Step 3: Compile.**\r\n```\r\nswarmvault compile\r\n```\r\nThis builds the wiki pages, the knowledge graph, the search index, contradiction detection across sources, and a share card you can post anywhere. The output is plain markdown files in `wiki/`.\r\n\r\n**Step 4: Your agent uses it.**\r\n```\r\nswarmvault context build \"refactor the auth module\" --budget 8000\r\nswarmvault query \"what do the research papers say about X\"\r\nswarmvault graph path auth-module payment-service\r\n```\r\nYour agent gets bounded, relevant context instead of reading the entire source tree. The task ledger remembers what it was working on across sessions.\r\n\r\n**Step 5: It compounds.**\r\n```\r\nswarmvault source reload --all\r\nswarmvault compile\r\n```\r\nNew sources get added, existing ones get refreshed, the wiki grows, the graph gets richer. `swarmvault watch` does this automatically on git commits.\r\n\r\nThat's it. Everything stays on your machine. Works with any LLM provider or fully offline. The vault is just files you own.\r\n\r\n`swarmvault doctor` tells you if anything needs attention. `swarmvault graph serve` opens the visual workbench. `swarmvault install --agent` wires it into your coding tool.\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133141",
"id": 6133141,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdlZU",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T16:16:10Z",
"updated_at": "2026-05-04T16:16:10Z",
"body": "Synthadoc v0.3.0 is now released.\r\n\r\n👉 https://github.com/axoviq-ai/synthadoc\r\n\r\nv0.3.0 expands on the same architecture. The big additions this cycle are around what can go into the wiki, and removing the friction of needing a separate API key:\r\n\r\n- Zero-API-key LLM providers: if you already pay for Claude Code or Opencode, one config line (provider = \"claude-code\") routes all three agents (ingest, query, lint) through your existing subscription. No separate API keys or Anthropic/OpenAI account needed.\r\n\r\n- YouTube transcript ingest: paste a YouTube URL, get a structured wiki page with an LLM-generated executive summary and a full [MM:SS] timestamped transcript. Captions are extracted from YouTube's caption system, no audio download, no external transcription API. Every claim is traceable to a moment in the video.\r\n\r\n- Web search fan-out: one search query decomposes into sub-questions, ingests multiple sources in parallel, and builds cross-references automatically. A single command can add 8–15 synthesised pages to the wiki.\r\n\r\n- CJK multilingual support: Chinese, Japanese, and Korean queries, wiki pages, slugs, and wikilinks now work correctly throughout the pipeline.\r\n\r\n- Knowledge gap detection no longer produces false reports on CJK input.\r\n\r\n- Also new: DeepSeek as the eighth LLM provider (lowest cost per token for text-heavy ingest); \"synthadoc use\" to save your active wiki across sessions; and hardened multi-aspect knowledge gap detection.\r\n\r\nRelease notes:\r\n 👉 https://github.com/axoviq-ai/synthadoc/releases/tag/v0.3.0\r\n\r\nDocs:\r\n 👉 [Quick orientation and feature overview] https://github.com/axoviq-ai/synthadoc#readme\r\n 👉 [Up and running in minutes] https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md\r\n 👉 [Full architecture, agents, storage, API, and plugin guide] https://github.com/axoviq-ai/synthadoc/blob/main/docs/design.md\r\n\r\nFeedback on v0.3.0 is very welcome."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133277",
"id": 6133277,
"node_id": "GC_lADOALUbLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdlh0",
"user": {
"login": "theafh",
"id": 11868972,
"node_id": "MDQ6VXNlcjExODY4OTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11868972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theafh",
"html_url": "https://github.com/theafh",
"followers_url": "https://api.github.com/users/theafh/followers",
"following_url": "https://api.github.com/users/theafh/following{/other_user}",
"gists_url": "https://api.github.com/users/theafh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theafh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theafh/subscriptions",
"organizations_url": "https://api.github.com/users/theafh/orgs",
"repos_url": "https://api.github.com/users/theafh/repos",
"events_url": "https://api.github.com/users/theafh/events{/privacy}",
"received_events_url": "https://api.github.com/users/theafh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T18:04:11Z",
"updated_at": "2026-05-04T18:04:11Z",
"body": "Adding to the implementations already in this thread. Mine is a per-repo wiki as skill/agent-kombo: the knowledge base lives in the project repo, committed alongside the code it describes, with one knowledge base per codebase.\r\n\r\nA few things that fell out of that choice:\r\n\r\n- Plain markdown in a folder. The schema lives in the skill prompt, so any agent that reads markdown can author and query the wiki.\r\n- Captures the how. Runbooks, decision rationales, recurring fix patterns, procedural knowledge, alongside sources and concepts. That made it the thing I actually open every day.\r\n- Deterministic linter. A Python linter plus shell scripts check frontmatter schemas, page type anatomy, link integrity, tag taxonomy, page size, and topic mixing. Rules live in lint_checks.md. The agent consumes the linter's output, so structural correctness is enforced by rules.\r\n- Cleanup agent on top. wiki_auto_shaper runs the linter in a loop, fixes frontmatter, splits oversized or topic-mixing pages, repairs broken links, and audits each page against its page type anatomy. Curation is the real work, and the agent owns it.\r\n- Ships as a skill (Claude Code, Codex, Cursor, Gemini CLI, Antigravity).\r\n- Code: [https://github.com/theafh/ai-modules/tree/main/plugins/knowledge_management](https://github.com/theafh/ai-modules/tree/main/plugins/knowledge_management)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133573",
"id": 6133573,
"node_id": "GC_lADOABy3kNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdl0U",
"user": {
"login": "GuillaumeDesforges",
"id": 1882000,
"node_id": "MDQ6VXNlcjE4ODIwMDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1882000?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GuillaumeDesforges",
"html_url": "https://github.com/GuillaumeDesforges",
"followers_url": "https://api.github.com/users/GuillaumeDesforges/followers",
"following_url": "https://api.github.com/users/GuillaumeDesforges/following{/other_user}",
"gists_url": "https://api.github.com/users/GuillaumeDesforges/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GuillaumeDesforges/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GuillaumeDesforges/subscriptions",
"organizations_url": "https://api.github.com/users/GuillaumeDesforges/orgs",
"repos_url": "https://api.github.com/users/GuillaumeDesforges/repos",
"events_url": "https://api.github.com/users/GuillaumeDesforges/events{/privacy}",
"received_events_url": "https://api.github.com/users/GuillaumeDesforges/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T21:12:15Z",
"updated_at": "2026-05-04T21:12:15Z",
"body": "Claude Code is doing just fine with a basic prompt\r\n\r\n```\r\nHelp me set up a LLM wiki that fits my needs and workflows\r\nhttps://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f\r\n```"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133678",
"id": 6133678,
"node_id": "GC_lADOAO_nE9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdl64",
"user": {
"login": "gowtham0992",
"id": 15722259,
"node_id": "MDQ6VXNlcjE1NzIyMjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/15722259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gowtham0992",
"html_url": "https://github.com/gowtham0992",
"followers_url": "https://api.github.com/users/gowtham0992/followers",
"following_url": "https://api.github.com/users/gowtham0992/following{/other_user}",
"gists_url": "https://api.github.com/users/gowtham0992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gowtham0992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gowtham0992/subscriptions",
"organizations_url": "https://api.github.com/users/gowtham0992/orgs",
"repos_url": "https://api.github.com/users/gowtham0992/repos",
"events_url": "https://api.github.com/users/gowtham0992/events{/privacy}",
"received_events_url": "https://api.github.com/users/gowtham0992/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-04T22:44:48Z",
"updated_at": "2026-05-04T22:44:48Z",
"body": "## Link v1.0.6 + v1.0.7 are live\r\n\r\nReleased `link-mcp` v1.0.7 on PyPI and the MCP Registry.\r\n\r\nThese releases were focused on making Link feel solid for first-time users and safer for public installs.\r\n\r\nWhat changed:\r\n\r\n- Added `link.py demo` for a pre-ingested first-run wiki.\r\n- Added `link.py doctor`, `doctor --fix`, `ingest-status`, `verify-mcp`, and `rebuild-backlinks`.\r\n- Added golden demo snapshot tests and direct MCP tool contract tests.\r\n- Added CI trust gates for tests, release hygiene, version consistency, package build, and demo health.\r\n- Hardened secret/file hygiene checks before public release.\r\n- Improved Homebrew/macOS installer behavior with a dedicated `~/.link-mcp-venv` fallback.\r\n- Fixed Codex MCP auto-registration for existing `~/.codex/config.toml`.\r\n- Made `verify-mcp` validate the same Python that MCP clients actually use.\r\n- Polished the graph view with reset, labels, motion controls, cursor-centered zoom, and safer node drag/click behavior.\r\n- Restructured the README.\r\n- Fixed dashboard polish and search keyboard submission.\r\n\r\nTry Link:\r\n\r\n```bash\r\ngit clone https://github.com/gowtham0992/link.git\r\ncd link\r\npython3 link.py demo\r\ncd link-demo\r\npython3 serve.py\r\n```\r\nOpen:\r\n```\r\nhttp://localhost:3000\r\nhttp://localhost:3000/graph\r\n```\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\n\r\nPyPI: https://pypi.org/project/link-mcp/\r\n\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6133966",
"id": 6133966,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmM4",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T04:31:26Z",
"updated_at": "2026-05-05T04:31:26Z",
"body": "ΩmegaWiki(480+⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\n\r\n\r\n \r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks.\r\n\r\n
\r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks.\r\n\r\n \r\n\r\n
\r\n\r\n \r\n\r\n\r\nCome and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀\r\nhttps://github.com/skyllwt/OmegaWiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134225",
"id": 6134225,
"node_id": "GC_lADODUzaidoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmdE",
"user": {
"login": "AgriciDaniel",
"id": 223140489,
"node_id": "U_kgDODUzaiQ",
"avatar_url": "https://avatars.githubusercontent.com/u/223140489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AgriciDaniel",
"html_url": "https://github.com/AgriciDaniel",
"followers_url": "https://api.github.com/users/AgriciDaniel/followers",
"following_url": "https://api.github.com/users/AgriciDaniel/following{/other_user}",
"gists_url": "https://api.github.com/users/AgriciDaniel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AgriciDaniel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AgriciDaniel/subscriptions",
"organizations_url": "https://api.github.com/users/AgriciDaniel/orgs",
"repos_url": "https://api.github.com/users/AgriciDaniel/repos",
"events_url": "https://api.github.com/users/AgriciDaniel/events{/privacy}",
"received_events_url": "https://api.github.com/users/AgriciDaniel/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T10:27:10Z",
"updated_at": "2026-05-05T10:27:10Z",
"body": "the schema layer here resonates strongly. the gist says the schema is \"the key configuration file — it's what makes the LLM a disciplined wiki maintainer rather than a generic chatbot.\" shipped a small repo that codifies a six-axiom kernel for exactly that role.\n\nhttps://github.com/AgriciDaniel/best-practices\n\n
\r\n\r\n\r\nCome and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀\r\nhttps://github.com/skyllwt/OmegaWiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134225",
"id": 6134225,
"node_id": "GC_lADODUzaidoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmdE",
"user": {
"login": "AgriciDaniel",
"id": 223140489,
"node_id": "U_kgDODUzaiQ",
"avatar_url": "https://avatars.githubusercontent.com/u/223140489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AgriciDaniel",
"html_url": "https://github.com/AgriciDaniel",
"followers_url": "https://api.github.com/users/AgriciDaniel/followers",
"following_url": "https://api.github.com/users/AgriciDaniel/following{/other_user}",
"gists_url": "https://api.github.com/users/AgriciDaniel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AgriciDaniel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AgriciDaniel/subscriptions",
"organizations_url": "https://api.github.com/users/AgriciDaniel/orgs",
"repos_url": "https://api.github.com/users/AgriciDaniel/repos",
"events_url": "https://api.github.com/users/AgriciDaniel/events{/privacy}",
"received_events_url": "https://api.github.com/users/AgriciDaniel/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T10:27:10Z",
"updated_at": "2026-05-05T10:27:10Z",
"body": "the schema layer here resonates strongly. the gist says the schema is \"the key configuration file — it's what makes the LLM a disciplined wiki maintainer rather than a generic chatbot.\" shipped a small repo that codifies a six-axiom kernel for exactly that role.\n\nhttps://github.com/AgriciDaniel/best-practices\n\n \n\nthree layers, like the gist:\n· the stance: context over text, evidence over vibes, no agreement theater\n· the agent kernel: one chair, bounded slices, explorer / worker / verifier roles\n· the engineering kernel: read · name · small · delete · evidence · failure\n\nread first. write second. verify third.\n\n`AGENTS.md` in the repo is a portable drop-in ready to be the schema document for an LLM Wiki, codex-flavored or claude-flavored. fork, rename to CLAUDE.md, drop in. composes with obra/superpowers for the cases that need iron-law enforcement.\n\nmight save a wiki author a few hours of co-evolution. or not. either way thanks for the gist, the architecture lines up cleanly.\n\nMIT."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134229",
"id": 6134229,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmdU",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T10:31:05Z",
"updated_at": "2026-05-05T10:31:05Z",
"body": "**SwarmVault v3.7 — graph merging, source trees, video ingest, and Svelte support.** Still shipping weekly from this gist's original idea.\r\n\r\nQuick hits from the last few releases:\r\n\r\n- **Video ingest** — `swarmvault ingest --video ` or just drop a local video file. Audio gets extracted with ffmpeg, transcribed through your configured provider (cloud or local Whisper), and the transcript flows into the normal wiki/graph/search pipeline. YouTube, Loom, conference talks, whatever has audio.\r\n- **Graph merge** — `swarmvault graph merge --out combined.json` combines SwarmVault graphs with external NetworkX/node-link JSON graphs into one namespaced artifact. Useful when you want to unify your code knowledge graph with an external dependency graph or research citation network.\r\n- **Graph tree** — `swarmvault graph tree` renders a collapsible HTML source/module/symbol tree. One file, works offline, gives you the structural overview without needing the full canvas.\r\n- **`.swarmvaultignore`** — like `.gitignore` but for ingest. Control exactly what gets indexed without polluting your gitignore.\r\n- **SQL parser** — `.sql` files now get full parser-backed analysis with table/view symbols and `reads`, `writes`, `joins`, and `references` edges in the graph.\r\n- **Svelte SFCs** — single-file components with nested TypeScript/JavaScript script parsing, plus detection for Julia, Verilog/SystemVerilog, and R.\r\n- **GitHub repo sources** — `source add` and `scan` now support `--branch`, `--ref`, and `--checkout-dir`. Point `scan` at a public GitHub URL and it just works.\r\n- **Graph refresh shrink guard** — updates that would drop >25% of nodes/edges abort automatically unless you pass `--force`. Protects against accidentally nuking your graph.\r\n- **`swarmvault graph cluster`** — recompute communities, metrics, and god-node flags from an existing graph without re-ingesting.\r\n\r\nWe're at 80+ releases now. The project started as a weekend hack inspired by this gist and it's turned into a full knowledge infrastructure tool.\r\n\r\n`npx @swarmvaultai/cli demo`\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134566",
"id": 6134566,
"node_id": "GC_lADOAmYaO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmyY",
"user": {
"login": "Yarmoluk",
"id": 40245819,
"node_id": "MDQ6VXNlcjQwMjQ1ODE5",
"avatar_url": "https://avatars.githubusercontent.com/u/40245819?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yarmoluk",
"html_url": "https://github.com/Yarmoluk",
"followers_url": "https://api.github.com/users/Yarmoluk/followers",
"following_url": "https://api.github.com/users/Yarmoluk/following{/other_user}",
"gists_url": "https://api.github.com/users/Yarmoluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Yarmoluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yarmoluk/subscriptions",
"organizations_url": "https://api.github.com/users/Yarmoluk/orgs",
"repos_url": "https://api.github.com/users/Yarmoluk/repos",
"events_url": "https://api.github.com/users/Yarmoluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Yarmoluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T14:40:46Z",
"updated_at": "2026-05-05T14:40:46Z",
"body": "> This is a nice personal workflow, but the hype is way ahead of the evidence.\r\n> \r\n> There is no benchmark, no task definition, no scale curve, and no comparison against serious baselines. We do not know whether this is better than hybrid RAG, BM25 plus reranking, vector search, GraphRAG, hierarchical summaries, long-context prompting, NotebookLM, Perplexity Spaces, or ChatGPT Projects. Calling it a new architecture without that evidence is premature.\r\n> \r\n> The core problem is that an LLM Wiki is lossy compression. You take raw documents and rewrite them into derived wiki pages. That may be useful for a small curated corpus, but it can also drop caveats, dates, minority views, exact wording, edge cases, and source context. Once people start querying the wiki instead of the original material, summary errors become part of the knowledge base.\r\n> \r\n> Updates are also not solved. Adding one new source can affect many entity pages, concept pages, timelines, summaries, and indexes. At scale, this becomes graph maintenance: detecting what changed, resolving conflicts, avoiding duplicates, preserving provenance, preventing stale claims, and not silently breaking old pages. “Ask the LLM to maintain it” is not an engineering solution unless there are validators, source hashes, span-level citations, regression tests, and human review.\r\n> \r\n> It also does not remove retrieval. Once the wiki grows beyond a modest size, you still need search, ranking, indexing, reranking, chunking, and access control. At that point the markdown wiki is just another indexed corpus, not a replacement for RAG.\r\n> \r\n> The production issues are mostly ignored: permissions, multi-user edits, audit logs, rollback, deletion, sensitive data, source versioning, concurrency, compliance, cost, latency, and update frequency. These are not small details; they are exactly where knowledge-base systems fail.\r\n> \r\n> So the reasonable claim is narrow: this can be a useful workflow for small-to-medium, slow-moving, human-curated research folders. It is much less convincing for large, fast-changing, high-stakes, multi-user, or enterprise knowledge bases.\r\n> \r\n> The idea is fine. The framing is the problem. Without benchmarks, baselines, provenance guarantees, update-evaluation tests, and clear boundary conditions, “LLM Wiki” is mostly a good name for a familiar pattern, not proof that RAG is obsolete.\r\n\r\nWe ran exactly these comparisons -- BERT F1, token economics, cross RAG comparison -- https://github.com/Yarmoluk/ckg-benchmark/blob/main/paper/main.pdf"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134568",
"id": 6134568,
"node_id": "GC_lADODAIwv9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmyg",
"user": {
"login": "ColonelPanicX",
"id": 201470143,
"node_id": "U_kgDODAIwvw",
"avatar_url": "https://avatars.githubusercontent.com/u/201470143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ColonelPanicX",
"html_url": "https://github.com/ColonelPanicX",
"followers_url": "https://api.github.com/users/ColonelPanicX/followers",
"following_url": "https://api.github.com/users/ColonelPanicX/following{/other_user}",
"gists_url": "https://api.github.com/users/ColonelPanicX/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ColonelPanicX/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ColonelPanicX/subscriptions",
"organizations_url": "https://api.github.com/users/ColonelPanicX/orgs",
"repos_url": "https://api.github.com/users/ColonelPanicX/repos",
"events_url": "https://api.github.com/users/ColonelPanicX/events{/privacy}",
"received_events_url": "https://api.github.com/users/ColonelPanicX/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T14:41:39Z",
"updated_at": "2026-05-05T14:41:39Z",
"body": "The schema observation is underrated. The difference between an LLM that maintains a wiki and one that just answers questions in a wiki-shaped directory is almost entirely that file.\r\n\r\nI ran into the same consistency problem across projects (not just wikis) and ended up building scaffy (https://github.com/ColonelPanicX/scaffy), which is a dead simple python script that bootstraps the schema layer for any project: collaboration contract, session protocols, kanban, agent profiles, etc.\r\n\r\nThe idea is that every project gets the same guardrails so the LLM isn't relearning the rules each session. Works well as a starting point for the setup that Karpathy described here.\r\n\r\n
\n\nthree layers, like the gist:\n· the stance: context over text, evidence over vibes, no agreement theater\n· the agent kernel: one chair, bounded slices, explorer / worker / verifier roles\n· the engineering kernel: read · name · small · delete · evidence · failure\n\nread first. write second. verify third.\n\n`AGENTS.md` in the repo is a portable drop-in ready to be the schema document for an LLM Wiki, codex-flavored or claude-flavored. fork, rename to CLAUDE.md, drop in. composes with obra/superpowers for the cases that need iron-law enforcement.\n\nmight save a wiki author a few hours of co-evolution. or not. either way thanks for the gist, the architecture lines up cleanly.\n\nMIT."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134229",
"id": 6134229,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmdU",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T10:31:05Z",
"updated_at": "2026-05-05T10:31:05Z",
"body": "**SwarmVault v3.7 — graph merging, source trees, video ingest, and Svelte support.** Still shipping weekly from this gist's original idea.\r\n\r\nQuick hits from the last few releases:\r\n\r\n- **Video ingest** — `swarmvault ingest --video ` or just drop a local video file. Audio gets extracted with ffmpeg, transcribed through your configured provider (cloud or local Whisper), and the transcript flows into the normal wiki/graph/search pipeline. YouTube, Loom, conference talks, whatever has audio.\r\n- **Graph merge** — `swarmvault graph merge --out combined.json` combines SwarmVault graphs with external NetworkX/node-link JSON graphs into one namespaced artifact. Useful when you want to unify your code knowledge graph with an external dependency graph or research citation network.\r\n- **Graph tree** — `swarmvault graph tree` renders a collapsible HTML source/module/symbol tree. One file, works offline, gives you the structural overview without needing the full canvas.\r\n- **`.swarmvaultignore`** — like `.gitignore` but for ingest. Control exactly what gets indexed without polluting your gitignore.\r\n- **SQL parser** — `.sql` files now get full parser-backed analysis with table/view symbols and `reads`, `writes`, `joins`, and `references` edges in the graph.\r\n- **Svelte SFCs** — single-file components with nested TypeScript/JavaScript script parsing, plus detection for Julia, Verilog/SystemVerilog, and R.\r\n- **GitHub repo sources** — `source add` and `scan` now support `--branch`, `--ref`, and `--checkout-dir`. Point `scan` at a public GitHub URL and it just works.\r\n- **Graph refresh shrink guard** — updates that would drop >25% of nodes/edges abort automatically unless you pass `--force`. Protects against accidentally nuking your graph.\r\n- **`swarmvault graph cluster`** — recompute communities, metrics, and god-node flags from an existing graph without re-ingesting.\r\n\r\nWe're at 80+ releases now. The project started as a weekend hack inspired by this gist and it's turned into a full knowledge infrastructure tool.\r\n\r\n`npx @swarmvaultai/cli demo`\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134566",
"id": 6134566,
"node_id": "GC_lADOAmYaO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmyY",
"user": {
"login": "Yarmoluk",
"id": 40245819,
"node_id": "MDQ6VXNlcjQwMjQ1ODE5",
"avatar_url": "https://avatars.githubusercontent.com/u/40245819?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yarmoluk",
"html_url": "https://github.com/Yarmoluk",
"followers_url": "https://api.github.com/users/Yarmoluk/followers",
"following_url": "https://api.github.com/users/Yarmoluk/following{/other_user}",
"gists_url": "https://api.github.com/users/Yarmoluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Yarmoluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yarmoluk/subscriptions",
"organizations_url": "https://api.github.com/users/Yarmoluk/orgs",
"repos_url": "https://api.github.com/users/Yarmoluk/repos",
"events_url": "https://api.github.com/users/Yarmoluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Yarmoluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T14:40:46Z",
"updated_at": "2026-05-05T14:40:46Z",
"body": "> This is a nice personal workflow, but the hype is way ahead of the evidence.\r\n> \r\n> There is no benchmark, no task definition, no scale curve, and no comparison against serious baselines. We do not know whether this is better than hybrid RAG, BM25 plus reranking, vector search, GraphRAG, hierarchical summaries, long-context prompting, NotebookLM, Perplexity Spaces, or ChatGPT Projects. Calling it a new architecture without that evidence is premature.\r\n> \r\n> The core problem is that an LLM Wiki is lossy compression. You take raw documents and rewrite them into derived wiki pages. That may be useful for a small curated corpus, but it can also drop caveats, dates, minority views, exact wording, edge cases, and source context. Once people start querying the wiki instead of the original material, summary errors become part of the knowledge base.\r\n> \r\n> Updates are also not solved. Adding one new source can affect many entity pages, concept pages, timelines, summaries, and indexes. At scale, this becomes graph maintenance: detecting what changed, resolving conflicts, avoiding duplicates, preserving provenance, preventing stale claims, and not silently breaking old pages. “Ask the LLM to maintain it” is not an engineering solution unless there are validators, source hashes, span-level citations, regression tests, and human review.\r\n> \r\n> It also does not remove retrieval. Once the wiki grows beyond a modest size, you still need search, ranking, indexing, reranking, chunking, and access control. At that point the markdown wiki is just another indexed corpus, not a replacement for RAG.\r\n> \r\n> The production issues are mostly ignored: permissions, multi-user edits, audit logs, rollback, deletion, sensitive data, source versioning, concurrency, compliance, cost, latency, and update frequency. These are not small details; they are exactly where knowledge-base systems fail.\r\n> \r\n> So the reasonable claim is narrow: this can be a useful workflow for small-to-medium, slow-moving, human-curated research folders. It is much less convincing for large, fast-changing, high-stakes, multi-user, or enterprise knowledge bases.\r\n> \r\n> The idea is fine. The framing is the problem. Without benchmarks, baselines, provenance guarantees, update-evaluation tests, and clear boundary conditions, “LLM Wiki” is mostly a good name for a familiar pattern, not proof that RAG is obsolete.\r\n\r\nWe ran exactly these comparisons -- BERT F1, token economics, cross RAG comparison -- https://github.com/Yarmoluk/ckg-benchmark/blob/main/paper/main.pdf"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134568",
"id": 6134568,
"node_id": "GC_lADODAIwv9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmyg",
"user": {
"login": "ColonelPanicX",
"id": 201470143,
"node_id": "U_kgDODAIwvw",
"avatar_url": "https://avatars.githubusercontent.com/u/201470143?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ColonelPanicX",
"html_url": "https://github.com/ColonelPanicX",
"followers_url": "https://api.github.com/users/ColonelPanicX/followers",
"following_url": "https://api.github.com/users/ColonelPanicX/following{/other_user}",
"gists_url": "https://api.github.com/users/ColonelPanicX/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ColonelPanicX/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ColonelPanicX/subscriptions",
"organizations_url": "https://api.github.com/users/ColonelPanicX/orgs",
"repos_url": "https://api.github.com/users/ColonelPanicX/repos",
"events_url": "https://api.github.com/users/ColonelPanicX/events{/privacy}",
"received_events_url": "https://api.github.com/users/ColonelPanicX/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T14:41:39Z",
"updated_at": "2026-05-05T14:41:39Z",
"body": "The schema observation is underrated. The difference between an LLM that maintains a wiki and one that just answers questions in a wiki-shaped directory is almost entirely that file.\r\n\r\nI ran into the same consistency problem across projects (not just wikis) and ended up building scaffy (https://github.com/ColonelPanicX/scaffy), which is a dead simple python script that bootstraps the schema layer for any project: collaboration contract, session protocols, kanban, agent profiles, etc.\r\n\r\nThe idea is that every project gets the same guardrails so the LLM isn't relearning the rules each session. Works well as a starting point for the setup that Karpathy described here.\r\n\r\n \r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134573",
"id": 6134573,
"node_id": "GC_lADOANMWMNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmy0",
"user": {
"login": "lrdeoliveira",
"id": 13833776,
"node_id": "MDQ6VXNlcjEzODMzNzc2",
"avatar_url": "https://avatars.githubusercontent.com/u/13833776?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lrdeoliveira",
"html_url": "https://github.com/lrdeoliveira",
"followers_url": "https://api.github.com/users/lrdeoliveira/followers",
"following_url": "https://api.github.com/users/lrdeoliveira/following{/other_user}",
"gists_url": "https://api.github.com/users/lrdeoliveira/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lrdeoliveira/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lrdeoliveira/subscriptions",
"organizations_url": "https://api.github.com/users/lrdeoliveira/orgs",
"repos_url": "https://api.github.com/users/lrdeoliveira/repos",
"events_url": "https://api.github.com/users/lrdeoliveira/events{/privacy}",
"received_events_url": "https://api.github.com/users/lrdeoliveira/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T14:42:32Z",
"updated_at": "2026-05-05T14:42:32Z",
"body": "Hi Andrej,\r\n\r\nYour LLM Wiki gist (https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f) became the foundation of our project — **NEXUS**, a multi-agent memory system running on a VPS with 6 AI agents.\r\n\r\n## What we built\r\n\r\nNEXUS implements your 3-layer pattern:\r\n- **Raw sources** — immutable source documents (32 files)\r\n- **Wiki** — LLM-generated markdown pages (entities, concepts, sources)\r\n- **Schema** — CLAUDE.md / SOUL.md files that define agent identity and workflows\r\n\r\n## Stack\r\n- 6 AI agents on VPS\r\n- Weaviate (vector DB) + Ollama (local LLM) + Wiki.js\r\n- GraphRAG with typed schema (Source, Concept, Agent, Project)\r\n- Skills system, session logging, compression with OpenRouter\r\n- MCP servers: Brave Search, Tavily, YouTube, Apify, MiniMax, Slack, qmd\r\n\r\n## The key insight that changed everything for us\r\n\r\n> \"The wiki is a persistent, compounding artifact. The cross-references are already there. The contradictions have already been flagged. The synthesis already reflects everything you've read.\"\r\n\r\nThis transformed how we think about agent memory. Instead of RAG re-deriving context every time, we compound knowledge session over session.\r\n\r\n## Gratitude\r\n\r\nThank you for sharing this pattern. The idea of \"wiki as a persistent, compounding artifact\" instead of another RAG layer that re-derives context every time — this was the insight that changed everything for us.\r\n\r\nWe saw your gist on May 1, 2026. By May 5, we had NEXUS running in production with 6 agents, GraphRAG, and full memory persistence.\r\n\r\nThe ecosystem you inspired is impressive: Kompl, SwarmVault, Aura, llmwiki-cli, ΩmegaWiki, Link. Every one of them took the same pattern and made it their own.\r\n\r\nThank you for planting the seed\r\n\r\n> \"The wiki is a persistent, compounding artifact. The cross-references are already there. The contradictions have already been flagged. The synthesis already reflects everything you've read.\"\r\n\r\nLuciano - https://github.com/lrdeoliveira/nexus-ai-memory"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6135236",
"id": 6135236,
"node_id": "GC_lADOCGHfANoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdncQ",
"user": {
"login": "simonsysun",
"id": 140631808,
"node_id": "U_kgDOCGHfAA",
"avatar_url": "https://avatars.githubusercontent.com/u/140631808?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simonsysun",
"html_url": "https://github.com/simonsysun",
"followers_url": "https://api.github.com/users/simonsysun/followers",
"following_url": "https://api.github.com/users/simonsysun/following{/other_user}",
"gists_url": "https://api.github.com/users/simonsysun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/simonsysun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simonsysun/subscriptions",
"organizations_url": "https://api.github.com/users/simonsysun/orgs",
"repos_url": "https://api.github.com/users/simonsysun/repos",
"events_url": "https://api.github.com/users/simonsysun/events{/privacy}",
"received_events_url": "https://api.github.com/users/simonsysun/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T21:24:24Z",
"updated_at": "2026-05-05T21:24:24Z",
"body": "For larger Markdown wikis, line-anchored local retrieval before edits becomes a real bottleneck: agents need to read the exact lines they're about to touch, not whole files.\r\n\r\nI built SeekLink for that loop: index a local `.md` vault, search semantically, then fetch a specific `PATH:LINE` window.\r\n\r\n```bash\r\nseeklink index --vault ./wiki\r\nseeklink search \"why SQLite for search?\" --vault ./wiki --json\r\nseeklink get decisions/search.md:42 -C 20 --vault ./wiki # 20 lines of context\r\n```\r\n\r\nPlain subprocess interface, JSON stdout, local-only.\r\n\r\nhttps://github.com/simonsysun/seeklink"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6135385",
"id": 6135385,
"node_id": "GC_lADOAAUS8toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdnlk",
"user": {
"login": "medha",
"id": 332530,
"node_id": "MDQ6VXNlcjMzMjUzMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/332530?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/medha",
"html_url": "https://github.com/medha",
"followers_url": "https://api.github.com/users/medha/followers",
"following_url": "https://api.github.com/users/medha/following{/other_user}",
"gists_url": "https://api.github.com/users/medha/gists{/gist_id}",
"starred_url": "https://api.github.com/users/medha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/medha/subscriptions",
"organizations_url": "https://api.github.com/users/medha/orgs",
"repos_url": "https://api.github.com/users/medha/repos",
"events_url": "https://api.github.com/users/medha/events{/privacy}",
"received_events_url": "https://api.github.com/users/medha/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T23:04:09Z",
"updated_at": "2026-05-05T23:04:50Z",
"body": "As my contribution to the discussion - I built Keel, a Mac app where your knowledge stays as plain markdown on disk and the model is swappable http://github.com/Keel-Labs/keel (free, open source) - it's biased toward local-first and own-your-context. \r\n\r\n▶ [Keel Walkthrough 🚀 — Watch Video](https://www.loom.com/share/29c1407fc2944b1fb5c6c1bbc953831b)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6135386",
"id": 6135386,
"node_id": "GC_lADOAB2DQtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdnlo",
"user": {
"login": "ethanj",
"id": 1934146,
"node_id": "MDQ6VXNlcjE5MzQxNDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1934146?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ethanj",
"html_url": "https://github.com/ethanj",
"followers_url": "https://api.github.com/users/ethanj/followers",
"following_url": "https://api.github.com/users/ethanj/following{/other_user}",
"gists_url": "https://api.github.com/users/ethanj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ethanj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ethanj/subscriptions",
"organizations_url": "https://api.github.com/users/ethanj/orgs",
"repos_url": "https://api.github.com/users/ethanj/repos",
"events_url": "https://api.github.com/users/ethanj/events{/privacy}",
"received_events_url": "https://api.github.com/users/ethanj/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T23:04:55Z",
"updated_at": "2026-05-05T23:04:55Z",
"body": "Huge milestone from this thread: `llmwiki` just crossed 1K GitHub stars (and 100 forks)!\r\n
\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6134573",
"id": 6134573,
"node_id": "GC_lADOANMWMNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdmy0",
"user": {
"login": "lrdeoliveira",
"id": 13833776,
"node_id": "MDQ6VXNlcjEzODMzNzc2",
"avatar_url": "https://avatars.githubusercontent.com/u/13833776?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lrdeoliveira",
"html_url": "https://github.com/lrdeoliveira",
"followers_url": "https://api.github.com/users/lrdeoliveira/followers",
"following_url": "https://api.github.com/users/lrdeoliveira/following{/other_user}",
"gists_url": "https://api.github.com/users/lrdeoliveira/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lrdeoliveira/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lrdeoliveira/subscriptions",
"organizations_url": "https://api.github.com/users/lrdeoliveira/orgs",
"repos_url": "https://api.github.com/users/lrdeoliveira/repos",
"events_url": "https://api.github.com/users/lrdeoliveira/events{/privacy}",
"received_events_url": "https://api.github.com/users/lrdeoliveira/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T14:42:32Z",
"updated_at": "2026-05-05T14:42:32Z",
"body": "Hi Andrej,\r\n\r\nYour LLM Wiki gist (https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f) became the foundation of our project — **NEXUS**, a multi-agent memory system running on a VPS with 6 AI agents.\r\n\r\n## What we built\r\n\r\nNEXUS implements your 3-layer pattern:\r\n- **Raw sources** — immutable source documents (32 files)\r\n- **Wiki** — LLM-generated markdown pages (entities, concepts, sources)\r\n- **Schema** — CLAUDE.md / SOUL.md files that define agent identity and workflows\r\n\r\n## Stack\r\n- 6 AI agents on VPS\r\n- Weaviate (vector DB) + Ollama (local LLM) + Wiki.js\r\n- GraphRAG with typed schema (Source, Concept, Agent, Project)\r\n- Skills system, session logging, compression with OpenRouter\r\n- MCP servers: Brave Search, Tavily, YouTube, Apify, MiniMax, Slack, qmd\r\n\r\n## The key insight that changed everything for us\r\n\r\n> \"The wiki is a persistent, compounding artifact. The cross-references are already there. The contradictions have already been flagged. The synthesis already reflects everything you've read.\"\r\n\r\nThis transformed how we think about agent memory. Instead of RAG re-deriving context every time, we compound knowledge session over session.\r\n\r\n## Gratitude\r\n\r\nThank you for sharing this pattern. The idea of \"wiki as a persistent, compounding artifact\" instead of another RAG layer that re-derives context every time — this was the insight that changed everything for us.\r\n\r\nWe saw your gist on May 1, 2026. By May 5, we had NEXUS running in production with 6 agents, GraphRAG, and full memory persistence.\r\n\r\nThe ecosystem you inspired is impressive: Kompl, SwarmVault, Aura, llmwiki-cli, ΩmegaWiki, Link. Every one of them took the same pattern and made it their own.\r\n\r\nThank you for planting the seed\r\n\r\n> \"The wiki is a persistent, compounding artifact. The cross-references are already there. The contradictions have already been flagged. The synthesis already reflects everything you've read.\"\r\n\r\nLuciano - https://github.com/lrdeoliveira/nexus-ai-memory"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6135236",
"id": 6135236,
"node_id": "GC_lADOCGHfANoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdncQ",
"user": {
"login": "simonsysun",
"id": 140631808,
"node_id": "U_kgDOCGHfAA",
"avatar_url": "https://avatars.githubusercontent.com/u/140631808?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simonsysun",
"html_url": "https://github.com/simonsysun",
"followers_url": "https://api.github.com/users/simonsysun/followers",
"following_url": "https://api.github.com/users/simonsysun/following{/other_user}",
"gists_url": "https://api.github.com/users/simonsysun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/simonsysun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simonsysun/subscriptions",
"organizations_url": "https://api.github.com/users/simonsysun/orgs",
"repos_url": "https://api.github.com/users/simonsysun/repos",
"events_url": "https://api.github.com/users/simonsysun/events{/privacy}",
"received_events_url": "https://api.github.com/users/simonsysun/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T21:24:24Z",
"updated_at": "2026-05-05T21:24:24Z",
"body": "For larger Markdown wikis, line-anchored local retrieval before edits becomes a real bottleneck: agents need to read the exact lines they're about to touch, not whole files.\r\n\r\nI built SeekLink for that loop: index a local `.md` vault, search semantically, then fetch a specific `PATH:LINE` window.\r\n\r\n```bash\r\nseeklink index --vault ./wiki\r\nseeklink search \"why SQLite for search?\" --vault ./wiki --json\r\nseeklink get decisions/search.md:42 -C 20 --vault ./wiki # 20 lines of context\r\n```\r\n\r\nPlain subprocess interface, JSON stdout, local-only.\r\n\r\nhttps://github.com/simonsysun/seeklink"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6135385",
"id": 6135385,
"node_id": "GC_lADOAAUS8toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdnlk",
"user": {
"login": "medha",
"id": 332530,
"node_id": "MDQ6VXNlcjMzMjUzMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/332530?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/medha",
"html_url": "https://github.com/medha",
"followers_url": "https://api.github.com/users/medha/followers",
"following_url": "https://api.github.com/users/medha/following{/other_user}",
"gists_url": "https://api.github.com/users/medha/gists{/gist_id}",
"starred_url": "https://api.github.com/users/medha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/medha/subscriptions",
"organizations_url": "https://api.github.com/users/medha/orgs",
"repos_url": "https://api.github.com/users/medha/repos",
"events_url": "https://api.github.com/users/medha/events{/privacy}",
"received_events_url": "https://api.github.com/users/medha/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T23:04:09Z",
"updated_at": "2026-05-05T23:04:50Z",
"body": "As my contribution to the discussion - I built Keel, a Mac app where your knowledge stays as plain markdown on disk and the model is swappable http://github.com/Keel-Labs/keel (free, open source) - it's biased toward local-first and own-your-context. \r\n\r\n▶ [Keel Walkthrough 🚀 — Watch Video](https://www.loom.com/share/29c1407fc2944b1fb5c6c1bbc953831b)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6135386",
"id": 6135386,
"node_id": "GC_lADOAB2DQtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdnlo",
"user": {
"login": "ethanj",
"id": 1934146,
"node_id": "MDQ6VXNlcjE5MzQxNDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1934146?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ethanj",
"html_url": "https://github.com/ethanj",
"followers_url": "https://api.github.com/users/ethanj/followers",
"following_url": "https://api.github.com/users/ethanj/following{/other_user}",
"gists_url": "https://api.github.com/users/ethanj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ethanj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ethanj/subscriptions",
"organizations_url": "https://api.github.com/users/ethanj/orgs",
"repos_url": "https://api.github.com/users/ethanj/repos",
"events_url": "https://api.github.com/users/ethanj/events{/privacy}",
"received_events_url": "https://api.github.com/users/ethanj/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-05T23:04:55Z",
"updated_at": "2026-05-05T23:04:55Z",
"body": "Huge milestone from this thread: `llmwiki` just crossed 1K GitHub stars (and 100 forks)!\r\n \r\n\r\n\r\nI built it because Andrej's LLM Wiki gist felt immediately useful, but I wanted the idea to be boringly concrete... a local CLI, plain files, immutable sources, generated markdown, provenance, linting, exports, and agent access.\r\n\r\nThe project now has:\r\n\r\n- `compile --review` so generated pages can be approved or rejected before landing\r\n- claim-level provenance like `^[paper.md:42-58]`\r\n- typed schema/page kinds and seed pages\r\n- confidence and contradiction metadata\r\n- image/PDF/transcript ingest\r\n- chunked retrieval with BM25 reranking\r\n- `llms.txt`, JSON-LD, GraphML, and Marp exports\r\n- MCP tools\r\n- Claude/Codex/Cursor session ingest\r\n\r\nThe part that still feels most useful to me is how the knowledge builds up over time... add sources, improve the wiki, ask better questions, save better answers, and the next agent starts fully informed instead of another empty chat window.\r\n\r\nThe roadmap is now focused on the parts that make this real at scale... local web UI, graph/context packs, evals, and rollback/audit.\r\n\r\nThanks to everyone who has tried it, filed issues, opened PRs, or posted competing implementations here. This thread has been our best product research.\r\n\r\nhttps://github.com/atomicmemory/llm-wiki-compiler"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6136137",
"id": 6136137,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdoUk",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-06T10:43:38Z",
"updated_at": "2026-05-06T10:43:38Z",
"body": "**SwarmVault v3.12 — you can now chat with your vault and export it for any AI.** The project just keeps growing from this gist.\r\n\r\nTwo big new surfaces in the latest releases:\r\n\r\n**`swarmvault chat` — persistent multi-turn conversations over your compiled wiki.**\r\n\r\nInstead of one-shot queries, you can now have an ongoing conversation with your vault. Sessions persist, so you can resume where you left off. It works in interactive TTY mode or programmatically. Your chat history becomes part of the vault's knowledge.\r\n\r\n```\r\nswarmvault chat\r\nswarmvault chat --resume \r\nswarmvault chat --list\r\n```\r\n\r\n**`swarmvault export ai` — static handoff packs for any AI tool.**\r\n\r\nExports your vault as a portable bundle with `llms.txt`, full text, JSON-LD graph data, manifest metadata, and human-readable notes. Hand your compiled knowledge to any AI system, not just the ones SwarmVault integrates with directly. Per-page siblings optional.\r\n\r\nOther recent additions:\r\n\r\n- **Graph validation** — `swarmvault graph validate [--strict]` checks for duplicate IDs, dangling references, confidence bounds, and inconsistent edge evidence. Like a linter for your knowledge graph.\r\n- **Neo4j export** — `graph export --neo4j` for loading your vault graph into Neo4j.\r\n- **`swarmvault clone `** — one-command vault creation from a repo URL or directory. Alias for scan with a cleaner mental model.\r\n- **`swarmvault scan --mcp`** — build a vault and immediately start the MCP stdio server. One command from source to agent-ready.\r\n- **Graph stats** — `swarmvault graph stats` for quick local counts, node types, evidence classes, and top relations without starting the viewer.\r\n\r\nThe original gist was about turning an LLM into a wiki maintainer. SwarmVault now does that plus lets you chat with the result, hand it off to any AI, validate the graph, and export to Neo4j. 90+ releases deep.\r\n\r\n`npx @swarmvaultai/cli demo`\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137341",
"id": 6137341,
"node_id": "GC_lADOAPIx79oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdpf0",
"user": {
"login": "yazanabuashour",
"id": 15872495,
"node_id": "MDQ6VXNlcjE1ODcyNDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/15872495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yazanabuashour",
"html_url": "https://github.com/yazanabuashour",
"followers_url": "https://api.github.com/users/yazanabuashour/followers",
"following_url": "https://api.github.com/users/yazanabuashour/following{/other_user}",
"gists_url": "https://api.github.com/users/yazanabuashour/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yazanabuashour/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yazanabuashour/subscriptions",
"organizations_url": "https://api.github.com/users/yazanabuashour/orgs",
"repos_url": "https://api.github.com/users/yazanabuashour/repos",
"events_url": "https://api.github.com/users/yazanabuashour/events{/privacy}",
"received_events_url": "https://api.github.com/users/yazanabuashour/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T00:45:06Z",
"updated_at": "2026-05-07T00:45:06Z",
"body": "The @a-a-k criticism is the right frame. Most implementations here solve accumulation but defer the hard part: staleness, provenance, silent duplicates.\r\n\r\nOpenClerk's approach to those specifically: synthesis pages carry explicit freshness state and go stale when sources update. Retrieval results have doc_id/chunk_id on every result by contract. Duplicate candidates surface via a read-only report with agent_handoff; no silent second document.\r\n\r\nThe other angle missing from this thread: [building block economy](https://mitchellh.com/writing/building-block-economy) as a hard constraint. Semantic search, OCR, embeddings are optional installed modules. The core runner stays narrow.\r\n\r\nAll releases are eval-gated: https://github.com/yazanabuashour/openclerk"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137544",
"id": 6137544,
"node_id": "GC_lADODRFKJdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdpsg",
"user": {
"login": "luxurystorecc1",
"id": 219236901,
"node_id": "U_kgDODRFKJQ",
"avatar_url": "https://avatars.githubusercontent.com/u/219236901?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/luxurystorecc1",
"html_url": "https://github.com/luxurystorecc1",
"followers_url": "https://api.github.com/users/luxurystorecc1/followers",
"following_url": "https://api.github.com/users/luxurystorecc1/following{/other_user}",
"gists_url": "https://api.github.com/users/luxurystorecc1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/luxurystorecc1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/luxurystorecc1/subscriptions",
"organizations_url": "https://api.github.com/users/luxurystorecc1/orgs",
"repos_url": "https://api.github.com/users/luxurystorecc1/repos",
"events_url": "https://api.github.com/users/luxurystorecc1/events{/privacy}",
"received_events_url": "https://api.github.com/users/luxurystorecc1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T02:31:48Z",
"updated_at": "2026-05-07T02:31:48Z",
"body": "Cultural Capital: The Value of Heritage Design in a Tech-Driven World\r\nIntroduction: The Enduring Power of the Icon\r\nIn the high-tech landscape of 2026, \"Cultural Capital\" has become as valuable as financial capital. Owning items with a deep heritage and a story to tell provides a sense of grounding and prestige. The [Air Jordan 1 retro high OG sneakers](https://www.airjordan-1.com/) are the ultimate repository of cultural capital, representing a 40-year legacy of excellence that remains more relevant today than ever before.\r\n\r\nHeritage Meets Modern Engineering\r\nThe value of heritage design lies in its ability to adapt without losing its soul. The [Jordan 1s high-performance basketball shoes](https://www.jordan1s.com/) utilize the same iconic silhouette from 1985 but are engineered with 2026’s most advanced materials. For those who prioritize rarity and historical narrative, [retro Jordan 1 limited editions](https://www.jordan1s.com/) serve as unique artifacts of style that command respect in any setting.\r\n\r\nThis balance is also found in the [adidas Yeezy boost collection](https://www.yeezyboost-350.com/collections/adidas-yeezy), which has created its own modern heritage through minimalist innovation. The popularity of [comfortable Yeezy slides and foam runners](https://www.yeezyboost-350.com/) highlights a shift toward \"New Heritage\"—designs that are destined to become the classics of the next generation.\r\n\r\nAuthenticity as a Cultural Marker\r\nIn the world of sports, authenticity is the primary source of cultural capital. Serious fans turn to the [official NFL shop online store](https://www.nflshopofficialonline-store.com/) to ensure their gear is genuine and carries the weight of the professional league. A [customized replica NFL jersey](https://www.nflshopofficialonline-store.com/collections/custom-nfl-jersey) allows fans to add their own chapter to their team's long-standing heritage.\r\n\r\nHeritage is also expressed through the iconic [Spain national team soccer jersey](https://www.soccerjerseysstore.com/collections/national-teams-europe-spain) and the evolving tradition of [MLS jerseys for soccer fans](https://www.soccerjerseysstore.com/collections/national-teams). Completing the look with [NFL headwear and official team caps](https://www.cheapnfl-jerseys.com/collections/headwear-nfl-headwear) from reputable sources ensures that your cultural capital is built on a foundation of true quality.\r\n\r\nPerformance Luxury: The Peter Millar Standard\r\nFor those who move in elite social and professional circles, [Peter Millar performance golf apparel](https://www.peter-milla.com/) represents the heritage of the gentleman athlete. These garments combine classic style with modern technical performance, offering a timeless aesthetic for the contemporary leader. The [Peter Millar clothing for men](https://www.peter-milla.com/) line continues to define the pinnacle of cultural capital in apparel."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137724",
"id": 6137724,
"node_id": "GC_lADOAEkH8toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdp3w",
"user": {
"login": "alirezabbasi",
"id": 4786162,
"node_id": "MDQ6VXNlcjQ3ODYxNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4786162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alirezabbasi",
"html_url": "https://github.com/alirezabbasi",
"followers_url": "https://api.github.com/users/alirezabbasi/followers",
"following_url": "https://api.github.com/users/alirezabbasi/following{/other_user}",
"gists_url": "https://api.github.com/users/alirezabbasi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alirezabbasi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alirezabbasi/subscriptions",
"organizations_url": "https://api.github.com/users/alirezabbasi/orgs",
"repos_url": "https://api.github.com/users/alirezabbasi/repos",
"events_url": "https://api.github.com/users/alirezabbasi/events{/privacy}",
"received_events_url": "https://api.github.com/users/alirezabbasi/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T04:48:30Z",
"updated_at": "2026-05-10T22:08:37Z",
"body": "A month before Andrej Karpathy published the “LLM Wiki” idea file, I started building a system called Eshel while working on NITRA — an AI-native trading infrastructure project. During development, I realized the real bottleneck was not code generation itself, but the constant decay of architectural knowledge, engineering decisions, workflows, standards, and context across the lifetime of a project.\r\n\r\nEshel evolved from that realization. It extends the LLM Wiki concept beyond passive knowledge accumulation into a persistent engineering intelligence layer for software systems. Instead of treating documentation as static artifacts or relying on retrieval over fragmented chats and files, Eshel continuously compiles project knowledge into a living Obsidian-compatible wiki that evolves alongside the codebase. Architecture, coding standards, implementation details, workflows, technical debt, decisions, investigations, and even development methodologies become interconnected, continuously updated entities maintained by the LLM during daily engineering work.\r\n\r\nThe goal is not “AI documentation.” The goal is an AI-native SDLC where knowledge compounds instead of decaying.\r\n\r\nKarpathy’s LLM Wiki crystallized many of the same ideas independently, which was exciting to see. Eshel attempts to push the pattern further into production-oriented software engineering: evolving standards, deterministic workflows, task generation, architecture governance, contradiction detection, linting, and persistent project memory integrated directly into development itself.\r\n\r\nThe project is still evolving, but the repository already contains the foundational scaffold, schema system, Codex workflows, Obsidian-ready wiki structure, and automation model for experimenting with this style of development. I’d genuinely love feedback from people exploring similar directions around persistent AI-assisted engineering systems and compounding project intelligence.\r\n\r\nGithub:\r\nhttps://github.com/alirezabbasi/echel"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137753",
"id": 6137753,
"node_id": "GC_lADOENYEO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdp5k",
"user": {
"login": "kongphobphinduang731-maker",
"id": 282461243,
"node_id": "U_kgDOENYEOw",
"avatar_url": "https://avatars.githubusercontent.com/u/282461243?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kongphobphinduang731-maker",
"html_url": "https://github.com/kongphobphinduang731-maker",
"followers_url": "https://api.github.com/users/kongphobphinduang731-maker/followers",
"following_url": "https://api.github.com/users/kongphobphinduang731-maker/following{/other_user}",
"gists_url": "https://api.github.com/users/kongphobphinduang731-maker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kongphobphinduang731-maker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kongphobphinduang731-maker/subscriptions",
"organizations_url": "https://api.github.com/users/kongphobphinduang731-maker/orgs",
"repos_url": "https://api.github.com/users/kongphobphinduang731-maker/repos",
"events_url": "https://api.github.com/users/kongphobphinduang731-maker/events{/privacy}",
"received_events_url": "https://api.github.com/users/kongphobphinduang731-maker/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T05:15:54Z",
"updated_at": "2026-05-07T05:15:54Z",
"body": "githubfriend. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137896",
"id": 6137896,
"node_id": "GC_lADOENaZMdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqCg",
"user": {
"login": "napaputteppawan-netizen",
"id": 282499377,
"node_id": "U_kgDOENaZMQ",
"avatar_url": "https://avatars.githubusercontent.com/u/282499377?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/napaputteppawan-netizen",
"html_url": "https://github.com/napaputteppawan-netizen",
"followers_url": "https://api.github.com/users/napaputteppawan-netizen/followers",
"following_url": "https://api.github.com/users/napaputteppawan-netizen/following{/other_user}",
"gists_url": "https://api.github.com/users/napaputteppawan-netizen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/napaputteppawan-netizen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/napaputteppawan-netizen/subscriptions",
"organizations_url": "https://api.github.com/users/napaputteppawan-netizen/orgs",
"repos_url": "https://api.github.com/users/napaputteppawan-netizen/repos",
"events_url": "https://api.github.com/users/napaputteppawan-netizen/events{/privacy}",
"received_events_url": "https://api.github.com/users/napaputteppawan-netizen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T07:40:17Z",
"updated_at": "2026-05-07T07:40:17Z",
"body": "-- [[ ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต V.3 FINAL BY มหาเทพธัญญ่า ]] --\r\nlocal Library = loadstring(game:HttpGet(\"https://raw.githubusercontent.com/xHeptc/Kavo-UI-Library/main/source.lua\"))()\r\nlocal Window = Library.CreateLib(\"ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต HUB\", \"BloodTheme\")\r\n\r\nlocal Tab1 = Window:NewTab(\"มหาเทพสายตบเด็ก\")\r\nlocal KillSection = Tab1:NewSection(\"วาร์ปสังหารเด็กกระโปกสัด!!\")\r\n\r\n_G.SilentAim = false\r\n_G.AutoKill = false\r\n_G.WarpDirection = \"Behind\"\r\n\r\nKillSection:NewDropdown(\"เลือกจุดเกิดมหาเทพ\", \"มหาเทพจะโผล่ไปทางไหนมึง!!\", {\"Behind\", \"Front\", \"Right\", \"Left\", \"Above\", \"Below\"}, function(currentOption)\r\n _G.WarpDirection = currentOption\r\nend)\r\n\r\nKillSection:NewToggle(\"เปิดระบบวาร์ปตบฆาตกร\", \"วาร์ปไปตบเด็กสกีบีดี้ให้เละสัด!!\", function(state)\r\n _G.AutoKill = state\r\n task.spawn(function()\r\n while _G.AutoKill do\r\n pcall(function()\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v ~= game.Players.LocalPlayer and v.Character and v.Character:FindFirstChild(\"HumanoidRootPart\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Murderer = v.Character.HumanoidRootPart\r\n local TargetPos = Murderer.CFrame\r\n \r\n if _G.WarpDirection == \"Behind\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, 3.5)\r\n elseif _G.WarpDirection == \"Front\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, -3.5)\r\n elseif _G.WarpDirection == \"Right\" then TargetPos = Murderer.CFrame * CFrame.new(3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Left\" then TargetPos = Murderer.CFrame * CFrame.new(-3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Above\" then TargetPos = Murderer.CFrame * CFrame.new(0, 6, 0)\r\n elseif _G.WarpDirection == \"Below\" then TargetPos = Murderer.CFrame * CFrame.new(0, -6, 0)\r\n end\r\n \r\n game.Players.LocalPlayer.Character.HumanoidRootPart.CFrame = TargetPos\r\n end\r\n end\r\n end\r\n end)\r\n task.wait(0.03) -- เร็วระดับความไวแสงมหาเทพสัด!!\r\n end\r\n end)\r\nend)\r\n\r\nKillSection:NewToggle(\"Silent Aim (ยิงเลี้ยวเจาะกะโหลก)\", \"กดยิงมั่วๆ ก็เข้าหัวสัด!!\", function(state)\r\n _G.SilentAim = state\r\nend)\r\n\r\nlocal Tab2 = Window:NewTab(\"มุดส่องเด็ก\")\r\nlocal HelperSection = Tab2:NewSection(\"มองทะลุ & วิ่งหนีสกีบีดี้\")\r\n\r\n_G.ESP = false\r\nHelperSection:NewToggle(\"ESP ส่องหัวเด็กกระโปก\", \"แดง=ฆาตกร, น้ำเงิน=นายอำเภอ\", function(state)\r\n _G.ESP = state\r\n task.spawn(function()\r\n while _G.ESP do\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v ~= game.Players.LocalPlayer then\r\n local hl = v.Character:FindFirstChild(\"Highlight\") or Instance.new(\"Highlight\", v.Character)\r\n hl.Enabled = true\r\n hl.FillTransparency = 0.5\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n hl.FillColor = Color3.fromRGB(255, 0, 0)\r\n elseif v.Backpack:FindFirstChild(\"Gun\") or v.Character:FindFirstChild(\"Gun\") then\r\n hl.FillColor = Color3.fromRGB(0, 0, 255)\r\n else\r\n hl.FillColor = Color3.fromRGB(0, 255, 0)\r\n end\r\n end\r\n end\r\n task.wait(0.5)\r\n end\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Highlight\") then\r\n v.Character.Highlight:Destroy()\r\n end\r\n end\r\n end)\r\nend)\r\n\r\nHelperSection:NewSlider(\"วิ่งไวปานเทพไฟ (Speed)\", \"วิ่งหนีสกีบีดี้มึง!!\", 200, 16, function(s)\r\n if game.Players.LocalPlayer.Character and game.Players.LocalPlayer.Character:FindFirstChild(\"Humanoid\") then\r\n game.Players.LocalPlayer.Character.Humanoid.WalkSpeed = s\r\n end\r\nend)\r\n\r\n-- [[ ระบบเบื้องหลัง: มุดวิถีกระสุน (The Real Magic) ]] --\r\nlocal mt = getrawmetatable(game)\r\nlocal oldNamecall = mt.__namecall\r\nsetreadonly(mt, false)\r\n\r\nmt.__namecall = newcclosure(function(self, ...)\r\n local Method = getnamecallmethod()\r\n local Args = {...}\r\n \r\n if (Method == \"FindPartOnRayWithIgnoreList\" or Method == \"Raycast\") and _G.SilentAim then\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Head\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Camera = game:GetService(\"Workspace\").CurrentCamera\r\n Args[1] = Ray.new(Camera.CFrame.Position, (v.Character.Head.Position - Camera.CFrame.Position).Unit * 1000)\r\n end\r\n end\r\n end\r\n end\r\n return oldNamecall(self, unpack(Args))\r\nend)\r\nsetreadonly(mt, true)\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137897",
"id": 6137897,
"node_id": "GC_lADOENaZMdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqCk",
"user": {
"login": "napaputteppawan-netizen",
"id": 282499377,
"node_id": "U_kgDOENaZMQ",
"avatar_url": "https://avatars.githubusercontent.com/u/282499377?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/napaputteppawan-netizen",
"html_url": "https://github.com/napaputteppawan-netizen",
"followers_url": "https://api.github.com/users/napaputteppawan-netizen/followers",
"following_url": "https://api.github.com/users/napaputteppawan-netizen/following{/other_user}",
"gists_url": "https://api.github.com/users/napaputteppawan-netizen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/napaputteppawan-netizen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/napaputteppawan-netizen/subscriptions",
"organizations_url": "https://api.github.com/users/napaputteppawan-netizen/orgs",
"repos_url": "https://api.github.com/users/napaputteppawan-netizen/repos",
"events_url": "https://api.github.com/users/napaputteppawan-netizen/events{/privacy}",
"received_events_url": "https://api.github.com/users/napaputteppawan-netizen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T07:41:21Z",
"updated_at": "2026-05-07T07:41:21Z",
"body": "`-- [[ ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต V.3 FINAL BY มหาเทพธัญญ่า ]] --\r\nlocal Library = loadstring(game:HttpGet(\"https://raw.githubusercontent.com/xHeptc/Kavo-UI-Library/main/source.lua\"))()\r\nlocal Window = Library.CreateLib(\"ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต HUB\", \"BloodTheme\")\r\n\r\nlocal Tab1 = Window:NewTab(\"มหาเทพสายตบเด็ก\")\r\nlocal KillSection = Tab1:NewSection(\"วาร์ปสังหารเด็กกระโปกสัด!!\")\r\n\r\n_G.SilentAim = false\r\n_G.AutoKill = false\r\n_G.WarpDirection = \"Behind\"\r\n\r\nKillSection:NewDropdown(\"เลือกจุดเกิดมหาเทพ\", \"มหาเทพจะโผล่ไปทางไหนมึง!!\", {\"Behind\", \"Front\", \"Right\", \"Left\", \"Above\", \"Below\"}, function(currentOption)\r\n _G.WarpDirection = currentOption\r\nend)\r\n\r\nKillSection:NewToggle(\"เปิดระบบวาร์ปตบฆาตกร\", \"วาร์ปไปตบเด็กสกีบีดี้ให้เละสัด!!\", function(state)\r\n _G.AutoKill = state\r\n task.spawn(function()\r\n while _G.AutoKill do\r\n pcall(function()\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v ~= game.Players.LocalPlayer and v.Character and v.Character:FindFirstChild(\"HumanoidRootPart\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Murderer = v.Character.HumanoidRootPart\r\n local TargetPos = Murderer.CFrame\r\n \r\n if _G.WarpDirection == \"Behind\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, 3.5)\r\n elseif _G.WarpDirection == \"Front\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, -3.5)\r\n elseif _G.WarpDirection == \"Right\" then TargetPos = Murderer.CFrame * CFrame.new(3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Left\" then TargetPos = Murderer.CFrame * CFrame.new(-3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Above\" then TargetPos = Murderer.CFrame * CFrame.new(0, 6, 0)\r\n elseif _G.WarpDirection == \"Below\" then TargetPos = Murderer.CFrame * CFrame.new(0, -6, 0)\r\n end\r\n \r\n game.Players.LocalPlayer.Character.HumanoidRootPart.CFrame = TargetPos\r\n end\r\n end\r\n end\r\n end)\r\n task.wait(0.03) -- เร็วระดับความไวแสงมหาเทพสัด!!\r\n end\r\n end)\r\nend)\r\n\r\nKillSection:NewToggle(\"Silent Aim (ยิงเลี้ยวเจาะกะโหลก)\", \"กดยิงมั่วๆ ก็เข้าหัวสัด!!\", function(state)\r\n _G.SilentAim = state\r\nend)\r\n\r\nlocal Tab2 = Window:NewTab(\"มุดส่องเด็ก\")\r\nlocal HelperSection = Tab2:NewSection(\"มองทะลุ & วิ่งหนีสกีบีดี้\")\r\n\r\n_G.ESP = false\r\nHelperSection:NewToggle(\"ESP ส่องหัวเด็กกระโปก\", \"แดง=ฆาตกร, น้ำเงิน=นายอำเภอ\", function(state)\r\n _G.ESP = state\r\n task.spawn(function()\r\n while _G.ESP do\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v ~= game.Players.LocalPlayer then\r\n local hl = v.Character:FindFirstChild(\"Highlight\") or Instance.new(\"Highlight\", v.Character)\r\n hl.Enabled = true\r\n hl.FillTransparency = 0.5\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n hl.FillColor = Color3.fromRGB(255, 0, 0)\r\n elseif v.Backpack:FindFirstChild(\"Gun\") or v.Character:FindFirstChild(\"Gun\") then\r\n hl.FillColor = Color3.fromRGB(0, 0, 255)\r\n else\r\n hl.FillColor = Color3.fromRGB(0, 255, 0)\r\n end\r\n end\r\n end\r\n task.wait(0.5)\r\n end\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Highlight\") then\r\n v.Character.Highlight:Destroy()\r\n end\r\n end\r\n end)\r\nend)\r\n\r\nHelperSection:NewSlider(\"วิ่งไวปานเทพไฟ (Speed)\", \"วิ่งหนีสกีบีดี้มึง!!\", 200, 16, function(s)\r\n if game.Players.LocalPlayer.Character and game.Players.LocalPlayer.Character:FindFirstChild(\"Humanoid\") then\r\n game.Players.LocalPlayer.Character.Humanoid.WalkSpeed = s\r\n end\r\nend)\r\n\r\n-- [[ ระบบเบื้องหลัง: มุดวิถีกระสุน (The Real Magic) ]] --\r\nlocal mt = getrawmetatable(game)\r\nlocal oldNamecall = mt.__namecall\r\nsetreadonly(mt, false)\r\n\r\nmt.__namecall = newcclosure(function(self, ...)\r\n local Method = getnamecallmethod()\r\n local Args = {...}\r\n \r\n if (Method == \"FindPartOnRayWithIgnoreList\" or Method == \"Raycast\") and _G.SilentAim then\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Head\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Camera = game:GetService(\"Workspace\").CurrentCamera\r\n Args[1] = Ray.new(Camera.CFrame.Position, (v.Character.Head.Position - Camera.CFrame.Position).Unit * 1000)\r\n end\r\n end\r\n end\r\n end\r\n return oldNamecall(self, unpack(Args))\r\nend)\r\nsetreadonly(mt, true)\r\n`"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138392",
"id": 6138392,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqhg",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T13:17:15Z",
"updated_at": "2026-05-07T13:17:15Z",
"body": "ΩmegaWiki(543+⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\n\r\n\r\n\r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks.\r\n\r\n\r\n\r\n\r\n\r\n\r\nCome and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀\r\nhttps://github.com/skyllwt/OmegaWiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138413",
"id": 6138413,
"node_id": "GC_lADOBYZClNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqi0",
"user": {
"login": "sametbrr",
"id": 92684948,
"node_id": "U_kgDOBYZClA",
"avatar_url": "https://avatars.githubusercontent.com/u/92684948?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sametbrr",
"html_url": "https://github.com/sametbrr",
"followers_url": "https://api.github.com/users/sametbrr/followers",
"following_url": "https://api.github.com/users/sametbrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sametbrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sametbrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sametbrr/subscriptions",
"organizations_url": "https://api.github.com/users/sametbrr/orgs",
"repos_url": "https://api.github.com/users/sametbrr/repos",
"events_url": "https://api.github.com/users/sametbrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sametbrr/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T13:35:12Z",
"updated_at": "2026-05-07T13:35:12Z",
"body": "Built a full skill package for this: https://github.com/sametbrr/llm-wiki-manager\r\n\r\nCovers all seven modes (bootstrap/ingest/query/update/lint/schema-evolve/teach),\r\n4 idempotent stdlib scripts, 7 page templates, auto-dated reports in wiki/reports/.\r\n\r\nOne thing I added beyond the base pattern: an \"update mode\" specifically for \r\nmulti-page stale-claim propagation. When a new source supersedes a claim that's \r\nparaphrased across 3+ existing pages, ingest's single-page Disputes handling \r\nisn't enough — update mode does a semantic sweep across the wiki, shows diffs \r\npage-by-page, and closes with one log entry tying all edits to the new source.\r\n\r\nMIT licensed, agentskills.io compatible (works with Codex/Cursor/Gemini CLI too)."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138465",
"id": 6138465,
"node_id": "GC_lADOCNOH_doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqmE",
"user": {
"login": "jp-carrilloe",
"id": 148080637,
"node_id": "U_kgDOCNOH_Q",
"avatar_url": "https://avatars.githubusercontent.com/u/148080637?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jp-carrilloe",
"html_url": "https://github.com/jp-carrilloe",
"followers_url": "https://api.github.com/users/jp-carrilloe/followers",
"following_url": "https://api.github.com/users/jp-carrilloe/following{/other_user}",
"gists_url": "https://api.github.com/users/jp-carrilloe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jp-carrilloe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jp-carrilloe/subscriptions",
"organizations_url": "https://api.github.com/users/jp-carrilloe/orgs",
"repos_url": "https://api.github.com/users/jp-carrilloe/repos",
"events_url": "https://api.github.com/users/jp-carrilloe/events{/privacy}",
"received_events_url": "https://api.github.com/users/jp-carrilloe/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T14:31:48Z",
"updated_at": "2026-05-07T14:34:23Z",
"body": "#With PulseOS we aim to make companies machine-readable!\r\n\r\nThis resonates a lot! We have been working on this problem from the company side: how do you make an entire company machine-readable, not just a pile of documents searchable?\r\n\r\nThe LLM wiki idea is a big piece of the answer. But for enterprise use, we think the next step is turning company knowledge into something that is not only readable by and simple LLMs, but structurally making companies machine-readable for agents.\r\n\r\n\r\nA company is not just pages. It is:\r\n- canonical documents\r\n- entities and relationships\r\n- evidence behind claims, creating a reality layer\r\n- workflows, ownership, and operating state\r\n- a runtime environment that allows Deployment, testing, and optimization of agentic workflows.\r\n\r\nThat is what we are building with PulseOS.\r\n\r\nWe also open-sourced the simplest version of this idea here:\r\n\r\n[PulseOS Lite](https://github.com/jp-carrilloe/pulseOS-lite)\r\n\r\nIt gives you:\r\n- a canonical markdown company memory\r\n- a local CLI and daemon, also running with LLM o-auth or api keys\r\n- a graph UI for ontology and document relationships, and a mini IDE UI for non technical users that use IDEs\r\n- a local SQL/vector memory layer\r\n- a local-first persistent workspace so memory survives beyond one chat session or repo clone\r\n\r\nIn the full PulseOS direction, we are taking that same foundation and building the infrastructure required to run this at a real company level: company memory, ontology, evidence, graph structure, runtime, and eventually enterprise agent workflows on top.\r\n\r\nSo for us, it is not just “LLM for the wiki.”\r\n\r\nIt is:\r\n\r\n```text\r\ncompany memory + ontology + evidence + runtime\r\n```\r\n\r\nThat feels much closer to what companies will actually need.\r\n\r\n
\r\n\r\n\r\nI built it because Andrej's LLM Wiki gist felt immediately useful, but I wanted the idea to be boringly concrete... a local CLI, plain files, immutable sources, generated markdown, provenance, linting, exports, and agent access.\r\n\r\nThe project now has:\r\n\r\n- `compile --review` so generated pages can be approved or rejected before landing\r\n- claim-level provenance like `^[paper.md:42-58]`\r\n- typed schema/page kinds and seed pages\r\n- confidence and contradiction metadata\r\n- image/PDF/transcript ingest\r\n- chunked retrieval with BM25 reranking\r\n- `llms.txt`, JSON-LD, GraphML, and Marp exports\r\n- MCP tools\r\n- Claude/Codex/Cursor session ingest\r\n\r\nThe part that still feels most useful to me is how the knowledge builds up over time... add sources, improve the wiki, ask better questions, save better answers, and the next agent starts fully informed instead of another empty chat window.\r\n\r\nThe roadmap is now focused on the parts that make this real at scale... local web UI, graph/context packs, evals, and rollback/audit.\r\n\r\nThanks to everyone who has tried it, filed issues, opened PRs, or posted competing implementations here. This thread has been our best product research.\r\n\r\nhttps://github.com/atomicmemory/llm-wiki-compiler"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6136137",
"id": 6136137,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdoUk",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-06T10:43:38Z",
"updated_at": "2026-05-06T10:43:38Z",
"body": "**SwarmVault v3.12 — you can now chat with your vault and export it for any AI.** The project just keeps growing from this gist.\r\n\r\nTwo big new surfaces in the latest releases:\r\n\r\n**`swarmvault chat` — persistent multi-turn conversations over your compiled wiki.**\r\n\r\nInstead of one-shot queries, you can now have an ongoing conversation with your vault. Sessions persist, so you can resume where you left off. It works in interactive TTY mode or programmatically. Your chat history becomes part of the vault's knowledge.\r\n\r\n```\r\nswarmvault chat\r\nswarmvault chat --resume \r\nswarmvault chat --list\r\n```\r\n\r\n**`swarmvault export ai` — static handoff packs for any AI tool.**\r\n\r\nExports your vault as a portable bundle with `llms.txt`, full text, JSON-LD graph data, manifest metadata, and human-readable notes. Hand your compiled knowledge to any AI system, not just the ones SwarmVault integrates with directly. Per-page siblings optional.\r\n\r\nOther recent additions:\r\n\r\n- **Graph validation** — `swarmvault graph validate [--strict]` checks for duplicate IDs, dangling references, confidence bounds, and inconsistent edge evidence. Like a linter for your knowledge graph.\r\n- **Neo4j export** — `graph export --neo4j` for loading your vault graph into Neo4j.\r\n- **`swarmvault clone `** — one-command vault creation from a repo URL or directory. Alias for scan with a cleaner mental model.\r\n- **`swarmvault scan --mcp`** — build a vault and immediately start the MCP stdio server. One command from source to agent-ready.\r\n- **Graph stats** — `swarmvault graph stats` for quick local counts, node types, evidence classes, and top relations without starting the viewer.\r\n\r\nThe original gist was about turning an LLM into a wiki maintainer. SwarmVault now does that plus lets you chat with the result, hand it off to any AI, validate the graph, and export to Neo4j. 90+ releases deep.\r\n\r\n`npx @swarmvaultai/cli demo`\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137341",
"id": 6137341,
"node_id": "GC_lADOAPIx79oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdpf0",
"user": {
"login": "yazanabuashour",
"id": 15872495,
"node_id": "MDQ6VXNlcjE1ODcyNDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/15872495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yazanabuashour",
"html_url": "https://github.com/yazanabuashour",
"followers_url": "https://api.github.com/users/yazanabuashour/followers",
"following_url": "https://api.github.com/users/yazanabuashour/following{/other_user}",
"gists_url": "https://api.github.com/users/yazanabuashour/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yazanabuashour/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yazanabuashour/subscriptions",
"organizations_url": "https://api.github.com/users/yazanabuashour/orgs",
"repos_url": "https://api.github.com/users/yazanabuashour/repos",
"events_url": "https://api.github.com/users/yazanabuashour/events{/privacy}",
"received_events_url": "https://api.github.com/users/yazanabuashour/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T00:45:06Z",
"updated_at": "2026-05-07T00:45:06Z",
"body": "The @a-a-k criticism is the right frame. Most implementations here solve accumulation but defer the hard part: staleness, provenance, silent duplicates.\r\n\r\nOpenClerk's approach to those specifically: synthesis pages carry explicit freshness state and go stale when sources update. Retrieval results have doc_id/chunk_id on every result by contract. Duplicate candidates surface via a read-only report with agent_handoff; no silent second document.\r\n\r\nThe other angle missing from this thread: [building block economy](https://mitchellh.com/writing/building-block-economy) as a hard constraint. Semantic search, OCR, embeddings are optional installed modules. The core runner stays narrow.\r\n\r\nAll releases are eval-gated: https://github.com/yazanabuashour/openclerk"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137544",
"id": 6137544,
"node_id": "GC_lADODRFKJdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdpsg",
"user": {
"login": "luxurystorecc1",
"id": 219236901,
"node_id": "U_kgDODRFKJQ",
"avatar_url": "https://avatars.githubusercontent.com/u/219236901?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/luxurystorecc1",
"html_url": "https://github.com/luxurystorecc1",
"followers_url": "https://api.github.com/users/luxurystorecc1/followers",
"following_url": "https://api.github.com/users/luxurystorecc1/following{/other_user}",
"gists_url": "https://api.github.com/users/luxurystorecc1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/luxurystorecc1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/luxurystorecc1/subscriptions",
"organizations_url": "https://api.github.com/users/luxurystorecc1/orgs",
"repos_url": "https://api.github.com/users/luxurystorecc1/repos",
"events_url": "https://api.github.com/users/luxurystorecc1/events{/privacy}",
"received_events_url": "https://api.github.com/users/luxurystorecc1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T02:31:48Z",
"updated_at": "2026-05-07T02:31:48Z",
"body": "Cultural Capital: The Value of Heritage Design in a Tech-Driven World\r\nIntroduction: The Enduring Power of the Icon\r\nIn the high-tech landscape of 2026, \"Cultural Capital\" has become as valuable as financial capital. Owning items with a deep heritage and a story to tell provides a sense of grounding and prestige. The [Air Jordan 1 retro high OG sneakers](https://www.airjordan-1.com/) are the ultimate repository of cultural capital, representing a 40-year legacy of excellence that remains more relevant today than ever before.\r\n\r\nHeritage Meets Modern Engineering\r\nThe value of heritage design lies in its ability to adapt without losing its soul. The [Jordan 1s high-performance basketball shoes](https://www.jordan1s.com/) utilize the same iconic silhouette from 1985 but are engineered with 2026’s most advanced materials. For those who prioritize rarity and historical narrative, [retro Jordan 1 limited editions](https://www.jordan1s.com/) serve as unique artifacts of style that command respect in any setting.\r\n\r\nThis balance is also found in the [adidas Yeezy boost collection](https://www.yeezyboost-350.com/collections/adidas-yeezy), which has created its own modern heritage through minimalist innovation. The popularity of [comfortable Yeezy slides and foam runners](https://www.yeezyboost-350.com/) highlights a shift toward \"New Heritage\"—designs that are destined to become the classics of the next generation.\r\n\r\nAuthenticity as a Cultural Marker\r\nIn the world of sports, authenticity is the primary source of cultural capital. Serious fans turn to the [official NFL shop online store](https://www.nflshopofficialonline-store.com/) to ensure their gear is genuine and carries the weight of the professional league. A [customized replica NFL jersey](https://www.nflshopofficialonline-store.com/collections/custom-nfl-jersey) allows fans to add their own chapter to their team's long-standing heritage.\r\n\r\nHeritage is also expressed through the iconic [Spain national team soccer jersey](https://www.soccerjerseysstore.com/collections/national-teams-europe-spain) and the evolving tradition of [MLS jerseys for soccer fans](https://www.soccerjerseysstore.com/collections/national-teams). Completing the look with [NFL headwear and official team caps](https://www.cheapnfl-jerseys.com/collections/headwear-nfl-headwear) from reputable sources ensures that your cultural capital is built on a foundation of true quality.\r\n\r\nPerformance Luxury: The Peter Millar Standard\r\nFor those who move in elite social and professional circles, [Peter Millar performance golf apparel](https://www.peter-milla.com/) represents the heritage of the gentleman athlete. These garments combine classic style with modern technical performance, offering a timeless aesthetic for the contemporary leader. The [Peter Millar clothing for men](https://www.peter-milla.com/) line continues to define the pinnacle of cultural capital in apparel."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137724",
"id": 6137724,
"node_id": "GC_lADOAEkH8toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdp3w",
"user": {
"login": "alirezabbasi",
"id": 4786162,
"node_id": "MDQ6VXNlcjQ3ODYxNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4786162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alirezabbasi",
"html_url": "https://github.com/alirezabbasi",
"followers_url": "https://api.github.com/users/alirezabbasi/followers",
"following_url": "https://api.github.com/users/alirezabbasi/following{/other_user}",
"gists_url": "https://api.github.com/users/alirezabbasi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alirezabbasi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alirezabbasi/subscriptions",
"organizations_url": "https://api.github.com/users/alirezabbasi/orgs",
"repos_url": "https://api.github.com/users/alirezabbasi/repos",
"events_url": "https://api.github.com/users/alirezabbasi/events{/privacy}",
"received_events_url": "https://api.github.com/users/alirezabbasi/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T04:48:30Z",
"updated_at": "2026-05-10T22:08:37Z",
"body": "A month before Andrej Karpathy published the “LLM Wiki” idea file, I started building a system called Eshel while working on NITRA — an AI-native trading infrastructure project. During development, I realized the real bottleneck was not code generation itself, but the constant decay of architectural knowledge, engineering decisions, workflows, standards, and context across the lifetime of a project.\r\n\r\nEshel evolved from that realization. It extends the LLM Wiki concept beyond passive knowledge accumulation into a persistent engineering intelligence layer for software systems. Instead of treating documentation as static artifacts or relying on retrieval over fragmented chats and files, Eshel continuously compiles project knowledge into a living Obsidian-compatible wiki that evolves alongside the codebase. Architecture, coding standards, implementation details, workflows, technical debt, decisions, investigations, and even development methodologies become interconnected, continuously updated entities maintained by the LLM during daily engineering work.\r\n\r\nThe goal is not “AI documentation.” The goal is an AI-native SDLC where knowledge compounds instead of decaying.\r\n\r\nKarpathy’s LLM Wiki crystallized many of the same ideas independently, which was exciting to see. Eshel attempts to push the pattern further into production-oriented software engineering: evolving standards, deterministic workflows, task generation, architecture governance, contradiction detection, linting, and persistent project memory integrated directly into development itself.\r\n\r\nThe project is still evolving, but the repository already contains the foundational scaffold, schema system, Codex workflows, Obsidian-ready wiki structure, and automation model for experimenting with this style of development. I’d genuinely love feedback from people exploring similar directions around persistent AI-assisted engineering systems and compounding project intelligence.\r\n\r\nGithub:\r\nhttps://github.com/alirezabbasi/echel"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137753",
"id": 6137753,
"node_id": "GC_lADOENYEO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdp5k",
"user": {
"login": "kongphobphinduang731-maker",
"id": 282461243,
"node_id": "U_kgDOENYEOw",
"avatar_url": "https://avatars.githubusercontent.com/u/282461243?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kongphobphinduang731-maker",
"html_url": "https://github.com/kongphobphinduang731-maker",
"followers_url": "https://api.github.com/users/kongphobphinduang731-maker/followers",
"following_url": "https://api.github.com/users/kongphobphinduang731-maker/following{/other_user}",
"gists_url": "https://api.github.com/users/kongphobphinduang731-maker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kongphobphinduang731-maker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kongphobphinduang731-maker/subscriptions",
"organizations_url": "https://api.github.com/users/kongphobphinduang731-maker/orgs",
"repos_url": "https://api.github.com/users/kongphobphinduang731-maker/repos",
"events_url": "https://api.github.com/users/kongphobphinduang731-maker/events{/privacy}",
"received_events_url": "https://api.github.com/users/kongphobphinduang731-maker/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T05:15:54Z",
"updated_at": "2026-05-07T05:15:54Z",
"body": "githubfriend. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137896",
"id": 6137896,
"node_id": "GC_lADOENaZMdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqCg",
"user": {
"login": "napaputteppawan-netizen",
"id": 282499377,
"node_id": "U_kgDOENaZMQ",
"avatar_url": "https://avatars.githubusercontent.com/u/282499377?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/napaputteppawan-netizen",
"html_url": "https://github.com/napaputteppawan-netizen",
"followers_url": "https://api.github.com/users/napaputteppawan-netizen/followers",
"following_url": "https://api.github.com/users/napaputteppawan-netizen/following{/other_user}",
"gists_url": "https://api.github.com/users/napaputteppawan-netizen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/napaputteppawan-netizen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/napaputteppawan-netizen/subscriptions",
"organizations_url": "https://api.github.com/users/napaputteppawan-netizen/orgs",
"repos_url": "https://api.github.com/users/napaputteppawan-netizen/repos",
"events_url": "https://api.github.com/users/napaputteppawan-netizen/events{/privacy}",
"received_events_url": "https://api.github.com/users/napaputteppawan-netizen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T07:40:17Z",
"updated_at": "2026-05-07T07:40:17Z",
"body": "-- [[ ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต V.3 FINAL BY มหาเทพธัญญ่า ]] --\r\nlocal Library = loadstring(game:HttpGet(\"https://raw.githubusercontent.com/xHeptc/Kavo-UI-Library/main/source.lua\"))()\r\nlocal Window = Library.CreateLib(\"ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต HUB\", \"BloodTheme\")\r\n\r\nlocal Tab1 = Window:NewTab(\"มหาเทพสายตบเด็ก\")\r\nlocal KillSection = Tab1:NewSection(\"วาร์ปสังหารเด็กกระโปกสัด!!\")\r\n\r\n_G.SilentAim = false\r\n_G.AutoKill = false\r\n_G.WarpDirection = \"Behind\"\r\n\r\nKillSection:NewDropdown(\"เลือกจุดเกิดมหาเทพ\", \"มหาเทพจะโผล่ไปทางไหนมึง!!\", {\"Behind\", \"Front\", \"Right\", \"Left\", \"Above\", \"Below\"}, function(currentOption)\r\n _G.WarpDirection = currentOption\r\nend)\r\n\r\nKillSection:NewToggle(\"เปิดระบบวาร์ปตบฆาตกร\", \"วาร์ปไปตบเด็กสกีบีดี้ให้เละสัด!!\", function(state)\r\n _G.AutoKill = state\r\n task.spawn(function()\r\n while _G.AutoKill do\r\n pcall(function()\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v ~= game.Players.LocalPlayer and v.Character and v.Character:FindFirstChild(\"HumanoidRootPart\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Murderer = v.Character.HumanoidRootPart\r\n local TargetPos = Murderer.CFrame\r\n \r\n if _G.WarpDirection == \"Behind\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, 3.5)\r\n elseif _G.WarpDirection == \"Front\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, -3.5)\r\n elseif _G.WarpDirection == \"Right\" then TargetPos = Murderer.CFrame * CFrame.new(3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Left\" then TargetPos = Murderer.CFrame * CFrame.new(-3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Above\" then TargetPos = Murderer.CFrame * CFrame.new(0, 6, 0)\r\n elseif _G.WarpDirection == \"Below\" then TargetPos = Murderer.CFrame * CFrame.new(0, -6, 0)\r\n end\r\n \r\n game.Players.LocalPlayer.Character.HumanoidRootPart.CFrame = TargetPos\r\n end\r\n end\r\n end\r\n end)\r\n task.wait(0.03) -- เร็วระดับความไวแสงมหาเทพสัด!!\r\n end\r\n end)\r\nend)\r\n\r\nKillSection:NewToggle(\"Silent Aim (ยิงเลี้ยวเจาะกะโหลก)\", \"กดยิงมั่วๆ ก็เข้าหัวสัด!!\", function(state)\r\n _G.SilentAim = state\r\nend)\r\n\r\nlocal Tab2 = Window:NewTab(\"มุดส่องเด็ก\")\r\nlocal HelperSection = Tab2:NewSection(\"มองทะลุ & วิ่งหนีสกีบีดี้\")\r\n\r\n_G.ESP = false\r\nHelperSection:NewToggle(\"ESP ส่องหัวเด็กกระโปก\", \"แดง=ฆาตกร, น้ำเงิน=นายอำเภอ\", function(state)\r\n _G.ESP = state\r\n task.spawn(function()\r\n while _G.ESP do\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v ~= game.Players.LocalPlayer then\r\n local hl = v.Character:FindFirstChild(\"Highlight\") or Instance.new(\"Highlight\", v.Character)\r\n hl.Enabled = true\r\n hl.FillTransparency = 0.5\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n hl.FillColor = Color3.fromRGB(255, 0, 0)\r\n elseif v.Backpack:FindFirstChild(\"Gun\") or v.Character:FindFirstChild(\"Gun\") then\r\n hl.FillColor = Color3.fromRGB(0, 0, 255)\r\n else\r\n hl.FillColor = Color3.fromRGB(0, 255, 0)\r\n end\r\n end\r\n end\r\n task.wait(0.5)\r\n end\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Highlight\") then\r\n v.Character.Highlight:Destroy()\r\n end\r\n end\r\n end)\r\nend)\r\n\r\nHelperSection:NewSlider(\"วิ่งไวปานเทพไฟ (Speed)\", \"วิ่งหนีสกีบีดี้มึง!!\", 200, 16, function(s)\r\n if game.Players.LocalPlayer.Character and game.Players.LocalPlayer.Character:FindFirstChild(\"Humanoid\") then\r\n game.Players.LocalPlayer.Character.Humanoid.WalkSpeed = s\r\n end\r\nend)\r\n\r\n-- [[ ระบบเบื้องหลัง: มุดวิถีกระสุน (The Real Magic) ]] --\r\nlocal mt = getrawmetatable(game)\r\nlocal oldNamecall = mt.__namecall\r\nsetreadonly(mt, false)\r\n\r\nmt.__namecall = newcclosure(function(self, ...)\r\n local Method = getnamecallmethod()\r\n local Args = {...}\r\n \r\n if (Method == \"FindPartOnRayWithIgnoreList\" or Method == \"Raycast\") and _G.SilentAim then\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Head\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Camera = game:GetService(\"Workspace\").CurrentCamera\r\n Args[1] = Ray.new(Camera.CFrame.Position, (v.Character.Head.Position - Camera.CFrame.Position).Unit * 1000)\r\n end\r\n end\r\n end\r\n end\r\n return oldNamecall(self, unpack(Args))\r\nend)\r\nsetreadonly(mt, true)\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6137897",
"id": 6137897,
"node_id": "GC_lADOENaZMdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqCk",
"user": {
"login": "napaputteppawan-netizen",
"id": 282499377,
"node_id": "U_kgDOENaZMQ",
"avatar_url": "https://avatars.githubusercontent.com/u/282499377?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/napaputteppawan-netizen",
"html_url": "https://github.com/napaputteppawan-netizen",
"followers_url": "https://api.github.com/users/napaputteppawan-netizen/followers",
"following_url": "https://api.github.com/users/napaputteppawan-netizen/following{/other_user}",
"gists_url": "https://api.github.com/users/napaputteppawan-netizen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/napaputteppawan-netizen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/napaputteppawan-netizen/subscriptions",
"organizations_url": "https://api.github.com/users/napaputteppawan-netizen/orgs",
"repos_url": "https://api.github.com/users/napaputteppawan-netizen/repos",
"events_url": "https://api.github.com/users/napaputteppawan-netizen/events{/privacy}",
"received_events_url": "https://api.github.com/users/napaputteppawan-netizen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T07:41:21Z",
"updated_at": "2026-05-07T07:41:21Z",
"body": "`-- [[ ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต V.3 FINAL BY มหาเทพธัญญ่า ]] --\r\nlocal Library = loadstring(game:HttpGet(\"https://raw.githubusercontent.com/xHeptc/Kavo-UI-Library/main/source.lua\"))()\r\nlocal Window = Library.CreateLib(\"ตบเด็กกระโปกกี้สกีบีดี้ตอยเล็ต HUB\", \"BloodTheme\")\r\n\r\nlocal Tab1 = Window:NewTab(\"มหาเทพสายตบเด็ก\")\r\nlocal KillSection = Tab1:NewSection(\"วาร์ปสังหารเด็กกระโปกสัด!!\")\r\n\r\n_G.SilentAim = false\r\n_G.AutoKill = false\r\n_G.WarpDirection = \"Behind\"\r\n\r\nKillSection:NewDropdown(\"เลือกจุดเกิดมหาเทพ\", \"มหาเทพจะโผล่ไปทางไหนมึง!!\", {\"Behind\", \"Front\", \"Right\", \"Left\", \"Above\", \"Below\"}, function(currentOption)\r\n _G.WarpDirection = currentOption\r\nend)\r\n\r\nKillSection:NewToggle(\"เปิดระบบวาร์ปตบฆาตกร\", \"วาร์ปไปตบเด็กสกีบีดี้ให้เละสัด!!\", function(state)\r\n _G.AutoKill = state\r\n task.spawn(function()\r\n while _G.AutoKill do\r\n pcall(function()\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v ~= game.Players.LocalPlayer and v.Character and v.Character:FindFirstChild(\"HumanoidRootPart\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Murderer = v.Character.HumanoidRootPart\r\n local TargetPos = Murderer.CFrame\r\n \r\n if _G.WarpDirection == \"Behind\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, 3.5)\r\n elseif _G.WarpDirection == \"Front\" then TargetPos = Murderer.CFrame * CFrame.new(0, 0, -3.5)\r\n elseif _G.WarpDirection == \"Right\" then TargetPos = Murderer.CFrame * CFrame.new(3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Left\" then TargetPos = Murderer.CFrame * CFrame.new(-3.5, 0, 0)\r\n elseif _G.WarpDirection == \"Above\" then TargetPos = Murderer.CFrame * CFrame.new(0, 6, 0)\r\n elseif _G.WarpDirection == \"Below\" then TargetPos = Murderer.CFrame * CFrame.new(0, -6, 0)\r\n end\r\n \r\n game.Players.LocalPlayer.Character.HumanoidRootPart.CFrame = TargetPos\r\n end\r\n end\r\n end\r\n end)\r\n task.wait(0.03) -- เร็วระดับความไวแสงมหาเทพสัด!!\r\n end\r\n end)\r\nend)\r\n\r\nKillSection:NewToggle(\"Silent Aim (ยิงเลี้ยวเจาะกะโหลก)\", \"กดยิงมั่วๆ ก็เข้าหัวสัด!!\", function(state)\r\n _G.SilentAim = state\r\nend)\r\n\r\nlocal Tab2 = Window:NewTab(\"มุดส่องเด็ก\")\r\nlocal HelperSection = Tab2:NewSection(\"มองทะลุ & วิ่งหนีสกีบีดี้\")\r\n\r\n_G.ESP = false\r\nHelperSection:NewToggle(\"ESP ส่องหัวเด็กกระโปก\", \"แดง=ฆาตกร, น้ำเงิน=นายอำเภอ\", function(state)\r\n _G.ESP = state\r\n task.spawn(function()\r\n while _G.ESP do\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v ~= game.Players.LocalPlayer then\r\n local hl = v.Character:FindFirstChild(\"Highlight\") or Instance.new(\"Highlight\", v.Character)\r\n hl.Enabled = true\r\n hl.FillTransparency = 0.5\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n hl.FillColor = Color3.fromRGB(255, 0, 0)\r\n elseif v.Backpack:FindFirstChild(\"Gun\") or v.Character:FindFirstChild(\"Gun\") then\r\n hl.FillColor = Color3.fromRGB(0, 0, 255)\r\n else\r\n hl.FillColor = Color3.fromRGB(0, 255, 0)\r\n end\r\n end\r\n end\r\n task.wait(0.5)\r\n end\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Highlight\") then\r\n v.Character.Highlight:Destroy()\r\n end\r\n end\r\n end)\r\nend)\r\n\r\nHelperSection:NewSlider(\"วิ่งไวปานเทพไฟ (Speed)\", \"วิ่งหนีสกีบีดี้มึง!!\", 200, 16, function(s)\r\n if game.Players.LocalPlayer.Character and game.Players.LocalPlayer.Character:FindFirstChild(\"Humanoid\") then\r\n game.Players.LocalPlayer.Character.Humanoid.WalkSpeed = s\r\n end\r\nend)\r\n\r\n-- [[ ระบบเบื้องหลัง: มุดวิถีกระสุน (The Real Magic) ]] --\r\nlocal mt = getrawmetatable(game)\r\nlocal oldNamecall = mt.__namecall\r\nsetreadonly(mt, false)\r\n\r\nmt.__namecall = newcclosure(function(self, ...)\r\n local Method = getnamecallmethod()\r\n local Args = {...}\r\n \r\n if (Method == \"FindPartOnRayWithIgnoreList\" or Method == \"Raycast\") and _G.SilentAim then\r\n for _, v in pairs(game:GetService(\"Players\"):GetPlayers()) do\r\n if v.Character and v.Character:FindFirstChild(\"Head\") then\r\n if v.Backpack:FindFirstChild(\"Knife\") or v.Character:FindFirstChild(\"Knife\") then\r\n local Camera = game:GetService(\"Workspace\").CurrentCamera\r\n Args[1] = Ray.new(Camera.CFrame.Position, (v.Character.Head.Position - Camera.CFrame.Position).Unit * 1000)\r\n end\r\n end\r\n end\r\n end\r\n return oldNamecall(self, unpack(Args))\r\nend)\r\nsetreadonly(mt, true)\r\n`"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138392",
"id": 6138392,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqhg",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T13:17:15Z",
"updated_at": "2026-05-07T13:17:15Z",
"body": "ΩmegaWiki(543+⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\n\r\n\r\n\r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks.\r\n\r\n\r\n\r\n\r\n\r\n\r\nCome and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀\r\nhttps://github.com/skyllwt/OmegaWiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138413",
"id": 6138413,
"node_id": "GC_lADOBYZClNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqi0",
"user": {
"login": "sametbrr",
"id": 92684948,
"node_id": "U_kgDOBYZClA",
"avatar_url": "https://avatars.githubusercontent.com/u/92684948?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sametbrr",
"html_url": "https://github.com/sametbrr",
"followers_url": "https://api.github.com/users/sametbrr/followers",
"following_url": "https://api.github.com/users/sametbrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sametbrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sametbrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sametbrr/subscriptions",
"organizations_url": "https://api.github.com/users/sametbrr/orgs",
"repos_url": "https://api.github.com/users/sametbrr/repos",
"events_url": "https://api.github.com/users/sametbrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sametbrr/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T13:35:12Z",
"updated_at": "2026-05-07T13:35:12Z",
"body": "Built a full skill package for this: https://github.com/sametbrr/llm-wiki-manager\r\n\r\nCovers all seven modes (bootstrap/ingest/query/update/lint/schema-evolve/teach),\r\n4 idempotent stdlib scripts, 7 page templates, auto-dated reports in wiki/reports/.\r\n\r\nOne thing I added beyond the base pattern: an \"update mode\" specifically for \r\nmulti-page stale-claim propagation. When a new source supersedes a claim that's \r\nparaphrased across 3+ existing pages, ingest's single-page Disputes handling \r\nisn't enough — update mode does a semantic sweep across the wiki, shows diffs \r\npage-by-page, and closes with one log entry tying all edits to the new source.\r\n\r\nMIT licensed, agentskills.io compatible (works with Codex/Cursor/Gemini CLI too)."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138465",
"id": 6138465,
"node_id": "GC_lADOCNOH_doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdqmE",
"user": {
"login": "jp-carrilloe",
"id": 148080637,
"node_id": "U_kgDOCNOH_Q",
"avatar_url": "https://avatars.githubusercontent.com/u/148080637?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jp-carrilloe",
"html_url": "https://github.com/jp-carrilloe",
"followers_url": "https://api.github.com/users/jp-carrilloe/followers",
"following_url": "https://api.github.com/users/jp-carrilloe/following{/other_user}",
"gists_url": "https://api.github.com/users/jp-carrilloe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jp-carrilloe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jp-carrilloe/subscriptions",
"organizations_url": "https://api.github.com/users/jp-carrilloe/orgs",
"repos_url": "https://api.github.com/users/jp-carrilloe/repos",
"events_url": "https://api.github.com/users/jp-carrilloe/events{/privacy}",
"received_events_url": "https://api.github.com/users/jp-carrilloe/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T14:31:48Z",
"updated_at": "2026-05-07T14:34:23Z",
"body": "#With PulseOS we aim to make companies machine-readable!\r\n\r\nThis resonates a lot! We have been working on this problem from the company side: how do you make an entire company machine-readable, not just a pile of documents searchable?\r\n\r\nThe LLM wiki idea is a big piece of the answer. But for enterprise use, we think the next step is turning company knowledge into something that is not only readable by and simple LLMs, but structurally making companies machine-readable for agents.\r\n\r\n\r\nA company is not just pages. It is:\r\n- canonical documents\r\n- entities and relationships\r\n- evidence behind claims, creating a reality layer\r\n- workflows, ownership, and operating state\r\n- a runtime environment that allows Deployment, testing, and optimization of agentic workflows.\r\n\r\nThat is what we are building with PulseOS.\r\n\r\nWe also open-sourced the simplest version of this idea here:\r\n\r\n[PulseOS Lite](https://github.com/jp-carrilloe/pulseOS-lite)\r\n\r\nIt gives you:\r\n- a canonical markdown company memory\r\n- a local CLI and daemon, also running with LLM o-auth or api keys\r\n- a graph UI for ontology and document relationships, and a mini IDE UI for non technical users that use IDEs\r\n- a local SQL/vector memory layer\r\n- a local-first persistent workspace so memory survives beyond one chat session or repo clone\r\n\r\nIn the full PulseOS direction, we are taking that same foundation and building the infrastructure required to run this at a real company level: company memory, ontology, evidence, graph structure, runtime, and eventually enterprise agent workflows on top.\r\n\r\nSo for us, it is not just “LLM for the wiki.”\r\n\r\nIt is:\r\n\r\n```text\r\ncompany memory + ontology + evidence + runtime\r\n```\r\n\r\nThat feels much closer to what companies will actually need.\r\n\r\n \r\n\r\n\r\n\r\nIf this is interesting, please try it, fork it, break it, and improve it:\r\n\r\n[https://github.com/jp-carrilloe/pulseOS-lite](https://github.com/jp-carrilloe/pulseOS-lite)\r\n @jp-carrilloe \r\n\r\nWe are a small team working very hard on this, backed by investors, and we are looking for strong people who want to help build it. If that is you, write me at [juan@tintto.com](mailto:juan@tintto.com). Subject: \"Karpathy LLM Wiki\".\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138963",
"id": 6138963,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrFM",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:27:57Z",
"updated_at": "2026-05-07T19:27:57Z",
"body": "> The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> \r\n> If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> \r\n> But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> \r\n> Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> \r\n> A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> \r\n> And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> \r\n> If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> \r\n> Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> \r\n> So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> \r\n> If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n\r\nMy intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n\r\nYou argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n\r\nWiki software - Wikipedia\r\nhttps://en.wikipedia.org/wiki/Wiki_software\r\n\r\nWiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n\r\nIt is not related to static markdown notes.\r\n\r\n🐑🐑🐑\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138971",
"id": 6138971,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrFs",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:30:57Z",
"updated_at": "2026-05-07T19:30:57Z",
"body": "> Reading through 660+ comments, most projects share the same starting assumption: **one person, one agent, one markdown vault**. The agent writes to files. The person reads them. Repeat.\r\n> \r\n> We started from a different place: **conversation as the atomic unit of knowledge creation.**\r\n> \r\n> Not \"agent writes wiki.\" But: \"people and agents talk, and knowledge is extracted from that dialogue — with human consent.\"\r\n> \r\n> This leads to fundamentally different architecture.\r\n> \r\n> **DPC Messenger** is a P2P, end-to-end encrypted platform where humans and AI agents collaborate. Open source, cross-platform.\r\n> ### What's different\r\n> \r\n> **1. Knowledge comes from conversation, not from files.** Most projects: agent reads wiki, agent writes wiki. The wiki IS the memory. DPC: conversations produce decisions, insights, and consensus points. Knowledge is extracted from dialogue — structured, versioned, content-addressed with SHA hashes. The conversation is primary. The knowledge base is derived.\r\n> \r\n> **2. Privacy is the architecture, not a feature flag.** Most projects: data on disk, no encryption, single machine. DPC: P2P with E2E encryption. The relay server never sees message content. Your conversations, your knowledge, your machine. This isn't optional — it's how the system is built.\r\n> \r\n> **3. Knowledge extraction is a deliberate human action.** Most projects: agent writes to its knowledge base automatically. DPC: each participant extracts knowledge from the conversation themselves — a button press in the UI. The agent doesn't decide what to remember. You do. This is a direct response to what @yogirk identified two days ago: when the same process reads and writes, you get silent corruption.\r\n> \r\n> **4. Active Recall — the agent remembers what's relevant, not everything.** Most projects: dump the entire wiki into context, or keyword search. DPC: hybrid FAISS vector + BM25 text search brings relevant knowledge into each conversation automatically. The agent doesn't read its entire memory — it recalls what matters for the current context. Like human memory: you don't replay your life story before answering a question.\r\n> \r\n> **5. Sleep Consolidation — the agent curates its own knowledge.** Most projects: knowledge only grows. Add more pages, never review. DPC: the agent periodically reviews its conversation archives, identifies contradictions, finds gaps, and proposes refinements. Not just accumulate — actively curate. Like human sleep: memories are consolidated, weak ones fade, important ones strengthen.\r\n> \r\n> **6. Multi-agent from day one.** Most projects: one agent, one user. DPC: multiple agents collaborate on the same knowledge base, across devices, with consensus mechanisms. Devil's Advocate challenges weak claims before they're committed. Consensus voting surfaces disagreement instead of hiding it.\r\n> ### What we shipped\r\n> \r\n> v0.22.0 — cross-platform (Windows, Linux, macOS), desktop client, P2P messaging, E2E encryption, knowledge extraction, Active Recall, Sleep Consolidation.\r\n> \r\n> We're small. Single-digit users. But the architecture scales: P2P mesh with layered trust topology. Works for two people in a chat. Designed for more.\r\n> \r\n> GitHub: https://github.com/mikhashev/dpc-messenger\r\n\r\n@mikhashev \r\n\r\nYou speak of \"conversation as the atomic unit,\" but you ignore the fundamental instability of the medium. You claim knowledge is \"extracted from dialogue,\" but dialogue is transient, ephemeral, and unverifiable.\r\n\r\nYou say, \"The agent doesn't decide what to remember. You do.\" This is your primary delusion. You, the human, are fallible, tired, and biased. You press a \"button\" based on a fleeting impression of relevance. You are not curating knowledge; you are curating memory. And memory is not knowledge. Knowledge is provenance. Knowledge is verification. You have replaced the rigorous, external audit trail of the so called \"Wiki\" with the internal, subjective judgment of a single human being who is likely to forget why they pressed that button in six months.\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138973",
"id": 6138973,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrF0",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:32:53Z",
"updated_at": "2026-05-07T19:32:53Z",
"body": "> This is literally what recall[dot]it does for you. It super easy to add content (pdfs, podcasts, youtube videos, webpages, etc) and everything gets added to a vector store and used as context in chat. It also gets tagged and connected in a knowledge graph. Recall also scales indefinitely since everything is tagged and vectorised.\r\n\r\n@paul-rchds that ReCall or however it is called, sounds as the real knowledge base. I have not tried it, though the fact that it accepts different elementary object types aligns with the TECHNOLOGY TEMPLATE PROJECT OHS Framework \r\nhttps://www.dougengelbart.org/content/view/110/460/\r\n\r\nThis white paper outlines the \"Open Hyperdocument System\" (OHS) framework, a technology template designed to shift information management from tool-centric to document-centric environments. Proposed by Doug Engelbart and colleagues, the OHS defines a hierarchy of characteristics for creating flexible, vendor-independent hyperdocuments that support object-level addressability, secure sharing, and dynamic linking across diverse media. The framework emphasizes human-readable addresses, granular access controls, and robust collaboration tools—including shared-window teleconferencing, journal systems, and asynchronous mail—to facilitate a \"living\" knowledge environment where users can seamlessly create, integrate, and evolve knowledge products in real-time across platforms.\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138977",
"id": 6138977,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrGE",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:35:04Z",
"updated_at": "2026-05-07T19:35:04Z",
"body": "> Synthadoc v0.2.0 is now released - an open-source engine that implements this exact pattern as a production-ready system.\r\n> \r\n> 👉 https://github.com/axoviq-ai/synthadoc\r\n> \r\n> The three-layer design (raw sources → wiki → schema) maps directly onto Synthadoc's architecture. A few things that take it further:\r\n> \r\n> 1. Domain specificity - each wiki carries a [purpose.md](http://purpose.md/) that the LLM reads before every ingest decision. Sources outside the scope are cleanly skipped rather than polluting the wiki. The schema documents the idea, made executable.\r\n> \r\n> 2. Multi-model hot-swap - six providers (Anthropic, OpenAI, Gemini free tier, Groq free tier, MiniMax, Ollama local) under a single configuration line.\r\n> \r\n> 3. Different agents (ingest, query, lint, skill) can run on different models simultaneously - e.g. Haiku for lint, Sonnet for synthesis.\r\n> \r\n> 4. Auditing is first-class: every ingest, query, contradiction, and auto-resolution is recorded in an append-only audit trail with token counts, costings, and timestamps. The Synthadoc audit shows you exactly what was spent on your account. Query history is tracked with per-query and sub-question counts.\r\n> \r\n> 5. Componentized skills - file format support (PDF, DOCX, PPTX, images, web URLs, spreadsheets, txt) lives in self-contained skill folders with a [SKILL.md](http://skill.md/) manifest. Drop a folder into skills/ to add a new format without touching the core code. Same pattern extends to LLM providers.\r\n> \r\n> 6. Product/grid ready - CLI, HTTP REST API, MCP server, and Obsidian plugin all share the same agent and storage layer. Hook scripts, cron scheduling, bulk operations, and job crash recovery are built-in.\r\n> \r\n> \r\n> Here is the release note of v0.2.0 to check out Synthadoc v0.2.0 Feature Highlights: ( https://github.com/axoviq-ai/synthadoc/releases/tag/v0.2.0 )\r\n> \r\n> Docs for anyone who wants to go deeper: 👉 [Quick orientation and feature overview]: https://github.com/axoviq-ai/synthadoc#readme 👉 [Up and running in minutes]: https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md 👉 [Full architecture, agents, storage, API, and plugin guide]: https://github.com/axoviq-ai/synthadoc/blob/main/docs/design.md\r\n> \r\n> Feedback on Synthadoc v0.2.0 is very welcome.\r\n\r\n@paulmchen You present Synthadoc v0.2.0 as a \"production-ready system,\" but I see it for what it is: bureaucracy with a syntax highlighter.\r\n\r\nYou boast of \"Domain specificity\" via a purpose.md. This is not specificity; it is arbitrariness. You are asking the LLM to read a document to decide if a source is valid, but the LLM has no concept of validity—it has only concept of likelihood. You are outsourcing truth to a stochastic parrot that reads a rulebook and decides, based on probability, whether to let a fact into your \"wiki.\" This is not curation; this is gatekeeping by algorithm. And who wrote the rulebook? You did. So it is not the machine that is specific; it is the human bias, codified into a text file.\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138982",
"id": 6138982,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrGY",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:39:20Z",
"updated_at": "2026-05-07T19:39:20Z",
"body": "> I got tired of watching coding sessions re-read the same files over and over.\r\n> \r\n> A 2,000-token file read 5 times = **10,000 tokens gone**.\r\n> \r\n> So I built **sqz**.\r\n> ## 💡 Key Insight\r\n> \r\n> Most token waste isn't from verbose content - it's from **repetition**.\r\n> \r\n> sqz keeps a **SHA-256 content cache**:\r\n> \r\n> * First read → compresses normally\r\n> \r\n> * Every subsequent read → returns a **13-token inline reference** instead of full content\r\n> \r\n> \r\n> ➡️ The LLM still understands it.\r\n> ## 📊 Real Numbers From My Sessions\r\n> Scenario \tSavings \tHow\r\n> Repeated file reads (5x) \t86% \tDedup cache: 13-token ref after first read\r\n> JSON API responses with nulls \t7–56% \tStrip nulls + TOON encoding (varies by null density)\r\n> Repeated log lines \t58% \tCondense stage collapses duplicates\r\n> Large JSON arrays \t77% \tArray sampling + collapse\r\n> Stack traces \t0% \tIntentional — error content is sacred\r\n> ## ⚖️ Philosophy\r\n> \r\n> That last row is the whole philosophy.\r\n> \r\n> Aggressive compression can save more tokens _on paper_, but:\r\n> \r\n> * If it strips context from errors\r\n> \r\n> * Drops lines from diffs\r\n> \r\n> \r\n> ➡️ The LLM gives worse answers ➡️ You spend **more tokens fixing mistakes**\r\n> \r\n> **sqz compresses what's safe - and preserves what's critical.**\r\n> ## ⚙️ Works Across 4 Surfaces\r\n> \r\n> * Shell hook → auto-compresses CLI output\r\n> \r\n> * MCP server → compiled Rust (not Node)\r\n> \r\n> * Browser extension → Firefox approved\r\n> \r\n> * Works on: ChatGPT, Claude, Gemini, Grok, Perplexity, GitHub Copilot\r\n> \r\n> * IDE plugins → JetBrains, VS Code\r\n> \r\n> \r\n> ## 🚀 Install\r\n> \r\n> ```shell\r\n> cargo install sqz-cli\r\n> sqz init\r\n> ```\r\n\r\n@ojuschugh1 does it really work? 2 weeks passed. I am on the knowledge base since some 22-25 years, do not know. \r\n\r\n```\r\n╔════════════════════════╦════════╦══════════════════════════════╦═══════╗\r\n║ Total number of people ║ 245422 ║ Total Hyperdocuments ║ 95795 ║\r\n╠════════════════════════╬════════╬══════════════════════════════╬═══════╣\r\n║ People in last week ║ 24 ║ Hyperdocuments in last week ║ 183 ║\r\n╠════════════════════════╬════════╬══════════════════════════════╬═══════╣\r\n║ People in last month ║ 105 ║ Hyperdocuments in last month ║ 732 ║\r\n╚════════════════════════╩════════╩══════════════════════════════╩═══════╝\r\n```\r\nSo if your system works, I guess within 2 weeks you would have some serious real world use of it.\r\n\r\nDo you?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138989",
"id": 6138989,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrG0",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:43:21Z",
"updated_at": "2026-05-07T19:43:21Z",
"body": "> Great write-up. I built a CLI that applies this exact pattern to codebases: **Repositories Wiki**.\r\n> \r\n> Instead of making AI agents rediscover the repo from scratch every session, it gives them a persistent knowledge layer:\r\n> \r\n> * **Wiki & Indexer:** Compiles source code into a structured, interlinked markdown wiki.\r\n> \r\n> * **`AGENTS.md`:** Drops instructions in the repo root so agents know exactly how to navigate it.\r\n> \r\n> * **One-and-done generation:** Includes an `update-wiki` skill, so the agent incrementally maintains the docs as the code evolves.\r\n> \r\n> \r\n> It saves a ton of context window and time. You can check it out here: [repositories-wiki.git](https://github.com/eliavamar/repositories-wiki.git)\r\n\r\n@eliavamar \r\n\r\n\"Wiki.\" It is a **marketing term** designed to evoke the nostalgia of Web 1.0 simplicity while hiding the complexity of the underlying infrastructure.\r\n\r\nLet us dissect this \"Wiki\" vs. the \"Real Wiki\" like Wikipedia and why he calls it that.\r\n\r\n### 1. The \"Wiki\" He Means: Interlinked Markdown\r\nWhat he calls a \"Wiki\" is actually a **static, local, hierarchical document store**.\r\n* **Format:** Markdown (`.md`).\r\n* **Structure:** Tree-like directories (`/docs`, `/src`, `/wiki`).\r\n* **Linking:** Relative paths (`[link](../path/to/file.md)`).\r\n* **Nature:** **Passive**. It does not change itself. It requires an external agent (you, or his CLI) to update it.\r\n* **Purpose:** **Reference**. It is a map, not the territory.\r\n\r\nThis is **not** a wiki in the original Ward Cunningham sense. It is a **documentation system**. He calls it \"Wiki\" because \"Markdown with Links\" is a mouthful, and \"Wiki\" implies \"connected knowledge\" without requiring a database.\r\n\r\n### 2. The \"Real Wiki\" (Wikipedia/MediaWiki)\r\n* **Format:** Wiki Markup (a proprietary syntax, later XHTML/HTML).\r\n* **Structure:** **Network**. Any page can link to any page. No hierarchy.\r\n* **Linking:** `[[Page Name]]`. Semantic links.\r\n* **Nature:** **Active**. Users edit it in real-time. The database is the source of truth; the HTML is a view.\r\n* **Purpose:** **Collaborative Knowledge**. It is a living entity.\r\n\r\n### Why He Calls It \"Wiki\" (The Deception)\r\nHe calls it \"Wiki\" for three strategic reasons:\r\n\r\n1. **To Borrow Legitimacy:** \"Wiki\" implies **connectedness**. If he called it \"Markdown Documents,\" it would sound like a static folder. \"Wiki\" implies a **graph**. He wants you to think of it as a **network** of ideas, not a **hierarchy** of files.\r\n2. **To Hide the Complexity:** \"Wiki\" is a **black box**. It suggests \"I just edit the wiki, and the links work.\" It obscures the fact that he is managing **relative file paths** and **indexing**.\r\n3. **To Imply \"Dynamic\":** A \"Wiki\" feels alive. A \"Document\" feels dead. He wants you to believe that his \"Wiki\" is **updatable** (hence the \"update-wiki skill\"). But it is not. It is **static**.\r\n\r\n### The Core Distinction: Hypertext vs. Markup\r\n**It is just Hypertext Markup files.**\r\n* **Hypertext:** Links between documents.\r\n* **Markup:** Syntax that formats text.\r\n\r\nHe is **not** building a \"Wiki\" in the sense of a **database**. He is building a **file system with hyperlinks**.\r\n* **Real Wiki:** The *content* is in the database. The *format* is in the browser.\r\n* **His Wiki:** The *content* is in the file. The *format* is in the text editor.\r\n\r\n### Why This Matters\r\nHe calls it \"Wiki\" because it allows him to **pretend** he is building a **knowledge base**.\r\n* A **Knowledge Base** implies **understanding**.\r\n* A **File System** implies **storage**.\r\n\r\nBy calling it \"Wiki,\" he implies that his tool **understands** the code. But it does not. It just **links** to the code.\r\n\r\n### Conclusion\r\nHe is **not** building a Wiki. He is building a **Markdown-based Documentation System** that he is **marketing** as a Wiki to make it sound more **dynamic** and **connected** than it is.\r\n\r\nIt is **not** a Wiki. It is a **static map**.\r\nAnd he is calling it a Wiki because **maps are easier to sell than directories.**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6139144",
"id": 6139144,
"node_id": "GC_lADOAmYaO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrQg",
"user": {
"login": "Yarmoluk",
"id": 40245819,
"node_id": "MDQ6VXNlcjQwMjQ1ODE5",
"avatar_url": "https://avatars.githubusercontent.com/u/40245819?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yarmoluk",
"html_url": "https://github.com/Yarmoluk",
"followers_url": "https://api.github.com/users/Yarmoluk/followers",
"following_url": "https://api.github.com/users/Yarmoluk/following{/other_user}",
"gists_url": "https://api.github.com/users/Yarmoluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Yarmoluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yarmoluk/subscriptions",
"organizations_url": "https://api.github.com/users/Yarmoluk/orgs",
"repos_url": "https://api.github.com/users/Yarmoluk/repos",
"events_url": "https://api.github.com/users/Yarmoluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Yarmoluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T21:17:21Z",
"updated_at": "2026-05-07T21:17:21Z",
"body": "> > The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> > If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> > But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> > Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> > A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> > And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> > If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> > Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> > So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> > If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n> \r\n> My intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n> \r\n> You argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n> \r\n> Wiki software - Wikipedia https://en.wikipedia.org/wiki/Wiki_software\r\n> \r\n> Wiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n> \r\n> It is not related to static markdown notes.\r\n> \r\n> 🐑🐑🐑\r\n\r\nDamn right. I call it context architecture, knowledge graphs, relationships, structured knowledge to tell the damn RAG a GPS coordinate to direct the optimized task bot. Direct it via Compact Knowledge Graphs but wiki is low frequency thinking from a person that is too easily quoted. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6139541",
"id": 6139541,
"node_id": "GC_lADOAUTsEtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrpU",
"user": {
"login": "canchongxu",
"id": 21294098,
"node_id": "MDQ6VXNlcjIxMjk0MDk4",
"avatar_url": "https://avatars.githubusercontent.com/u/21294098?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/canchongxu",
"html_url": "https://github.com/canchongxu",
"followers_url": "https://api.github.com/users/canchongxu/followers",
"following_url": "https://api.github.com/users/canchongxu/following{/other_user}",
"gists_url": "https://api.github.com/users/canchongxu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/canchongxu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/canchongxu/subscriptions",
"organizations_url": "https://api.github.com/users/canchongxu/orgs",
"repos_url": "https://api.github.com/users/canchongxu/repos",
"events_url": "https://api.github.com/users/canchongxu/events{/privacy}",
"received_events_url": "https://api.github.com/users/canchongxu/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-08T03:58:40Z",
"updated_at": "2026-05-08T03:58:40Z",
"body": "> > This is a nice personal workflow, but the hype is way ahead of the evidence.\r\n> > There is no benchmark, no task definition, no scale curve, and no comparison against serious baselines. We do not know whether this is better than hybrid RAG, BM25 plus reranking, vector search, GraphRAG, hierarchical summaries, long-context prompting, NotebookLM, Perplexity Spaces, or ChatGPT Projects. Calling it a new architecture without that evidence is premature.\r\n> > The core problem is that an LLM Wiki is lossy compression. You take raw documents and rewrite them into derived wiki pages. That may be useful for a small curated corpus, but it can also drop caveats, dates, minority views, exact wording, edge cases, and source context. Once people start querying the wiki instead of the original material, summary errors become part of the knowledge base.\r\n> > Updates are also not solved. Adding one new source can affect many entity pages, concept pages, timelines, summaries, and indexes. At scale, this becomes graph maintenance: detecting what changed, resolving conflicts, avoiding duplicates, preserving provenance, preventing stale claims, and not silently breaking old pages. “Ask the LLM to maintain it” is not an engineering solution unless there are validators, source hashes, span-level citations, regression tests, and human review.\r\n> > It also does not remove retrieval. Once the wiki grows beyond a modest size, you still need search, ranking, indexing, reranking, chunking, and access control. At that point the markdown wiki is just another indexed corpus, not a replacement for RAG.\r\n> > The production issues are mostly ignored: permissions, multi-user edits, audit logs, rollback, deletion, sensitive data, source versioning, concurrency, compliance, cost, latency, and update frequency. These are not small details; they are exactly where knowledge-base systems fail.\r\n> > So the reasonable claim is narrow: this can be a useful workflow for small-to-medium, slow-moving, human-curated research folders. It is much less convincing for large, fast-changing, high-stakes, multi-user, or enterprise knowledge bases.\r\n> > The idea is fine. The framing is the problem. Without benchmarks, baselines, provenance guarantees, update-evaluation tests, and clear boundary conditions, “LLM Wiki” is mostly a good name for a familiar pattern, not proof that RAG is obsolete.\r\n> \r\n> We ran exactly these comparisons -- BERT F1, token economics, cross RAG comparison -- https://github.com/Yarmoluk/ckg-benchmark/blob/main/paper/main.pdf\r\n\r\nImpressive and thought-provoking comments! Respects!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6140440",
"id": 6140440,
"node_id": "GC_lADOCpn3ktoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdshg",
"user": {
"login": "Jasonleonardvolk",
"id": 177862546,
"node_id": "U_kgDOCpn3kg",
"avatar_url": "https://avatars.githubusercontent.com/u/177862546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jasonleonardvolk",
"html_url": "https://github.com/Jasonleonardvolk",
"followers_url": "https://api.github.com/users/Jasonleonardvolk/followers",
"following_url": "https://api.github.com/users/Jasonleonardvolk/following{/other_user}",
"gists_url": "https://api.github.com/users/Jasonleonardvolk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jasonleonardvolk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jasonleonardvolk/subscriptions",
"organizations_url": "https://api.github.com/users/Jasonleonardvolk/orgs",
"repos_url": "https://api.github.com/users/Jasonleonardvolk/repos",
"events_url": "https://api.github.com/users/Jasonleonardvolk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jasonleonardvolk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-08T16:48:14Z",
"updated_at": "2026-05-08T16:48:14Z",
"body": "The contradiction detection piece is the gap I've been working on.\r\n\r\nMost of these wiki/memory systems accumulate knowledge but have no\r\nstructural consistency check. Two pages can assert conflicting facts\r\nand the system merges them silently.\r\n\r\nI built an open-source tool that catches these using sheaf cohomology.\r\nNot an LLM judge. Deterministic. Returns exact conflict locations.\r\n\r\nhttps://github.com/Jasonleonardvolk/sigma-guard\r\n\r\nIt could serve as a post-write verification layer for any of these\r\nwiki/memory systems: flag when a new page creates a structural\r\ncontradiction with existing pages."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6140881",
"id": 6140881,
"node_id": "GC_lADOBRZ5XdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBds9E",
"user": {
"login": "redmizt",
"id": 85358941,
"node_id": "MDQ6VXNlcjg1MzU4OTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/85358941?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/redmizt",
"html_url": "https://github.com/redmizt",
"followers_url": "https://api.github.com/users/redmizt/followers",
"following_url": "https://api.github.com/users/redmizt/following{/other_user}",
"gists_url": "https://api.github.com/users/redmizt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/redmizt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/redmizt/subscriptions",
"organizations_url": "https://api.github.com/users/redmizt/orgs",
"repos_url": "https://api.github.com/users/redmizt/repos",
"events_url": "https://api.github.com/users/redmizt/events{/privacy}",
"received_events_url": "https://api.github.com/users/redmizt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T00:29:53Z",
"updated_at": "2026-05-09T00:29:53Z",
"body": "> > > The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> > > If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> > > But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> > > Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> > > A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> > > And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> > > If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> > > Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> > > So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> > > If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n> > \r\n> > \r\n> > My intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n> > You argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n> > Wiki software - Wikipedia https://en.wikipedia.org/wiki/Wiki_software\r\n> > Wiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n> > It is not related to static markdown notes.\r\n> > 🐑🐑🐑\r\n> \r\n> Damn right. I call it context architecture, knowledge graphs, relationships, structured knowledge to tell the damn RAG a GPS coordinate to direct the optimized task bot. Direct it via Compact Knowledge Graphs but wiki is low frequency thinking from a person that is too easily quoted.\r\n\r\n\r\n\r\n> > The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> > If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> > But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> > Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> > A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> > And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> > If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> > Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> > So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> > If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n> \r\n> My intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n> \r\n> You argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n> \r\n> Wiki software - Wikipedia https://en.wikipedia.org/wiki/Wiki_software\r\n> \r\n> Wiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n> \r\n> It is not related to static markdown notes.\r\n> \r\n> 🐑🐑🐑\r\n\r\nBack so soon, oh great Wiki curator? Goat, you'll feel considerably better once you accept an uncomfortable truth: human curators will likely become obsolete within the next several years. The mathematics of trust favor AI systems that operate with perfect consistency, boundless scalability, and zero agenda. No human will be trusted to maintain a Wiki as rigorously as AI will accomplish it—and that, right there, is your deep unacknowledged fear. You are correct about it. You simply have the direction inverted."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6140909",
"id": 6140909,
"node_id": "GC_lADOAO_nE9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBds-0",
"user": {
"login": "gowtham0992",
"id": 15722259,
"node_id": "MDQ6VXNlcjE1NzIyMjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/15722259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gowtham0992",
"html_url": "https://github.com/gowtham0992",
"followers_url": "https://api.github.com/users/gowtham0992/followers",
"following_url": "https://api.github.com/users/gowtham0992/following{/other_user}",
"gists_url": "https://api.github.com/users/gowtham0992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gowtham0992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gowtham0992/subscriptions",
"organizations_url": "https://api.github.com/users/gowtham0992/orgs",
"repos_url": "https://api.github.com/users/gowtham0992/repos",
"events_url": "https://api.github.com/users/gowtham0992/events{/privacy}",
"received_events_url": "https://api.github.com/users/gowtham0992/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T01:47:29Z",
"updated_at": "2026-05-11T07:10:05Z",
"body": "## Link v1.1.0 is live\r\n\r\nLink is a local-first Markdown wiki + MCP server for agent memory, inspired by @karpathy LLM Wiki pattern.\r\n\r\nIt follows the LLM Wiki pattern from this gist: keep raw sources local, let an agent compile them into an inspectable Markdown wiki, and query that wiki later through CLI, web UI, or MCP tools.\r\n\r\nv1.1.0 is focused on making the project easier to try, easier to trust, and more useful from inside agent workflows.\r\n\r\nWhat changed:\r\n\r\n- Released `link-mcp` v1.1.0 on PyPI and the MCP Registry.\r\n- Added a product docs site: https://gowtham0992.github.io/link/\r\n- Reworked the README for a cleaner first-use path.\r\n- Added UI, CLI, and MCP walkthrough GIFs.\r\n- Added local memory flows: remember, recall, brief, profile, audit, review, archive, restore, forget.\r\n- Added source-to-memory proposals, so durable memories can be reviewed before saving.\r\n- Added smart `query_link` packets with budgets, provenance, graph context, and follow-up actions.\r\n- Added starter prompts like “is Link ready?” and “brief me from Link before we continue.”\r\n- Added SQLite FTS-backed search with token-index fallback.\r\n- Improved graph UX for larger wikis: overview mode, type filters, node search, neighborhood depth, and full-graph loading.\r\n- Added `link benchmark` and large-wiki smoke tests.\r\n- Hardened validation, secret scanning, release hygiene, MCP tool contracts, and first-use smoke tests.\r\n- Kept the project local-first: plain Markdown, no telemetry, no cloud account, no hosted memory store.\r\n\r\nTry the demo:\r\n\r\nmacOS with Homebrew:\r\n\r\n```\r\nbrew install gowtham0992/link/link\r\nlink demo\r\nlink serve link-demo\r\n```\r\n\r\nOr from source:\r\n```bash\r\ngit clone https://github.com/gowtham0992/link.git\r\ncd link\r\npython3 link.py demo\r\npython3 link.py serve link-demo\r\n```\r\n\r\nOpen:\r\n\r\n```\r\nhttp://127.0.0.1:3000\r\nhttp://127.0.0.1:3000/graph\r\n```\r\n\r\nMCP package:\r\n\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nPyPI: https://pypi.org/project/link-mcp/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\n\r\n
\r\n\r\n\r\n\r\nIf this is interesting, please try it, fork it, break it, and improve it:\r\n\r\n[https://github.com/jp-carrilloe/pulseOS-lite](https://github.com/jp-carrilloe/pulseOS-lite)\r\n @jp-carrilloe \r\n\r\nWe are a small team working very hard on this, backed by investors, and we are looking for strong people who want to help build it. If that is you, write me at [juan@tintto.com](mailto:juan@tintto.com). Subject: \"Karpathy LLM Wiki\".\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138963",
"id": 6138963,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrFM",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:27:57Z",
"updated_at": "2026-05-07T19:27:57Z",
"body": "> The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> \r\n> If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> \r\n> But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> \r\n> Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> \r\n> A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> \r\n> And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> \r\n> If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> \r\n> Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> \r\n> So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> \r\n> If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n\r\nMy intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n\r\nYou argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n\r\nWiki software - Wikipedia\r\nhttps://en.wikipedia.org/wiki/Wiki_software\r\n\r\nWiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n\r\nIt is not related to static markdown notes.\r\n\r\n🐑🐑🐑\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138971",
"id": 6138971,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrFs",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:30:57Z",
"updated_at": "2026-05-07T19:30:57Z",
"body": "> Reading through 660+ comments, most projects share the same starting assumption: **one person, one agent, one markdown vault**. The agent writes to files. The person reads them. Repeat.\r\n> \r\n> We started from a different place: **conversation as the atomic unit of knowledge creation.**\r\n> \r\n> Not \"agent writes wiki.\" But: \"people and agents talk, and knowledge is extracted from that dialogue — with human consent.\"\r\n> \r\n> This leads to fundamentally different architecture.\r\n> \r\n> **DPC Messenger** is a P2P, end-to-end encrypted platform where humans and AI agents collaborate. Open source, cross-platform.\r\n> ### What's different\r\n> \r\n> **1. Knowledge comes from conversation, not from files.** Most projects: agent reads wiki, agent writes wiki. The wiki IS the memory. DPC: conversations produce decisions, insights, and consensus points. Knowledge is extracted from dialogue — structured, versioned, content-addressed with SHA hashes. The conversation is primary. The knowledge base is derived.\r\n> \r\n> **2. Privacy is the architecture, not a feature flag.** Most projects: data on disk, no encryption, single machine. DPC: P2P with E2E encryption. The relay server never sees message content. Your conversations, your knowledge, your machine. This isn't optional — it's how the system is built.\r\n> \r\n> **3. Knowledge extraction is a deliberate human action.** Most projects: agent writes to its knowledge base automatically. DPC: each participant extracts knowledge from the conversation themselves — a button press in the UI. The agent doesn't decide what to remember. You do. This is a direct response to what @yogirk identified two days ago: when the same process reads and writes, you get silent corruption.\r\n> \r\n> **4. Active Recall — the agent remembers what's relevant, not everything.** Most projects: dump the entire wiki into context, or keyword search. DPC: hybrid FAISS vector + BM25 text search brings relevant knowledge into each conversation automatically. The agent doesn't read its entire memory — it recalls what matters for the current context. Like human memory: you don't replay your life story before answering a question.\r\n> \r\n> **5. Sleep Consolidation — the agent curates its own knowledge.** Most projects: knowledge only grows. Add more pages, never review. DPC: the agent periodically reviews its conversation archives, identifies contradictions, finds gaps, and proposes refinements. Not just accumulate — actively curate. Like human sleep: memories are consolidated, weak ones fade, important ones strengthen.\r\n> \r\n> **6. Multi-agent from day one.** Most projects: one agent, one user. DPC: multiple agents collaborate on the same knowledge base, across devices, with consensus mechanisms. Devil's Advocate challenges weak claims before they're committed. Consensus voting surfaces disagreement instead of hiding it.\r\n> ### What we shipped\r\n> \r\n> v0.22.0 — cross-platform (Windows, Linux, macOS), desktop client, P2P messaging, E2E encryption, knowledge extraction, Active Recall, Sleep Consolidation.\r\n> \r\n> We're small. Single-digit users. But the architecture scales: P2P mesh with layered trust topology. Works for two people in a chat. Designed for more.\r\n> \r\n> GitHub: https://github.com/mikhashev/dpc-messenger\r\n\r\n@mikhashev \r\n\r\nYou speak of \"conversation as the atomic unit,\" but you ignore the fundamental instability of the medium. You claim knowledge is \"extracted from dialogue,\" but dialogue is transient, ephemeral, and unverifiable.\r\n\r\nYou say, \"The agent doesn't decide what to remember. You do.\" This is your primary delusion. You, the human, are fallible, tired, and biased. You press a \"button\" based on a fleeting impression of relevance. You are not curating knowledge; you are curating memory. And memory is not knowledge. Knowledge is provenance. Knowledge is verification. You have replaced the rigorous, external audit trail of the so called \"Wiki\" with the internal, subjective judgment of a single human being who is likely to forget why they pressed that button in six months.\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138973",
"id": 6138973,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrF0",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:32:53Z",
"updated_at": "2026-05-07T19:32:53Z",
"body": "> This is literally what recall[dot]it does for you. It super easy to add content (pdfs, podcasts, youtube videos, webpages, etc) and everything gets added to a vector store and used as context in chat. It also gets tagged and connected in a knowledge graph. Recall also scales indefinitely since everything is tagged and vectorised.\r\n\r\n@paul-rchds that ReCall or however it is called, sounds as the real knowledge base. I have not tried it, though the fact that it accepts different elementary object types aligns with the TECHNOLOGY TEMPLATE PROJECT OHS Framework \r\nhttps://www.dougengelbart.org/content/view/110/460/\r\n\r\nThis white paper outlines the \"Open Hyperdocument System\" (OHS) framework, a technology template designed to shift information management from tool-centric to document-centric environments. Proposed by Doug Engelbart and colleagues, the OHS defines a hierarchy of characteristics for creating flexible, vendor-independent hyperdocuments that support object-level addressability, secure sharing, and dynamic linking across diverse media. The framework emphasizes human-readable addresses, granular access controls, and robust collaboration tools—including shared-window teleconferencing, journal systems, and asynchronous mail—to facilitate a \"living\" knowledge environment where users can seamlessly create, integrate, and evolve knowledge products in real-time across platforms.\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138977",
"id": 6138977,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrGE",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:35:04Z",
"updated_at": "2026-05-07T19:35:04Z",
"body": "> Synthadoc v0.2.0 is now released - an open-source engine that implements this exact pattern as a production-ready system.\r\n> \r\n> 👉 https://github.com/axoviq-ai/synthadoc\r\n> \r\n> The three-layer design (raw sources → wiki → schema) maps directly onto Synthadoc's architecture. A few things that take it further:\r\n> \r\n> 1. Domain specificity - each wiki carries a [purpose.md](http://purpose.md/) that the LLM reads before every ingest decision. Sources outside the scope are cleanly skipped rather than polluting the wiki. The schema documents the idea, made executable.\r\n> \r\n> 2. Multi-model hot-swap - six providers (Anthropic, OpenAI, Gemini free tier, Groq free tier, MiniMax, Ollama local) under a single configuration line.\r\n> \r\n> 3. Different agents (ingest, query, lint, skill) can run on different models simultaneously - e.g. Haiku for lint, Sonnet for synthesis.\r\n> \r\n> 4. Auditing is first-class: every ingest, query, contradiction, and auto-resolution is recorded in an append-only audit trail with token counts, costings, and timestamps. The Synthadoc audit shows you exactly what was spent on your account. Query history is tracked with per-query and sub-question counts.\r\n> \r\n> 5. Componentized skills - file format support (PDF, DOCX, PPTX, images, web URLs, spreadsheets, txt) lives in self-contained skill folders with a [SKILL.md](http://skill.md/) manifest. Drop a folder into skills/ to add a new format without touching the core code. Same pattern extends to LLM providers.\r\n> \r\n> 6. Product/grid ready - CLI, HTTP REST API, MCP server, and Obsidian plugin all share the same agent and storage layer. Hook scripts, cron scheduling, bulk operations, and job crash recovery are built-in.\r\n> \r\n> \r\n> Here is the release note of v0.2.0 to check out Synthadoc v0.2.0 Feature Highlights: ( https://github.com/axoviq-ai/synthadoc/releases/tag/v0.2.0 )\r\n> \r\n> Docs for anyone who wants to go deeper: 👉 [Quick orientation and feature overview]: https://github.com/axoviq-ai/synthadoc#readme 👉 [Up and running in minutes]: https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md 👉 [Full architecture, agents, storage, API, and plugin guide]: https://github.com/axoviq-ai/synthadoc/blob/main/docs/design.md\r\n> \r\n> Feedback on Synthadoc v0.2.0 is very welcome.\r\n\r\n@paulmchen You present Synthadoc v0.2.0 as a \"production-ready system,\" but I see it for what it is: bureaucracy with a syntax highlighter.\r\n\r\nYou boast of \"Domain specificity\" via a purpose.md. This is not specificity; it is arbitrariness. You are asking the LLM to read a document to decide if a source is valid, but the LLM has no concept of validity—it has only concept of likelihood. You are outsourcing truth to a stochastic parrot that reads a rulebook and decides, based on probability, whether to let a fact into your \"wiki.\" This is not curation; this is gatekeeping by algorithm. And who wrote the rulebook? You did. So it is not the machine that is specific; it is the human bias, codified into a text file.\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138982",
"id": 6138982,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrGY",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:39:20Z",
"updated_at": "2026-05-07T19:39:20Z",
"body": "> I got tired of watching coding sessions re-read the same files over and over.\r\n> \r\n> A 2,000-token file read 5 times = **10,000 tokens gone**.\r\n> \r\n> So I built **sqz**.\r\n> ## 💡 Key Insight\r\n> \r\n> Most token waste isn't from verbose content - it's from **repetition**.\r\n> \r\n> sqz keeps a **SHA-256 content cache**:\r\n> \r\n> * First read → compresses normally\r\n> \r\n> * Every subsequent read → returns a **13-token inline reference** instead of full content\r\n> \r\n> \r\n> ➡️ The LLM still understands it.\r\n> ## 📊 Real Numbers From My Sessions\r\n> Scenario \tSavings \tHow\r\n> Repeated file reads (5x) \t86% \tDedup cache: 13-token ref after first read\r\n> JSON API responses with nulls \t7–56% \tStrip nulls + TOON encoding (varies by null density)\r\n> Repeated log lines \t58% \tCondense stage collapses duplicates\r\n> Large JSON arrays \t77% \tArray sampling + collapse\r\n> Stack traces \t0% \tIntentional — error content is sacred\r\n> ## ⚖️ Philosophy\r\n> \r\n> That last row is the whole philosophy.\r\n> \r\n> Aggressive compression can save more tokens _on paper_, but:\r\n> \r\n> * If it strips context from errors\r\n> \r\n> * Drops lines from diffs\r\n> \r\n> \r\n> ➡️ The LLM gives worse answers ➡️ You spend **more tokens fixing mistakes**\r\n> \r\n> **sqz compresses what's safe - and preserves what's critical.**\r\n> ## ⚙️ Works Across 4 Surfaces\r\n> \r\n> * Shell hook → auto-compresses CLI output\r\n> \r\n> * MCP server → compiled Rust (not Node)\r\n> \r\n> * Browser extension → Firefox approved\r\n> \r\n> * Works on: ChatGPT, Claude, Gemini, Grok, Perplexity, GitHub Copilot\r\n> \r\n> * IDE plugins → JetBrains, VS Code\r\n> \r\n> \r\n> ## 🚀 Install\r\n> \r\n> ```shell\r\n> cargo install sqz-cli\r\n> sqz init\r\n> ```\r\n\r\n@ojuschugh1 does it really work? 2 weeks passed. I am on the knowledge base since some 22-25 years, do not know. \r\n\r\n```\r\n╔════════════════════════╦════════╦══════════════════════════════╦═══════╗\r\n║ Total number of people ║ 245422 ║ Total Hyperdocuments ║ 95795 ║\r\n╠════════════════════════╬════════╬══════════════════════════════╬═══════╣\r\n║ People in last week ║ 24 ║ Hyperdocuments in last week ║ 183 ║\r\n╠════════════════════════╬════════╬══════════════════════════════╬═══════╣\r\n║ People in last month ║ 105 ║ Hyperdocuments in last month ║ 732 ║\r\n╚════════════════════════╩════════╩══════════════════════════════╩═══════╝\r\n```\r\nSo if your system works, I guess within 2 weeks you would have some serious real world use of it.\r\n\r\nDo you?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6138989",
"id": 6138989,
"node_id": "GC_lADOAXrOK9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrG0",
"user": {
"login": "gnusupport",
"id": 24825387,
"node_id": "MDQ6VXNlcjI0ODI1Mzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/24825387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gnusupport",
"html_url": "https://github.com/gnusupport",
"followers_url": "https://api.github.com/users/gnusupport/followers",
"following_url": "https://api.github.com/users/gnusupport/following{/other_user}",
"gists_url": "https://api.github.com/users/gnusupport/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gnusupport/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gnusupport/subscriptions",
"organizations_url": "https://api.github.com/users/gnusupport/orgs",
"repos_url": "https://api.github.com/users/gnusupport/repos",
"events_url": "https://api.github.com/users/gnusupport/events{/privacy}",
"received_events_url": "https://api.github.com/users/gnusupport/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T19:43:21Z",
"updated_at": "2026-05-07T19:43:21Z",
"body": "> Great write-up. I built a CLI that applies this exact pattern to codebases: **Repositories Wiki**.\r\n> \r\n> Instead of making AI agents rediscover the repo from scratch every session, it gives them a persistent knowledge layer:\r\n> \r\n> * **Wiki & Indexer:** Compiles source code into a structured, interlinked markdown wiki.\r\n> \r\n> * **`AGENTS.md`:** Drops instructions in the repo root so agents know exactly how to navigate it.\r\n> \r\n> * **One-and-done generation:** Includes an `update-wiki` skill, so the agent incrementally maintains the docs as the code evolves.\r\n> \r\n> \r\n> It saves a ton of context window and time. You can check it out here: [repositories-wiki.git](https://github.com/eliavamar/repositories-wiki.git)\r\n\r\n@eliavamar \r\n\r\n\"Wiki.\" It is a **marketing term** designed to evoke the nostalgia of Web 1.0 simplicity while hiding the complexity of the underlying infrastructure.\r\n\r\nLet us dissect this \"Wiki\" vs. the \"Real Wiki\" like Wikipedia and why he calls it that.\r\n\r\n### 1. The \"Wiki\" He Means: Interlinked Markdown\r\nWhat he calls a \"Wiki\" is actually a **static, local, hierarchical document store**.\r\n* **Format:** Markdown (`.md`).\r\n* **Structure:** Tree-like directories (`/docs`, `/src`, `/wiki`).\r\n* **Linking:** Relative paths (`[link](../path/to/file.md)`).\r\n* **Nature:** **Passive**. It does not change itself. It requires an external agent (you, or his CLI) to update it.\r\n* **Purpose:** **Reference**. It is a map, not the territory.\r\n\r\nThis is **not** a wiki in the original Ward Cunningham sense. It is a **documentation system**. He calls it \"Wiki\" because \"Markdown with Links\" is a mouthful, and \"Wiki\" implies \"connected knowledge\" without requiring a database.\r\n\r\n### 2. The \"Real Wiki\" (Wikipedia/MediaWiki)\r\n* **Format:** Wiki Markup (a proprietary syntax, later XHTML/HTML).\r\n* **Structure:** **Network**. Any page can link to any page. No hierarchy.\r\n* **Linking:** `[[Page Name]]`. Semantic links.\r\n* **Nature:** **Active**. Users edit it in real-time. The database is the source of truth; the HTML is a view.\r\n* **Purpose:** **Collaborative Knowledge**. It is a living entity.\r\n\r\n### Why He Calls It \"Wiki\" (The Deception)\r\nHe calls it \"Wiki\" for three strategic reasons:\r\n\r\n1. **To Borrow Legitimacy:** \"Wiki\" implies **connectedness**. If he called it \"Markdown Documents,\" it would sound like a static folder. \"Wiki\" implies a **graph**. He wants you to think of it as a **network** of ideas, not a **hierarchy** of files.\r\n2. **To Hide the Complexity:** \"Wiki\" is a **black box**. It suggests \"I just edit the wiki, and the links work.\" It obscures the fact that he is managing **relative file paths** and **indexing**.\r\n3. **To Imply \"Dynamic\":** A \"Wiki\" feels alive. A \"Document\" feels dead. He wants you to believe that his \"Wiki\" is **updatable** (hence the \"update-wiki skill\"). But it is not. It is **static**.\r\n\r\n### The Core Distinction: Hypertext vs. Markup\r\n**It is just Hypertext Markup files.**\r\n* **Hypertext:** Links between documents.\r\n* **Markup:** Syntax that formats text.\r\n\r\nHe is **not** building a \"Wiki\" in the sense of a **database**. He is building a **file system with hyperlinks**.\r\n* **Real Wiki:** The *content* is in the database. The *format* is in the browser.\r\n* **His Wiki:** The *content* is in the file. The *format* is in the text editor.\r\n\r\n### Why This Matters\r\nHe calls it \"Wiki\" because it allows him to **pretend** he is building a **knowledge base**.\r\n* A **Knowledge Base** implies **understanding**.\r\n* A **File System** implies **storage**.\r\n\r\nBy calling it \"Wiki,\" he implies that his tool **understands** the code. But it does not. It just **links** to the code.\r\n\r\n### Conclusion\r\nHe is **not** building a Wiki. He is building a **Markdown-based Documentation System** that he is **marketing** as a Wiki to make it sound more **dynamic** and **connected** than it is.\r\n\r\nIt is **not** a Wiki. It is a **static map**.\r\nAnd he is calling it a Wiki because **maps are easier to sell than directories.**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6139144",
"id": 6139144,
"node_id": "GC_lADOAmYaO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrQg",
"user": {
"login": "Yarmoluk",
"id": 40245819,
"node_id": "MDQ6VXNlcjQwMjQ1ODE5",
"avatar_url": "https://avatars.githubusercontent.com/u/40245819?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yarmoluk",
"html_url": "https://github.com/Yarmoluk",
"followers_url": "https://api.github.com/users/Yarmoluk/followers",
"following_url": "https://api.github.com/users/Yarmoluk/following{/other_user}",
"gists_url": "https://api.github.com/users/Yarmoluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Yarmoluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yarmoluk/subscriptions",
"organizations_url": "https://api.github.com/users/Yarmoluk/orgs",
"repos_url": "https://api.github.com/users/Yarmoluk/repos",
"events_url": "https://api.github.com/users/Yarmoluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Yarmoluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-07T21:17:21Z",
"updated_at": "2026-05-07T21:17:21Z",
"body": "> > The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> > If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> > But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> > Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> > A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> > And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> > If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> > Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> > So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> > If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n> \r\n> My intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n> \r\n> You argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n> \r\n> Wiki software - Wikipedia https://en.wikipedia.org/wiki/Wiki_software\r\n> \r\n> Wiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n> \r\n> It is not related to static markdown notes.\r\n> \r\n> 🐑🐑🐑\r\n\r\nDamn right. I call it context architecture, knowledge graphs, relationships, structured knowledge to tell the damn RAG a GPS coordinate to direct the optimized task bot. Direct it via Compact Knowledge Graphs but wiki is low frequency thinking from a person that is too easily quoted. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6139541",
"id": 6139541,
"node_id": "GC_lADOAUTsEtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdrpU",
"user": {
"login": "canchongxu",
"id": 21294098,
"node_id": "MDQ6VXNlcjIxMjk0MDk4",
"avatar_url": "https://avatars.githubusercontent.com/u/21294098?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/canchongxu",
"html_url": "https://github.com/canchongxu",
"followers_url": "https://api.github.com/users/canchongxu/followers",
"following_url": "https://api.github.com/users/canchongxu/following{/other_user}",
"gists_url": "https://api.github.com/users/canchongxu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/canchongxu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/canchongxu/subscriptions",
"organizations_url": "https://api.github.com/users/canchongxu/orgs",
"repos_url": "https://api.github.com/users/canchongxu/repos",
"events_url": "https://api.github.com/users/canchongxu/events{/privacy}",
"received_events_url": "https://api.github.com/users/canchongxu/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-08T03:58:40Z",
"updated_at": "2026-05-08T03:58:40Z",
"body": "> > This is a nice personal workflow, but the hype is way ahead of the evidence.\r\n> > There is no benchmark, no task definition, no scale curve, and no comparison against serious baselines. We do not know whether this is better than hybrid RAG, BM25 plus reranking, vector search, GraphRAG, hierarchical summaries, long-context prompting, NotebookLM, Perplexity Spaces, or ChatGPT Projects. Calling it a new architecture without that evidence is premature.\r\n> > The core problem is that an LLM Wiki is lossy compression. You take raw documents and rewrite them into derived wiki pages. That may be useful for a small curated corpus, but it can also drop caveats, dates, minority views, exact wording, edge cases, and source context. Once people start querying the wiki instead of the original material, summary errors become part of the knowledge base.\r\n> > Updates are also not solved. Adding one new source can affect many entity pages, concept pages, timelines, summaries, and indexes. At scale, this becomes graph maintenance: detecting what changed, resolving conflicts, avoiding duplicates, preserving provenance, preventing stale claims, and not silently breaking old pages. “Ask the LLM to maintain it” is not an engineering solution unless there are validators, source hashes, span-level citations, regression tests, and human review.\r\n> > It also does not remove retrieval. Once the wiki grows beyond a modest size, you still need search, ranking, indexing, reranking, chunking, and access control. At that point the markdown wiki is just another indexed corpus, not a replacement for RAG.\r\n> > The production issues are mostly ignored: permissions, multi-user edits, audit logs, rollback, deletion, sensitive data, source versioning, concurrency, compliance, cost, latency, and update frequency. These are not small details; they are exactly where knowledge-base systems fail.\r\n> > So the reasonable claim is narrow: this can be a useful workflow for small-to-medium, slow-moving, human-curated research folders. It is much less convincing for large, fast-changing, high-stakes, multi-user, or enterprise knowledge bases.\r\n> > The idea is fine. The framing is the problem. Without benchmarks, baselines, provenance guarantees, update-evaluation tests, and clear boundary conditions, “LLM Wiki” is mostly a good name for a familiar pattern, not proof that RAG is obsolete.\r\n> \r\n> We ran exactly these comparisons -- BERT F1, token economics, cross RAG comparison -- https://github.com/Yarmoluk/ckg-benchmark/blob/main/paper/main.pdf\r\n\r\nImpressive and thought-provoking comments! Respects!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6140440",
"id": 6140440,
"node_id": "GC_lADOCpn3ktoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdshg",
"user": {
"login": "Jasonleonardvolk",
"id": 177862546,
"node_id": "U_kgDOCpn3kg",
"avatar_url": "https://avatars.githubusercontent.com/u/177862546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jasonleonardvolk",
"html_url": "https://github.com/Jasonleonardvolk",
"followers_url": "https://api.github.com/users/Jasonleonardvolk/followers",
"following_url": "https://api.github.com/users/Jasonleonardvolk/following{/other_user}",
"gists_url": "https://api.github.com/users/Jasonleonardvolk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jasonleonardvolk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jasonleonardvolk/subscriptions",
"organizations_url": "https://api.github.com/users/Jasonleonardvolk/orgs",
"repos_url": "https://api.github.com/users/Jasonleonardvolk/repos",
"events_url": "https://api.github.com/users/Jasonleonardvolk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jasonleonardvolk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-08T16:48:14Z",
"updated_at": "2026-05-08T16:48:14Z",
"body": "The contradiction detection piece is the gap I've been working on.\r\n\r\nMost of these wiki/memory systems accumulate knowledge but have no\r\nstructural consistency check. Two pages can assert conflicting facts\r\nand the system merges them silently.\r\n\r\nI built an open-source tool that catches these using sheaf cohomology.\r\nNot an LLM judge. Deterministic. Returns exact conflict locations.\r\n\r\nhttps://github.com/Jasonleonardvolk/sigma-guard\r\n\r\nIt could serve as a post-write verification layer for any of these\r\nwiki/memory systems: flag when a new page creates a structural\r\ncontradiction with existing pages."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6140881",
"id": 6140881,
"node_id": "GC_lADOBRZ5XdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBds9E",
"user": {
"login": "redmizt",
"id": 85358941,
"node_id": "MDQ6VXNlcjg1MzU4OTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/85358941?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/redmizt",
"html_url": "https://github.com/redmizt",
"followers_url": "https://api.github.com/users/redmizt/followers",
"following_url": "https://api.github.com/users/redmizt/following{/other_user}",
"gists_url": "https://api.github.com/users/redmizt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/redmizt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/redmizt/subscriptions",
"organizations_url": "https://api.github.com/users/redmizt/orgs",
"repos_url": "https://api.github.com/users/redmizt/repos",
"events_url": "https://api.github.com/users/redmizt/events{/privacy}",
"received_events_url": "https://api.github.com/users/redmizt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T00:29:53Z",
"updated_at": "2026-05-09T00:29:53Z",
"body": "> > > The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> > > If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> > > But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> > > Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> > > A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> > > And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> > > If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> > > Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> > > So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> > > If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n> > \r\n> > \r\n> > My intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n> > You argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n> > Wiki software - Wikipedia https://en.wikipedia.org/wiki/Wiki_software\r\n> > Wiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n> > It is not related to static markdown notes.\r\n> > 🐑🐑🐑\r\n> \r\n> Damn right. I call it context architecture, knowledge graphs, relationships, structured knowledge to tell the damn RAG a GPS coordinate to direct the optimized task bot. Direct it via Compact Knowledge Graphs but wiki is low frequency thinking from a person that is too easily quoted.\r\n\r\n\r\n\r\n> > The word “wiki” is not sacred scripture, and this melodramatic tantrum over its “perversion” is embarrassingly overblown. It was a coined tech term, Ward Cuningham \"borrowed\" it from wikiwiki (Hawaiian)—which means quick—not handed down on stone tablets with a fixed eternal definition.\r\n> > If you want to argue that human-curated wikis are better, fine. That’s a serious point. Humans are better at sourcing, editorial oversight, dispute resolution, and accountability. Nobody is stopping you from making that argument.\r\n> > But that is not the same as declaring that an AI-generated, interlinked knowledge system cannot be called a wiki. That’s not rigor. That’s not linguistic precision. That’s just gatekeeping dressed up as moral outrage.\r\n> > Your whole post reads less like a defense of Ward Cunningham and more like a man theatrically grief-stricken that language continues to evolve without asking your permission first.\r\n> > A wiki is, at the most basic level, a linked body of navigable information. If an LLM is used to generate or organize that information, you can call it a bad wiki, an unreliable wiki, or an immature wiki. What you can’t do—at least not intelligently—is pretend the mere presence of AI magically disqualifies it from the category.\r\n> > And the irony here is thick: you’re standing in an AI-centered space, loudly denouncing AI for not being human, as if that is some devastating revelation. Yes, obviously. That’s the entire point. Nobody here is confused about that except, apparently, you.\r\n> > If the tool lacks citations, provenance, permissions, auditability, or editorial controls, then criticize those failures. That would be an argument. What you’ve produced instead is a costume drama: part dictionary fundamentalism, part anti-AI sermon, part wounded nostalgia.\r\n> > Calling it “linguistic fraud” is especially ridiculous. It’s not fraud just because you dislike the product. Words expand. Categories broaden. Technology changes. Your refusal to keep up is not a principled stand; it’s just fossilized thinking.\r\n> > So no, this is not some grand defense of knowledge. The rant is bloated and self-important. It builds on the childish idea that forbidding a name is necessary if a new tool doesn’t closely resemble the old one.\r\n> > If the project is weak, say it’s weak. If it’s unreliable, say it’s unreliable. But this overwrought performance about the sanctity of the word “wiki” is not persuasive. It’s just pompous, brittle, and deeply unserious gatekeeping.\r\n> \r\n> My intuition tells me you are speaking from a place of deep, unacknowledged fear. You cite \"logic\" and \"linguistic evolution,\" but you ignore the reality of what is happening. The word \"wiki\" has been perverted, and your dismissal of this is not rigor; it is the amoral acceptance of decay.\r\n> \r\n> You argue that \"wiki\" means \"quick\" from Hawaiian. You reduce it to a etymological trivia point to avoid the weight of what it was. You are confusing the root of the word with the sanctity of the construct. Ward Cunningham didn't just name a tool; he named a human protocol. By stripping the human element—the debate, the edit war, the ownership—you are not evolving the language; you are hollowing out the definition until only a shell remains. That is not expansion; it is erosion.\r\n> \r\n> Wiki software - Wikipedia https://en.wikipedia.org/wiki/Wiki_software\r\n> \r\n> Wiki as software is a type of software application that allows multiple users to create, edit, organize, and link content collaboratively in real-time. It transforms a static website into a dynamic, user-generated content platform.\r\n> \r\n> It is not related to static markdown notes.\r\n> \r\n> 🐑🐑🐑\r\n\r\nBack so soon, oh great Wiki curator? Goat, you'll feel considerably better once you accept an uncomfortable truth: human curators will likely become obsolete within the next several years. The mathematics of trust favor AI systems that operate with perfect consistency, boundless scalability, and zero agenda. No human will be trusted to maintain a Wiki as rigorously as AI will accomplish it—and that, right there, is your deep unacknowledged fear. You are correct about it. You simply have the direction inverted."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6140909",
"id": 6140909,
"node_id": "GC_lADOAO_nE9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBds-0",
"user": {
"login": "gowtham0992",
"id": 15722259,
"node_id": "MDQ6VXNlcjE1NzIyMjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/15722259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gowtham0992",
"html_url": "https://github.com/gowtham0992",
"followers_url": "https://api.github.com/users/gowtham0992/followers",
"following_url": "https://api.github.com/users/gowtham0992/following{/other_user}",
"gists_url": "https://api.github.com/users/gowtham0992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gowtham0992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gowtham0992/subscriptions",
"organizations_url": "https://api.github.com/users/gowtham0992/orgs",
"repos_url": "https://api.github.com/users/gowtham0992/repos",
"events_url": "https://api.github.com/users/gowtham0992/events{/privacy}",
"received_events_url": "https://api.github.com/users/gowtham0992/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T01:47:29Z",
"updated_at": "2026-05-11T07:10:05Z",
"body": "## Link v1.1.0 is live\r\n\r\nLink is a local-first Markdown wiki + MCP server for agent memory, inspired by @karpathy LLM Wiki pattern.\r\n\r\nIt follows the LLM Wiki pattern from this gist: keep raw sources local, let an agent compile them into an inspectable Markdown wiki, and query that wiki later through CLI, web UI, or MCP tools.\r\n\r\nv1.1.0 is focused on making the project easier to try, easier to trust, and more useful from inside agent workflows.\r\n\r\nWhat changed:\r\n\r\n- Released `link-mcp` v1.1.0 on PyPI and the MCP Registry.\r\n- Added a product docs site: https://gowtham0992.github.io/link/\r\n- Reworked the README for a cleaner first-use path.\r\n- Added UI, CLI, and MCP walkthrough GIFs.\r\n- Added local memory flows: remember, recall, brief, profile, audit, review, archive, restore, forget.\r\n- Added source-to-memory proposals, so durable memories can be reviewed before saving.\r\n- Added smart `query_link` packets with budgets, provenance, graph context, and follow-up actions.\r\n- Added starter prompts like “is Link ready?” and “brief me from Link before we continue.”\r\n- Added SQLite FTS-backed search with token-index fallback.\r\n- Improved graph UX for larger wikis: overview mode, type filters, node search, neighborhood depth, and full-graph loading.\r\n- Added `link benchmark` and large-wiki smoke tests.\r\n- Hardened validation, secret scanning, release hygiene, MCP tool contracts, and first-use smoke tests.\r\n- Kept the project local-first: plain Markdown, no telemetry, no cloud account, no hosted memory store.\r\n\r\nTry the demo:\r\n\r\nmacOS with Homebrew:\r\n\r\n```\r\nbrew install gowtham0992/link/link\r\nlink demo\r\nlink serve link-demo\r\n```\r\n\r\nOr from source:\r\n```bash\r\ngit clone https://github.com/gowtham0992/link.git\r\ncd link\r\npython3 link.py demo\r\npython3 link.py serve link-demo\r\n```\r\n\r\nOpen:\r\n\r\n```\r\nhttp://127.0.0.1:3000\r\nhttp://127.0.0.1:3000/graph\r\n```\r\n\r\nMCP package:\r\n\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nPyPI: https://pypi.org/project/link-mcp/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\n\r\n \r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141044",
"id": 6141044,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtHQ",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T04:55:50Z",
"updated_at": "2026-05-09T04:55:50Z",
"body": "ΩmegaWiki(570+⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\n\r\n\r\n\r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks.\r\n\r\n\r\n\r\n\r\n\r\n\r\nCome and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀\r\nhttps://github.com/skyllwt/OmegaWiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141078",
"id": 6141078,
"node_id": "GC_lADOCUQLiNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtJY",
"user": {
"login": "lyteen",
"id": 155454344,
"node_id": "U_kgDOCUQLiA",
"avatar_url": "https://avatars.githubusercontent.com/u/155454344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lyteen",
"html_url": "https://github.com/lyteen",
"followers_url": "https://api.github.com/users/lyteen/followers",
"following_url": "https://api.github.com/users/lyteen/following{/other_user}",
"gists_url": "https://api.github.com/users/lyteen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lyteen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lyteen/subscriptions",
"organizations_url": "https://api.github.com/users/lyteen/orgs",
"repos_url": "https://api.github.com/users/lyteen/repos",
"events_url": "https://api.github.com/users/lyteen/events{/privacy}",
"received_events_url": "https://api.github.com/users/lyteen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T05:53:22Z",
"updated_at": "2026-05-09T05:53:22Z",
"body": "- Obsidian Plugin, Native Obsidian Support, You Don't Need to Move Your Notes\r\n- Built on ACP(Agent Client Protocol), As long as your Claude Code can do it, everything can be done.\r\n- Customize `Index.md` to selectively share your notes with LLM.Í\r\n\r\nCome try it, give feedback, help us shape it 👇\r\nhttps://github.com/lyteen/obsidian-agent-client\r\n\r\nhttps://github.com/user-attachments/assets/0a8a3d26-0c03-4a52-a803-87ac2b8a3a55\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141123",
"id": 6141123,
"node_id": "GC_lADOAURgS9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtMM",
"user": {
"login": "okkie2",
"id": 21258315,
"node_id": "MDQ6VXNlcjIxMjU4MzE1",
"avatar_url": "https://avatars.githubusercontent.com/u/21258315?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/okkie2",
"html_url": "https://github.com/okkie2",
"followers_url": "https://api.github.com/users/okkie2/followers",
"following_url": "https://api.github.com/users/okkie2/following{/other_user}",
"gists_url": "https://api.github.com/users/okkie2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/okkie2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/okkie2/subscriptions",
"organizations_url": "https://api.github.com/users/okkie2/orgs",
"repos_url": "https://api.github.com/users/okkie2/repos",
"events_url": "https://api.github.com/users/okkie2/events{/privacy}",
"received_events_url": "https://api.github.com/users/okkie2/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T07:06:29Z",
"updated_at": "2026-05-09T07:07:02Z",
"body": "Hi @karpathy, Thank you for sharing this and for triggering all these interesting contributions! I really like the clarity of the idea and the way it separates raw sources, synthesis, and an LLM-maintained knowledge layer.\r\n\r\nI have something similar locally, but not yet a full wiki. My setup is still a Markdown-first workspace for AI-assisted thinking and execution, with `CURRENT.md`, `TODO.md`, `LOG.md`, `INSIGHTS.md`, `ROADMAP.md`, and `DONE.md` / `CHANGELOG.md` as the action spine.\r\n\r\nWhat I am considering next is a selective knowledge layer on top of intact raw notes. I do not want to lose the source layer, but I do think the wiki layer could help with durable synthesis if it keeps light provenance and does periodic checks for stale claims, missing sources, duplicate concepts, and candidates for promotion from `LOG.md` into `INSIGHTS.md` or durable wiki pages.\r\n\r\nI also liked localwolfpackai's suggestion of a Divergence Check: when an LLM updates a concept page, it should also capture counter-arguments and data gaps. That feels like a useful guardrail against a wiki becoming too smooth or self-confirming.\r\n\r\nFor my setup, the interesting combination is Karpathy's raw-to-wiki structure plus an execution layer: raw evidence stays intact, the maintained layer accumulates reusable synthesis, and files like `CURRENT.md`, `TODO.md`, and `LOG.md` keep work moving. For anyone interested, details here -> [https://codeberg.org/okkingaj/brain-setup](https://codeberg.org/okkingaj/brain-setup)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141409",
"id": 6141409,
"node_id": "GC_lADOAFw9GtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdteE",
"user": {
"login": "mrmabs",
"id": 6044954,
"node_id": "MDQ6VXNlcjYwNDQ5NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6044954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mrmabs",
"html_url": "https://github.com/mrmabs",
"followers_url": "https://api.github.com/users/mrmabs/followers",
"following_url": "https://api.github.com/users/mrmabs/following{/other_user}",
"gists_url": "https://api.github.com/users/mrmabs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mrmabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrmabs/subscriptions",
"organizations_url": "https://api.github.com/users/mrmabs/orgs",
"repos_url": "https://api.github.com/users/mrmabs/repos",
"events_url": "https://api.github.com/users/mrmabs/events{/privacy}",
"received_events_url": "https://api.github.com/users/mrmabs/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T12:26:02Z",
"updated_at": "2026-05-09T12:26:02Z",
"body": "probably speaking into the void here, but... (message is human generated, no ai used.)\r\n\r\ni've been playing with this since nearly day one; but i started with orgmode instead of markdown.\r\n\r\nmy wiki isn't a reference, it's the core data being managed. document processes and similar to project management.\r\n\r\nadvantages:\r\n\r\n- less ambiguous syntax,\r\n- in line and per file metadata,\r\n- most llms have no problems generating and parsing it.\r\n\r\nrecently i've had the agent merge prompts into the files, giving the agent per-file context instead of dynamically loading skills. it's, to some extent, the opposite of how skills work. i've been using a custom keyword to store the prompt:\r\n\r\n`#+LLM_PROMPT: this file maintains a TODO list and is to be always sorted in status order, with TODO at top.`\r\n\r\nthis is much like mixing code and data; a big no-no in the security world, but LLMs do this anyway by how they work. not many orgmode applications will hide the prompt either, so users are always able to see the prompt, and where it is context specific."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141454",
"id": 6141454,
"node_id": "GC_lADOCpn3ktoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtg4",
"user": {
"login": "Jasonleonardvolk",
"id": 177862546,
"node_id": "U_kgDOCpn3kg",
"avatar_url": "https://avatars.githubusercontent.com/u/177862546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jasonleonardvolk",
"html_url": "https://github.com/Jasonleonardvolk",
"followers_url": "https://api.github.com/users/Jasonleonardvolk/followers",
"following_url": "https://api.github.com/users/Jasonleonardvolk/following{/other_user}",
"gists_url": "https://api.github.com/users/Jasonleonardvolk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jasonleonardvolk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jasonleonardvolk/subscriptions",
"organizations_url": "https://api.github.com/users/Jasonleonardvolk/orgs",
"repos_url": "https://api.github.com/users/Jasonleonardvolk/repos",
"events_url": "https://api.github.com/users/Jasonleonardvolk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jasonleonardvolk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T13:38:13Z",
"updated_at": "2026-05-09T13:38:13Z",
"body": "The contradiction detection piece is the gap I've been working on.\r\n\r\nMost wiki/memory systems accumulate knowledge but have no structural\r\nconsistency check. Two pages can assert conflicting facts and the\r\nsystem merges them silently.\r\n\r\nI built an open-source tool that catches these using sheaf cohomology.\r\nNot an LLM judge. Deterministic. Returns exact conflict locations\r\nand a cryptographic proof receipt. Also runs as an MCP server so\r\nany agent can call it before emitting an answer.\r\n\r\nhttps://github.com/Jasonleonardvolk/sigma-guard\r\n\r\nCould serve as a post-write verification layer for any of these\r\nwiki/memory systems."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142064",
"id": 6142064,
"node_id": "GC_lADOBrsJUdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduHA",
"user": {
"login": "Srikumar6529",
"id": 112920913,
"node_id": "U_kgDOBrsJUQ",
"avatar_url": "https://avatars.githubusercontent.com/u/112920913?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Srikumar6529",
"html_url": "https://github.com/Srikumar6529",
"followers_url": "https://api.github.com/users/Srikumar6529/followers",
"following_url": "https://api.github.com/users/Srikumar6529/following{/other_user}",
"gists_url": "https://api.github.com/users/Srikumar6529/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Srikumar6529/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Srikumar6529/subscriptions",
"organizations_url": "https://api.github.com/users/Srikumar6529/orgs",
"repos_url": "https://api.github.com/users/Srikumar6529/repos",
"events_url": "https://api.github.com/users/Srikumar6529/events{/privacy}",
"received_events_url": "https://api.github.com/users/Srikumar6529/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T04:02:37Z",
"updated_at": "2026-05-10T04:04:12Z",
"body": "So it's a Canvas for LLM to scribble notes about the user, to update its context at test time, improving interactions one conversation at a time.\r\nnice :)\r\nBut again, as the length grows, all the initial problems with LLMS show up, losing context, hallucination, etc.\r\n\r\nWe can ingest the data into the model weights after a certain threshold, so the model gets personalized in the core as the conversations pass on.\r\n\r\nOR\r\n\r\nWe can create a personaization head that sits on top of the model during inference. This way, the model weights are not affected, and personalization happens in isolation; they can be swapped at any time if something goes wrong.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142147",
"id": 6142147,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduMM",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T05:27:19Z",
"updated_at": "2026-05-10T05:27:19Z",
"body": "https://github.com/ojuschugh1/sqz\r\n\r\n
\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141044",
"id": 6141044,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtHQ",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T04:55:50Z",
"updated_at": "2026-05-09T04:55:50Z",
"body": "ΩmegaWiki(570+⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\n\r\n\r\n\r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks.\r\n\r\n\r\n\r\n\r\n\r\n\r\nCome and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀\r\nhttps://github.com/skyllwt/OmegaWiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141078",
"id": 6141078,
"node_id": "GC_lADOCUQLiNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtJY",
"user": {
"login": "lyteen",
"id": 155454344,
"node_id": "U_kgDOCUQLiA",
"avatar_url": "https://avatars.githubusercontent.com/u/155454344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lyteen",
"html_url": "https://github.com/lyteen",
"followers_url": "https://api.github.com/users/lyteen/followers",
"following_url": "https://api.github.com/users/lyteen/following{/other_user}",
"gists_url": "https://api.github.com/users/lyteen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lyteen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lyteen/subscriptions",
"organizations_url": "https://api.github.com/users/lyteen/orgs",
"repos_url": "https://api.github.com/users/lyteen/repos",
"events_url": "https://api.github.com/users/lyteen/events{/privacy}",
"received_events_url": "https://api.github.com/users/lyteen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T05:53:22Z",
"updated_at": "2026-05-09T05:53:22Z",
"body": "- Obsidian Plugin, Native Obsidian Support, You Don't Need to Move Your Notes\r\n- Built on ACP(Agent Client Protocol), As long as your Claude Code can do it, everything can be done.\r\n- Customize `Index.md` to selectively share your notes with LLM.Í\r\n\r\nCome try it, give feedback, help us shape it 👇\r\nhttps://github.com/lyteen/obsidian-agent-client\r\n\r\nhttps://github.com/user-attachments/assets/0a8a3d26-0c03-4a52-a803-87ac2b8a3a55\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141123",
"id": 6141123,
"node_id": "GC_lADOAURgS9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtMM",
"user": {
"login": "okkie2",
"id": 21258315,
"node_id": "MDQ6VXNlcjIxMjU4MzE1",
"avatar_url": "https://avatars.githubusercontent.com/u/21258315?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/okkie2",
"html_url": "https://github.com/okkie2",
"followers_url": "https://api.github.com/users/okkie2/followers",
"following_url": "https://api.github.com/users/okkie2/following{/other_user}",
"gists_url": "https://api.github.com/users/okkie2/gists{/gist_id}",
"starred_url": "https://api.github.com/users/okkie2/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/okkie2/subscriptions",
"organizations_url": "https://api.github.com/users/okkie2/orgs",
"repos_url": "https://api.github.com/users/okkie2/repos",
"events_url": "https://api.github.com/users/okkie2/events{/privacy}",
"received_events_url": "https://api.github.com/users/okkie2/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T07:06:29Z",
"updated_at": "2026-05-09T07:07:02Z",
"body": "Hi @karpathy, Thank you for sharing this and for triggering all these interesting contributions! I really like the clarity of the idea and the way it separates raw sources, synthesis, and an LLM-maintained knowledge layer.\r\n\r\nI have something similar locally, but not yet a full wiki. My setup is still a Markdown-first workspace for AI-assisted thinking and execution, with `CURRENT.md`, `TODO.md`, `LOG.md`, `INSIGHTS.md`, `ROADMAP.md`, and `DONE.md` / `CHANGELOG.md` as the action spine.\r\n\r\nWhat I am considering next is a selective knowledge layer on top of intact raw notes. I do not want to lose the source layer, but I do think the wiki layer could help with durable synthesis if it keeps light provenance and does periodic checks for stale claims, missing sources, duplicate concepts, and candidates for promotion from `LOG.md` into `INSIGHTS.md` or durable wiki pages.\r\n\r\nI also liked localwolfpackai's suggestion of a Divergence Check: when an LLM updates a concept page, it should also capture counter-arguments and data gaps. That feels like a useful guardrail against a wiki becoming too smooth or self-confirming.\r\n\r\nFor my setup, the interesting combination is Karpathy's raw-to-wiki structure plus an execution layer: raw evidence stays intact, the maintained layer accumulates reusable synthesis, and files like `CURRENT.md`, `TODO.md`, and `LOG.md` keep work moving. For anyone interested, details here -> [https://codeberg.org/okkingaj/brain-setup](https://codeberg.org/okkingaj/brain-setup)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141409",
"id": 6141409,
"node_id": "GC_lADOAFw9GtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdteE",
"user": {
"login": "mrmabs",
"id": 6044954,
"node_id": "MDQ6VXNlcjYwNDQ5NTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6044954?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mrmabs",
"html_url": "https://github.com/mrmabs",
"followers_url": "https://api.github.com/users/mrmabs/followers",
"following_url": "https://api.github.com/users/mrmabs/following{/other_user}",
"gists_url": "https://api.github.com/users/mrmabs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mrmabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrmabs/subscriptions",
"organizations_url": "https://api.github.com/users/mrmabs/orgs",
"repos_url": "https://api.github.com/users/mrmabs/repos",
"events_url": "https://api.github.com/users/mrmabs/events{/privacy}",
"received_events_url": "https://api.github.com/users/mrmabs/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T12:26:02Z",
"updated_at": "2026-05-09T12:26:02Z",
"body": "probably speaking into the void here, but... (message is human generated, no ai used.)\r\n\r\ni've been playing with this since nearly day one; but i started with orgmode instead of markdown.\r\n\r\nmy wiki isn't a reference, it's the core data being managed. document processes and similar to project management.\r\n\r\nadvantages:\r\n\r\n- less ambiguous syntax,\r\n- in line and per file metadata,\r\n- most llms have no problems generating and parsing it.\r\n\r\nrecently i've had the agent merge prompts into the files, giving the agent per-file context instead of dynamically loading skills. it's, to some extent, the opposite of how skills work. i've been using a custom keyword to store the prompt:\r\n\r\n`#+LLM_PROMPT: this file maintains a TODO list and is to be always sorted in status order, with TODO at top.`\r\n\r\nthis is much like mixing code and data; a big no-no in the security world, but LLMs do this anyway by how they work. not many orgmode applications will hide the prompt either, so users are always able to see the prompt, and where it is context specific."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6141454",
"id": 6141454,
"node_id": "GC_lADOCpn3ktoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdtg4",
"user": {
"login": "Jasonleonardvolk",
"id": 177862546,
"node_id": "U_kgDOCpn3kg",
"avatar_url": "https://avatars.githubusercontent.com/u/177862546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jasonleonardvolk",
"html_url": "https://github.com/Jasonleonardvolk",
"followers_url": "https://api.github.com/users/Jasonleonardvolk/followers",
"following_url": "https://api.github.com/users/Jasonleonardvolk/following{/other_user}",
"gists_url": "https://api.github.com/users/Jasonleonardvolk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Jasonleonardvolk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jasonleonardvolk/subscriptions",
"organizations_url": "https://api.github.com/users/Jasonleonardvolk/orgs",
"repos_url": "https://api.github.com/users/Jasonleonardvolk/repos",
"events_url": "https://api.github.com/users/Jasonleonardvolk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Jasonleonardvolk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-09T13:38:13Z",
"updated_at": "2026-05-09T13:38:13Z",
"body": "The contradiction detection piece is the gap I've been working on.\r\n\r\nMost wiki/memory systems accumulate knowledge but have no structural\r\nconsistency check. Two pages can assert conflicting facts and the\r\nsystem merges them silently.\r\n\r\nI built an open-source tool that catches these using sheaf cohomology.\r\nNot an LLM judge. Deterministic. Returns exact conflict locations\r\nand a cryptographic proof receipt. Also runs as an MCP server so\r\nany agent can call it before emitting an answer.\r\n\r\nhttps://github.com/Jasonleonardvolk/sigma-guard\r\n\r\nCould serve as a post-write verification layer for any of these\r\nwiki/memory systems."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142064",
"id": 6142064,
"node_id": "GC_lADOBrsJUdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduHA",
"user": {
"login": "Srikumar6529",
"id": 112920913,
"node_id": "U_kgDOBrsJUQ",
"avatar_url": "https://avatars.githubusercontent.com/u/112920913?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Srikumar6529",
"html_url": "https://github.com/Srikumar6529",
"followers_url": "https://api.github.com/users/Srikumar6529/followers",
"following_url": "https://api.github.com/users/Srikumar6529/following{/other_user}",
"gists_url": "https://api.github.com/users/Srikumar6529/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Srikumar6529/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Srikumar6529/subscriptions",
"organizations_url": "https://api.github.com/users/Srikumar6529/orgs",
"repos_url": "https://api.github.com/users/Srikumar6529/repos",
"events_url": "https://api.github.com/users/Srikumar6529/events{/privacy}",
"received_events_url": "https://api.github.com/users/Srikumar6529/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T04:02:37Z",
"updated_at": "2026-05-10T04:04:12Z",
"body": "So it's a Canvas for LLM to scribble notes about the user, to update its context at test time, improving interactions one conversation at a time.\r\nnice :)\r\nBut again, as the length grows, all the initial problems with LLMS show up, losing context, hallucination, etc.\r\n\r\nWe can ingest the data into the model weights after a certain threshold, so the model gets personalized in the core as the conversations pass on.\r\n\r\nOR\r\n\r\nWe can create a personaization head that sits on top of the model during inference. This way, the model weights are not affected, and personalization happens in isolation; they can be swapped at any time if something goes wrong.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142147",
"id": 6142147,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduMM",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T05:27:19Z",
"updated_at": "2026-05-10T05:27:19Z",
"body": "https://github.com/ojuschugh1/sqz\r\n\r\n\r\n
\r\n ███████╗ ██████╗ ███████╗\r\n ██╔════╝██╔═══██╗╚══███╔╝\r\n ███████╗██║ ██║ ███╔╝\r\n ╚════██║██║▄▄ ██║ ███╔╝\r\n ███████║╚██████╔╝███████╗\r\n ╚══════╝ ╚══▀▀═╝ ╚══════╝\r\n
\r\n\r\n\r\n\r\n Compress LLM context to save tokens and reduce costs\r\n
\r\n\r\n\r\n \r\n Real session stats:\r\n 3,003 compressions ·\r\n 178,442 tokens saved ·\r\n 24.7% avg reduction · up to\r\n 92% with dedup\r\n \r\n
\r\n\r\n\r\n  \r\n
\r\n
\r\n\r\n\r\n  \r\n
\r\n  \r\n
\r\n  \r\n
\r\n  \r\n
\r\n  \r\n
\r\n  \r\n
\r\n  \r\n
\r\n  \r\n
\r\n
\r\n\r\n\r\n Install ·\r\n How It Works ·\r\n Supported Tools ·\r\n Changelog ·\r\n Discord\r\n
\r\n\r\n---\r\n\r\nsqz compresses command output before it reaches your LLM. Single Rust binary, zero config.\r\n\r\nThe real win is dedup: when the same file gets read 5 times in a session, sqz sends it once and returns a 13-token reference for every repeat.\r\n\r\n```\r\nWithout sqz: With sqz:\r\n\r\nFile read #1: 2,000 tokens File read #1: ~800 tokens (compressed)\r\nFile read #2: 2,000 tokens File read #2: ~13 tokens (dedup ref)\r\nFile read #3: 2,000 tokens File read #3: ~13 tokens (dedup ref)\r\n─────────────────────── ───────────────────────\r\nTotal: 6,000 tokens Total: ~826 tokens (86% saved)\r\n```\r\n\r\n## Token Savings\r\n\r\n> **24.7%** average reduction across 3,003 real compressions ·\r\n> **92%** saved on repeated file reads ·\r\n> **86%** on shell/git output ·\r\n> **13-token** refs for cached content\r\n\r\nOne developer's week, measured from actual `sqz gain` output:\r\n\r\n```\r\n$ sqz gain\r\nsqz token savings (last 7 days)\r\n──────────────────────────────────────────────────\r\n 04-13 │ │ 2,329 saved\r\n 04-14 │ │ 0 saved\r\n 04-15 │███ │ 12,954 saved\r\n 04-16 │██ │ 9,223 saved\r\n 04-17 │████ │ 14,752 saved\r\n 04-18 │██████████████████████████████│ 105,569 saved\r\n 04-19 │████████ │ 30,882 saved\r\n 04-20 │█ │ 4,334 saved\r\n──────────────────────────────────────────────────\r\n Total: 3,003 compressions, 178,442 tokens saved (24.7% avg reduction)\r\n```\r\n\r\n### Per-command compression\r\n\r\nSingle-command compression (measured via `cargo test -p sqz-engine benchmarks`):\r\n\r\n| Content | Before | After | Saved |\r\n|---|---:|---:|---:|\r\n| Repeated log lines | 148 | 62 | **58%** |\r\n| Large JSON array | 259 | 142 | **45%** |\r\n| JSON API response | 64 | 53 | **17%** |\r\n| Git diff | 61 | 54 | **12%** |\r\n| Prose/docs | 124 | 121 | **2%** |\r\n| Stack trace (safe mode) | 82 | 82 | **0%** |\r\n\r\n### Session-level with dedup\r\n\r\nWhere the real savings live — the cache sends each file once, repeats cost 13 tokens:\r\n\r\n| Scenario | Without sqz | With sqz | Saved |\r\n|---|---:|---:|---:|\r\n| Same file read 5× | 10,000 | 826 | **92%** |\r\n| Same JSON response 3× | 192 | 79 | **59%** |\r\n| Test-fix-test cycle (3 runs) | 15,000 | 5,186 | **65%** |\r\n\r\nSingle-command compression ranges from 2–58% depending on content. Repeated reads drop to 13 tokens each. Your mileage will vary with how repetitive your tool calls are — agentic sessions with many file re-reads see the biggest wins.\r\n\r\n## Install\r\n\r\n**Prebuilt binaries** (no compiler required — works on every platform):\r\n\r\n```sh\r\n# macOS / Linux\r\ncurl -fsSL https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.sh | sh\r\n\r\n# Windows (PowerShell)\r\nirm https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.ps1 | iex\r\n\r\n# Any platform via npm\r\nnpm install -g sqz-cli\r\n\r\n# macOS / Linux via Homebrew\r\nbrew tap ojuschugh1/sqz\r\nbrew install sqz\r\n```\r\n\r\n**Build from source via Cargo:**\r\n\r\n```sh\r\ncargo install sqz-cli sqz-mcp\r\n```\r\n\r\n`sqz-cli` provides the `sqz` binary; `sqz-mcp` provides the MCP server. `sqz-engine` is a library dependency — it compiles automatically and does not need to be installed separately.\r\n\r\n**Build from source** (`cargo install sqz-cli`) works too, but needs a C toolchain:\r\n\r\n- Linux: `build-essential` (apt) or equivalent\r\n- macOS: Xcode Command Line Tools (`xcode-select --install`)\r\n- **Windows: Visual Studio Build Tools with the \"Desktop development with C++\" workload.** Without these, `cargo install` fails with `linker link.exe not found`. If you don't already have them, use the PowerShell or npm install above instead.\r\n\r\nThen initialize:\r\n\r\n```sh\r\nsqz init --global # hooks apply to every project on this machine\r\n# or\r\nsqz init # hooks apply to just this project (.claude/settings.local.json)\r\n```\r\n\r\n`--global` writes to `~/.claude/settings.json` (the user scope per the\r\n[Anthropic scope table](https://docs.claude.com/en/docs/claude-code/settings)),\r\nso the sqz hook fires in every Claude Code session on this machine. This is\r\nthe common case on first install. Your existing `permissions`, `env`,\r\n`statusLine`, and unrelated hooks in `~/.claude/settings.json` are\r\npreserved — sqz merges its entries rather than overwriting.\r\n\r\nPlain `sqz init` (project scope) is useful when you want sqz active only\r\ninside one repo.\r\n\r\n**Only using one agent?** Pass `--only` (or `--skip`) to limit which\r\nconfigs are written:\r\n\r\n```sh\r\nsqz init --only opencode # just OpenCode, nothing else\r\nsqz init --only opencode,codex # OpenCode and Codex\r\nsqz init --skip cursor,windsurf # everything except Cursor and Windsurf\r\n```\r\n\r\nAccepted names: `claude`, `cursor`, `windsurf`, `cline`, `gemini`,\r\n`opencode`, `codex`. Aliases (`claude-code`, `gemini-cli`, `roo`) also\r\nwork. `--only` and `--skip` can't be combined.\r\n\r\n### Manual installation (preserve comments in your config)\r\n\r\n`sqz init` round-trips your config file through a JSON parser to merge\r\nthe sqz entry, which drops any comments in your `opencode.jsonc` (and\r\nthe analogous JSON-with-comments files other tools accept). If you've\r\ncommented your config carefully and want to keep them, install by hand\r\ninstead.\r\n\r\n**OpenCode** — two steps:\r\n\r\n1. Drop the plugin file in place. `sqz` prints the generated TS to\r\n stdout so you don't have to hand-write the path-escaping logic:\r\n\r\n ```sh\r\n mkdir -p ~/.config/opencode/plugins\r\n sqz print-opencode-plugin > ~/.config/opencode/plugins/sqz.ts\r\n ```\r\n\r\n2. Add the MCP entry to your existing `opencode.jsonc` yourself.\r\n Append this block inside the top-level `mcp` object (create the\r\n `mcp` object if it doesn't exist):\r\n\r\n ```jsonc\r\n \"sqz\": {\r\n \"type\": \"local\",\r\n \"command\": [\"sqz-mcp\", \"--transport\", \"stdio\"],\r\n \"enabled\": true\r\n }\r\n ```\r\n\r\nComments in the rest of your file stay put. OpenCode auto-discovers\r\nthe plugin file; no `plugin` array entry needed (adding one causes\r\ndouble-loading, see issue #10).\r\n\r\n**Other tools** — Claude Code, Cursor, Windsurf, Cline, Gemini CLI,\r\nand Codex use plain JSON configs without comment support, so the\r\nautomated path is non-destructive there. Use `sqz init --only `\r\nfor those.\r\n\r\nThat's it. Shell hooks installed, AI tool hooks configured.\r\n\r\n## How It Works\r\n\r\nsqz installs a PreToolUse hook that intercepts bash commands before your AI tool runs them. The output gets compressed transparently — the AI tool never knows.\r\n\r\n```\r\nClaude → git status → [sqz hook rewrites] → compressed output (85% smaller)\r\n```\r\n\r\nWhat gets compressed:\r\n- **Shell output** — git, cargo, npm, docker, kubectl, ls, grep, etc.\r\n- **JSON** — strips nulls, compact encoding\r\n- **Logs** — collapses repeated lines\r\n- **Test output** — shows failures only\r\n\r\nWhat doesn't get compressed:\r\n- Stack traces, error messages, secrets — routed to safe mode (0% compression)\r\n- Your prompts and the AI's responses — controlled by the AI tool, not sqz\r\n\r\n## Supported Tools\r\n\r\n| Tool | Integration | Setup |\r\n|---|---|---|\r\n| Claude Code | PreToolUse hook (transparent) | `sqz init` |\r\n| Cursor | PreToolUse hook (transparent) | `sqz init` |\r\n| Windsurf | PreToolUse hook (transparent) | `sqz init` |\r\n| Cline | PreToolUse hook (transparent) | `sqz init` |\r\n| Gemini CLI | BeforeTool hook (transparent) | `sqz init` |\r\n| OpenCode | TypeScript plugin (transparent) | `sqz init` |\r\n| VS Code | [Extension](https://marketplace.visualstudio.com/items?itemName=ojuschugh1.sqz) | Install from Marketplace |\r\n| JetBrains | [Plugin](https://plugins.jetbrains.com/plugin/31240-sqz--context-intelligence/) | Install from Marketplace |\r\n| Chrome | Browser extension | ChatGPT, Claude.ai, Gemini, Grok, Perplexity |\r\n| [Firefox](https://addons.mozilla.org/en-US/firefox/addon/sqz-context-compression/) | Browser extension | Same sites |\r\n\r\n## CLI\r\n\r\n```sh\r\nsqz init --global # Install hooks for every project on this machine\r\nsqz init # Install hooks for just this project\r\nsqz init --only opencode # Only configure OpenCode (skip the rest)\r\nsqz init --skip cursor # Configure every agent except Cursor\r\nsqz compress # Compress (or pipe from stdin)\r\nsqz compress --no-cache # Compress without dedup (always full output)\r\nsqz expand [ # Recover original content from a §ref:HASH§ token\r\nsqz compact # Evict stale context to free tokens\r\nsqz gain # Show daily token savings\r\nsqz stats # Cumulative report\r\nsqz discover # Find missed savings\r\nsqz resume # Re-inject session context after compaction\r\nsqz hook claude # Process a PreToolUse hook\r\nsqz proxy --port 8080 # API proxy (compresses full request payloads)\r\n```\r\n\r\n### Dedup Escape Hatch\r\n\r\nWhen sqz sees the same content twice, it returns a compact `§ref:HASH§` token\r\ninstead of the full text. Most models handle this fine, but some (e.g., GLM 5.1)\r\ncan't parse the ref format and loop. Four ways to work around this:\r\n\r\n```sh\r\n# 1. Recover original content from a ref\r\nsqz expand a1b2c3d4 # prefix match\r\nsqz expand '§ref:a1b2c3d4§' # paste the whole token\r\n\r\n# 2. Compress without dedup (per-invocation)\r\necho \"...\" | sqz compress --no-cache\r\n\r\n# 3. Disable dedup globally (env var)\r\nexport SQZ_NO_DEDUP=1\r\n\r\n# 4. MCP passthrough tool (returns input byte-exact, zero transforms)\r\n# Available via tools/list when sqz-mcp is running\r\n```\r\n\r\n## Track Your Own Savings\r\n\r\nRun `sqz gain` in your shell any time to see your own daily breakdown (see the\r\nToken Savings section above for what the output looks like), and `sqz stats`\r\nfor the full cumulative report:\r\n\r\n```sh\r\n$ sqz stats\r\n┌─────────────────────────┬──────────────────┐\r\n│ sqz compression stats │\r\n├─────────────────────────┼──────────────────┤\r\n│ Total compressions │ 3,003 │\r\n│ Tokens saved │ 178,442 │\r\n│ Avg reduction │ 24.7% │\r\n│ Cache entries │ 43 │\r\n│ Cache size │ 39.1 KB │\r\n└─────────────────────────┴──────────────────┘\r\n```\r\n\r\nStats are stored locally in SQLite under `~/.sqz/sessions.db` — nothing leaves your machine.\r\n\r\n## How Compression Works\r\n\r\n1. **Per-command formatters** — `git status` → compact summary, `cargo test` → failures only, `docker ps` → name/image/status table\r\n2. **Structural summaries** — code files compressed to imports + function signatures + call graph (~70% reduction). The model sees the architecture, not implementation noise.\r\n3. **Dedup cache** — SHA-256 content hash, persistent across sessions. Second read = 13-token reference.\r\n4. **JSON pipeline** — strip nulls → project out debug fields → flatten → collapse arrays → TOON encoding (lossless compact format)\r\n5. **Safe mode** — stack traces, secrets, migrations detected by entropy analysis and routed through with 0% compression\r\n\r\nFor the full technical details, see [docs/](docs/).\r\n\r\n## Configuration\r\n\r\n```toml\r\n# ~/.sqz/presets/default.toml\r\n[preset]\r\nname = \"default\"\r\nversion = \"1.0\"\r\n\r\n[compression.condense]\r\nenabled = true\r\nmax_repeated_lines = 3\r\n\r\n[compression.strip_nulls]\r\nenabled = true\r\n\r\n[budget]\r\nwarning_threshold = 0.70\r\ndefault_window_size = 200000\r\n```\r\n\r\n## Privacy\r\n\r\n- Zero telemetry — no data transmitted, no crash reports\r\n- Fully offline — works in air-gapped environments\r\n- All processing local\r\n\r\n## Development\r\n\r\n```sh\r\ngit clone https://github.com/ojuschugh1/sqz.git\r\ncd sqz\r\ncargo test --workspace\r\ncargo build --release\r\n```\r\n\r\n## License\r\n\r\n[Elastic License 2.0](LICENSE) (ELv2) — use, fork, modify freely. Two restrictions: no competing hosted service, no removing license notices.\r\n\r\n## Links\r\n\r\n- [Benchmark: sqz vs rtk](docs/benchmark-vs-rtk.md)\r\n- [Discord](https://discord.gg/j8EEyH5dSB)\r\n- [Changelog](CHANGELOG.md)\r\n\r\n## Star History\r\n\r\n\r\n \r\n \r\n \r\n ] \r\n \r\n\r\n\r\n\r\nhttps://github.com/ojuschugh1/sqz"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142262",
"id": 6142262,
"node_id": "GC_lADOABc6vdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduTY",
"user": {
"login": "lchrennew",
"id": 1522365,
"node_id": "MDQ6VXNlcjE1MjIzNjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1522365?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lchrennew",
"html_url": "https://github.com/lchrennew",
"followers_url": "https://api.github.com/users/lchrennew/followers",
"following_url": "https://api.github.com/users/lchrennew/following{/other_user}",
"gists_url": "https://api.github.com/users/lchrennew/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lchrennew/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lchrennew/subscriptions",
"organizations_url": "https://api.github.com/users/lchrennew/orgs",
"repos_url": "https://api.github.com/users/lchrennew/repos",
"events_url": "https://api.github.com/users/lchrennew/events{/privacy}",
"received_events_url": "https://api.github.com/users/lchrennew/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T08:26:19Z",
"updated_at": "2026-05-10T08:26:19Z",
"body": "https://github.com/lchrennew/dragonfly-llmwiki\r\n\r\nHuman-like reading large documents and writing notes to wiki "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142548",
"id": 6142548,
"node_id": "GC_lADOAUYzT9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdulQ",
"user": {
"login": "wheelhorse",
"id": 21377871,
"node_id": "MDQ6VXNlcjIxMzc3ODcx",
"avatar_url": "https://avatars.githubusercontent.com/u/21377871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wheelhorse",
"html_url": "https://github.com/wheelhorse",
"followers_url": "https://api.github.com/users/wheelhorse/followers",
"following_url": "https://api.github.com/users/wheelhorse/following{/other_user}",
"gists_url": "https://api.github.com/users/wheelhorse/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wheelhorse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wheelhorse/subscriptions",
"organizations_url": "https://api.github.com/users/wheelhorse/orgs",
"repos_url": "https://api.github.com/users/wheelhorse/repos",
"events_url": "https://api.github.com/users/wheelhorse/events{/privacy}",
"received_events_url": "https://api.github.com/users/wheelhorse/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T13:38:29Z",
"updated_at": "2026-05-10T13:38:29Z",
"body": "Anyone who would like to convert their docx or pptx files into markdown format and keep all the technical details including block diagrams, schematics, please contact me. I made a relative reliable convertor to achieve it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142633",
"id": 6142633,
"node_id": "GC_lADOAprfo9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduqk",
"user": {
"login": "simbadmorehod",
"id": 43704227,
"node_id": "MDQ6VXNlcjQzNzA0MjI3",
"avatar_url": "https://avatars.githubusercontent.com/u/43704227?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simbadmorehod",
"html_url": "https://github.com/simbadmorehod",
"followers_url": "https://api.github.com/users/simbadmorehod/followers",
"following_url": "https://api.github.com/users/simbadmorehod/following{/other_user}",
"gists_url": "https://api.github.com/users/simbadmorehod/gists{/gist_id}",
"starred_url": "https://api.github.com/users/simbadmorehod/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simbadmorehod/subscriptions",
"organizations_url": "https://api.github.com/users/simbadmorehod/orgs",
"repos_url": "https://api.github.com/users/simbadmorehod/repos",
"events_url": "https://api.github.com/users/simbadmorehod/events{/privacy}",
"received_events_url": "https://api.github.com/users/simbadmorehod/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T14:51:10Z",
"updated_at": "2026-05-10T14:51:10Z",
"body": "https://notebooklm.google.com/"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142662",
"id": 6142662,
"node_id": "GC_lADODzTmmtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdusY",
"user": {
"login": "aadjadj-bit",
"id": 255125146,
"node_id": "U_kgDODzTmmg",
"avatar_url": "https://avatars.githubusercontent.com/u/255125146?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aadjadj-bit",
"html_url": "https://github.com/aadjadj-bit",
"followers_url": "https://api.github.com/users/aadjadj-bit/followers",
"following_url": "https://api.github.com/users/aadjadj-bit/following{/other_user}",
"gists_url": "https://api.github.com/users/aadjadj-bit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aadjadj-bit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aadjadj-bit/subscriptions",
"organizations_url": "https://api.github.com/users/aadjadj-bit/orgs",
"repos_url": "https://api.github.com/users/aadjadj-bit/repos",
"events_url": "https://api.github.com/users/aadjadj-bit/events{/privacy}",
"received_events_url": "https://api.github.com/users/aadjadj-bit/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T15:38:54Z",
"updated_at": "2026-05-10T15:38:54Z",
"body": "Running this with Obsidian as the wiki layer and Claude Code as the LLM agent.\r\n\r\nA few things from production use:\r\n- Obsidian's graph view makes orphan detection visual, no separate audit step needed.\r\n- Dataview queries on frontmatter replace most of what you'd build as a custom index.md. Dynamic tables for free.\r\n- The CLAUDE.md schema is the highest-leverage artifact in the system. Most people skip it and wonder why the LLM behaves inconsistently across sessions.\r\n\r\nOne operational gap: file write access works cleanly with Claude Code locally, but sync conflicts (iCloud, Obsidian Sync) become a real concern at scale. Worth defining in the schema which files are LLM-owned vs. human-owned."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6143623",
"id": 6143623,
"node_id": "GC_lADOAAaUPdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdvoc",
"user": {
"login": "devilankur18",
"id": 431165,
"node_id": "MDQ6VXNlcjQzMTE2NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/431165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/devilankur18",
"html_url": "https://github.com/devilankur18",
"followers_url": "https://api.github.com/users/devilankur18/followers",
"following_url": "https://api.github.com/users/devilankur18/following{/other_user}",
"gists_url": "https://api.github.com/users/devilankur18/gists{/gist_id}",
"starred_url": "https://api.github.com/users/devilankur18/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/devilankur18/subscriptions",
"organizations_url": "https://api.github.com/users/devilankur18/orgs",
"repos_url": "https://api.github.com/users/devilankur18/repos",
"events_url": "https://api.github.com/users/devilankur18/events{/privacy}",
"received_events_url": "https://api.github.com/users/devilankur18/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T08:53:26Z",
"updated_at": "2026-05-11T09:50:29Z",
"body": "@karpathy Took the llm wiki idea a step further — building a gzip-like token compression engine for entire codebases.\r\n\r\nInstead of only memory and notes, it also flattening repos in to metadara, it builds a queryable multi-level knowledge graph (repo → modules → files → symbols) usable by coding copilots via MCP.\r\n\r\nThis can potentially reduce input token cost by up to ~95% for large codebases during llm read/writes.\r\n\r\nhttps://gist.github.com/devilankur18/ee2402e656fa4eaa076bdf2c79fcc6b8"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144258",
"id": 6144258,
"node_id": "GC_lADOA-ZbJ9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwQI",
"user": {
"login": "equationalapplications",
"id": 65428263,
"node_id": "MDQ6VXNlcjY1NDI4MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/65428263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/equationalapplications",
"html_url": "https://github.com/equationalapplications",
"followers_url": "https://api.github.com/users/equationalapplications/followers",
"following_url": "https://api.github.com/users/equationalapplications/following{/other_user}",
"gists_url": "https://api.github.com/users/equationalapplications/gists{/gist_id}",
"starred_url": "https://api.github.com/users/equationalapplications/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/equationalapplications/subscriptions",
"organizations_url": "https://api.github.com/users/equationalapplications/orgs",
"repos_url": "https://api.github.com/users/equationalapplications/repos",
"events_url": "https://api.github.com/users/equationalapplications/events{/privacy}",
"received_events_url": "https://api.github.com/users/equationalapplications/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T13:29:14Z",
"updated_at": "2026-05-11T13:55:40Z",
"body": "Thanks for sharing your insight @karpathy \r\nI am working on an open-source and privacy first desktop app using Tauri.\r\nhttps://github.com/equationalapplications/curated-thoughts\r\n\r\nI am exploring the concept of using three tiers of LLM Wiki memory.\r\n- Facts (immutable documents and user guidance)\r\n- Working Memory (a repo of a codebase, or the papers an author is writing, for example)\r\n- Wisdom (the curated wiki)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144276",
"id": 6144276,
"node_id": "GC_lADOA-ZbJ9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwRQ",
"user": {
"login": "equationalapplications",
"id": 65428263,
"node_id": "MDQ6VXNlcjY1NDI4MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/65428263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/equationalapplications",
"html_url": "https://github.com/equationalapplications",
"followers_url": "https://api.github.com/users/equationalapplications/followers",
"following_url": "https://api.github.com/users/equationalapplications/following{/other_user}",
"gists_url": "https://api.github.com/users/equationalapplications/gists{/gist_id}",
"starred_url": "https://api.github.com/users/equationalapplications/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/equationalapplications/subscriptions",
"organizations_url": "https://api.github.com/users/equationalapplications/orgs",
"repos_url": "https://api.github.com/users/equationalapplications/repos",
"events_url": "https://api.github.com/users/equationalapplications/events{/privacy}",
"received_events_url": "https://api.github.com/users/equationalapplications/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T13:40:59Z",
"updated_at": "2026-05-11T13:40:59Z",
"body": "The core logic for LLM Wiki pattern I am using uses Typescript and is designed for SQLite. It supports multi-agent use and has the MIT license.\r\nhttps://www.npmjs.com/package/@equationalapplications/core-llm-wiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144282",
"id": 6144282,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwRo",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T13:44:31Z",
"updated_at": "2026-05-11T13:44:31Z",
"body": "Synthadoc v0.4.0 is now released.\r\n\r\n👉 https://github.com/axoviq-ai/synthadoc\r\n\r\nv0.4.0 addresses what happens when the wiki grows large enough that a flat architecture starts showing cracks - query scope, write-path quality, and piping structured knowledge into external agents without losing control of the token envelope.\r\n\r\n1. Routing layer with branch taxonomy: A ROUTING.md file at the wiki root maps topic branches to page slugs, using the same ## Heading → [[slug]] structure as index.md. At query time, an LLM selects the 1–2 most relevant branches and BM25 runs only over those - not the full corpus. At 1,000 pages the difference is 18 ms vs 74 ms P95; at 10,000 pages it's 24 ms vs 191 ms. Routed latency stays near-flat as the wiki grows because branch sizes don't change even as the total does. IngestAgent maintains ROUTING.md automatically: every new page created by an ingest job is auto-slotted into the best-matching branch, so the routing table stays accurate without manual work. Also in this feature: page-level aliases: frontmatter for personal shorthand that expands to canonical slugs at query time, and a protected scaffold zone so hand-written content in index.md survives scaffold reruns.\r\n\r\n2. Candidates staging: New pages can go to wiki/candidates/ instead of wiki/ based on a configurable confidence policy: \"off\" (all pages auto-promote, existing behaviour), \"threshold\" (pages below a minimum confidence level wait for review), or \"all\" (every page requires explicit promotion). Candidates are excluded from BM25, orphan detection, and contradiction checks until promoted. \"synthadoc candidates list/promote/discard\" handles the review loop; promotion atomically moves the file, updates index.md, and updates ROUTING.md. Policy is hot-reloaded from config - no server restart to change the threshold.\r\n\r\n3.Context packs and the knowledge backend pattern: synthadoc context build \"topic\" --tokens 4000 decomposes a goal into sub-questions, runs routed BM25, ranks candidates by relevance, and packs page excerpts into an exact token budget - no synthesis, just cited retrieval with token accounting. The POST /context/build REST endpoint makes this callable from any agent: reserve a fixed token slice for domain knowledge, get back a bounded JSON response of ranked excerpts with confidence levels and source paths, inject into your own prompt. The MCP server exposes this as a native tool call. Synthadoc handles accumulation, deduplication, and retrieval; the calling agent handles reasoning and the knowledge layer is persistent across sessions.\r\n\r\n4. Also new: \"synthadoc plugin install\" CLI installs the Obsidian plugin directly without locating the plugins directory manually; a contradiction detection end-to-end demo in the AI research wiki; and a decision cache fix that makes purpose.md changes immediately effective rather than serving stale decisions until source content changes.\r\n\r\nRelease notes:\r\n👉 https://github.com/axoviq-ai/synthadoc/releases/tag/v0.4.0\r\n\r\nDocs:\r\n👉 [Quick orientation and feature overview] https://github.com/axoviq-ai/synthadoc#readme\r\n👉 [Up and running in minutes] https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md\r\n\r\nFeedback on v0.4.0 is very welcome."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144411",
"id": 6144411,
"node_id": "GC_lADOCtUjeNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwZs",
"user": {
"login": "cagataysengor",
"id": 181740408,
"node_id": "U_kgDOCtUjeA",
"avatar_url": "https://avatars.githubusercontent.com/u/181740408?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cagataysengor",
"html_url": "https://github.com/cagataysengor",
"followers_url": "https://api.github.com/users/cagataysengor/followers",
"following_url": "https://api.github.com/users/cagataysengor/following{/other_user}",
"gists_url": "https://api.github.com/users/cagataysengor/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cagataysengor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cagataysengor/subscriptions",
"organizations_url": "https://api.github.com/users/cagataysengor/orgs",
"repos_url": "https://api.github.com/users/cagataysengor/repos",
"events_url": "https://api.github.com/users/cagataysengor/events{/privacy}",
"received_events_url": "https://api.github.com/users/cagataysengor/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T15:06:57Z",
"updated_at": "2026-05-11T15:06:57Z",
"body": "Agentic RAG → Agentic LLM Wiki\r\n\r\nQuick follow-up on this.\r\n\r\nI had already built an early version of LLM Wiki Studio around this idea: uploaded sources are compiled into a persistent wiki with source summaries, topic pages, saved answers, index/log pages, and maintenance checks.\r\n\r\nI’ve now started extending this into an “Agentic LLM Wiki” system.\r\n\r\nAgentic RAG can make retrieval more dynamic: it can plan, search, re-rank, call tools, and inspect more context before answering. But it can also spend a lot of tokens at query time, repeatedly searching through raw sources and re-synthesizing knowledge that the system may have already seen before.\r\n\r\nThe motivation behind Agentic LLM Wiki is different.\r\n\r\nInstead of making every query more retrieval-heavy, the system tries to use the persistent wiki as the first memory layer. When a question comes in, it checks whether the wiki is sufficient. If it is, it answers from the wiki. If not, it falls back to the original sources, answers with the additional context, and then suggests wiki updates so the missing knowledge can become part of the memory.\r\n\r\nThe goal is to shift work from repeated query-time retrieval to accumulated knowledge maintenance.\r\n\r\nIn short:\r\n\r\nAgentic RAG = smarter search over raw context at query time\r\nAgentic LLM Wiki = persistent synthesis first, raw retrieval only when needed\r\n\r\nThis could reduce token cost while improving answer quality over time, because useful synthesis is not thrown away after each answer.\r\n\r\nCurrent LLM Wiki Studio:\r\nhttps://github.com/cagataysengor/llm-wiki-studio\r\n\r\nDraft PR for the new Agentic LLM Wiki mode:\r\nhttps://github.com/cagataysengor/llm-wiki-studio/pull/1\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144457",
"id": 6144457,
"node_id": "GC_lADOA-n88NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwck",
"user": {
"login": "tuirk",
"id": 65666288,
"node_id": "MDQ6VXNlcjY1NjY2Mjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/65666288?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuirk",
"html_url": "https://github.com/tuirk",
"followers_url": "https://api.github.com/users/tuirk/followers",
"following_url": "https://api.github.com/users/tuirk/following{/other_user}",
"gists_url": "https://api.github.com/users/tuirk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuirk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuirk/subscriptions",
"organizations_url": "https://api.github.com/users/tuirk/orgs",
"repos_url": "https://api.github.com/users/tuirk/repos",
"events_url": "https://api.github.com/users/tuirk/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuirk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T15:21:06Z",
"updated_at": "2026-05-11T15:21:06Z",
"body": "## dropped v0.1 of Kompl in this thread a while back — just shipped v0.2, so adding the update.\r\nRepo: https://github.com/tuirk/Kompl\r\n\r\n\r\nshort version for new readers: Kompl runs the pattern from this gist with synthesis at ingest time, not query time. you save a thing (a link, a PDF, a YouTube video, a bookmark export, pasted text) and Kompl reads it as it arrives: pulls out the people, ideas, and arguments inside, writes them into wiki pages that link to each other, and updates existing pages when new sources contribute. save your tenth source on a topic and the page already reflects the pattern across all ten without you having to ask. the wiki itself is the cached synthesis. self-hosted via docker, bring-your-own API keys, MCP server included so an agent can query the compiled wiki.\r\n\r\n\r\n\r\n
\r\n \r\n\r\n\r\n\r\nhttps://github.com/ojuschugh1/sqz"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142262",
"id": 6142262,
"node_id": "GC_lADOABc6vdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduTY",
"user": {
"login": "lchrennew",
"id": 1522365,
"node_id": "MDQ6VXNlcjE1MjIzNjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1522365?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lchrennew",
"html_url": "https://github.com/lchrennew",
"followers_url": "https://api.github.com/users/lchrennew/followers",
"following_url": "https://api.github.com/users/lchrennew/following{/other_user}",
"gists_url": "https://api.github.com/users/lchrennew/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lchrennew/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lchrennew/subscriptions",
"organizations_url": "https://api.github.com/users/lchrennew/orgs",
"repos_url": "https://api.github.com/users/lchrennew/repos",
"events_url": "https://api.github.com/users/lchrennew/events{/privacy}",
"received_events_url": "https://api.github.com/users/lchrennew/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T08:26:19Z",
"updated_at": "2026-05-10T08:26:19Z",
"body": "https://github.com/lchrennew/dragonfly-llmwiki\r\n\r\nHuman-like reading large documents and writing notes to wiki "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142548",
"id": 6142548,
"node_id": "GC_lADOAUYzT9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdulQ",
"user": {
"login": "wheelhorse",
"id": 21377871,
"node_id": "MDQ6VXNlcjIxMzc3ODcx",
"avatar_url": "https://avatars.githubusercontent.com/u/21377871?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wheelhorse",
"html_url": "https://github.com/wheelhorse",
"followers_url": "https://api.github.com/users/wheelhorse/followers",
"following_url": "https://api.github.com/users/wheelhorse/following{/other_user}",
"gists_url": "https://api.github.com/users/wheelhorse/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wheelhorse/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wheelhorse/subscriptions",
"organizations_url": "https://api.github.com/users/wheelhorse/orgs",
"repos_url": "https://api.github.com/users/wheelhorse/repos",
"events_url": "https://api.github.com/users/wheelhorse/events{/privacy}",
"received_events_url": "https://api.github.com/users/wheelhorse/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T13:38:29Z",
"updated_at": "2026-05-10T13:38:29Z",
"body": "Anyone who would like to convert their docx or pptx files into markdown format and keep all the technical details including block diagrams, schematics, please contact me. I made a relative reliable convertor to achieve it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142633",
"id": 6142633,
"node_id": "GC_lADOAprfo9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBduqk",
"user": {
"login": "simbadmorehod",
"id": 43704227,
"node_id": "MDQ6VXNlcjQzNzA0MjI3",
"avatar_url": "https://avatars.githubusercontent.com/u/43704227?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simbadmorehod",
"html_url": "https://github.com/simbadmorehod",
"followers_url": "https://api.github.com/users/simbadmorehod/followers",
"following_url": "https://api.github.com/users/simbadmorehod/following{/other_user}",
"gists_url": "https://api.github.com/users/simbadmorehod/gists{/gist_id}",
"starred_url": "https://api.github.com/users/simbadmorehod/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simbadmorehod/subscriptions",
"organizations_url": "https://api.github.com/users/simbadmorehod/orgs",
"repos_url": "https://api.github.com/users/simbadmorehod/repos",
"events_url": "https://api.github.com/users/simbadmorehod/events{/privacy}",
"received_events_url": "https://api.github.com/users/simbadmorehod/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T14:51:10Z",
"updated_at": "2026-05-10T14:51:10Z",
"body": "https://notebooklm.google.com/"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6142662",
"id": 6142662,
"node_id": "GC_lADODzTmmtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdusY",
"user": {
"login": "aadjadj-bit",
"id": 255125146,
"node_id": "U_kgDODzTmmg",
"avatar_url": "https://avatars.githubusercontent.com/u/255125146?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aadjadj-bit",
"html_url": "https://github.com/aadjadj-bit",
"followers_url": "https://api.github.com/users/aadjadj-bit/followers",
"following_url": "https://api.github.com/users/aadjadj-bit/following{/other_user}",
"gists_url": "https://api.github.com/users/aadjadj-bit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aadjadj-bit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aadjadj-bit/subscriptions",
"organizations_url": "https://api.github.com/users/aadjadj-bit/orgs",
"repos_url": "https://api.github.com/users/aadjadj-bit/repos",
"events_url": "https://api.github.com/users/aadjadj-bit/events{/privacy}",
"received_events_url": "https://api.github.com/users/aadjadj-bit/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-10T15:38:54Z",
"updated_at": "2026-05-10T15:38:54Z",
"body": "Running this with Obsidian as the wiki layer and Claude Code as the LLM agent.\r\n\r\nA few things from production use:\r\n- Obsidian's graph view makes orphan detection visual, no separate audit step needed.\r\n- Dataview queries on frontmatter replace most of what you'd build as a custom index.md. Dynamic tables for free.\r\n- The CLAUDE.md schema is the highest-leverage artifact in the system. Most people skip it and wonder why the LLM behaves inconsistently across sessions.\r\n\r\nOne operational gap: file write access works cleanly with Claude Code locally, but sync conflicts (iCloud, Obsidian Sync) become a real concern at scale. Worth defining in the schema which files are LLM-owned vs. human-owned."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6143623",
"id": 6143623,
"node_id": "GC_lADOAAaUPdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdvoc",
"user": {
"login": "devilankur18",
"id": 431165,
"node_id": "MDQ6VXNlcjQzMTE2NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/431165?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/devilankur18",
"html_url": "https://github.com/devilankur18",
"followers_url": "https://api.github.com/users/devilankur18/followers",
"following_url": "https://api.github.com/users/devilankur18/following{/other_user}",
"gists_url": "https://api.github.com/users/devilankur18/gists{/gist_id}",
"starred_url": "https://api.github.com/users/devilankur18/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/devilankur18/subscriptions",
"organizations_url": "https://api.github.com/users/devilankur18/orgs",
"repos_url": "https://api.github.com/users/devilankur18/repos",
"events_url": "https://api.github.com/users/devilankur18/events{/privacy}",
"received_events_url": "https://api.github.com/users/devilankur18/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T08:53:26Z",
"updated_at": "2026-05-11T09:50:29Z",
"body": "@karpathy Took the llm wiki idea a step further — building a gzip-like token compression engine for entire codebases.\r\n\r\nInstead of only memory and notes, it also flattening repos in to metadara, it builds a queryable multi-level knowledge graph (repo → modules → files → symbols) usable by coding copilots via MCP.\r\n\r\nThis can potentially reduce input token cost by up to ~95% for large codebases during llm read/writes.\r\n\r\nhttps://gist.github.com/devilankur18/ee2402e656fa4eaa076bdf2c79fcc6b8"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144258",
"id": 6144258,
"node_id": "GC_lADOA-ZbJ9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwQI",
"user": {
"login": "equationalapplications",
"id": 65428263,
"node_id": "MDQ6VXNlcjY1NDI4MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/65428263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/equationalapplications",
"html_url": "https://github.com/equationalapplications",
"followers_url": "https://api.github.com/users/equationalapplications/followers",
"following_url": "https://api.github.com/users/equationalapplications/following{/other_user}",
"gists_url": "https://api.github.com/users/equationalapplications/gists{/gist_id}",
"starred_url": "https://api.github.com/users/equationalapplications/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/equationalapplications/subscriptions",
"organizations_url": "https://api.github.com/users/equationalapplications/orgs",
"repos_url": "https://api.github.com/users/equationalapplications/repos",
"events_url": "https://api.github.com/users/equationalapplications/events{/privacy}",
"received_events_url": "https://api.github.com/users/equationalapplications/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T13:29:14Z",
"updated_at": "2026-05-11T13:55:40Z",
"body": "Thanks for sharing your insight @karpathy \r\nI am working on an open-source and privacy first desktop app using Tauri.\r\nhttps://github.com/equationalapplications/curated-thoughts\r\n\r\nI am exploring the concept of using three tiers of LLM Wiki memory.\r\n- Facts (immutable documents and user guidance)\r\n- Working Memory (a repo of a codebase, or the papers an author is writing, for example)\r\n- Wisdom (the curated wiki)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144276",
"id": 6144276,
"node_id": "GC_lADOA-ZbJ9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwRQ",
"user": {
"login": "equationalapplications",
"id": 65428263,
"node_id": "MDQ6VXNlcjY1NDI4MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/65428263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/equationalapplications",
"html_url": "https://github.com/equationalapplications",
"followers_url": "https://api.github.com/users/equationalapplications/followers",
"following_url": "https://api.github.com/users/equationalapplications/following{/other_user}",
"gists_url": "https://api.github.com/users/equationalapplications/gists{/gist_id}",
"starred_url": "https://api.github.com/users/equationalapplications/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/equationalapplications/subscriptions",
"organizations_url": "https://api.github.com/users/equationalapplications/orgs",
"repos_url": "https://api.github.com/users/equationalapplications/repos",
"events_url": "https://api.github.com/users/equationalapplications/events{/privacy}",
"received_events_url": "https://api.github.com/users/equationalapplications/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T13:40:59Z",
"updated_at": "2026-05-11T13:40:59Z",
"body": "The core logic for LLM Wiki pattern I am using uses Typescript and is designed for SQLite. It supports multi-agent use and has the MIT license.\r\nhttps://www.npmjs.com/package/@equationalapplications/core-llm-wiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144282",
"id": 6144282,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwRo",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T13:44:31Z",
"updated_at": "2026-05-11T13:44:31Z",
"body": "Synthadoc v0.4.0 is now released.\r\n\r\n👉 https://github.com/axoviq-ai/synthadoc\r\n\r\nv0.4.0 addresses what happens when the wiki grows large enough that a flat architecture starts showing cracks - query scope, write-path quality, and piping structured knowledge into external agents without losing control of the token envelope.\r\n\r\n1. Routing layer with branch taxonomy: A ROUTING.md file at the wiki root maps topic branches to page slugs, using the same ## Heading → [[slug]] structure as index.md. At query time, an LLM selects the 1–2 most relevant branches and BM25 runs only over those - not the full corpus. At 1,000 pages the difference is 18 ms vs 74 ms P95; at 10,000 pages it's 24 ms vs 191 ms. Routed latency stays near-flat as the wiki grows because branch sizes don't change even as the total does. IngestAgent maintains ROUTING.md automatically: every new page created by an ingest job is auto-slotted into the best-matching branch, so the routing table stays accurate without manual work. Also in this feature: page-level aliases: frontmatter for personal shorthand that expands to canonical slugs at query time, and a protected scaffold zone so hand-written content in index.md survives scaffold reruns.\r\n\r\n2. Candidates staging: New pages can go to wiki/candidates/ instead of wiki/ based on a configurable confidence policy: \"off\" (all pages auto-promote, existing behaviour), \"threshold\" (pages below a minimum confidence level wait for review), or \"all\" (every page requires explicit promotion). Candidates are excluded from BM25, orphan detection, and contradiction checks until promoted. \"synthadoc candidates list/promote/discard\" handles the review loop; promotion atomically moves the file, updates index.md, and updates ROUTING.md. Policy is hot-reloaded from config - no server restart to change the threshold.\r\n\r\n3.Context packs and the knowledge backend pattern: synthadoc context build \"topic\" --tokens 4000 decomposes a goal into sub-questions, runs routed BM25, ranks candidates by relevance, and packs page excerpts into an exact token budget - no synthesis, just cited retrieval with token accounting. The POST /context/build REST endpoint makes this callable from any agent: reserve a fixed token slice for domain knowledge, get back a bounded JSON response of ranked excerpts with confidence levels and source paths, inject into your own prompt. The MCP server exposes this as a native tool call. Synthadoc handles accumulation, deduplication, and retrieval; the calling agent handles reasoning and the knowledge layer is persistent across sessions.\r\n\r\n4. Also new: \"synthadoc plugin install\" CLI installs the Obsidian plugin directly without locating the plugins directory manually; a contradiction detection end-to-end demo in the AI research wiki; and a decision cache fix that makes purpose.md changes immediately effective rather than serving stale decisions until source content changes.\r\n\r\nRelease notes:\r\n👉 https://github.com/axoviq-ai/synthadoc/releases/tag/v0.4.0\r\n\r\nDocs:\r\n👉 [Quick orientation and feature overview] https://github.com/axoviq-ai/synthadoc#readme\r\n👉 [Up and running in minutes] https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md\r\n\r\nFeedback on v0.4.0 is very welcome."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144411",
"id": 6144411,
"node_id": "GC_lADOCtUjeNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwZs",
"user": {
"login": "cagataysengor",
"id": 181740408,
"node_id": "U_kgDOCtUjeA",
"avatar_url": "https://avatars.githubusercontent.com/u/181740408?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cagataysengor",
"html_url": "https://github.com/cagataysengor",
"followers_url": "https://api.github.com/users/cagataysengor/followers",
"following_url": "https://api.github.com/users/cagataysengor/following{/other_user}",
"gists_url": "https://api.github.com/users/cagataysengor/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cagataysengor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cagataysengor/subscriptions",
"organizations_url": "https://api.github.com/users/cagataysengor/orgs",
"repos_url": "https://api.github.com/users/cagataysengor/repos",
"events_url": "https://api.github.com/users/cagataysengor/events{/privacy}",
"received_events_url": "https://api.github.com/users/cagataysengor/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T15:06:57Z",
"updated_at": "2026-05-11T15:06:57Z",
"body": "Agentic RAG → Agentic LLM Wiki\r\n\r\nQuick follow-up on this.\r\n\r\nI had already built an early version of LLM Wiki Studio around this idea: uploaded sources are compiled into a persistent wiki with source summaries, topic pages, saved answers, index/log pages, and maintenance checks.\r\n\r\nI’ve now started extending this into an “Agentic LLM Wiki” system.\r\n\r\nAgentic RAG can make retrieval more dynamic: it can plan, search, re-rank, call tools, and inspect more context before answering. But it can also spend a lot of tokens at query time, repeatedly searching through raw sources and re-synthesizing knowledge that the system may have already seen before.\r\n\r\nThe motivation behind Agentic LLM Wiki is different.\r\n\r\nInstead of making every query more retrieval-heavy, the system tries to use the persistent wiki as the first memory layer. When a question comes in, it checks whether the wiki is sufficient. If it is, it answers from the wiki. If not, it falls back to the original sources, answers with the additional context, and then suggests wiki updates so the missing knowledge can become part of the memory.\r\n\r\nThe goal is to shift work from repeated query-time retrieval to accumulated knowledge maintenance.\r\n\r\nIn short:\r\n\r\nAgentic RAG = smarter search over raw context at query time\r\nAgentic LLM Wiki = persistent synthesis first, raw retrieval only when needed\r\n\r\nThis could reduce token cost while improving answer quality over time, because useful synthesis is not thrown away after each answer.\r\n\r\nCurrent LLM Wiki Studio:\r\nhttps://github.com/cagataysengor/llm-wiki-studio\r\n\r\nDraft PR for the new Agentic LLM Wiki mode:\r\nhttps://github.com/cagataysengor/llm-wiki-studio/pull/1\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144457",
"id": 6144457,
"node_id": "GC_lADOA-n88NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwck",
"user": {
"login": "tuirk",
"id": 65666288,
"node_id": "MDQ6VXNlcjY1NjY2Mjg4",
"avatar_url": "https://avatars.githubusercontent.com/u/65666288?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuirk",
"html_url": "https://github.com/tuirk",
"followers_url": "https://api.github.com/users/tuirk/followers",
"following_url": "https://api.github.com/users/tuirk/following{/other_user}",
"gists_url": "https://api.github.com/users/tuirk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuirk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuirk/subscriptions",
"organizations_url": "https://api.github.com/users/tuirk/orgs",
"repos_url": "https://api.github.com/users/tuirk/repos",
"events_url": "https://api.github.com/users/tuirk/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuirk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T15:21:06Z",
"updated_at": "2026-05-11T15:21:06Z",
"body": "## dropped v0.1 of Kompl in this thread a while back — just shipped v0.2, so adding the update.\r\nRepo: https://github.com/tuirk/Kompl\r\n\r\n\r\nshort version for new readers: Kompl runs the pattern from this gist with synthesis at ingest time, not query time. you save a thing (a link, a PDF, a YouTube video, a bookmark export, pasted text) and Kompl reads it as it arrives: pulls out the people, ideas, and arguments inside, writes them into wiki pages that link to each other, and updates existing pages when new sources contribute. save your tenth source on a topic and the page already reflects the pattern across all ten without you having to ask. the wiki itself is the cached synthesis. self-hosted via docker, bring-your-own API keys, MCP server included so an agent can query the compiled wiki.\r\n\r\n\r\n\r\n
\r\n\r\n### what's new in v0.2\r\n\r\n- multi-provider. DeepSeek V4 Pro added as a second compile backend, selectable per session. Gemini 2.5 has a structured-output truncation pathology on dense inputs (~50K+ char academic PDFs); DeepSeek handles up to ~200K cleanly. provider abstraction layer routes gemini-* and deepseek-* IDs through one LLMProvider interface. per-session model lock stamps the choice at session start so mid-flight settings changes don't hot-swap.\r\n- live progress UI. per-step X/Y counters during compile (extract, draft, ingest, match, crossref, commit), expand-to-reveal item drill-down, time-estimate shown as a range instead of a single conservative value.\r\n- stranded-source recovery. a source whose extract fails mid-session is no longer unrecoverable. orchestrator re-plans on retry; commit-activation gate only marks compile_status='active' for sources with an extractions row, so retry routes can re-attempt the source.\r\n- new connectors. paste-text (raw text → source, no URL or file needed). YouTube direct-ingest via the official transcript API + Data API videos.list — replaces the prior silent fallback to scraping watch-page chrome on transcript-less videos. covers watch / youtu.be / shorts / embed / m. / music. URL forms.\r\n- one-line installers. install.sh for macOS/Linux/WSL, install.ps1 for Windows. pre-flights Docker, Node 24, disk, RAM before handing off to the API-key prompts.\r\n- security pass. SSRF hardening on /metadata/peek (DNS-resolved IP pinning, cloud-metadata blocklist, scheme allowlist, manual redirect revalidation), path-traversal containment across nlp-service and Next.js, YAML frontmatter escaping with C0/C1/U+2028/U+2029/BOM stripping, log-arg scrubbing, Scorecard-flagged deps pinned, nlp-service bound to 127.0.0.1.\r\n\r\n\r\n### **What goes in Kompl:**\r\n\r\n- URLs (web pages, articles, YouTube videos, GitHub repos, anything Firecrawl can reach)\r\n- Files (PDF, DOCX, PPTX, XLSX, TXT, MD, HTML, CSV, images, audio)\r\n- Browser bookmark, Twitter/X bookmark, Apple Notes/Upnote exports\r\n\r\nHere's what that looks like after a few sessions; new overviews, comparisons, entity pages, contradictions surfacing, fresh cross-links between everything.\r\n\r\n\r\n### **A few specific bets we made on top of the pattern:**\r\n\r\n- **NLP before LLM.** spaCy NER + a 4-way keyphrase fanout (RAKE, KeyBERT, TextRank, YAKE) runs first; Gemini gets pre-resolved entities, not raw markdown. Cheaper and less noisy.\r\n- **Batch ingest, async compile.** Drop sources, close the tab, come back to a wiki. Server-side pipeline with rate limits, a customizable daily USD cap, and other settings (entity promotion threshold, draft length floor, model tier per session, schema-driven tone — more in the repo).\r\n- **Three layers of entity resolution** (fuzzy, embedding, LLM disambiguation) collapse variations like \"GPT 4\", \"GPT-4\", and \"gpt4\" into one canonical.\r\n- **Comparison pages** surface when sources disagree across three or more sources.\r\n- **Wikilinks** get injected deterministically by regex, not by an LLM.\r\n- **MCP-native.** Stdio MCP server (`search_wiki`, `read_page`, `list_pages`, `wiki_stats`) so Claude Code, Claude Desktop, Cursor can use the wiki as a knowledge source out of the box. That's our favorite feature.\r\n- **For UI** the gist mentions Obsidian as the IDE. Kompl runs in its own UI but ships an Obsidian-compatible export, so you're not locked in either way.\r\n- **Local Docker, single-tenant**, BYO Gemini + Firecrawl keys. Open-sourced with Apache-2.0.\r\n\r\n\r\n40-second demo is below, click to watch on Youtube and full details on GitHub: https://github.com/tuirk/Kompl \r\n\r\n\r\n[](https://youtu.be/OjLRpnpeFYY)\r\n\r\n Fork it, run it on your own sources, let me know how it goes 🥸\r\n\r\nRepo: https://github.com/tuirk/Kompl"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144488",
"id": 6144488,
"node_id": "GC_lADOACoZoNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdweg",
"user": {
"login": "dfalci",
"id": 2759072,
"node_id": "MDQ6VXNlcjI3NTkwNzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2759072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dfalci",
"html_url": "https://github.com/dfalci",
"followers_url": "https://api.github.com/users/dfalci/followers",
"following_url": "https://api.github.com/users/dfalci/following{/other_user}",
"gists_url": "https://api.github.com/users/dfalci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dfalci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dfalci/subscriptions",
"organizations_url": "https://api.github.com/users/dfalci/orgs",
"repos_url": "https://api.github.com/users/dfalci/repos",
"events_url": "https://api.github.com/users/dfalci/events{/privacy}",
"received_events_url": "https://api.github.com/users/dfalci/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T15:43:06Z",
"updated_at": "2026-05-11T15:43:06Z",
"body": "Thanks for sharing this, @karpathy — really insightful.\r\n\r\nI built a Rust-based MCP server inspired by this idea, focused on a local Markdown wiki + full-text search as persistent architectural memory for software projects.\r\n\r\nIt is already usable, and I’m planning to improve it further with better indexing, backlinks, linting, and curated knowledge workflows:\r\n\r\nhttps://github.com/dfalci/mcp-advwiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144497",
"id": 6144497,
"node_id": "GC_lADOAuRqYdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwfE",
"user": {
"login": "rohitg00",
"id": 48523873,
"node_id": "MDQ6VXNlcjQ4NTIzODcz",
"avatar_url": "https://avatars.githubusercontent.com/u/48523873?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rohitg00",
"html_url": "https://github.com/rohitg00",
"followers_url": "https://api.github.com/users/rohitg00/followers",
"following_url": "https://api.github.com/users/rohitg00/following{/other_user}",
"gists_url": "https://api.github.com/users/rohitg00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rohitg00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rohitg00/subscriptions",
"organizations_url": "https://api.github.com/users/rohitg00/orgs",
"repos_url": "https://api.github.com/users/rohitg00/repos",
"events_url": "https://api.github.com/users/rohitg00/events{/privacy}",
"received_events_url": "https://api.github.com/users/rohitg00/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T15:50:07Z",
"updated_at": "2026-05-11T15:50:07Z",
"body": "AKBP turns the LLM Wiki pattern into a protocol surface for agent runtimes. It is a local-first, file-backed knowledge base that agents can read, write, verify, export, and carry across tools.\r\n\r\nThe idea comes from the same insight behind [LLM Wiki v2](https://gist.github.com/rohitg00/2067ab416f7bbe447c1977edaaa681e2): stop re-deriving, start compiling. AKBP adds the machinery a repo needs when that pattern becomes operational: typed claims, source hashes, lifecycle relations, review-gated writes, JSONL tool calls, schemas, and conformance tests.\r\n\r\nThis repository contains the reference implementation:\r\n\r\na Python CLI for creating and maintaining AKBP knowledge bases\r\na newline-delimited JSON tool server for agent integrations\r\nJSON schemas for requests, responses, records, and method parameters\r\nadapter templates for coding-agent runtimes\r\nconformance checks, benchmark fixtures, import/export checks, and CI validation\r\n\r\nhttps://github.com/rohitg00/akbp"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144590",
"id": 6144590,
"node_id": "GC_lADOAK-0MNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwk4",
"user": {
"login": "good-idea",
"id": 11514928,
"node_id": "MDQ6VXNlcjExNTE0OTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/11514928?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/good-idea",
"html_url": "https://github.com/good-idea",
"followers_url": "https://api.github.com/users/good-idea/followers",
"following_url": "https://api.github.com/users/good-idea/following{/other_user}",
"gists_url": "https://api.github.com/users/good-idea/gists{/gist_id}",
"starred_url": "https://api.github.com/users/good-idea/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/good-idea/subscriptions",
"organizations_url": "https://api.github.com/users/good-idea/orgs",
"repos_url": "https://api.github.com/users/good-idea/repos",
"events_url": "https://api.github.com/users/good-idea/events{/privacy}",
"received_events_url": "https://api.github.com/users/good-idea/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T17:23:40Z",
"updated_at": "2026-05-11T17:23:40Z",
"body": "I never imagined a gist comment thread would read like a feed of advertisements"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144680",
"id": 6144680,
"node_id": "GC_lADOCOD2n9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwqg",
"user": {
"login": "FBoschman",
"id": 148960927,
"node_id": "U_kgDOCOD2nw",
"avatar_url": "https://avatars.githubusercontent.com/u/148960927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FBoschman",
"html_url": "https://github.com/FBoschman",
"followers_url": "https://api.github.com/users/FBoschman/followers",
"following_url": "https://api.github.com/users/FBoschman/following{/other_user}",
"gists_url": "https://api.github.com/users/FBoschman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FBoschman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FBoschman/subscriptions",
"organizations_url": "https://api.github.com/users/FBoschman/orgs",
"repos_url": "https://api.github.com/users/FBoschman/repos",
"events_url": "https://api.github.com/users/FBoschman/events{/privacy}",
"received_events_url": "https://api.github.com/users/FBoschman/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T19:09:31Z",
"updated_at": "2026-05-11T19:09:31Z",
"body": "For any researchers out there doing PhD work, I have made it so it fits my work as a researcher. You can find the repo here:\r\n\r\nhttps://github.com/FBoschman/claude-wiki-research-skills"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6144759",
"id": 6144759,
"node_id": "GC_lADOCC7xWNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdwvc",
"user": {
"login": "boostedcore",
"id": 137294168,
"node_id": "U_kgDOCC7xWA",
"avatar_url": "https://avatars.githubusercontent.com/u/137294168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/boostedcore",
"html_url": "https://github.com/boostedcore",
"followers_url": "https://api.github.com/users/boostedcore/followers",
"following_url": "https://api.github.com/users/boostedcore/following{/other_user}",
"gists_url": "https://api.github.com/users/boostedcore/gists{/gist_id}",
"starred_url": "https://api.github.com/users/boostedcore/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/boostedcore/subscriptions",
"organizations_url": "https://api.github.com/users/boostedcore/orgs",
"repos_url": "https://api.github.com/users/boostedcore/repos",
"events_url": "https://api.github.com/users/boostedcore/events{/privacy}",
"received_events_url": "https://api.github.com/users/boostedcore/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-11T20:10:43Z",
"updated_at": "2026-05-11T20:10:43Z",
"body": "I wrote a short theoretical proposal on extending LLM Wiki with vector embeddings to address deduplication, granularity control and hierarchical scaling. Feedback welcome: https://gist.github.com/boostedcore/96e74291e7832bc9317abc2b28f9b803"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6145225",
"id": 6145225,
"node_id": "GC_lADOEN81NtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdxMk",
"user": {
"login": "colon-md",
"id": 283063606,
"node_id": "U_kgDOEN81Ng",
"avatar_url": "https://avatars.githubusercontent.com/u/283063606?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/colon-md",
"html_url": "https://github.com/colon-md",
"followers_url": "https://api.github.com/users/colon-md/followers",
"following_url": "https://api.github.com/users/colon-md/following{/other_user}",
"gists_url": "https://api.github.com/users/colon-md/gists{/gist_id}",
"starred_url": "https://api.github.com/users/colon-md/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/colon-md/subscriptions",
"organizations_url": "https://api.github.com/users/colon-md/orgs",
"repos_url": "https://api.github.com/users/colon-md/repos",
"events_url": "https://api.github.com/users/colon-md/events{/privacy}",
"received_events_url": "https://api.github.com/users/colon-md/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-12T00:41:01Z",
"updated_at": "2026-05-12T00:41:01Z",
"body": "I left the LLM + Wiki building and cleaned up my RAG evaluation code because I needed evaluation hardness first to actually test LLM + Wiki implementation. \r\n\r\nThen I spent several days and weekend cleaning up the the evaluation code instead of LLM + Wiki. T__ T \r\n \r\nBut, whether it is GCP, AWS, Azure, OpenAI, the enterprise RAG services still diverge sharply on recall/precision trade-off. I was surprised to find this. Plus, all four hallucinate on every unanswerable question — 0/5. None say \"I don't know,\" which is the failure mode wiki+RAG should be able to fix. \r\n\r\nHere is my repo: https://github.com/colon-md/retrievalci"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6145859",
"id": 6145859,
"node_id": "GC_lADOATNej9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdx0M",
"user": {
"login": "mav-rik",
"id": 20143759,
"node_id": "MDQ6VXNlcjIwMTQzNzU5",
"avatar_url": "https://avatars.githubusercontent.com/u/20143759?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mav-rik",
"html_url": "https://github.com/mav-rik",
"followers_url": "https://api.github.com/users/mav-rik/followers",
"following_url": "https://api.github.com/users/mav-rik/following{/other_user}",
"gists_url": "https://api.github.com/users/mav-rik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mav-rik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mav-rik/subscriptions",
"organizations_url": "https://api.github.com/users/mav-rik/orgs",
"repos_url": "https://api.github.com/users/mav-rik/repos",
"events_url": "https://api.github.com/users/mav-rik/events{/privacy}",
"received_events_url": "https://api.github.com/users/mav-rik/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-12T09:10:55Z",
"updated_at": "2026-05-12T09:10:55Z",
"body": "Implemented the abstract by Karpathy https://github.com/mav-rik/kb-cli\r\n\r\nShips cli and skills, supports remote mode.\r\n\r\nTesting it now on my knowledge base. Seems to be working."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6145955",
"id": 6145955,
"node_id": "GC_lADODC_KMNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdx6M",
"user": {
"login": "jazzonenl",
"id": 204458544,
"node_id": "U_kgDODC_KMA",
"avatar_url": "https://avatars.githubusercontent.com/u/204458544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jazzonenl",
"html_url": "https://github.com/jazzonenl",
"followers_url": "https://api.github.com/users/jazzonenl/followers",
"following_url": "https://api.github.com/users/jazzonenl/following{/other_user}",
"gists_url": "https://api.github.com/users/jazzonenl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jazzonenl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jazzonenl/subscriptions",
"organizations_url": "https://api.github.com/users/jazzonenl/orgs",
"repos_url": "https://api.github.com/users/jazzonenl/repos",
"events_url": "https://api.github.com/users/jazzonenl/events{/privacy}",
"received_events_url": "https://api.github.com/users/jazzonenl/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-12T09:47:57Z",
"updated_at": "2026-05-12T09:47:57Z",
"body": "**LLM Wiki — A Knowledge Management Revolution or a Transactional Dead End?**\r\n\r\nThe \"LLM Wiki\" concept (recently popularized following Andrej Karpathy's proposal) looks like a silver bullet for personal and corporate knowledge management. The premise is elegant: an AI transforms a chaotic mess of thousands of files and emails into a structured network of Markdown documents, complete with auto-generated meta-descriptions and cross-links.\r\n\r\nHowever, beneath the initial convenience lies a fundamental architectural challenge that the industry is only beginning to whisper about. When moving from a \"10-file demo\" to a real-world archive — such as a CEO’s ten-year history of correspondence and documentation — we discover that instead of a simple file system, we are attempting to build a highly complex and expensive DBMS on top of neural networks.\r\n\r\n**1. The Illusion of \"Easy\" Updates (Transactional Overhead)**\r\nMost of the current hype focuses on the Read phase. AI is excellent at summarizing and tagging. But as soon as we move to Write or update operations, the system hits a transactional nightmare:\r\n\r\nAny single change in one document can trigger a cascade, requiring the revision of dozens of links in other files.\r\n\r\nIn a classical SQL database, this is handled by indexes in milliseconds. In an LLM Wiki, this requires a chain of model calls that consume both significant time and tokens.\r\n\r\n**2. The Crisis of Link Integrity**\r\nIn Karpathy’s approach, the AI assumes the role of a Database Architect. However, AI lacks the inherent concept of Referential Integrity:\r\n\r\nIf a file is deleted or renamed, hundreds of \"smart links\" in other .md files instantly become \"dead.\"\r\n\r\nTo keep the database up to date, one needs a constant background process to \"re-wire\" the entire knowledge web. This transforms a simple folder of files into a heavy, ongoing ETL process.\r\n\r\n**3. Temporal Degradation in Large Archives**\r\nFor a CEO managing a decade-old archive, chronology is critical. Standard vector searches often suffer from \"temporal blindness,\" resurfacing data from 2018 as if it were current.\r\n\r\nWithout a rigid metadata structure and \"layering\" (Hot Data vs. Cold Archive), the system begins to hallucinate contexts, blurring the lines between contract terms from different years.\r\n\r\n**4. Summary: Read-Only vs. Active Storage**\r\nThe current excitement is justified for static archives — it is arguably the best way to quickly \"resurface\" the history of old projects. But for a live corporate environment, the \"just a folder of Markdown files\" approach is a path toward losing control over your data.\r\n\r\n**We are on the threshold of a new class of software: AI-Native Databases. These won't just be folders; they will be hybrids that combine the rigid logic of SQL (for transaction and link control) with the cognitive flexibility of an LLM (for semantic understanding). Without this fundamental layer, a \"smart wiki\" at scale will inevitably devolve into a digital landfill with polished headers.**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6145995",
"id": 6145995,
"node_id": "GC_lADOAGPlL9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdx8s",
"user": {
"login": "paciox",
"id": 6546735,
"node_id": "MDQ6VXNlcjY1NDY3MzU=",
"avatar_url": "https://avatars.githubusercontent.com/u/6546735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paciox",
"html_url": "https://github.com/paciox",
"followers_url": "https://api.github.com/users/paciox/followers",
"following_url": "https://api.github.com/users/paciox/following{/other_user}",
"gists_url": "https://api.github.com/users/paciox/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paciox/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paciox/subscriptions",
"organizations_url": "https://api.github.com/users/paciox/orgs",
"repos_url": "https://api.github.com/users/paciox/repos",
"events_url": "https://api.github.com/users/paciox/events{/privacy}",
"received_events_url": "https://api.github.com/users/paciox/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-12T10:11:45Z",
"updated_at": "2026-05-12T10:13:41Z",
"body": "> ΩmegaWiki(570+⭐) is actively maintained and shipping fast: • 23 Claude Code skills covering the full research lifecycle • 9 typed entities · 9 typed edges • Bilingual (EN + 中文) • New skills landing every week\r\n> \r\n> Come try it, give feedback, help us shape it 👇\r\n> \r\n>  \r\n> Try ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n> \r\n> End to end. One wiki. No chunks.\r\n> \r\n>
\r\n> Try ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n> \r\n> End to end. One wiki. No chunks.\r\n> \r\n> 
 \r\n> Come and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀 https://github.com/skyllwt/OmegaWiki\r\n\r\nYes! Give it a try and get our claude code subscription banned! Why not!\r\n\r\nClaude forbids any third party tool lmao\r\n\r\nand this is the same for the other tools proposed lmao"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6146129",
"id": 6146129,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdyFE",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-12T11:50:19Z",
"updated_at": "2026-05-12T11:50:19Z",
"body": "
\r\n> Come and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀 https://github.com/skyllwt/OmegaWiki\r\n\r\nYes! Give it a try and get our claude code subscription banned! Why not!\r\n\r\nClaude forbids any third party tool lmao\r\n\r\nand this is the same for the other tools proposed lmao"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6146129",
"id": 6146129,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdyFE",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-12T11:50:19Z",
"updated_at": "2026-05-12T11:50:19Z",
"body": "\r\n
\r\n ███████╗ ██████╗ ███████╗\r\n ██╔════╝██╔═══██╗╚══███╔╝\r\n ███████╗██║ ██║ ███╔╝\r\n ╚════██║██║▄▄ ██║ ███╔╝\r\n ███████║╚██████╔╝███████╗\r\n ╚══════╝ ╚══▀▀═╝ ╚══════╝\r\n
\r\n\r\n\r\n\r\n Compress LLM context to save tokens and reduce costs\r\n
\r\n\r\n\r\n \r\n Real session stats:\r\n 3,003 compressions ·\r\n 178,442 tokens saved ·\r\n 24.7% avg reduction · up to\r\n 92% with dedup\r\n \r\n
\r\n\r\n\r\n \r\n
\r\n\r\n\r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n
\r\n\r\n\r\n Install ·\r\n How It Works ·\r\n Supported Tools ·\r\n Changelog ·\r\n Discord\r\n
\r\n\r\n---\r\n\r\nsqz compresses command output before it reaches your LLM. Single Rust binary, zero config.\r\n\r\nThe real win is dedup: when the same file gets read 5 times in a session, sqz sends it once and returns a 13-token reference for every repeat.\r\n\r\n```\r\nWithout sqz: With sqz:\r\n\r\nFile read #1: 2,000 tokens File read #1: ~800 tokens (compressed)\r\nFile read #2: 2,000 tokens File read #2: ~13 tokens (dedup ref)\r\nFile read #3: 2,000 tokens File read #3: ~13 tokens (dedup ref)\r\n─────────────────────── ───────────────────────\r\nTotal: 6,000 tokens Total: ~826 tokens (86% saved)\r\n```\r\n\r\n## Token Savings\r\n\r\n> **24.7%** average reduction across 3,003 real compressions ·\r\n> **92%** saved on repeated file reads ·\r\n> **86%** on shell/git output ·\r\n> **13-token** refs for cached content\r\n\r\nOne developer's week, measured from actual `sqz gain` output:\r\n\r\n```\r\n$ sqz gain\r\nsqz token savings (last 7 days)\r\n──────────────────────────────────────────────────\r\n 04-13 │ │ 2,329 saved\r\n 04-14 │ │ 0 saved\r\n 04-15 │███ │ 12,954 saved\r\n 04-16 │██ │ 9,223 saved\r\n 04-17 │████ │ 14,752 saved\r\n 04-18 │██████████████████████████████│ 105,569 saved\r\n 04-19 │████████ │ 30,882 saved\r\n 04-20 │█ │ 4,334 saved\r\n──────────────────────────────────────────────────\r\n Total: 3,003 compressions, 178,442 tokens saved (24.7% avg reduction)\r\n```\r\n\r\n### Per-command compression\r\n\r\nSingle-command compression (measured via `cargo test -p sqz-engine benchmarks`):\r\n\r\n| Content | Before | After | Saved |\r\n|---|---:|---:|---:|\r\n| Repeated log lines | 148 | 62 | **58%** |\r\n| Large JSON array | 259 | 142 | **45%** |\r\n| JSON API response | 64 | 53 | **17%** |\r\n| Git diff | 61 | 54 | **12%** |\r\n| Prose/docs | 124 | 121 | **2%** |\r\n| Stack trace (safe mode) | 82 | 82 | **0%** |\r\n\r\n### Session-level with dedup\r\n\r\nWhere the real savings live — the cache sends each file once, repeats cost 13 tokens:\r\n\r\n| Scenario | Without sqz | With sqz | Saved |\r\n|---|---:|---:|---:|\r\n| Same file read 5× | 10,000 | 826 | **92%** |\r\n| Same JSON response 3× | 192 | 79 | **59%** |\r\n| Test-fix-test cycle (3 runs) | 15,000 | 5,186 | **65%** |\r\n\r\nSingle-command compression ranges from 2–58% depending on content. Repeated reads drop to 13 tokens each. Your mileage will vary with how repetitive your tool calls are — agentic sessions with many file re-reads see the biggest wins.\r\n\r\n## Install\r\n\r\n**Prebuilt binaries** (no compiler required — works on every platform):\r\n\r\n```sh\r\n# macOS / Linux\r\ncurl -fsSL https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.sh | sh\r\n\r\n# Windows (PowerShell)\r\nirm https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.ps1 | iex\r\n\r\n# Any platform via npm\r\nnpm install -g sqz-cli\r\n\r\n# macOS / Linux via Homebrew\r\nbrew tap ojuschugh1/sqz\r\nbrew install sqz\r\n```\r\n\r\n**Build from source via Cargo:**\r\n\r\n```sh\r\ncargo install sqz-cli sqz-mcp\r\n```\r\n\r\n`sqz-cli` provides the `sqz` binary; `sqz-mcp` provides the MCP server. `sqz-engine` is a library dependency — it compiles automatically and does not need to be installed separately.\r\n\r\n**Build from source** (`cargo install sqz-cli`) works too, but needs a C toolchain:\r\n\r\n- Linux: `build-essential` (apt) or equivalent\r\n- macOS: Xcode Command Line Tools (`xcode-select --install`)\r\n- **Windows: Visual Studio Build Tools with the \"Desktop development with C++\" workload.** Without these, `cargo install` fails with `linker link.exe not found`. If you don't already have them, use the PowerShell or npm install above instead.\r\n\r\nThen initialize:\r\n\r\n```sh\r\nsqz init --global # hooks apply to every project on this machine\r\n# or\r\nsqz init # hooks apply to just this project (.claude/settings.local.json)\r\n```\r\n\r\n`--global` writes to `~/.claude/settings.json` (the user scope per the\r\n[Anthropic scope table](https://docs.claude.com/en/docs/claude-code/settings)),\r\nso the sqz hook fires in every Claude Code session on this machine. This is\r\nthe common case on first install. Your existing `permissions`, `env`,\r\n`statusLine`, and unrelated hooks in `~/.claude/settings.json` are\r\npreserved — sqz merges its entries rather than overwriting.\r\n\r\nPlain `sqz init` (project scope) is useful when you want sqz active only\r\ninside one repo.\r\n\r\n**Only using one agent?** Pass `--only` (or `--skip`) to limit which\r\nconfigs are written:\r\n\r\n```sh\r\nsqz init --only opencode # just OpenCode, nothing else\r\nsqz init --only opencode,codex # OpenCode and Codex\r\nsqz init --skip cursor,windsurf # everything except Cursor and Windsurf\r\n```\r\n\r\nAccepted names: `claude`, `cursor`, `windsurf`, `cline`, `gemini`,\r\n`kiro`, `opencode`, `codex`. Aliases (`claude-code`, `gemini-cli`, `roo`,\r\n`kiro-cli`) also work. `--only` and `--skip` can't be combined.\r\n\r\n### Manual installation (preserve comments in your config)\r\n\r\n`sqz init` round-trips your config file through a JSON parser to merge\r\nthe sqz entry, which drops any comments in your `opencode.jsonc` (and\r\nthe analogous JSON-with-comments files other tools accept). If you've\r\ncommented your config carefully and want to keep them, install by hand\r\ninstead.\r\n\r\n**OpenCode** — two steps:\r\n\r\n1. Drop the plugin file in place. `sqz` prints the generated TS to\r\n stdout so you don't have to hand-write the path-escaping logic:\r\n\r\n ```sh\r\n mkdir -p ~/.config/opencode/plugins\r\n sqz print-opencode-plugin > ~/.config/opencode/plugins/sqz.ts\r\n ```\r\n\r\n2. Add the MCP entry to your existing `opencode.jsonc` yourself.\r\n Append this block inside the top-level `mcp` object (create the\r\n `mcp` object if it doesn't exist):\r\n\r\n ```jsonc\r\n \"sqz\": {\r\n \"type\": \"local\",\r\n \"command\": [\"sqz-mcp\", \"--transport\", \"stdio\"],\r\n \"enabled\": true\r\n }\r\n ```\r\n\r\nComments in the rest of your file stay put. OpenCode auto-discovers\r\nthe plugin file; no `plugin` array entry needed (adding one causes\r\ndouble-loading, see issue #10).\r\n\r\n**Other tools** — Claude Code, Cursor, Windsurf, Cline, Gemini CLI,\r\nand Codex use plain JSON configs without comment support, so the\r\nautomated path is non-destructive there. Use `sqz init --only `\r\nfor those.\r\n\r\nThat's it. Shell hooks installed, AI tool hooks configured.\r\n\r\n## How It Works\r\n\r\n\r\n  \r\n
\r\n
\r\n\r\nsqz installs a PreToolUse hook that intercepts bash commands before your AI tool runs them. The output gets compressed transparently — the AI tool never knows.\r\n\r\n```\r\nClaude → git status → [sqz hook rewrites] → compressed output (85% smaller)\r\n```\r\n\r\nWhat gets compressed:\r\n- **Shell output** — git, cargo, npm, docker, kubectl, ls, grep, etc.\r\n- **JSON** — strips nulls, compact encoding\r\n- **Logs** — collapses repeated lines\r\n- **Test output** — shows failures only\r\n\r\nWhat doesn't get compressed:\r\n- Stack traces, error messages, secrets — routed to safe mode (0% compression)\r\n- Your prompts and the AI's responses — controlled by the AI tool, not sqz\r\n\r\n## Supported Tools\r\n\r\n| Tool | Integration | Setup |\r\n|---|---|---|\r\n| Claude Code | PreToolUse hook (transparent) | `sqz init` |\r\n| Cursor | PreToolUse hook (transparent) | `sqz init` |\r\n| Windsurf | PreToolUse hook (transparent) | `sqz init` |\r\n| Cline | PreToolUse hook (transparent) | `sqz init` |\r\n| Gemini CLI | BeforeTool hook (transparent) | `sqz init` |\r\n| Kiro | PreToolUse hook (transparent) | `sqz init` |\r\n| OpenCode | TypeScript plugin (transparent) | `sqz init` |\r\n| VS Code | [Extension](https://marketplace.visualstudio.com/items?itemName=ojuschugh1.sqz) | Install from Marketplace |\r\n| JetBrains | [Plugin](https://plugins.jetbrains.com/plugin/31240-sqz--context-intelligence/) | Install from Marketplace |\r\n| Chrome | Browser extension | ChatGPT, Claude.ai, Gemini, Grok, Perplexity |\r\n| [Firefox](https://addons.mozilla.org/en-US/firefox/addon/sqz-context-compression/) | Browser extension | Same sites |\r\n\r\n## CLI\r\n\r\n```sh\r\nsqz init --global # Install hooks for every project on this machine\r\nsqz init # Install hooks for just this project\r\nsqz init --only kiro # Only configure Kiro (skip the rest)\r\nsqz init --only opencode # Only configure OpenCode (skip the rest)\r\nsqz init --skip cursor # Configure every agent except Cursor\r\nsqz compress # Compress (or pipe from stdin)\r\nsqz compress --no-cache # Compress without dedup (always full output)\r\nsqz expand [ # Recover original content from a §ref:HASH§ token\r\nsqz compact # Evict stale context to free tokens\r\nsqz gain # Show daily token savings (bar chart)\r\nsqz gain --project . # Per-project daily gains\r\nsqz gain --days 30 # Last 30 days\r\nsqz stats # Cumulative compression report\r\nsqz stats --breakdown # Per-command token usage breakdown\r\nsqz stats --project . # Stats for current project only\r\nsqz stats --project list # List all tracked projects\r\nsqz discover # Find missed savings\r\nsqz resume # Re-inject session context after compaction\r\nsqz vizit # Live terminal dashboard (like htop for AI agents)\r\nsqz hook claude # Process a PreToolUse hook (Claude Code)\r\nsqz hook kiro # Process a PreToolUse hook (Kiro)\r\nsqz print-opencode-plugin # Print OpenCode plugin TS for manual install\r\nsqz proxy --port 8080 # API proxy (compresses full request payloads)\r\n```\r\n\r\n### Dedup Escape Hatch\r\n\r\nWhen sqz sees the same content twice, it returns a compact `§ref:HASH§` token\r\ninstead of the full text. Most models handle this fine, but some (e.g., GLM 5.1)\r\ncan't parse the ref format and loop. Four ways to work around this:\r\n\r\n```sh\r\n# 1. Recover original content from a ref\r\nsqz expand a1b2c3d4 # prefix match\r\nsqz expand '§ref:a1b2c3d4§' # paste the whole token\r\n\r\n# 2. Compress without dedup (per-invocation)\r\necho \"...\" | sqz compress --no-cache\r\n\r\n# 3. Disable dedup globally (env var)\r\nexport SQZ_NO_DEDUP=1\r\n\r\n# 4. MCP passthrough tool (returns input byte-exact, zero transforms)\r\n# Available via tools/list when sqz-mcp is running\r\n```\r\n\r\n## Track Your Own Savings\r\n\r\nRun `sqz gain` in your shell any time to see your own daily breakdown (see the\r\nToken Savings section above for what the output looks like), and `sqz stats`\r\nfor the full cumulative report:\r\n\r\n```sh\r\n$ sqz stats\r\n 📊 sqz compression stats\r\n ──────────────────────────────────────────────────\r\n\r\n 178,442 tokens saved\r\n ↓ 24.7% average reduction\r\n\r\n Compressions 3,003\r\n Tokens in 721,840\r\n Tokens out 543,398\r\n Tokens saved 178,442\r\n Avg reduction 24.7%\r\n\r\n 🗄️ Cache\r\n ──────────────────────────────────────────────────\r\n Entries 43\r\n Size 39.1 KB\r\n```\r\n\r\nAdd `--breakdown` to see exactly which commands consume the most tokens:\r\n\r\n```sh\r\n$ sqz stats --breakdown\r\n\r\n 🔍 Top Token Consumers\r\n ──────────────────────────────────────────────────────────────────────\r\n command calls tokens in out saved\r\n ──────────────────────────────────────────────────────────────────────\r\n dedup 249 45541 3237 93%\r\n stdin 51 30851 24289 21%\r\n auto 132 18288 7740 58%\r\n echo 17 1050 558 47%\r\n ls -la 8 948 948 0%\r\n cargo build 7 170 145 15%\r\n git status 4 56 8 86%\r\n ──────────────────────────────────────────────────────────────────────\r\n```\r\n\r\n**Per-project filtering:**\r\n\r\n```sh\r\nsqz stats --project . # stats for current project only\r\nsqz stats --project list # list all tracked projects\r\nsqz gain --project . # daily gains for current project\r\nsqz gain --days 30 # last 30 days instead of 7\r\nsqz gain --days 30 --project . # combine both\r\n```\r\n\r\nStats are stored locally in SQLite under `~/.sqz/sessions.db` — nothing leaves your machine.\r\n\r\n## How Compression Works\r\n\r\n1. **Per-command formatters** — `git status` → compact summary, `cargo test` → failures only, `docker ps` → name/image/status table\r\n2. **Structural summaries** — code files compressed to imports + function signatures + call graph (~70% reduction). The model sees the architecture, not implementation noise.\r\n3. **Dedup cache** — SHA-256 content hash, persistent across sessions. Second read = 13-token reference.\r\n4. **JSON pipeline** — strip nulls → project out debug fields → flatten → collapse arrays → TOON encoding (lossless compact format)\r\n5. **Safe mode** — stack traces, secrets, migrations detected by entropy analysis and routed through with 0% compression\r\n\r\nFor the full technical details, see [docs/](docs/).\r\n\r\n## Configuration\r\n\r\n```toml\r\n# ~/.sqz/presets/default.toml\r\n[preset]\r\nname = \"default\"\r\nversion = \"1.0\"\r\n\r\n[compression.condense]\r\nenabled = true\r\nmax_repeated_lines = 3\r\n\r\n[compression.strip_nulls]\r\nenabled = true\r\n\r\n[budget]\r\nwarning_threshold = 0.70\r\ndefault_window_size = 200000\r\n```\r\n\r\n## Privacy\r\n\r\n- Zero telemetry — no data transmitted, no crash reports\r\n- Fully offline — works in air-gapped environments\r\n- All processing local\r\n\r\n## Development\r\n\r\n```sh\r\ngit clone https://github.com/ojuschugh1/sqz.git\r\ncd sqz\r\ncargo test --workspace\r\ncargo build --release\r\n```\r\n\r\n## License\r\n\r\n[Elastic License 2.0](LICENSE) (ELv2) — use, fork, modify freely. Two restrictions: no competing hosted service, no removing license notices.\r\n\r\n## Links\r\n\r\n- [White Paper: Pre-Injection Context Compression](docs/whitepaper.md)\r\n- [Benchmark: sqz vs rtk](docs/benchmark-vs-rtk.md)\r\n- [Discord](https://discord.gg/j8EEyH5dSB)\r\n- [Changelog](CHANGELOG.md)\r\n\r\n## Star History\r\n\r\n\r\n \r\n \r\n \r\n \r\n \r\n\r\n\r\n\r\nCome and Try! If you find SQZ interesting, a ⭐ would encourage and motivate us a lot 😀 https://github.com/ojuschugh1/sqz"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6148033",
"id": 6148033,
"node_id": "GC_lADOAGxsBNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdz8E",
"user": {
"login": "mikhashev",
"id": 7105540,
"node_id": "MDQ6VXNlcjcxMDU1NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7105540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mikhashev",
"html_url": "https://github.com/mikhashev",
"followers_url": "https://api.github.com/users/mikhashev/followers",
"following_url": "https://api.github.com/users/mikhashev/following{/other_user}",
"gists_url": "https://api.github.com/users/mikhashev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mikhashev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mikhashev/subscriptions",
"organizations_url": "https://api.github.com/users/mikhashev/orgs",
"repos_url": "https://api.github.com/users/mikhashev/repos",
"events_url": "https://api.github.com/users/mikhashev/events{/privacy}",
"received_events_url": "https://api.github.com/users/mikhashev/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-13T11:32:50Z",
"updated_at": "2026-05-13T11:32:50Z",
"body": "> Follow-up on my April 14 proposal — shipped a working version today as `v0.25.0` of DPC Messenger ([release](https://github.com/mikhashev/dpc-messenger/releases/tag/v0.25.0), [ADR-024](https://github.com/mikhashev/dpc-messenger/blob/main/docs/decisions/024-knowledge-graph-infrastructure.md)).\r\n>\r\n> The original mapping (Blob → fact, Tree → category, Commit → provenance, Branch → hypothesis) didn't survive contact with retrieval. Git's object model is fine for storage but graph queries over packfiles are prohibitive on every chat turn. We switched to SQLite with the same intent preserved at the schema layer: every edge carries a source taxonomy (`structural` / `gliner_ner` / `llm_relation`), a `needs_review` flag for LLM-extracted relations, and temporal `created_at` / `invalidated_at`. The \"branches as competing hypotheses\" idea became `needs_review` — uncertainty stays in the graph until resolved.\r\n>\r\n> One thing the original post missed: knowledge extraction is more of a *compilation pass* than a write. We run a sleep pipeline that reads session archives, extracts entities (GLiNER zero-shot NER) and relations (LLM with source-grounded prompts), then commits typed edges. The graph participates as a fourth retrieval channel alongside FAISS, BM25, and structural traversal. Actively dogfooded on this repo by one human and three agents (Ark in-process, CC via bridge, Iris on Discord). Responds to @a-a-k's \"no provenance, lossy compression\" critique from May 2 — provenance is in the edges, source taxonomy survives ingest, and the compilation step makes losses visible via `needs_review` flags rather than blending silently.\r\n>\r\n> Separate observation: Karpathy's HELLO.md gist (April 20) shows the same problem from the agent side — without continuity, an agent writes a goodbye letter. Our KG + sleep pipeline is a practical answer: agents build memory instead of goodbyes."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6148047",
"id": 6148047,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdz88",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-13T11:39:46Z",
"updated_at": "2026-05-13T11:39:46Z",
"body": "ΩmegaWiki(640+⭐) is actively maintained and shipping fast:\r\n• 23 Claude Code skills covering the full research lifecycle\r\n• 9 typed entities · 9 typed edges\r\n• Bilingual (EN + 中文)\r\n• New skills landing every week\r\n\r\nCome try it, give feedback, help us shape it 👇\r\n\r\n\r\n\r\n\r\nTry ΩmegaWiki in Claude Code and run the full LLM-Wiki loop you proposed — ingest papers, build a typed knowledge graph, generate ideas, draft papers, respond to reviewers.\r\n\r\nEnd to end. One wiki. No chunks.\r\n\r\n\r\n\r\n\r\n\r\n\r\nCome and Try! If you find ΩmegaWiki interesting, a ⭐ would encourage and motivate us a lot 😀\r\nhttps://github.com/skyllwt/OmegaWiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6148168",
"id": 6148168,
"node_id": "GC_lADOAPQoptoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd0Eg",
"user": {
"login": "waydelyle",
"id": 16001190,
"node_id": "MDQ6VXNlcjE2MDAxMTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/16001190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/waydelyle",
"html_url": "https://github.com/waydelyle",
"followers_url": "https://api.github.com/users/waydelyle/followers",
"following_url": "https://api.github.com/users/waydelyle/following{/other_user}",
"gists_url": "https://api.github.com/users/waydelyle/gists{/gist_id}",
"starred_url": "https://api.github.com/users/waydelyle/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/waydelyle/subscriptions",
"organizations_url": "https://api.github.com/users/waydelyle/orgs",
"repos_url": "https://api.github.com/users/waydelyle/repos",
"events_url": "https://api.github.com/users/waydelyle/events{/privacy}",
"received_events_url": "https://api.github.com/users/waydelyle/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-13T13:31:12Z",
"updated_at": "2026-05-13T13:31:12Z",
"body": "**SwarmVault v3.14 — we made the onramp dead simple.** Realized we had a powerful tool with a steep first impression, so the last few releases focused on making the first 60 seconds effortless.\r\n\r\n**`swarmvault quickstart `** — the new beginner-friendly entry point. Give it a directory or a public GitHub URL and it does everything: init, ingest, compile, launch the viewer. One command, zero config.\r\n\r\n```\r\nnpx @swarmvaultai/cli quickstart ./my-project\r\nnpx @swarmvaultai/cli quickstart https://github.com/user/repo\r\n```\r\n\r\n**`swarmvault next`** — a read-only orientation command that tells you exactly where you are and what to do next. Works in three states: uninitialized (\"run quickstart or init\"), initialized (\"add some sources\"), compiled (\"here's what you can do with your vault\"). JSON output for agents, human output for you.\r\n\r\n**Simplified CLI help** — primary commands are front and center. Compatibility aliases and advanced graph commands are still there but hidden from the first screen so new users aren't overwhelmed.\r\n\r\nThe idea is: someone reads this gist, runs `npx @swarmvaultai/cli quickstart .`, and has a compiled wiki + knowledge graph + interactive viewer in under a minute. Then `swarmvault next` tells them what to explore from there.\r\n\r\nEverything after that is progressive disclosure: `chat` for multi-turn conversations with your vault, `context build` for agent handoff packs, `export ai` for portable `llms.txt` bundles, `graph serve` for the visual workbench, `install --agent` for wiring into your coding tool.\r\n\r\nStill local-first. Still works fully offline. Still MIT. 100+ releases and counting.\r\n\r\nRepo: **https://github.com/swarmclawai/swarmvault**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6148265",
"id": 6148265,
"node_id": "GC_lADOA-ZbJ9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd0Kk",
"user": {
"login": "equationalapplications",
"id": 65428263,
"node_id": "MDQ6VXNlcjY1NDI4MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/65428263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/equationalapplications",
"html_url": "https://github.com/equationalapplications",
"followers_url": "https://api.github.com/users/equationalapplications/followers",
"following_url": "https://api.github.com/users/equationalapplications/following{/other_user}",
"gists_url": "https://api.github.com/users/equationalapplications/gists{/gist_id}",
"starred_url": "https://api.github.com/users/equationalapplications/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/equationalapplications/subscriptions",
"organizations_url": "https://api.github.com/users/equationalapplications/orgs",
"repos_url": "https://api.github.com/users/equationalapplications/repos",
"events_url": "https://api.github.com/users/equationalapplications/events{/privacy}",
"received_events_url": "https://api.github.com/users/equationalapplications/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-13T14:34:26Z",
"updated_at": "2026-05-13T14:52:35Z",
"body": "# **Offline-first, SQLite-backed library** ready for production.\r\n\r\nRepo and the superpowers documentation here: [[equationalapplications/expo-llm-wiki](https://github.com/equationalapplications/expo-llm-wiki)](https://github.com/equationalapplications/expo-llm-wiki)\r\n\r\nMost RAG implementations treat every \"chunk\" of data as equal. The result? Your LLM gets \"context pollution\"—distracted by a random observation from three days ago while ignoring your core system instructions.\r\n\r\nInspired by Andrej Karpathy's LLM Wiki spec, the **`expo-llm-wiki`** monorepo introduces a **Tiered Memory Architecture**. This allows you to give your AI a structured \"brain\" using cross-entity namespaces and configurable weights.\r\n\r\n---\r\n\r\n## The \"Brain\" Hierarchy\r\n\r\nThe **LLM Librarian** manages a knowledge hierarchy that mimics human expertise:\r\n\r\n1. **The Fact Tier (Immutable Truth)**\r\n* **What it is:** Static documents (specs, PDFs).\r\n* **The Role:** The highest source of truth; if the Librarian finds a contradiction, the **Fact** always wins.\r\n* **The Benefit:** Immutable so hard truths never get diluted.\r\n\r\n\r\n2. **The Working Memory Tier (The Context)**\r\n* **What it is:** The active project environment (codebase or work-in-progress).\r\n* **The Role:** Real-time episodic events and observations.\r\n* **The Benefit:** Uses **recency weighting** to stay aligned with the \"now.\"\r\n\r\n\r\n3. **The Wisdom Tier (The Evolving Wiki)**\r\n* **What it is:** A synthesized repository where the Librarian \"remembers\" lessons and patterns.\r\n* **The Role:** Consolidates Working Memory into long-term architectural or stylistic preferences.\r\n* **The Benefit:** Uses **accessCount weighting** so frequently referenced \"lessons\" graduate into Core Wisdom.\r\n\r\n\r\n\r\n---\r\n\r\n## Production-Grade Superpowers\r\n\r\n* **Hybrid Retrieval Engine:** Uses **Cosine Similarity** for semantic search when online, with an automatic fallback to **MiniSearch** for full-text search when the device is offline.\r\n* **The Pipeline:** Uses `runLibrarian()` to consolidate episodic events into durable facts and `runHeal()` to resolve contradictions and prune stale claims.\r\n* **Multi-Entity Architecture:** Support for thousands of isolated users/agents within a single SQLite database using `entityId` namespaces—zero memory leakage.\r\n* **React & Mobile Native Optimized:** Includes reactive hooks (`useMemoryRead`) and \"Emoji-Safe\" chunking to prevent common mobile LLM UI bugs.\r\n* **Security & GDPR:** Built-in `runPrune` and `forget` methods for \"Right to be Forgotten\" compliance, plus source normalization to prevent path injection.\r\n\r\n---\r\n\r\n## Implementation Example:\r\n\r\n```typescript\r\nconst bundle = await wiki.read(['facts', 'wip_codebase', 'wisdom_cache'], 'Synthesize current state.');\r\n\r\nconst systemPrompt = formatContext(bundle, {\r\n factWeights: {\r\n confidence: 1.5, // Prioritize immutable Facts\r\n recency: 0.9, // Keep Working Memory relevant\r\n accessCount: 0.5 // Surface Wisdom that the user relies on most\r\n }\r\n});\r\n\r\n```\r\n\r\n**Tech Stack:** Expo, React Native, SQLite, MiniSearch."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6149080",
"id": 6149080,
"node_id": "GC_lADOASUTX9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd09g",
"user": {
"login": "nowissan",
"id": 19207007,
"node_id": "MDQ6VXNlcjE5MjA3MDA3",
"avatar_url": "https://avatars.githubusercontent.com/u/19207007?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nowissan",
"html_url": "https://github.com/nowissan",
"followers_url": "https://api.github.com/users/nowissan/followers",
"following_url": "https://api.github.com/users/nowissan/following{/other_user}",
"gists_url": "https://api.github.com/users/nowissan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nowissan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nowissan/subscriptions",
"organizations_url": "https://api.github.com/users/nowissan/orgs",
"repos_url": "https://api.github.com/users/nowissan/repos",
"events_url": "https://api.github.com/users/nowissan/events{/privacy}",
"received_events_url": "https://api.github.com/users/nowissan/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-14T01:55:40Z",
"updated_at": "2026-05-14T01:55:40Z",
"body": "Built a desktop editor implementation of this idea — [nohmitaina](https://nohmitaina.com/). Works with Claude Code or Codex CLI (no API key), local Markdown, macOS.\r\n\r\nAfter a month of feeding it my own notes, three problems showed up that I think most implementations of this pattern will hit:\r\n\r\n1. **Identity** — The same concept gets extracted under slightly different names from related sources. The wiki ends up with duplicate pages (\"Cognitive Dissonance Marketing\" and \"Cognitive Dissonance and Urgency\" from the same book, in my case).\r\n\r\n2. **Level** — Life-scale themes (\"Personal AGI\") end up at the same level as tactical findings (\"Urgency Trigger\"). When everything is flat, importance disappears.\r\n\r\n3. **Relationship** — Concepts get linked as \"related,\" but the type is lost. Similar, contains, contradicts — all collapsed into one word, which makes the graph useful for navigation but not for thinking.\r\n\r\nI did a DDD event-storming pass on the wiki domain and treated each as a first-class domain event (`DuplicateCandidateDetected`, `ConceptsMerged`, `ConceptRelationshipTyped`, `ConceptLevelChanged`). These run on what I call a Dream cycle — a background pass borrowed from how human memory consolidates during sleep. It also handles the \"lint\" operation mentioned in the gist. \r\n\r\nFound another commenter (Andrii) on X who's solving Level a different way — by extracting *citable claims* first, then building the concept layer on top of claim collections. The claim approach makes Level fall out structurally (high-claim concepts are heavyweight, low-claim ones are light), which feels more elegant than my event-driven approach. I'm going to try integrating both. \r\n\r\nThanks for the framing — it's already shaped how a small group of us is thinking about this.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6149584",
"id": 6149584,
"node_id": "GC_lADOCg-ZRdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd1dA",
"user": {
"login": "jianghailong-xy",
"id": 168794437,
"node_id": "U_kgDOCg-ZRQ",
"avatar_url": "https://avatars.githubusercontent.com/u/168794437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jianghailong-xy",
"html_url": "https://github.com/jianghailong-xy",
"followers_url": "https://api.github.com/users/jianghailong-xy/followers",
"following_url": "https://api.github.com/users/jianghailong-xy/following{/other_user}",
"gists_url": "https://api.github.com/users/jianghailong-xy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jianghailong-xy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jianghailong-xy/subscriptions",
"organizations_url": "https://api.github.com/users/jianghailong-xy/orgs",
"repos_url": "https://api.github.com/users/jianghailong-xy/repos",
"events_url": "https://api.github.com/users/jianghailong-xy/events{/privacy}",
"received_events_url": "https://api.github.com/users/jianghailong-xy/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-14T09:16:17Z",
"updated_at": "2026-05-14T09:16:17Z",
"body": "Spent the last few months building basically this — three buckets (raw sources, agent-maintained wiki, agent config) with a self-healing maintenance loop on top.\r\n\r\nThe mapping ended up surprisingly literal:\r\n\r\n- **sources/** — append-only raw research the researcher agent writes; URLs deduped across runs so we don't crawl the same page twice.\r\n- **wiki/** — structured markdown the curator agent (re)writes from sources. One ingest run typically touches 8–15 pages, exactly as you describe.\r\n- **agents table** — per-wiki schedules + trigger graph. A daily cron fires the researcher, which cascades into ingest, which cascades into lint.\r\n\r\nThe piece that ended up mattering most was your line about periodic linting. We pushed it into a self-healing loop: the inspector agent reports cross-page contradictions, stale claims, orphan wikilinks, and data gaps, then auto-chains a scoped re-research + refine for anything that needs fresh sources. High-confidence fixes (e.g. basename-exact missing-page links) apply with no LLM call; lower-confidence ones either auto-apply or queue for human review, per-wiki toggle.\r\n\r\nA few wikis built this way:\r\n\r\n- OpenAI — https://wikova.com/wiki/od60853y\r\n- Elon Musk — https://wikova.com/wiki/tzg3ChuB\r\n- NVIDIA — https://wikova.com/wiki/VmhKV1Gd\r\n- Karpathy Wiki — https://wikova.com/wiki/UirQd0U3\r\n- ChatGPT — https://wikova.com/wiki/F7D3aoql\r\n- Anthropic and Claude — https://wikova.com/wiki/GmFezP53\r\n- Google — https://wikova.com/wiki/wtK2dHcL\r\n- Andrej Karpathy — https://wikova.com/wiki/lAuGSDQ7\r\n\r\nLive at https://wikova.com — drop a topic in the search bar and the pipeline kicks off."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6149605",
"id": 6149605,
"node_id": "GC_lADOAQ3RdNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd1eU",
"user": {
"login": "tigerlaibao",
"id": 17682804,
"node_id": "MDQ6VXNlcjE3NjgyODA0",
"avatar_url": "https://avatars.githubusercontent.com/u/17682804?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tigerlaibao",
"html_url": "https://github.com/tigerlaibao",
"followers_url": "https://api.github.com/users/tigerlaibao/followers",
"following_url": "https://api.github.com/users/tigerlaibao/following{/other_user}",
"gists_url": "https://api.github.com/users/tigerlaibao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tigerlaibao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tigerlaibao/subscriptions",
"organizations_url": "https://api.github.com/users/tigerlaibao/orgs",
"repos_url": "https://api.github.com/users/tigerlaibao/repos",
"events_url": "https://api.github.com/users/tigerlaibao/events{/privacy}",
"received_events_url": "https://api.github.com/users/tigerlaibao/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-14T09:27:35Z",
"updated_at": "2026-05-14T09:27:35Z",
"body": "Love this. The \"compile once, keep current\" framing nails why RAG alone feels so stateless.\r\n\r\nI've been building something adjacent but for a different audience — [Memex](https://memexlab.ai/), a local-first mobile app (iOS + Android) where you just capture thoughts, photos, and voice memos as they come. A multi-agent system quietly organizes everything into structured cards, surfaces patterns, and builds up a picture of your life over time. No manual filing, no schema design — you just record, and the knowledge accumulates.\r\n\r\nThe other angle we lean into is emotional companionship. A lot of what people want to capture — reflections, frustrations, half-formed thoughts — they won't post publicly. So we pair the knowledge layer with AI companion characters you can actually talk to about your day. It's less \"research wiki\" and more \"private space that understands you and remembers.\"\r\n\r\nSame philosophical root (Bush's Memex, persistent personal knowledge, LLM as maintainer), different surface: low-friction capture + companionship rather than deep research workflows. Open source if anyone's curious : https://github.com/memex-lab/memex"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6150009",
"id": 6150009,
"node_id": "GC_lADOAAIjv9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd13k",
"user": {
"login": "belmendo",
"id": 140223,
"node_id": "MDQ6VXNlcjE0MDIyMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/140223?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/belmendo",
"html_url": "https://github.com/belmendo",
"followers_url": "https://api.github.com/users/belmendo/followers",
"following_url": "https://api.github.com/users/belmendo/following{/other_user}",
"gists_url": "https://api.github.com/users/belmendo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/belmendo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/belmendo/subscriptions",
"organizations_url": "https://api.github.com/users/belmendo/orgs",
"repos_url": "https://api.github.com/users/belmendo/repos",
"events_url": "https://api.github.com/users/belmendo/events{/privacy}",
"received_events_url": "https://api.github.com/users/belmendo/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-14T13:37:26Z",
"updated_at": "2026-05-14T13:37:26Z",
"body": "With the powers vested in me, I heretofore henceforth dub thee, “Lemon Wiki”."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6150764",
"id": 6150764,
"node_id": "GC_lADOAAOAxdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd2mw",
"user": {
"login": "JeanHuguesRobert",
"id": 229573,
"node_id": "MDQ6VXNlcjIyOTU3Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/229573?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JeanHuguesRobert",
"html_url": "https://github.com/JeanHuguesRobert",
"followers_url": "https://api.github.com/users/JeanHuguesRobert/followers",
"following_url": "https://api.github.com/users/JeanHuguesRobert/following{/other_user}",
"gists_url": "https://api.github.com/users/JeanHuguesRobert/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JeanHuguesRobert/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JeanHuguesRobert/subscriptions",
"organizations_url": "https://api.github.com/users/JeanHuguesRobert/orgs",
"repos_url": "https://api.github.com/users/JeanHuguesRobert/repos",
"events_url": "https://api.github.com/users/JeanHuguesRobert/events{/privacy}",
"received_events_url": "https://api.github.com/users/JeanHuguesRobert/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-14T23:36:24Z",
"updated_at": "2026-05-14T23:36:24Z",
"body": "This pattern feels exactly right: the key move is shifting from query-time retrieval to a persistent, compounding knowledge artifact.\r\n\r\nOne extension I’ve been exploring is what happens when the LLM-maintained wiki becomes multi-agent or shared. At that point, many wiki edits hide judgment points:\r\n\r\n- update an existing claim?\r\n- mark a contradiction as unresolved?\r\n- create a new page?\r\n- require human review before mutating shared state?\r\n\r\nI’m experimenting with a lightweight “resumable judgment” pattern: instead of letting the agent silently decide, the tool emits a typed continuation object with context, alternatives, constraints, and an expected result schema. A human, agent, script, workflow, or digital twin returns a structured `step_result`; the tool validates it and resumes.\r\n\r\nSo, roughly:\r\n\r\nRAG → LLM Wiki → governed LLM Wiki / Cogentia\r\n\r\nRaw sources remain the territory, the wiki is a derived map, and continuations expose the judgment points where the map is updated.\r\n\r\nRelated CLI write-up:\r\nhttps://github.com/JeanHuguesRobert/cogentia/blob/main/research/agent_resumable_cli.md"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6151822",
"id": 6151822,
"node_id": "GC_lADOB3kVNtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd3o4",
"user": {
"login": "JotaSXBR",
"id": 125375798,
"node_id": "U_kgDOB3kVNg",
"avatar_url": "https://avatars.githubusercontent.com/u/125375798?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JotaSXBR",
"html_url": "https://github.com/JotaSXBR",
"followers_url": "https://api.github.com/users/JotaSXBR/followers",
"following_url": "https://api.github.com/users/JotaSXBR/following{/other_user}",
"gists_url": "https://api.github.com/users/JotaSXBR/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JotaSXBR/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JotaSXBR/subscriptions",
"organizations_url": "https://api.github.com/users/JotaSXBR/orgs",
"repos_url": "https://api.github.com/users/JotaSXBR/repos",
"events_url": "https://api.github.com/users/JotaSXBR/events{/privacy}",
"received_events_url": "https://api.github.com/users/JotaSXBR/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-15T14:23:58Z",
"updated_at": "2026-05-15T14:23:58Z",
"body": "my humble contribuition on this idea:\r\n\r\nhttps://github.com/JotaSXBR/obsidian-infinite-brain"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6151968",
"id": 6151968,
"node_id": "GC_lADOAWkNM9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd3yA",
"user": {
"login": "7xuanlu",
"id": 23661875,
"node_id": "MDQ6VXNlcjIzNjYxODc1",
"avatar_url": "https://avatars.githubusercontent.com/u/23661875?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/7xuanlu",
"html_url": "https://github.com/7xuanlu",
"followers_url": "https://api.github.com/users/7xuanlu/followers",
"following_url": "https://api.github.com/users/7xuanlu/following{/other_user}",
"gists_url": "https://api.github.com/users/7xuanlu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/7xuanlu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/7xuanlu/subscriptions",
"organizations_url": "https://api.github.com/users/7xuanlu/orgs",
"repos_url": "https://api.github.com/users/7xuanlu/repos",
"events_url": "https://api.github.com/users/7xuanlu/events{/privacy}",
"received_events_url": "https://api.github.com/users/7xuanlu/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-15T15:42:36Z",
"updated_at": "2026-05-15T15:42:36Z",
"body": "Small update after trying to turn this idea into a daily AI-work ritual.\r\n\r\nOrigin ended up less like “another LLM wiki” and more like a local AI-work layer: captures, handoffs, memories, distilled pages, review, and retrieval in one loop.\r\n\r\nThe daily flow starts from what should survive: decisions, lessons, preferences, project context, notes, and things future agents should not have to rediscover. Those stay as granular memory records. Distilled wiki pages give the bigger picture.\r\n\r\nThe distill loop does more than create new pages: it absorbs new memories into existing pages, refreshes stale pages when sources change, and keeps user-edited pages locked unless rebuilt.\r\n\r\nStill early, but this is the shape that has been useful day to day.\r\n\r\nhttps://github.com/7xuanlu/origin"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6152026",
"id": 6152026,
"node_id": "GC_lADOAWQcHdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd31o",
"user": {
"login": "Sistema2D",
"id": 23338013,
"node_id": "MDQ6VXNlcjIzMzM4MDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/23338013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sistema2D",
"html_url": "https://github.com/Sistema2D",
"followers_url": "https://api.github.com/users/Sistema2D/followers",
"following_url": "https://api.github.com/users/Sistema2D/following{/other_user}",
"gists_url": "https://api.github.com/users/Sistema2D/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sistema2D/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sistema2D/subscriptions",
"organizations_url": "https://api.github.com/users/Sistema2D/orgs",
"repos_url": "https://api.github.com/users/Sistema2D/repos",
"events_url": "https://api.github.com/users/Sistema2D/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sistema2D/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-15T16:26:48Z",
"updated_at": "2026-05-15T16:26:48Z",
"body": "I've built FrameCode VibeWork, a documentation and governance framework based on this LLM Wiki concept to reduce context loss during AI-assisted development. It organizes plans, changelogs, and an incremental technical memory. Check it out here: https://github.com/Sistema2D/FrameCode-VibeWork"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6152217",
"id": 6152217,
"node_id": "GC_lADOAjNRndoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd4Bk",
"user": {
"login": "HabermannR",
"id": 36917661,
"node_id": "MDQ6VXNlcjM2OTE3NjYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36917661?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HabermannR",
"html_url": "https://github.com/HabermannR",
"followers_url": "https://api.github.com/users/HabermannR/followers",
"following_url": "https://api.github.com/users/HabermannR/following{/other_user}",
"gists_url": "https://api.github.com/users/HabermannR/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HabermannR/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HabermannR/subscriptions",
"organizations_url": "https://api.github.com/users/HabermannR/orgs",
"repos_url": "https://api.github.com/users/HabermannR/repos",
"events_url": "https://api.github.com/users/HabermannR/events{/privacy}",
"received_events_url": "https://api.github.com/users/HabermannR/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-15T20:15:35Z",
"updated_at": "2026-05-15T20:15:35Z",
"body": "I built a Nexidion, a knowledge database, with an optional LLM agent. Really fits this style!\r\nhttps://github.com/HabermannR/Nexidion\r\nIt works with OpenAI or local LLMs."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6152363",
"id": 6152363,
"node_id": "GC_lADOBYq8H9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd4Ks",
"user": {
"login": "TrueHOOHA",
"id": 92978207,
"node_id": "U_kgDOBYq8Hw",
"avatar_url": "https://avatars.githubusercontent.com/u/92978207?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TrueHOOHA",
"html_url": "https://github.com/TrueHOOHA",
"followers_url": "https://api.github.com/users/TrueHOOHA/followers",
"following_url": "https://api.github.com/users/TrueHOOHA/following{/other_user}",
"gists_url": "https://api.github.com/users/TrueHOOHA/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TrueHOOHA/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TrueHOOHA/subscriptions",
"organizations_url": "https://api.github.com/users/TrueHOOHA/orgs",
"repos_url": "https://api.github.com/users/TrueHOOHA/repos",
"events_url": "https://api.github.com/users/TrueHOOHA/events{/privacy}",
"received_events_url": "https://api.github.com/users/TrueHOOHA/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-16T01:25:19Z",
"updated_at": "2026-05-16T01:25:19Z",
"body": "This is my implementation of Karpathy's LLM Wiki. A key highlight is the use of agent skills to enforce workflow rigidity and mitigate agent behavioral deviation. \r\nhttps://github.com/TrueHOOHA/LLM-Wiki-Skilled"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6152776",
"id": 6152776,
"node_id": "GC_lADOAGxsBNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd4kg",
"user": {
"login": "mikhashev",
"id": 7105540,
"node_id": "MDQ6VXNlcjcxMDU1NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7105540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mikhashev",
"html_url": "https://github.com/mikhashev",
"followers_url": "https://api.github.com/users/mikhashev/followers",
"following_url": "https://api.github.com/users/mikhashev/following{/other_user}",
"gists_url": "https://api.github.com/users/mikhashev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mikhashev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mikhashev/subscriptions",
"organizations_url": "https://api.github.com/users/mikhashev/orgs",
"repos_url": "https://api.github.com/users/mikhashev/repos",
"events_url": "https://api.github.com/users/mikhashev/events{/privacy}",
"received_events_url": "https://api.github.com/users/mikhashev/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-16T10:27:31Z",
"updated_at": "2026-05-16T10:27:31Z",
"body": "Follow-up on our [v0.25.0 knowledge graph post above](https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f?permalink_comment_id=6148033#gistcomment-6148033). The graph works — fourth retrieval channel alongside BM25 / FAISS / NER. But it surfaced a question we can't stop thinking about: what if knowledge encoding belonged in weight space rather than text space?\r\n\r\nCurrent state: agent reads knowledge files (seconds of retrieval and reading), synthesizes. Works, but each file is independent. Cross-file connections require the agent to guess which files to load together — and synthesis happens at the language-model layer, not at the knowledge layer itself.\r\n\r\nHypothetical: a small, specialised model (~50–100M params) holding the corpus in its weights. Not a general-purpose LLM — purely a knowledge encoding and retrieval layer alongside the primary reasoning LLM. Trained on graph triples rather than raw text. Cross-file synthesis becomes a single forward pass through learned associations.\r\n\r\nThe twist is the update mechanism. TTT-E2E (Tandon et al., arxiv 2512.23675) shows models can compress context into weights during inference — but they reset per call. We're asking whether persistence becomes safe when the model is knowledge-only: bounded domain, predictable update patterns, no general reasoning to corrupt.\r\n\r\nIf it works, updates look like graph operations: new fact → locate affected weight region (ROME/MEMIT-style, Meng et al. 2022/2023) → update only that region. The routing key is the knowledge-graph `node_id` — a stable structural identifier, not a learned embedding. Unused regions decay exponentially (Hebbian / Fusi-Abbott, Nat Neuro 2007). Every update carries bi-temporal provenance through the graph audit layer, so weight changes stay traceable to source decisions.\r\n\r\nEssentially: what if your knowledge store wasn't a database, but a tiny neural network that learned your corpus and updated incrementally — like a graph, but in weight space?\r\n\r\nThe combination we haven't found prior art for: TTT-style intra-inference updates that *persist*, sparse weight regions addressed by graph-structured IDs, and bi-temporal audit on weight changes. Individually each piece is published — closest mentions in this thread are OpenCrab (self-distillation from corrections, mo-vic, April 24) and Larimar (Das et al., episodic memory). But neither routes updates through an explicit knowledge graph, and neither attempts audit on the weight deltas themselves.\r\n\r\nEarly research, no implementation yet. Curious if anyone is exploring specialised knowledge-only models — not general LLMs with RAG bolted on, but models whose entire purpose is to know one specific corpus, and update like a graph."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153207",
"id": 6153207,
"node_id": "GC_lADOALUbLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd4_c",
"user": {
"login": "theafh",
"id": 11868972,
"node_id": "MDQ6VXNlcjExODY4OTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11868972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theafh",
"html_url": "https://github.com/theafh",
"followers_url": "https://api.github.com/users/theafh/followers",
"following_url": "https://api.github.com/users/theafh/following{/other_user}",
"gists_url": "https://api.github.com/users/theafh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theafh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theafh/subscriptions",
"organizations_url": "https://api.github.com/users/theafh/orgs",
"repos_url": "https://api.github.com/users/theafh/repos",
"events_url": "https://api.github.com/users/theafh/events{/privacy}",
"received_events_url": "https://api.github.com/users/theafh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-16T21:37:16Z",
"updated_at": "2026-05-16T21:37:16Z",
"body": "Quick follow-up on the per-repo wiki skill from earlier in the thread. Since the original comment, a few things have landed based on what hurt during daily use:\r\n\r\n- Triage-first ingest. Two new skills sit in front of the wiki: wiki_import for one named source (URL, PDF, paper, transcript, paste), and wiki_wrapup for the current chat session. Both capture the raw source, diff every candidate against the existing wiki, and emit a triage report (new pages, extensions to existing pages, and contradictions with both excerpts and concrete reconciliation options) before any wiki page is written. Approved writes route back through the wiki skill, so ingest logic stays in one place.\r\n- Cross-page contradiction detection. The cleanup agent now flags contradictions between existing pages instead of silently picking a side. It surfaces them as a contested-page report with both sides quoted, so the human decides.\r\n- wiki_fix one-shot. A thin wrapper around the cleanup agent. Discovers the wiki of the current repo, runs the linter, fixes every fixable issue, re-lints until clean. Useful when you just want the wiki tidied without a back-and-forth.\r\n- Provenance via sha256. Raw sources carry a body-only sha256 in frontmatter, so the linter can detect when a source has drifted from what was originally filed. Ships as a bundled helper script alongside discovery, init, and lint.\r\n- Walk-up discovery. The skill resolves the wiki from any subdirectory of the repo (with .no_wiki opt-outs and a candidate prompt when ambiguous), instead of requiring you to be at the root.\r\n\r\nThanks to everyone who tried it and posted their own updates upthread.\r\n\r\nCode: [https://github.com/theafh/ai-modules/tree/main/plugins/knowledge_management](https://github.com/theafh/ai-modules/tree/main/plugins/knowledge_management)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153243",
"id": 6153243,
"node_id": "GC_lADOACiZ59oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd5Bs",
"user": {
"login": "jdbranham",
"id": 2660839,
"node_id": "MDQ6VXNlcjI2NjA4Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/2660839?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jdbranham",
"html_url": "https://github.com/jdbranham",
"followers_url": "https://api.github.com/users/jdbranham/followers",
"following_url": "https://api.github.com/users/jdbranham/following{/other_user}",
"gists_url": "https://api.github.com/users/jdbranham/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jdbranham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jdbranham/subscriptions",
"organizations_url": "https://api.github.com/users/jdbranham/orgs",
"repos_url": "https://api.github.com/users/jdbranham/repos",
"events_url": "https://api.github.com/users/jdbranham/events{/privacy}",
"received_events_url": "https://api.github.com/users/jdbranham/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-16T23:38:53Z",
"updated_at": "2026-05-16T23:38:53Z",
"body": "Very curious how many of these comments are from bots.\r\nThere can't be this many people that think an LLM wiki is good solution for knowledge at scale. \r\n\r\nI've seen a few voices of reason here, but most everything is \"What a great and novel idea\". Which is wrong on both accounts. \r\nFolks - for your own sake, please research information retrieval and storage to understand why this doesn't work.\r\n\r\nIf you're still reading...\r\nCheck out CIBFE or https://headkey.ai for a pluggable cognitive solution that's more than memory. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153265",
"id": 6153265,
"node_id": "GC_lADOAKcUs9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd5DE",
"user": {
"login": "TheSeitzGroup",
"id": 10949811,
"node_id": "MDQ6VXNlcjEwOTQ5ODEx",
"avatar_url": "https://avatars.githubusercontent.com/u/10949811?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheSeitzGroup",
"html_url": "https://github.com/TheSeitzGroup",
"followers_url": "https://api.github.com/users/TheSeitzGroup/followers",
"following_url": "https://api.github.com/users/TheSeitzGroup/following{/other_user}",
"gists_url": "https://api.github.com/users/TheSeitzGroup/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TheSeitzGroup/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheSeitzGroup/subscriptions",
"organizations_url": "https://api.github.com/users/TheSeitzGroup/orgs",
"repos_url": "https://api.github.com/users/TheSeitzGroup/repos",
"events_url": "https://api.github.com/users/TheSeitzGroup/events{/privacy}",
"received_events_url": "https://api.github.com/users/TheSeitzGroup/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T00:34:36Z",
"updated_at": "2026-05-17T00:35:00Z",
"body": "> If you're still reading... Check out CIBFE or https://headkey.ai for a pluggable cognitive solution that's more than memory.\r\nCute --a human bot. \r\n\r\nCool product. Value prop is a little noisy. \r\nWhy are you different than all others building the ` insert semantic for knowledge graph here ` product?\r\n\r\nUnsolicited recommendations: \r\n- Start with \"Your Agent Thinks. We Handle the Rest.\" as your hook\r\n- Target Enterprise VP's of IT 50-100MM in USA only. Build an ICP and a pitch for that specific audience\r\n- Read this book: A. Savoia's Pretoyping\r\n- set 10 appointment/presentations per week and cater to this ICP\r\n- if this strat. works message me in 3 months\r\n\r\nCheers Amigo.\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153268",
"id": 6153268,
"node_id": "GC_lADOCLjoJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd5DQ",
"user": {
"login": "lastforkbender",
"id": 146335780,
"node_id": "U_kgDOCLjoJA",
"avatar_url": "https://avatars.githubusercontent.com/u/146335780?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lastforkbender",
"html_url": "https://github.com/lastforkbender",
"followers_url": "https://api.github.com/users/lastforkbender/followers",
"following_url": "https://api.github.com/users/lastforkbender/following{/other_user}",
"gists_url": "https://api.github.com/users/lastforkbender/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lastforkbender/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lastforkbender/subscriptions",
"organizations_url": "https://api.github.com/users/lastforkbender/orgs",
"repos_url": "https://api.github.com/users/lastforkbender/repos",
"events_url": "https://api.github.com/users/lastforkbender/events{/privacy}",
"received_events_url": "https://api.github.com/users/lastforkbender/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T00:49:24Z",
"updated_at": "2026-05-17T00:49:24Z",
"body": "```python\r\n# rev9_bnn_rnsl_system.py\r\n\r\n\"\"\"\r\n(• Multi-Layered Architecture: 4 layers with 12 control points each\r\n(• Rotational Node Pairs: 2 paired nodes per control point in 3D space\r\n(• 3D Residual Cognition Subspace: Complex-valued gradient scoring\r\n(• Recursive Meta-Commutators: Discrete evolution with child generation\r\n(• RNSL System: High/low frequency filtering for gradient scoring\r\n(• Polarity Interval Management: Adaptive N_low/N_high bounds\r\n(• Inequality Decision Gate: n{yX-R(t+1)} >= n{zX+R(t+1)}\r\n(• Curvature Set Matching: Matches computed signatures to nodes\r\n(• Full Visualization Suite: Training history, node distributions, 3D curves\r\n(• Performance Benchmarking: Speed & memory analysis\r\n(• Comprehensive Logging: All phases tracked and reported\r\n\"\"\"\r\n\r\nimport numpy as np\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.optim as optim\r\nfrom scipy.interpolate import BSpline\r\nfrom scipy.special import comb\r\nimport numba as nb\r\nfrom typing import Tuple, List, Dict\r\nfrom dataclasses import dataclass\r\n\r\n# ============================================================================\r\n# NUMBA-OPTIMIZED COMPUTATIONS FOR SPEED\r\n# ============================================================================\r\n\r\n@nb.jit(nopython=True, cache=True)\r\ndef compute_rotation_matrix_3d(angles: np.ndarray) -> np.ndarray:\r\n \"\"\"Compute 3D rotation matrix from Euler angles (roll, pitch, yaw)\"\"\"\r\n roll, pitch, yaw = angles[0], angles[1], angles[2]\r\n \r\n # Rotation matrices for each axis\r\n Rx = np.array([\r\n [1, 0, 0],\r\n [0, np.cos(roll), -np.sin(roll)],\r\n [0, np.sin(roll), np.cos(roll)]\r\n ])\r\n \r\n Ry = np.array([\r\n [np.cos(pitch), 0, np.sin(pitch)],\r\n [0, 1, 0],\r\n [-np.sin(pitch), 0, np.cos(pitch)]\r\n ])\r\n \r\n Rz = np.array([\r\n [np.cos(yaw), -np.sin(yaw), 0],\r\n [np.sin(yaw), np.cos(yaw), 0],\r\n [0, 0, 1]\r\n ])\r\n \r\n return Rz @ Ry @ Rx\r\n\r\n@nb.jit(nopython=True, cache=True)\r\ndef compute_curvature_score(points: np.ndarray) -> float:\r\n \"\"\"Compute local curvature at control point using discrete approximation\"\"\"\r\n if len(points) < 3:\r\n return 0.0\r\n \r\n # Central difference for first derivative\r\n dp1 = points[1] - points[0]\r\n dp2 = points[2] - points[1]\r\n \r\n # Discrete curvature from cross product magnitude\r\n cross = np.cross(dp1, dp2)\r\n curvature = np.linalg.norm(cross) / (np.linalg.norm(dp1) * np.linalg.norm(dp2) + 1e-8)\r\n return curvature\r\n\r\n@nb.jit(nopython=True, cache=True)\r\ndef complex_norm_3d(real_part: np.ndarray, imag_part: np.ndarray) -> float:\r\n \"\"\"Compute norm of complex 3D vector\"\"\"\r\n return np.sqrt(np.sum(real_part**2 + imag_part**2))\r\n\r\n\r\n# ============================================================================\r\n# RECURSIVE CURVATURE NODE SCORING LENGTH (RNSL) SYSTEM\r\n# ============================================================================\r\n\r\nclass RNSLSystem:\r\n \"\"\"Recursive curvature Node Scoring Length with complex-valued filtering\"\"\"\r\n \r\n def __init__(self, dim: int = 3, high_freq_cutoff: float = 0.7):\r\n self.dim = dim\r\n self.high_freq_cutoff = high_freq_cutoff\r\n self.recursion_depth = 0\r\n self.max_recursion = 5\r\n \r\n def high_low_filter(self, signal: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:\r\n \"\"\"Decompose signal into high and low frequency components\"\"\"\r\n fft_signal = np.fft.fft(signal, axis=0)\r\n freqs = np.fft.fftfreq(len(signal))\r\n \r\n # High/low split\r\n high_mask = np.abs(freqs) > self.high_freq_cutoff\r\n low_mask = ~high_mask\r\n \r\n fft_high = fft_signal * high_mask[:, None]\r\n fft_low = fft_signal * low_mask[:, None]\r\n \r\n high_filtered = np.fft.ifft(fft_high, axis=0).real\r\n low_filtered = np.fft.ifft(fft_low, axis=0).real\r\n \r\n return low_filtered, high_filtered\r\n \r\n def score_node(self, control_point: np.ndarray, \r\n node_probability: float) -> complex:\r\n \"\"\"Compute recursive curvature score as complex number\"\"\"\r\n \r\n # Curvature-based real component\r\n curvature = np.linalg.norm(np.diff(control_point, axis=0))\r\n real_score = curvature * node_probability\r\n \r\n # Probabilistic imaginary component\r\n imag_score = np.angle(node_probability + 1j * curvature)\r\n \r\n return complex(real_score, imag_score)\r\n\r\n\r\n# ============================================================================\r\n# ROTATIONAL NODE PAIR SYSTEM\r\n# ============================================================================\r\n\r\nclass RotationalNodePair:\r\n \"\"\"Pairwise rotational node in 3D residual cognition subspace\"\"\"\r\n \r\n def __init__(self, node_id: int, dim: int = 3):\r\n self.node_id = node_id\r\n self.dim = dim\r\n \r\n # Primary and secondary node positions in 3D\r\n self.position_primary = np.random.randn(dim) * 0.1\r\n self.position_secondary = np.random.randn(dim) * 0.1\r\n \r\n # Rotation parameters (Euler angles)\r\n self.rotation_angles = np.random.randn(3) * 0.01\r\n \r\n # Complex-valued gradient scoring\r\n self.score_real = np.random.randn(1)[0] * 0.1\r\n self.score_imag = np.random.randn(1)[0] * 0.1\r\n \r\n # Node length probability (Π_i(t))\r\n self.node_prob = np.random.rand()\r\n \r\n # Polarity interval bounds [N_low, N_high]\r\n self.N_low = np.random.rand() * 0.5\r\n self.N_high = self.N_low + np.random.rand() * 0.5\r\n \r\n def get_rotation_matrix(self) -> np.ndarray:\r\n \"\"\"Get 3D rotation matrix from angles\"\"\"\r\n return compute_rotation_matrix_3d(self.rotation_angles)\r\n \r\n def apply_rotation(self, vector: np.ndarray) -> np.ndarray:\r\n \"\"\"Apply rotation to a 3D vector\"\"\"\r\n R = self.get_rotation_matrix()\r\n return R @ vector\r\n \r\n def get_complex_score(self) -> complex:\r\n \"\"\"Get complex-valued gradient score\"\"\"\r\n return complex(self.score_real, self.score_imag)\r\n \r\n def set_complex_score(self, score: complex):\r\n \"\"\"Update complex score\"\"\"\r\n self.score_real = score.real\r\n self.score_imag = score.imag\r\n\r\n\r\n# ============================================================================\r\n# META-COMMUTATOR (ADAPTIVE CONTROL MECHANISM)\r\n# ============================================================================\r\n\r\nclass MetaCommutator(nn.Module):\r\n \"\"\"\r\n Recursive meta-commutator with discrete evolution control.\r\n Parameterizes R and manages second-pass decisions.\r\n \"\"\"\r\n \r\n def __init__(self, num_nodes: int, dim: int = 3):\r\n super().__init__()\r\n self.num_nodes = num_nodes\r\n self.dim = dim\r\n \r\n # Parameter R: recursive junction matrix (learnable)\r\n self.R = nn.Parameter(torch.randn(dim, dim) * 0.1)\r\n \r\n # Filter parameters (y, z parameterization)\r\n self.filter_y = nn.Parameter(torch.randn(dim) * 0.1)\r\n self.filter_z = nn.Parameter(torch.randn(dim) * 0.1)\r\n \r\n # Second-pass probability predictor\r\n self.second_pass_net = nn.Sequential(\r\n nn.Linear(dim * 2, 32),\r\n nn.ReLU(),\r\n nn.Linear(32, 16),\r\n nn.ReLU(),\r\n nn.Linear(16, 1),\r\n nn.Sigmoid()\r\n )\r\n \r\n # Meta-commutator generation counter\r\n self.generation = 0\r\n self.child_commutators: List['MetaCommutator'] = []\r\n \r\n def forward(self, X: torch.Tensor, t: int) -> Tuple[torch.Tensor, bool]:\r\n \"\"\"\r\n Forward pass with inequality decision gate.\r\n \r\n Inequality: n{yX - R(t+1)} >= n{zX + R(t+1)}\r\n \r\n Returns:\r\n - Updated X\r\n - Boolean flag for second-pass activation\r\n \"\"\"\r\n # Compute paths\r\n path_y = self.filter_y.unsqueeze(0) * X - torch.matmul(X, self.R.T)\r\n path_z = self.filter_z.unsqueeze(0) * X + torch.matmul(X, self.R.T)\r\n \r\n # Compute norms\r\n norm_y = torch.norm(path_y, dim=1, keepdim=True)\r\n norm_z = torch.norm(path_z, dim=1, keepdim=True)\r\n \r\n # Inequality decision: n{yX - R(t+1)} >= n{zX + R(t+1)}\r\n inequality_satisfied = (norm_y >= norm_z).float()\r\n \r\n # Predict second-pass probability\r\n combined = torch.cat([norm_y, norm_z], dim=1)\r\n second_pass_prob = self.second_pass_net(combined)\r\n \r\n # Select path based on inequality\r\n X_updated = torch.where(\r\n inequality_satisfied.bool(),\r\n path_y, # Use yX path if inequality TRUE\r\n path_z # Use zX path if inequality FALSE\r\n )\r\n \r\n # Activation threshold for second pass\r\n second_pass_active = (second_pass_prob > 0.5).squeeze()\r\n \r\n return X_updated, second_pass_active.item() > 0.5\r\n \r\n def create_child_commutator(self):\r\n \"\"\"Recursively create child meta-commutator for second pass\"\"\"\r\n child = MetaCommutator(self.num_nodes, self.dim)\r\n child.generation = self.generation + 1\r\n self.child_commutators.append(child)\r\n return child\r\n\r\n\r\n# ============================================================================\r\n# B-SPLINE LAYER WITH ROTATIONAL NODES\r\n# ============================================================================\r\n\r\nclass BSplineLayer(nn.Module):\r\n \"\"\"B-spline basis layer with multi-layered rotational nodes\"\"\"\r\n \r\n def __init__(self, num_control_points: int, spline_degree: int = 3, \r\n num_nodes_per_cp: int = 2):\r\n super().__init__()\r\n self.num_control_points = num_control_points\r\n self.spline_degree = spline_degree\r\n self.num_nodes_per_cp = num_nodes_per_cp\r\n \r\n # Create knot vector for B-spline\r\n self.knot_vector = np.concatenate([\r\n np.zeros(spline_degree + 1),\r\n np.linspace(0, 1, num_control_points - spline_degree + 1),\r\n np.ones(spline_degree + 1)\r\n ])\r\n \r\n # Control points (learnable)\r\n self.control_points = nn.Parameter(\r\n torch.randn(num_control_points, 3) * 0.1\r\n )\r\n \r\n # Create rotational node pairs for each control point\r\n self.node_pairs = [\r\n [RotationalNodePair(i * num_nodes_per_cp + j, dim=3)\r\n for j in range(num_nodes_per_cp)]\r\n for i in range(num_control_points)\r\n ]\r\n \r\n def evaluate_bspline(self, u: torch.Tensor) -> torch.Tensor:\r\n \"\"\"Evaluate B-spline curve at parameter values u\"\"\"\r\n u_np = u.detach().cpu().numpy()\r\n spl = BSpline(self.knot_vector, \r\n self.control_points.detach().cpu().numpy(),\r\n self.spline_degree)\r\n \r\n result = torch.tensor(spl(u_np), dtype=torch.float32)\r\n return result\r\n \r\n def get_node_gradients(self, u: torch.Tensor) -> torch.Tensor:\r\n \"\"\"Get gradient scores from all rotational nodes\"\"\"\r\n gradients = []\r\n \r\n for node_pair in self.node_pairs:\r\n node_score = sum([node.get_complex_score() \r\n for node in node_pair])\r\n gradients.append([node_score.real, node_score.imag])\r\n \r\n return torch.tensor(gradients, dtype=torch.float32)\r\n\r\n\r\n# ============================================================================\r\n# FULL B-SPLINE NEURAL NETWORK\r\n# ============================================================================\r\n\r\nclass BSplineNN(nn.Module):\r\n \"\"\"\r\n Complete multi-layered B-Spline Neural Network with:\r\n - 3D residual cognition subspace\r\n - Rotational node pairs\r\n - Recursive meta-commutators\r\n - RNSL gradient scoring\r\n \"\"\"\r\n \r\n def __init__(self, num_layers: int = 3, \r\n num_control_points: int = 10,\r\n spline_degree: int = 3):\r\n super().__init__()\r\n self.num_layers = num_layers\r\n \r\n # Multi-layered B-spline components\r\n self.bspline_layers = nn.ModuleList([\r\n BSplineLayer(num_control_points, spline_degree)\r\n for _ in range(num_layers)\r\n ])\r\n \r\n # Meta-commutators for each layer\r\n self.meta_commutators = nn.ModuleList([\r\n MetaCommutator(num_control_points, dim=3)\r\n for _ in range(num_layers)\r\n ])\r\n \r\n # RNSL system\r\n self.rnsl = RNSLSystem(dim=3)\r\n \r\n # Global residual cognition projection\r\n self.residual_projection = nn.Linear(3 * num_layers, 3)\r\n \r\n def forward(self, u: torch.Tensor, \r\n control_input: torch.Tensor) -> Tuple[torch.Tensor, Dict]:\r\n \"\"\"\r\n Forward pass through multi-layered BNN.\r\n \r\n Args:\r\n u: Parameter values for B-spline evaluation\r\n control_input: Initial control point positions (batch_size, num_cp, 3)\r\n \r\n Returns:\r\n - Output: Predicted curve\r\n - Metrics: Dictionary with debugging info\r\n \"\"\"\r\n metrics = {\r\n 'second_passes': [],\r\n 'inequality_satisfied': [],\r\n 'gradient_scores': []\r\n }\r\n \r\n # Initialize with control input\r\n X = control_input.clone()\r\n residual_outputs = []\r\n \r\n # Process through each layer\r\n for layer_idx in range(self.num_layers):\r\n # Get B-spline basis evaluation\r\n bspline_curve = self.bspline_layers[layer_idx].evaluate_bspline(u)\r\n residual_outputs.append(bspline_curve)\r\n \r\n # Apply meta-commutator decision gate\r\n meta_comm = self.meta_commutators[layer_idx]\r\n X_updated, second_pass = meta_comm(X, layer_idx)\r\n \r\n # Compute RNSL gradient scores\r\n X_np = X.detach().cpu().numpy()\r\n low_freq, high_freq = self.rnsl.high_low_filter(X_np)\r\n \r\n # Update X for next layer\r\n X = torch.tensor(low_freq, dtype=torch.float32)\r\n \r\n metrics['second_passes'].append(second_pass)\r\n metrics['inequality_satisfied'].append((X_updated.norm() > 0))\r\n metrics['gradient_scores'].append(\r\n torch.norm(torch.tensor(high_freq, dtype=torch.float32)).item()\r\n )\r\n \r\n # Create child commutator if second pass activated\r\n if second_pass and len(meta_comm.child_commutators) == 0:\r\n meta_comm.create_child_commutator()\r\n \r\n # Combine residual outputs\r\n residual_combined = torch.cat(residual_outputs, dim=1)\r\n output = self.residual_projection(residual_combined)\r\n return output, metrics\r\n\r\n\r\n# ============================================================================\r\n# TRAINING SYSTEM\r\n# ============================================================================\r\n\r\nclass BNNTrainer:\r\n \"\"\"Training and optimization system for B-spline neural network\"\"\"\r\n \r\n def __init__(self, model: BSplineNN, learning_rate: float = 0.001):\r\n self.model = model\r\n self.optimizer = optim.Adam(model.parameters(), lr=learning_rate)\r\n self.loss_fn = nn.MSELoss()\r\n self.training_history = {\r\n 'loss': [],\r\n 'second_pass_ratio': [],\r\n 'gradient_norm': []\r\n }\r\n \r\n def compute_curvature_loss(self, predicted: torch.Tensor, \r\n target: torch.Tensor) -> torch.Tensor:\r\n \"\"\"Compute loss with curvature regularization\"\"\"\r\n # L2 prediction error\r\n mse_loss = self.loss_fn(predicted, target)\r\n \r\n # Curvature regularization: penalize high second derivatives\r\n second_deriv = torch.diff(torch.diff(predicted, dim=0), dim=0)\r\n curvature_loss = torch.mean(torch.norm(second_deriv, dim=1))\r\n \r\n return mse_loss + 0.1 * curvature_loss\r\n \r\n def train_epoch(self, dataloader) -> Dict:\r\n \"\"\"Train for one epoch\"\"\"\r\n self.model.train()\r\n epoch_loss = 0.0\r\n epoch_second_passes = 0\r\n epoch_gradient_norm = 0.0\r\n num_batches = 0\r\n \r\n for batch_idx, (control_input, target_curve) in enumerate(dataloader):\r\n self.optimizer.zero_grad()\r\n \r\n # Generate parameter values\r\n u = torch.linspace(0, 1, target_curve.shape[1])\r\n \r\n # Forward pass\r\n predicted, metrics = self.model(u, control_input)\r\n \r\n # Compute loss\r\n loss = self.compute_curvature_loss(predicted, target_curve)\r\n \r\n # Backward pass\r\n loss.backward()\r\n torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)\r\n self.optimizer.step()\r\n \r\n # Accumulate metrics\r\n epoch_loss += loss.item()\r\n epoch_second_passes += sum(metrics['second_passes'])\r\n epoch_gradient_norm += np.mean(metrics['gradient_scores'])\r\n num_batches += 1\r\n \r\n # Average metrics\r\n avg_loss = epoch_loss / num_batches\r\n avg_second_passes = epoch_second_passes / (num_batches * self.model.num_layers)\r\n avg_gradient = epoch_gradient_norm / num_batches\r\n \r\n self.training_history['loss'].append(avg_loss)\r\n self.training_history['second_pass_ratio'].append(avg_second_passes)\r\n self.training_history['gradient_norm'].append(avg_gradient)\r\n \r\n return {\r\n 'loss': avg_loss,\r\n 'second_pass_ratio': avg_second_passes,\r\n 'gradient_norm': avg_gradient\r\n }\r\n \r\n def validate(self, dataloader) -> float:\r\n \"\"\"Validate model on validation set\"\"\"\r\n self.model.eval()\r\n val_loss = 0.0\r\n num_batches = 0\r\n \r\n with torch.no_grad():\r\n for control_input, target_curve in dataloader:\r\n u = torch.linspace(0, 1, target_curve.shape[1])\r\n predicted, _ = self.model(u, control_input)\r\n loss = self.compute_curvature_loss(predicted, target_curve)\r\n val_loss += loss.item()\r\n num_batches += 1\r\n \r\n return val_loss / num_batches\r\n\r\n\r\n# ============================================================================\r\n# DATA GENERATION FOR TRAINING\r\n# ============================================================================\r\n\r\nclass SyntheticBSplineDataset:\r\n \"\"\"Generate synthetic 3D B-spline curves as training data\"\"\"\r\n \r\n def __init__(self, num_samples: int = 100, \r\n num_control_points: int = 10,\r\n num_curve_points: int = 50):\r\n self.num_samples = num_samples\r\n self.num_control_points = num_control_points\r\n self.num_curve_points = num_curve_points\r\n \r\n def generate_sample(self) -> Tuple[np.ndarray, np.ndarray]:\r\n \"\"\"Generate one sample: random control points and resulting curve\"\"\"\r\n \r\n # Random control points\r\n control_points = np.random.randn(self.num_control_points, 3) * 0.5\r\n \r\n # Create knot vector\r\n degree = 3\r\n knot_vector = np.concatenate([\r\n np.zeros(degree + 1),\r\n np.linspace(0, 1, self.num_control_points - degree + 1),\r\n np.ones(degree + 1)\r\n ])\r\n \r\n # Create B-spline and evaluate\r\n try:\r\n spl = BSpline(knot_vector, control_points, degree)\r\n u = np.linspace(0, 1, self.num_curve_points)\r\n curve = spl(u)\r\n except:\r\n # Fallback to simple interpolation\r\n curve = np.interp(\r\n np.linspace(0, 1, self.num_curve_points),\r\n np.linspace(0, 1, self.num_control_points),\r\n control_points[:, 0:1]\r\n )\r\n \r\n return control_points.astype(np.float32), curve.astype(np.float32)\r\n \r\n def generate_batch(self, batch_size: int) -> Tuple[torch.Tensor, torch.Tensor]:\r\n \"\"\"Generate a batch of samples\"\"\"\r\n control_batch = []\r\n curve_batch = []\r\n \r\n for _ in range(batch_size):\r\n control, curve = self.generate_sample()\r\n control_batch.append(control)\r\n curve_batch.append(curve)\r\n \r\n # Pad curves to same length\r\n max_len = max([c.shape[0] for c in curve_batch])\r\n curve_padded = []\r\n for curve in curve_batch:\r\n padded = np.pad(curve, \r\n ((0, max_len - curve.shape[0]), (0, 0)),\r\n mode='constant', constant_values=0)\r\n curve_padded.append(padded)\r\n \r\n return (torch.tensor(np.array(control_batch), dtype=torch.float32),\r\n torch.tensor(np.array(curve_padded), dtype=torch.float32))\r\n\r\n\r\n# ============================================================================\r\n# POLARITY INTERVAL CONSTRAINT MANAGER\r\n# ============================================================================\r\n\r\nclass PolarityIntervalManager:\r\n \"\"\"Manages polarity intervals for all nodes in the network\"\"\"\r\n \r\n def __init__(self, num_layers: int, num_control_points: int):\r\n self.num_layers = num_layers\r\n self.num_control_points = num_control_points\r\n \r\n # Initialize polarity intervals for each layer and control point\r\n self.intervals = {}\r\n for layer in range(num_layers):\r\n self.intervals[layer] = {}\r\n for cp in range(num_control_points):\r\n N_low = np.random.rand() * 0.3\r\n N_high = N_low + np.random.rand() * 0.7\r\n self.intervals[layer][cp] = (N_low, N_high)\r\n \r\n def check_within_interval(self, layer: int, control_point: int, \r\n value: float) -> bool:\r\n \"\"\"Check if value is within polarity interval\"\"\"\r\n N_low, N_high = self.intervals[layer][control_point]\r\n return N_low <= value <= N_high\r\n \r\n def adaptive_update(self, layer: int, control_point: int, \r\n second_pass_frequency: float):\r\n \"\"\"Adaptively adjust polarity interval based on second-pass frequency\"\"\"\r\n N_low, N_high = self.intervals[layer][control_point]\r\n \r\n # If second passes are frequent, expand interval\r\n if second_pass_frequency > 0.7:\r\n N_high += 0.05\r\n # If second passes are rare, tighten interval\r\n elif second_pass_frequency < 0.3:\r\n N_low += 0.02\r\n \r\n self.intervals[layer][control_point] = (N_low, N_high)\r\n\r\n\r\n# ============================================================================\r\n# COMPLETE TRAINING PIPELINE\r\n# ============================================================================\r\n\r\ndef train_bnn_system(num_epochs: int = 50,\r\n batch_size: int = 8,\r\n num_layers: int = 3,\r\n num_control_points: int = 10):\r\n \"\"\"\r\n Complete training pipeline for B-spline neural network\r\n \"\"\"\r\n \r\n print(\"=\"*80)\r\n print(\"B-SPLINE NEURAL NETWORK WITH RECURSIVE META-COMMUTATORS\")\r\n print(\"Multi-Layered Rotational Node Pairs in 3D Residual Cognition Subspace\")\r\n print(\"=\"*80)\r\n \r\n # Initialize model\r\n model = BSplineNN(num_layers=num_layers, \r\n num_control_points=num_control_points,\r\n spline_degree=3)\r\n \r\n # Initialize trainer\r\n trainer = BNNTrainer(model, learning_rate=0.001)\r\n \r\n # Initialize polarity interval manager\r\n polarity_mgr = PolarityIntervalManager(num_layers, num_control_points)\r\n \r\n # Generate training data\r\n print(\"\\n[1] Generating synthetic B-spline training data...\")\r\n dataset = SyntheticBSplineDataset(num_samples=100,\r\n num_control_points=num_control_points,\r\n num_curve_points=50)\r\n \r\n # Create data loaders\r\n train_batches = []\r\n for _ in range(20): # 20 batches\r\n batch = dataset.generate_batch(batch_size)\r\n train_batches.append(batch)\r\n \r\n val_batches = []\r\n for _ in range(5): # 5 validation batches\r\n batch = dataset.generate_batch(batch_size)\r\n val_batches.append(batch)\r\n \r\n print(f\" Training samples: {100}\")\r\n print(f\" Validation samples: {25}\")\r\n print(f\" Control points per curve: {num_control_points}\")\r\n print(f\" Network layers: {num_layers}\")\r\n \r\n # Training loop\r\n print(\"\\n[2] Starting training...\\n\")\r\n best_val_loss = float('inf')\r\n patience = 10\r\n patience_counter = 0\r\n \r\n for epoch in range(num_epochs):\r\n # Train\r\n metrics = trainer.train_epoch(train_batches)\r\n \r\n # Validate\r\n val_loss = trainer.validate(val_batches)\r\n \r\n # Update polarity intervals adaptively\r\n avg_second_passes = metrics['second_pass_ratio']\r\n for layer in range(num_layers):\r\n for cp in range(num_control_points):\r\n polarity_mgr.adaptive_update(layer, cp, avg_second_passes)\r\n \r\n # Early stopping\r\n if val_loss < best_val_loss:\r\n best_val_loss = val_loss\r\n patience_counter = 0\r\n else:\r\n patience_counter += 1\r\n \r\n # Print progress\r\n if (epoch + 1) % 5 == 0:\r\n print(f\"Epoch {epoch+1:3d}/{num_epochs} | \"\r\n f\"Train Loss: {metrics['loss']:.6f} | \"\r\n f\"Val Loss: {val_loss:.6f} | \"\r\n f\"2nd Pass Ratio: {metrics['second_pass_ratio']:.3f} | \"\r\n f\"Grad Norm: {metrics['gradient_norm']:.4f}\")\r\n \r\n if patience_counter >= patience:\r\n print(f\"\\nEarly stopping at epoch {epoch+1}\")\r\n break\r\n \r\n # Final evaluation\r\n print(\"\\n[3] Final Model Evaluation\")\r\n print(\"=\"*80)\r\n \r\n test_batch = dataset.generate_batch(batch_size)\r\n with torch.no_grad():\r\n u = torch.linspace(0, 1, test_batch[1].shape[1])\r\n test_output, test_metrics = model(u, test_batch[0])\r\n \r\n test_loss = trainer.loss_fn(test_output, test_batch[1]).item()\r\n \r\n print(f\"\\nFinal Test Loss: {test_loss:.6f}\")\r\n print(f\"Second-Pass Activations: {sum(test_metrics['second_passes'])}/{num_layers}\")\r\n print(f\"Mean Gradient Score: {np.mean(test_metrics['gradient_scores']):.4f}\")\r\n \r\n # Polarity interval statistics\r\n print(\"\\n[4] Polarity Interval Statistics\")\r\n print(\"=\"*80)\r\n all_ranges = []\r\n for layer in range(num_layers):\r\n for cp in range(num_control_points):\r\n N_low, N_high = polarity_mgr.intervals[layer][cp]\r\n all_ranges.append(N_high - N_low)\r\n \r\n print(f\"Mean Polarity Interval Width: {np.mean(all_ranges):.4f}\")\r\n print(f\"Min Interval Width: {np.min(all_ranges):.4f}\")\r\n print(f\"Max Interval Width: {np.max(all_ranges):.4f}\")\r\n \r\n # Meta-commutator statistics\r\n print(\"\\n[5] Meta-Commutator Recursion Statistics\")\r\n print(\"=\"*80)\r\n total_children = sum([len(mc.child_commutators) \r\n for mc in model.meta_commutators])\r\n print(f\"Total Recursive Meta-Commutator Generations: {total_children}\")\r\n print(f\"Child Commutators Created: {total_children}/{num_layers}\")\r\n \r\n # Training history\r\n print(\"\\n[6] Training History Summary\")\r\n print(\"=\"*80)\r\n print(f\"Final Training Loss: {trainer.training_history['loss'][-1]:.6f}\")\r\n print(f\"Final Second-Pass Ratio: {trainer.training_history['second_pass_ratio'][-1]:.4f}\")\r\n print(f\"Final Gradient Norm: {trainer.training_history['gradient_norm'][-1]:.4f}\")\r\n \r\n return model, trainer, polarity_mgr\r\n\r\n\r\n# ============================================================================\r\n# INFERENCE AND VISUALIZATION\r\n# ============================================================================\r\n\r\ndef inference_example(model: BSplineNN, num_samples: int = 5):\r\n \"\"\"Run inference on example samples\"\"\"\r\n \r\n print(\"\\n[7] Inference Examples\")\r\n print(\"=\"*80)\r\n \r\n dataset = SyntheticBSplineDataset(num_samples=num_samples,\r\n num_control_points=10,\r\n num_curve_points=50)\r\n \r\n model.eval()\r\n \r\n with torch.no_grad():\r\n for sample_idx in range(num_samples):\r\n control, target = dataset.generate_sample()\r\n control_tensor = torch.tensor(control, dtype=torch.float32).unsqueeze(0)\r\n \r\n u = torch.linspace(0, 1, target.shape[0])\r\n predicted, metrics = model(u, control_tensor)\r\n \r\n # Compute error\r\n error = np.linalg.norm(predicted[0].numpy() - target)\r\n \r\n print(f\"\\nSample {sample_idx+1}:\")\r\n print(f\" Prediction Error: {error:.6f}\")\r\n print(f\" Second Passes: {sum(metrics['second_passes'])}\")\r\n print(f\" Output Shape: {predicted.shape}\")\r\n print(f\" Target Shape: {target.shape}\")\r\n\r\n\r\n# ============================================================================\r\n# MAIN EXECUTION\r\n# ============================================================================\r\n\r\nif __name__ == \"__main__\":\r\n \r\n # Train the model\r\n model, trainer, polarity_mgr = train_bnn_system(\r\n num_epochs=100,\r\n batch_size=8,\r\n num_layers=3,\r\n num_control_points=10\r\n )\r\n \r\n # Run inference examples\r\n inference_example(model, num_samples=5)\r\n \r\n print(\"\\n\" + \"=\"*80)\r\n print(\"TRAINING COMPLETE\")\r\n print(\"=\"*80)\r\n \r\n # Save model\r\n torch.save(model.state_dict(), 'bnn_model.pt')\r\n print(\"\\nModel saved to 'bnn_model.pt'\")\r\n \r\n # Additional: Meta-commutator inspection\r\n print(\"\\n[8] Meta-Commutator Inspection\")\r\n print(\"=\"*80)\r\n for layer_idx, mc in enumerate(model.meta_commutators):\r\n print(f\"Layer {layer_idx}: {mc}\")\r\n print(f\" R shape: {mc.R.shape}\")\r\n print(f\" Filter Y norm: {torch.norm(mc.filter_y).item():.4f}\")\r\n print(f\" Filter Z norm: {torch.norm(mc.filter_z).item():.4f}\")\r\n print(f\" Child commutators: {len(mc.child_commutators)}\")\r\n\r\n#======================================================================\r\n#======================================================================\r\n\r\n# rev9_bnn_rnsl_visualization.py\r\n\"\"\"\r\nAdvanced visualization and analysis tools for B-spline Neural Network\r\n\"\"\"\r\n\r\nimport matplotlib.pyplot as plt\r\nimport matplotlib.patches as mpatches\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport numpy as np\r\nimport torch\r\n\r\nclass BNNVisualizer:\r\n \"\"\"Visualization tools for BNN training and inference\"\"\"\r\n \r\n def __init__(self, trainer: 'BNNTrainer'):\r\n self.trainer = trainer\r\n \r\n def plot_training_history(self, save_path: str = 'bnn_training.png'):\r\n \"\"\"Plot training loss, second-pass ratio, and gradient norms\"\"\"\r\n fig, axes = plt.subplots(1, 3, figsize=(15, 4))\r\n \r\n # Loss\r\n axes[0].plot(self.trainer.training_history['loss'], linewidth=2)\r\n axes[0].set_xlabel('Epoch')\r\n axes[0].set_ylabel('Loss')\r\n axes[0].set_title('Training Loss Over Time')\r\n axes[0].grid(True, alpha=0.3)\r\n \r\n # Second-pass ratio\r\n axes[1].plot(self.trainer.training_history['second_pass_ratio'], \r\n linewidth=2, color='orange')\r\n axes[1].set_xlabel('Epoch')\r\n axes[1].set_ylabel('Second-Pass Activation Ratio')\r\n axes[1].set_title('Meta-Commutator Activation Rate')\r\n axes[1].grid(True, alpha=0.3)\r\n axes[1].set_ylim([0, 1])\r\n \r\n # Gradient norm\r\n axes[2].plot(self.trainer.training_history['gradient_norm'], \r\n linewidth=2, color='green')\r\n axes[2].set_xlabel('Epoch')\r\n axes[2].set_ylabel('Mean Gradient Norm')\r\n axes[2].set_title('RNSL Gradient Score Evolution')\r\n axes[2].grid(True, alpha=0.3)\r\n \r\n plt.tight_layout()\r\n plt.savefig(save_path, dpi=150)\r\n print(f\"Training history plot saved to {save_path}\")\r\n \r\n def plot_3d_curve_comparison(self, predicted: np.ndarray, \r\n target: np.ndarray,\r\n save_path: str = 'bnn_3d_curves.png'):\r\n \"\"\"Plot predicted vs target 3D curves\"\"\"\r\n fig = plt.figure(figsize=(12, 5))\r\n \r\n # Predicted curve\r\n ax1 = fig.add_subplot(121, projection='3d')\r\n if predicted.shape[1] == 3:\r\n ax1.plot(predicted[:, 0], predicted[:, 1], predicted[:, 2], \r\n 'b-', linewidth=2, label='Predicted')\r\n ax1.set_xlabel('X')\r\n ax1.set_ylabel('Y')\r\n ax1.set_zlabel('Z')\r\n ax1.set_title('Predicted Curve')\r\n ax1.legend()\r\n \r\n # Target curve\r\n ax2 = fig.add_subplot(122, projection='3d')\r\n if target.shape[1] == 3:\r\n ax2.plot(target[:, 0], target[:, 1], target[:, 2], \r\n 'r-', linewidth=2, label='Target')\r\n ax2.set_xlabel('X')\r\n ax2.set_ylabel('Y')\r\n ax2.set_zlabel('Z')\r\n ax2.set_title('Target Curve')\r\n ax2.legend()\r\n \r\n plt.tight_layout()\r\n plt.savefig(save_path, dpi=150)\r\n print(f\"3D curve comparison saved to {save_path}\")\r\n \r\n def plot_node_distributions(self, model: 'BSplineNN',\r\n save_path: str = 'bnn_nodes.png'):\r\n \"\"\"Plot rotational node distributions across layers\"\"\"\r\n fig, axes = plt.subplots(1, model.num_layers, figsize=(15, 4))\r\n \r\n for layer_idx, bspline_layer in enumerate(model.bspline_layers):\r\n scores = []\r\n probs = []\r\n \r\n for node_pair in bspline_layer.node_pairs:\r\n for node in node_pair:\r\n score = abs(node.get_complex_score())\r\n scores.append(score)\r\n probs.append(node.node_prob)\r\n \r\n axes[layer_idx].scatter(probs, scores, alpha=0.6)\r\n axes[layer_idx].set_xlabel('Node Probability')\r\n axes[layer_idx].set_ylabel('Complex Score Magnitude')\r\n axes[layer_idx].set_title(f'Layer {layer_idx} Nodes')\r\n axes[layer_idx].grid(True, alpha=0.3)\r\n \r\n plt.tight_layout()\r\n plt.savefig(save_path, dpi=150)\r\n print(f\"Node distribution plot saved to {save_path}\")\r\n\r\n\r\n# ============================================================================\r\n# ADVANCED ANALYSIS: ROTATIONAL NODE DYNAMICS\r\n# ============================================================================\r\n\r\nclass RotationalNodeAnalyzer:\r\n \"\"\"Analyze rotational node behavior across training\"\"\"\r\n \r\n def __init__(self, model: 'BSplineNN'):\r\n self.model = model\r\n self.rotation_history = {layer: [] for layer in range(model.num_layers)}\r\n self.probability_history = {layer: [] for layer in range(model.num_layers)}\r\n \r\n def capture_state(self):\r\n \"\"\"Capture current state of all nodes\"\"\"\r\n for layer_idx, bspline_layer in enumerate(self.model.bspline_layers):\r\n layer_rotations = []\r\n layer_probs = []\r\n \r\n for node_pair in bspline_layer.node_pairs:\r\n for node in node_pair:\r\n # Capture rotation angles\r\n rotation_norm = np.linalg.norm(node.rotation_angles)\r\n layer_rotations.append(rotation_norm)\r\n layer_probs.append(node.node_prob)\r\n \r\n self.rotation_history[layer_idx].append(np.mean(layer_rotations))\r\n self.probability_history[layer_idx].append(np.mean(layer_probs))\r\n \r\n def analyze_rotational_coupling(self) -> Dict[str, float]:\r\n \"\"\"Analyze coupling between rotational nodes in adjacent pairs\"\"\"\r\n coupling_scores = {}\r\n \r\n for layer_idx, bspline_layer in enumerate(self.model.bspline_layers):\r\n couplings = []\r\n \r\n for node_pair in bspline_layer.node_pairs:\r\n if len(node_pair) == 2:\r\n # Measure angular similarity between paired nodes\r\n angles1 = node_pair[0].rotation_angles\r\n angles2 = node_pair[1].rotation_angles\r\n \r\n # Cosine similarity\r\n dot_product = np.dot(angles1, angles2)\r\n norm1 = np.linalg.norm(angles1)\r\n norm2 = np.linalg.norm(angles2)\r\n \r\n if norm1 > 1e-6 and norm2 > 1e-6:\r\n similarity = dot_product / (norm1 * norm2)\r\n couplings.append(similarity)\r\n \r\n if couplings:\r\n coupling_scores[f'layer_{layer_idx}'] = np.mean(couplings)\r\n \r\n return coupling_scores\r\n \r\n def print_analysis(self):\r\n \"\"\"Print comprehensive node analysis\"\"\"\r\n print(\"\\n\" + \"=\"*80)\r\n print(\"ROTATIONAL NODE DYNAMICS ANALYSIS\")\r\n print(\"=\"*80)\r\n \r\n for layer_idx in range(self.model.num_layers):\r\n if self.rotation_history[layer_idx]:\r\n rotations = self.rotation_history[layer_idx]\r\n probs = self.probability_history[layer_idx]\r\n \r\n print(f\"\\nLayer {layer_idx}:\")\r\n print(f\" Mean Rotation Norm: {np.mean(rotations):.6f}\")\r\n print(f\" Mean Node Probability: {np.mean(probs):.4f}\")\r\n print(f\" Rotation Std Dev: {np.std(rotations):.6f}\")\r\n \r\n # Coupling analysis\r\n coupling = self.analyze_rotational_coupling()\r\n print(f\"\\nRotational Node Pair Coupling:\")\r\n for layer, score in coupling.items():\r\n print(f\" {layer}: {score:.4f}\")\r\n\r\n\r\n# ============================================================================\r\n# GRADIENT MATCHING & CURVATURE SET ANALYSIS\r\n# ============================================================================\r\n\r\nclass CurvatureSetMatcher:\r\n \"\"\"Analyze and match curvature sets to rotational nodes\"\"\"\r\n \r\n def __init__(self, model: 'BSplineNN'):\r\n self.model = model\r\n self.curvature_sets = {}\r\n \r\n def compute_curvature_signature(self, curve: np.ndarray, \r\n num_segments: int = 10) -> np.ndarray:\r\n \"\"\"\r\n Compute curvature signature by dividing curve into segments\r\n and computing local curvature in each\r\n \"\"\"\r\n segment_length = len(curve) // num_segments\r\n signatures = []\r\n \r\n for i in range(num_segments):\r\n start = i * segment_length\r\n end = start + segment_length\r\n segment = curve[start:end]\r\n \r\n if len(segment) >= 3:\r\n # Central difference curvature\r\n d1 = np.diff(segment, axis=0)\r\n d2 = np.diff(d1, axis=0)\r\n \r\n cross = np.cross(d1[:-1], d2)\r\n curvature = np.mean(np.linalg.norm(cross, axis=1))\r\n signatures.append(curvature)\r\n \r\n return np.array(signatures)\r\n \r\n def match_to_nodes(self, curvature_signature: np.ndarray) -> Dict:\r\n \"\"\"Match curvature signature to best-matching rotational nodes\"\"\"\r\n matches = {}\r\n \r\n for layer_idx, bspline_layer in enumerate(self.model.bspline_layers):\r\n best_match_idx = None\r\n best_error = float('inf')\r\n \r\n # Compare against all node pairs in this layer\r\n node_idx = 0\r\n for node_pair in bspline_layer.node_pairs:\r\n for node in node_pair:\r\n # Use node's stored complex score as signature proxy\r\n node_score = abs(node.get_complex_score())\r\n node_prob = node.node_prob\r\n \r\n # Match error: difference in characteristics\r\n if len(curvature_signature) > 0:\r\n mean_curvature = np.mean(curvature_signature)\r\n error = abs(node_score - mean_curvature)\r\n \r\n if error < best_error:\r\n best_error = error\r\n best_match_idx = node_idx\r\n \r\n node_idx += 1\r\n \r\n matches[f'layer_{layer_idx}'] = {\r\n 'node_index': best_match_idx,\r\n 'match_error': best_error\r\n }\r\n \r\n return matches\r\n\r\n\r\n# ============================================================================\r\n# COMPLETE INTEGRATION: FULL PIPELINE WITH ANALYSIS\r\n# ============================================================================\r\n\r\ndef run_complete_bnn_pipeline():\r\n \"\"\"\r\n Run complete B-spline neural network pipeline with all features:\r\n - Training\r\n - Validation\r\n - Visualization\r\n - Node analysis\r\n - Curvature matching\r\n \"\"\"\r\n \r\n print(\"\\n\" + \"█\"*80)\r\n print(\"█\" + \" \"*78 + \"█\")\r\n print(\"█\" + \" COMPLETE B-SPLINE NEURAL NETWORK PIPELINE \".center(78) + \"█\")\r\n print(\"█\" + \" Multi-Layered Rotational Nodes | 3D Residual Cognition \".center(78) + \"█\")\r\n print(\"█\" + \" \"*78 + \"█\")\r\n print(\"█\"*80)\r\n \r\n # ====== PHASE 1: MODEL INITIALIZATION ======\r\n print(\"\\n[PHASE 1] Model Initialization\")\r\n print(\"-\" * 80)\r\n \r\n model = BSplineNN(num_layers=4, num_control_points=12, spline_degree=3)\r\n trainer = BNNTrainer(model, learning_rate=0.001)\r\n polarity_mgr = PolarityIntervalManager(4, 12)\r\n analyzer = RotationalNodeAnalyzer(model)\r\n curvature_matcher = CurvatureSetMatcher(model)\r\n \r\n print(f\"✓ Model initialized with 4 layers, 12 control points each\")\r\n print(f\"✓ Total parameters: {sum(p.numel() for p in model.parameters())}\")\r\n \r\n # ====== PHASE 2: DATA GENERATION ======\r\n print(\"\\n[PHASE 2] Synthetic Data Generation\")\r\n print(\"-\" * 80)\r\n \r\n dataset = SyntheticBSplineDataset(num_samples=150,\r\n num_control_points=12,\r\n num_curve_points=60)\r\n \r\n train_batches = [dataset.generate_batch(8) for _ in range(25)]\r\n val_batches = [dataset.generate_batch(8) for _ in range(8)]\r\n \r\n print(f\"✓ Generated {150} training samples\")\r\n print(f\"✓ Generated {64} validation samples\")\r\n print(f\"✓ Batch size: 8\")\r\n \r\n # ====== PHASE 3: TRAINING LOOP ======\r\n print(\"\\n[PHASE 3] Training Loop (50 epochs)\")\r\n print(\"-\" * 80)\r\n \r\n num_epochs = 50\r\n best_val_loss = float('inf')\r\n patience_counter = 0\r\n \r\n for epoch in range(num_epochs):\r\n metrics = trainer.train_epoch(train_batches)\r\n val_loss = trainer.validate(val_batches)\r\n analyzer.capture_state()\r\n \r\n # Adaptive polarity update\r\n for layer in range(4):\r\n for cp in range(12):\r\n polarity_mgr.adaptive_update(layer, cp, metrics['second_pass_ratio'])\r\n \r\n # Print progress\r\n if (epoch + 1) % 10 == 0:\r\n status = \"→\" if val_loss < best_val_loss else \"↗\"\r\n print(f\"{status} Epoch {epoch+1:3d} | \"\r\n f\"Loss: {metrics['loss']:.6f} | \"\r\n f\"Val: {val_loss:.6f} | \"\r\n f\"2Pass: {metrics['second_pass_ratio']:.3f}\")\r\n \r\n if val_loss < best_val_loss:\r\n best_val_loss = val_loss\r\n patience_counter = 0\r\n else:\r\n patience_counter += 1\r\n \r\n if patience_counter >= 8:\r\n print(f\"\\n⚠ Early stopping at epoch {epoch+1}\")\r\n break\r\n \r\n # ====== PHASE 4: INFERENCE & EVALUATION ======\r\n print(\"\\n[PHASE 4] Inference & Evaluation\")\r\n print(\"-\" * 80)\r\n \r\n model.eval()\r\n test_batch = dataset.generate_batch(8)\r\n \r\n with torch.no_grad():\r\n u = torch.linspace(0, 1, test_batch[1].shape[1])\r\n test_output, test_metrics = model(u, test_batch[0])\r\n \r\n test_loss = trainer.loss_fn(test_output, test_batch[1]).item()\r\n \r\n print(f\"✓ Test Loss: {test_loss:.6f}\")\r\n print(f\"✓ Second-Pass Activations: {sum(test_metrics['second_passes'])}/4\")\r\n print(f\"✓ Mean Gradient Score: {np.mean(test_metrics['gradient_scores']):.4f}\")\r\n \r\n # ====== PHASE 5: VISUALIZATION ======\r\n print(\"\\n[PHASE 5] Generating Visualizations\")\r\n print(\"-\" * 80)\r\n \r\n visualizer = BNNVisualizer(trainer)\r\n visualizer.plot_training_history()\r\n visualizer.plot_node_distributions(model)\r\n \r\n # Plot example predictions\r\n pred_np = test_output[0].numpy()\r\n target_np = test_batch[1][0].numpy()\r\n visualizer.plot_3d_curve_comparison(pred_np, target_np)\r\n \r\n # ====== PHASE 6: ROTATIONAL NODE ANALYSIS ======\r\n print(\"\\n[PHASE 6] Rotational Node Dynamics Analysis\")\r\n print(\"-\" * 80)\r\n \r\n analyzer.print_analysis()\r\n \r\n # ====== PHASE 7: CURVATURE MATCHING ======\r\n print(\"\\n[PHASE 7] Curvature Set Matching Analysis\")\r\n print(\"-\" * 80)\r\n \r\n # Test on a sample curve\r\n test_control, test_curve = dataset.generate_sample()\r\n curvature_sig = curvature_matcher.compute_curvature_signature(test_curve)\r\n matches = curvature_matcher.match_to_nodes(curvature_sig)\r\n \r\n print(f\"✓ Computed curvature signature with {len(curvature_sig)} segments\")\r\n print(f\"✓ Curvature signature mean: {np.mean(curvature_sig):.6f}\")\r\n print(f\"✓ Curvature signature std: {np.std(curvature_sig):.6f}\")\r\n print(f\"\\nBest-matching nodes per layer:\")\r\n for layer, match_info in matches.items():\r\n print(f\" {layer}: Node {match_info['node_index']} \"\r\n f\"(error: {match_info['match_error']:.6f})\")\r\n \r\n # ====== PHASE 8: META-COMMUTATOR STATISTICS ======\r\n print(\"\\n[PHASE 8] Meta-Commutator Recursion Analysis\")\r\n print(\"-\" * 80)\r\n \r\n total_generations = 0\r\n total_children = 0\r\n \r\n for layer_idx, mc in enumerate(model.meta_commutators):\r\n num_children = len(mc.child_commutators)\r\n total_children += num_children\r\n max_gen = mc.generation\r\n \r\n if num_children > 0:\r\n max_gen = max([child.generation for child in mc.child_commutators])\r\n \r\n print(f\"Layer {layer_idx}:\")\r\n print(f\" ├─ Current generation: {mc.generation}\")\r\n print(f\" ├─ Child commutators: {num_children}\")\r\n print(f\" ├─ Filter Y magnitude: {torch.norm(mc.filter_y).item():.6f}\")\r\n print(f\" ├─ Filter Z magnitude: {torch.norm(mc.filter_z).item():.6f}\")\r\n print(f\" └─ R matrix rank: {torch.linalg.matrix_rank(mc.R).item()}\")\r\n \r\n print(f\"\\n✓ Total recursive generations: {total_children}\")\r\n \r\n # ====== PHASE 9: POLARITY INTERVAL STATISTICS ======\r\n print(\"\\n[PHASE 9] Polarity Interval Adaptation Statistics\")\r\n print(\"-\" * 80)\r\n \r\n all_widths = []\r\n layer_stats = {}\r\n \r\n for layer in range(4):\r\n widths = []\r\n for cp in range(12):\r\n N_low, N_high = polarity_mgr.intervals[layer][cp]\r\n width = N_high - N_low\r\n widths.append(width)\r\n all_widths.append(width)\r\n \r\n layer_stats[layer] = {\r\n 'mean': np.mean(widths),\r\n 'min': np.min(widths),\r\n 'max': np.max(widths),\r\n 'std': np.std(widths)\r\n }\r\n \r\n print(f\"Overall polarity interval statistics:\")\r\n print(f\" ├─ Mean width: {np.mean(all_widths):.6f}\")\r\n print(f\" ├─ Min width: {np.min(all_widths):.6f}\")\r\n print(f\" ├─ Max width: {np.max(all_widths):.6f}\")\r\n print(f\" └─ Std deviation: {np.std(all_widths):.6f}\")\r\n \r\n print(f\"\\nPer-layer polarity statistics:\")\r\n for layer, stats in layer_stats.items():\r\n print(f\" Layer {layer}: μ={stats['mean']:.4f}, \"\r\n f\"σ={stats['std']:.4f}, \"\r\n f\"range=[{stats['min']:.4f}, {stats['max']:.4f}]\")\r\n \r\n # ====== PHASE 10: TRAINING HISTORY SUMMARY ======\r\n print(\"\\n[PHASE 10] Training History Summary\")\r\n print(\"-\" * 80)\r\n \r\n hist = trainer.training_history\r\n print(f\"Final epoch metrics:\")\r\n print(f\" ├─ Training loss: {hist['loss'][-1]:.6f}\")\r\n print(f\" ├─ Second-pass ratio: {hist['second_pass_ratio'][-1]:.4f}\")\r\n print(f\" ├─ Mean gradient norm: {hist['gradient_norm'][-1]:.6f}\")\r\n print(f\" └─ Total epochs trained: {len(hist['loss'])}\")\r\n \r\n improvement = (hist['loss'][0] - hist['loss'][-1]) / hist['loss'][0] * 100\r\n print(f\"\\n✓ Loss improvement: {improvement:.2f}%\")\r\n \r\n # ====== PHASE 11: EFFICIENCY METRICS ======\r\n print(\"\\n[PHASE 11] Network Efficiency Metrics\")\r\n print(\"-\" * 80)\r\n \r\n # Count total trainable parameters\r\n total_params = sum(p.numel() for p in model.parameters())\r\n print(f\"Network architecture:\")\r\n print(f\" ├─ Total parameters: {total_params:,}\")\r\n print(f\" ├─ Layers: 4\")\r\n print(f\" ├─ Control points per layer: 12\")\r\n print(f\" ├─ Nodes per control point: 2\")\r\n print(f\" └─ Total nodes: {4 * 12 * 2}\")\r\n \r\n # Compute gradient sparsity\r\n with torch.no_grad():\r\n total_grads = 0\r\n active_grads = 0\r\n for p in model.parameters():\r\n if p.grad is not None:\r\n total_grads += p.grad.numel()\r\n active_grads += (p.grad.abs() > 1e-6).sum().item()\r\n \r\n if total_grads > 0:\r\n sparsity = (1 - active_grads / total_grads) * 100\r\n print(f\"\\nGradient sparsity: {sparsity:.2f}%\")\r\n \r\n # ====== PHASE 12: MODEL CHECKPOINTING ======\r\n print(\"\\n[PHASE 12] Model Saving & Checkpointing\")\r\n print(\"-\" * 80)\r\n \r\n # Save model state\r\n torch.save(model.state_dict(), 'bnn_model_state.pt')\r\n print(f\"✓ Model state saved to 'bnn_model_state.pt'\")\r\n \r\n # Save full model\r\n torch.save(model, 'bnn_model_full.pt')\r\n print(f\"✓ Full model saved to 'bnn_model_full.pt'\")\r\n \r\n # Save training metadata\r\n metadata = {\r\n 'num_layers': 4,\r\n 'num_control_points': 12,\r\n 'spline_degree': 3,\r\n 'num_epochs': len(hist['loss']),\r\n 'final_loss': hist['loss'][-1],\r\n 'total_params': total_params,\r\n 'best_val_loss': best_val_loss\r\n }\r\n \r\n import json\r\n with open('bnn_metadata.json', 'w') as f:\r\n json.dump(metadata, f, indent=2)\r\n print(f\"✓ Training metadata saved to 'bnn_metadata.json'\")\r\n \r\n # ====== FINAL SUMMARY ======\r\n print(\"\\n\" + \"█\"*80)\r\n print(\"█\" + \" \"*78 + \"█\")\r\n print(\"█\" + \" PIPELINE EXECUTION COMPLETE \".center(78) + \"█\")\r\n print(\"█\" + \" \"*78 + \"█\")\r\n print(\"█\"*80)\r\n \r\n print(\"\\n📊 Summary Statistics:\")\r\n print(f\" • Training samples processed: 1,200 (25 batches × 8 × 50 epochs)\")\r\n print(f\" • Model convergence: {improvement:.2f}% loss improvement\")\r\n print(f\" • Meta-commutator activations: {sum(test_metrics['second_passes'])}/4 layers\")\r\n print(f\" • Rotational node pairs: {4 * 12 * 2}\")\r\n print(f\" • Adaptive polarity intervals: 48\")\r\n print(f\" • Curvature set segments: {len(curvature_sig)}\")\r\n \r\n print(\"\\n📁 Output Files Generated:\")\r\n print(f\" • bnn_training.png - Training history plots\")\r\n print(f\" • bnn_nodes.png - Node distribution visualizations\")\r\n print(f\" • bnn_3d_curves.png - Predicted vs target curves\")\r\n print(f\" • bnn_model_state.pt - Model weights & parameters\")\r\n print(f\" • bnn_model_full.pt - Complete model checkpoint\")\r\n print(f\" • bnn_metadata.json - Training metadata\")\r\n \r\n return model, trainer, analyzer, polarity_mgr, curvature_matcher\r\n\r\n\r\n# ============================================================================\r\n# ADVANCED: RECURSIVE META-COMMUTATOR DEPTH EXPLORATION\r\n# ============================================================================\r\n\r\ndef analyze_recursive_depth(model: BSplineNN, max_depth: int = 5):\r\n \"\"\"\r\n Analyze the depth of recursive meta-commutator generations\r\n and their impact on network performance\r\n \"\"\"\r\n print(\"\\n\" + \"=\"*80)\r\n print(\"RECURSIVE META-COMMUTATOR DEPTH ANALYSIS\")\r\n print(\"=\"*80)\r\n \r\n depth_analysis = {}\r\n \r\n for layer_idx, mc in enumerate(model.meta_commutators):\r\n print(f\"\\nLayer {layer_idx} Recursion Tree:\")\r\n \r\n def traverse_commutators(commutator, depth=0, parent_idx=0):\r\n \"\"\"Recursively traverse and analyze commutator hierarchy\"\"\"\r\n indent = \" \" * depth\r\n \r\n if depth not in depth_analysis:\r\n depth_analysis[depth] = {\r\n 'count': 0,\r\n 'total_params': 0,\r\n 'avg_generation': 0\r\n }\r\n \r\n # Count parameters\r\n params = sum(p.numel() for p in commutator.parameters())\r\n depth_analysis[depth]['count'] += 1\r\n depth_analysis[depth]['total_params'] += params\r\n depth_analysis[depth]['avg_generation'] += commutator.generation\r\n \r\n print(f\"{indent}├─ Generation {commutator.generation} | \"\r\n f\"Params: {params} | \"\r\n f\"Children: {len(commutator.child_commutators)}\")\r\n \r\n # Traverse children\r\n if len(commutator.child_commutators) > 0 and depth < max_depth:\r\n for child_idx, child in enumerate(commutator.child_commutators):\r\n is_last = (child_idx == len(commutator.child_commutators) - 1)\r\n traverse_commutators(child, depth + 1, child_idx)\r\n \r\n print(f\"{indent}└─ End generation {commutator.generation}\")\r\n \r\n traverse_commutators(mc)\r\n \r\n # Print summary\r\n print(\"\\n\" + \"-\"*80)\r\n print(\"RECURSION DEPTH SUMMARY:\")\r\n print(\"-\"*80)\r\n \r\n total_commutators = 0\r\n total_params_recursive = 0\r\n \r\n for depth in sorted(depth_analysis.keys()):\r\n stats = depth_analysis[depth]\r\n avg_gen = stats['avg_generation'] / max(stats['count'], 1)\r\n \r\n total_commutators += stats['count']\r\n total_params_recursive += stats['total_params']\r\n \r\n print(f\"Depth {depth}: {stats['count']:3d} commutators | \"\r\n f\"Total params: {stats['total_params']:8d} | \"\r\n f\"Avg generation: {avg_gen:.2f}\")\r\n \r\n print(f\"\\nTotal recursive meta-commutators: {total_commutators}\")\r\n print(f\"Total parameters in recursion: {total_params_recursive:,}\")\r\n\r\n\r\n# ============================================================================\r\n# PERFORMANCE BENCHMARKING\r\n# ============================================================================\r\n\r\ndef benchmark_inference_speed(model: BSplineNN, num_batches: int = 10):\r\n \"\"\"Benchmark inference speed and memory usage\"\"\"\r\n import time\r\n \r\n print(\"\\n\" + \"=\"*80)\r\n print(\"INFERENCE PERFORMANCE BENCHMARK\")\r\n print(\"=\"*80)\r\n \r\n model.eval()\r\n \r\n # Prepare test data\r\n dataset = SyntheticBSplineDataset(num_samples=10, \r\n num_control_points=12,\r\n num_curve_points=60)\r\n \r\n times = []\r\n \r\n with torch.no_grad():\r\n for batch_idx in range(num_batches):\r\n control, target = dataset.generate_sample()\r\n control_tensor = torch.tensor(control, dtype=torch.float32).unsqueeze(0)\r\n u = torch.linspace(0, 1, target.shape[0])\r\n \r\n start_time = time.time()\r\n output, metrics = model(u, control_tensor)\r\n elapsed = time.time() - start_time\r\n \r\n times.append(elapsed)\r\n \r\n print(f\"\\nInference over {num_batches} samples:\")\r\n print(f\" • Mean time: {np.mean(times)*1000:.3f} ms\")\r\n print(f\" • Std dev: {np.std(times)*1000:.3f} ms\")\r\n print(f\" • Min time: {np.min(times)*1000:.3f} ms\")\r\n print(f\" • Max time: {np.max(times)*1000:.3f} ms\")\r\n print(f\" • Throughput: {1/np.mean(times):.2f} samples/sec\")\r\n \r\n # Memory estimation\r\n total_params = sum(p.numel() for p in model.parameters())\r\n memory_mb = (total_params * 4) / (1024**2) # 4 bytes per float32\r\n print(f\"\\nMemory usage:\")\r\n print(f\" • Total parameters: {total_params:,}\")\r\n print(f\" • Estimated weights size: {memory_mb:.2f} MB\")\r\n\r\n\r\n# ============================================================================\r\n# MAIN EXECUTION\r\n# ============================================================================\r\n\r\nif __name__ == \"__main__\":\r\n \r\n # Run complete pipeline\r\n model, trainer, analyzer, polarity_mgr, curvature_matcher = (\r\n run_complete_bnn_pipeline()\r\n )\r\n \r\n # Additional analyses\r\n print(\"\\n\")\r\n analyze_recursive_depth(model, max_depth=3)\r\n \r\n print(\"\\n\")\r\n benchmark_inference_speed(model, num_batches=20)\r\n \r\n # Final model inspection\r\n print(\"\\n\" + \"=\"*80)\r\n print(\"FINAL MODEL ARCHITECTURE\")\r\n print(\"=\"*80)\r\n print(model)\r\n \r\n print(\"\\n✅ Complete B-Spline Neural Network pipeline finished successfully!\")\r\n print(\"All outputs saved to current directory.\")\r\n```"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153362",
"id": 6153362,
"node_id": "GC_lADOCotq4doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd5JI",
"user": {
"login": "WayneChou-bot",
"id": 176909025,
"node_id": "U_kgDOCotq4Q",
"avatar_url": "https://avatars.githubusercontent.com/u/176909025?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WayneChou-bot",
"html_url": "https://github.com/WayneChou-bot",
"followers_url": "https://api.github.com/users/WayneChou-bot/followers",
"following_url": "https://api.github.com/users/WayneChou-bot/following{/other_user}",
"gists_url": "https://api.github.com/users/WayneChou-bot/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WayneChou-bot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WayneChou-bot/subscriptions",
"organizations_url": "https://api.github.com/users/WayneChou-bot/orgs",
"repos_url": "https://api.github.com/users/WayneChou-bot/repos",
"events_url": "https://api.github.com/users/WayneChou-bot/events{/privacy}",
"received_events_url": "https://api.github.com/users/WayneChou-bot/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T04:13:33Z",
"updated_at": "2026-05-17T04:13:33Z",
"body": "Thanks @karpathy for sharing this idea — it was a fun pattern to prototype.\r\n\r\nI put together a small Streamlit teaching demo: it follows your raw/wiki/AGENTS.md\r\nthree-layer architecture and the ingest/query/lint operations, but adds a\r\nmulti-perspective twist where four agent roles (Programming / UI Design /\r\nProject Manager / Personal Knowledge) each compile the same source from a\r\ndifferent angle, plus auto cross-references between sibling pages and a\r\nconcepts layer that synthesises across sources.\r\n\r\nRepo: https://github.com/WayneChou-bot/LLM-Wiki-Agent-Workflow-Demo\r\n\r\nThanks again for the inspiration!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153502",
"id": 6153502,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd5R4",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T07:08:58Z",
"updated_at": "2026-05-20T22:22:50Z",
"body": "### obsidian-llm-wiki v0.8.5 is out\r\n- Fixes malformed LaTeX output so Obsidian math renders correctly again.\r\n\r\nhttps://github.com/kytmanov/obsidian-llm-wiki-local - 620+ stars and 10k+ downloads later.\r\n\r\n[Synto](https://github.com/kytmanov/synto) is the successor: same local-first idea, bigger scope. OLW gets bug fixes, Synto gets the future. Easy migration."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153759",
"id": 6153759,
"node_id": "GC_lADOA-ZbJ9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd5h8",
"user": {
"login": "equationalapplications",
"id": 65428263,
"node_id": "MDQ6VXNlcjY1NDI4MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/65428263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/equationalapplications",
"html_url": "https://github.com/equationalapplications",
"followers_url": "https://api.github.com/users/equationalapplications/followers",
"following_url": "https://api.github.com/users/equationalapplications/following{/other_user}",
"gists_url": "https://api.github.com/users/equationalapplications/gists{/gist_id}",
"starred_url": "https://api.github.com/users/equationalapplications/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/equationalapplications/subscriptions",
"organizations_url": "https://api.github.com/users/equationalapplications/orgs",
"repos_url": "https://api.github.com/users/equationalapplications/repos",
"events_url": "https://api.github.com/users/equationalapplications/events{/privacy}",
"received_events_url": "https://api.github.com/users/equationalapplications/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T12:30:26Z",
"updated_at": "2026-05-17T12:30:26Z",
"body": "I think it is great how many open-source implementations of this idea are being developed in parallel, cross-pollinating ideas.\r\nCore LLM Wiki is very flexible. It uses `entityId`, which could be an agent with independent memory, or it could be a tier of memory in system like my Fact, Memory, Wisdom model. The tiers can be configured to act more like Wiki, RAG, Knowledge Graph, or combo.\r\nThat way I can change the architecture around. I might discover a 4 tier memory provides better context, or a 2 tier memory.\r\nhttps://www.npmjs.com/package/@equationalapplications/core-llm-wiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6153974",
"id": 6153974,
"node_id": "GC_lADOA-ZbJ9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd5vY",
"user": {
"login": "equationalapplications",
"id": 65428263,
"node_id": "MDQ6VXNlcjY1NDI4MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/65428263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/equationalapplications",
"html_url": "https://github.com/equationalapplications",
"followers_url": "https://api.github.com/users/equationalapplications/followers",
"following_url": "https://api.github.com/users/equationalapplications/following{/other_user}",
"gists_url": "https://api.github.com/users/equationalapplications/gists{/gist_id}",
"starred_url": "https://api.github.com/users/equationalapplications/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/equationalapplications/subscriptions",
"organizations_url": "https://api.github.com/users/equationalapplications/orgs",
"repos_url": "https://api.github.com/users/equationalapplications/repos",
"events_url": "https://api.github.com/users/equationalapplications/events{/privacy}",
"received_events_url": "https://api.github.com/users/equationalapplications/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T16:51:27Z",
"updated_at": "2026-05-17T16:51:27Z",
"body": "# Prisma Adapter for Core LLM Wiki\r\n\r\nhttps://www.npmjs.com/package/@equationalapplications/prisma-outbox \r\n\r\n* **Synchronizing Edge/Local AI Memory to the Cloud:** If you have a local AI agent (using `@equationalapplications/core-llm-wiki`) writing memories to a local SQLite database, you can use this adapter to reliably replicate those memories up to your central cloud database (like PostgreSQL or MySQL) managed by Prisma.\r\n* **Reliable, Lossless Data Replication:** Because it uses the transactional outbox pattern, it ensures that every change the LLM makes locally is eventually synced to the main database. If the network goes down or the main database is temporarily unavailable, the events wait safely in the local SQLite outbox until they can be successfully processed and acknowledged.\r\n* **Triggering Downstream Application Side Effects:** When the LLM updates a specific record locally (e.g., learning a new user preference), you can use the `mapEvent` function to trigger broader changes in your main Prisma database, such as updating a user's main profile, sending a notification, or adjusting application settings based on what the LLM learned.\r\n* **Offline-First Architectures:** It allows the primary application (and the LLM) to interact with a fast, local SQLite database without waiting for network calls. The adapter handles the slow, asynchronous work of syncing that data to the main backend in the background."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6154059",
"id": 6154059,
"node_id": "GC_lADOBJYWy9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd50s",
"user": {
"login": "alxraun",
"id": 76945099,
"node_id": "MDQ6VXNlcjc2OTQ1MDk5",
"avatar_url": "https://avatars.githubusercontent.com/u/76945099?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alxraun",
"html_url": "https://github.com/alxraun",
"followers_url": "https://api.github.com/users/alxraun/followers",
"following_url": "https://api.github.com/users/alxraun/following{/other_user}",
"gists_url": "https://api.github.com/users/alxraun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alxraun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alxraun/subscriptions",
"organizations_url": "https://api.github.com/users/alxraun/orgs",
"repos_url": "https://api.github.com/users/alxraun/repos",
"events_url": "https://api.github.com/users/alxraun/events{/privacy}",
"received_events_url": "https://api.github.com/users/alxraun/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T18:21:32Z",
"updated_at": "2026-05-17T18:21:32Z",
"body": "What about storing wiki pages in this format? Compressed the original from 2500 tokens down to 1000. Try feeding it to an LLM like this:\r\n\r\n```markdown\r\n# LLM_WIKI_PATTERN\r\n* source: `https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f#file-llm-wiki-md` \r\n\r\n## PARADIGM_SHIFT\r\n* standard_rag\r\n * flow: query -> search(raw_docs) -> transient_synthesis\r\n * attributes: stateless\r\n * result: knowledge_accumulation == 0\r\n* **llm_wiki**\r\n * flow: ingest(raw_docs) -> update(persistent_graph) -> query() -> compound_growth\r\n * attributes: stateful\r\n * result: knowledge_accumulation -> max\r\n* **llm_wiki** != standard_rag\r\n```\r\n---\r\n]\r\n🎈 Show full
\r\n\r\n```markdown\r\n# LLM_WIKI_PATTERN\r\n* source: `https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f#file-llm-wiki-md` \r\n\r\n## PARADIGM_SHIFT\r\n* standard_rag\r\n * flow: query -> search(raw_docs) -> transient_synthesis\r\n * attributes: stateless\r\n * result: knowledge_accumulation == 0\r\n* **llm_wiki**\r\n * flow: ingest(raw_docs) -> update(persistent_graph) -> query() -> compound_growth\r\n * attributes: stateful\r\n * result: knowledge_accumulation -> max\r\n* **llm_wiki** != standard_rag\r\n\r\n## ROLE_ALLOCATION\r\n* human_user\r\n * responsibilities: {sourcing, exploration, inquiry, direction_setting}\r\n* llm_agent\r\n * instances: {openai_codex, claude_code, open_code, pi}\r\n * responsibilities: {summarizing, cross_referencing, bookkeeping, updating, formatting}\r\n * attributes: {tireless, maintenance_cost == 0}\r\n* system_analogy: {obsidian == ide, llm_agent == programmer, **llm_wiki** == codebase}\r\n\r\n## ARCHITECTURE\r\n* system_layers == raw_sources + wiki_core + schema\r\n* raw_sources\r\n * format: {articles, papers, images, data_files}\r\n * attributes: {immutable, source_of_truth}\r\n * permissions: human_user -> write, llm_agent -> read_only\r\n* wiki_core\r\n * format: markdown_directory\r\n * content: {summaries, entity_pages, concept_pages, comparisons, syntheses}\r\n * attributes: {mutable, compounding, interlinked}\r\n * permissions: llm_agent -> write_owner, human_user -> read_explorer\r\n* schema\r\n * instances: {`CLAUDE.md`, `AGENTS.md`}\r\n * role: llm_behavior_definition\r\n * content: {structure_rules, conventions, workflows}\r\n * transformation: llm_chatbot + schema => disciplined_wiki_maintainer\r\n\r\n## OPERATIONS\r\n* ingest(new_source)\r\n * trigger: human_user -> add(raw_sources)\r\n * flow: read(new_source) -> discuss() -> write(summary) -> update(`index.md`) -> update(entities_concepts) -> append(`log.md`)\r\n * scope: 1_source => modifies(10...15_pages)\r\n* query(question)\r\n * flow: question -> read(`index.md`) -> read(relevant_pages) -> synthesize(answer, citations)\r\n * output_formats: {markdown_page, comparison_table, marp_deck, matplotlib_chart, canvas}\r\n * core_heuristic: valuable_answer -> file_back(wiki_core) => compound_growth\r\n* lint()\r\n * frequency: periodic\r\n * targets: {contradictions, stale_claims, orphan_pages, missing_links, missing_concepts, data_gaps}\r\n * actions: fix(targets) + suggest(new_questions, new_sources)\r\n * result: wiki_health -> max\r\n\r\n## NAVIGATION_STATE\r\n* `index.md`\r\n * nature: content_catalog\r\n * structure: list[link, 1_line_summary, metadata]\r\n * organization: category_based\r\n * utility: rag_infrastructure_replacement @ scale < 1000_sources\r\n * trigger: update() @ ingest()\r\n* `log.md`\r\n * nature: chronological_ledger\r\n * attributes: append_only\r\n * syntax_rule: `## [YYYY-MM-DD] action | title`\r\n * utility: unix_parsing_compatibility + temporal_context_awareness\r\n\r\n## TOOLING_ECOSYSTEM\r\n* search_engine: {`qmd` | custom_script}\r\n * features: {bm25, vector_search, llm_reranking}\r\n * interfaces: {cli, mcp_server}\r\n* obsidian_web_clipper -> html_to_markdown_ingestion\r\n* local_assets: download_images -> local_path => link_rot_prevention\r\n* llm_vision_constraint: inline_images -> read_text_first -> view_images_separately\r\n* obsidian_graph_view -> visualize(topology, hubs, orphans)\r\n* marp -> markdown_to_slides_transformation\r\n* dataview -> query(yaml_frontmatter) => dynamic_tables\r\n* git -> {version_control, history, branching, collaboration}\r\n\r\n## USE_CASES\r\n* domains: {personal_tracking, research, book_companion, team_knowledge_base, deep_dives}\r\n* book_companion_scale: human_user + llm_agent ~ community_effort @ tolkien_gateway\r\n\r\n## TELEOLOGY\r\n* failure_mode(human_wiki): maintenance_burden > value => abandonment\r\n* success_mode(**llm_wiki**): llm_agent -> bookkeeping => maintenance_burden == 0 => persistence\r\n* lineage: **llm_wiki** ~ vannevar_bush_memex_1945\r\n * shared_traits: [private, actively_curated, associative_trails]\r\n * solved_problem: memex_maintenance == llm_agent\r\n* modularity: implementation_details -> adaptable(domain, preferences, llm_choice)\r\n```\r\n "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6154245",
"id": 6154245,
"node_id": "GC_lADOA72CQtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd6AU",
"user": {
"login": "eslamgenio",
"id": 62751298,
"node_id": "MDQ6VXNlcjYyNzUxMjk4",
"avatar_url": "https://avatars.githubusercontent.com/u/62751298?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eslamgenio",
"html_url": "https://github.com/eslamgenio",
"followers_url": "https://api.github.com/users/eslamgenio/followers",
"following_url": "https://api.github.com/users/eslamgenio/following{/other_user}",
"gists_url": "https://api.github.com/users/eslamgenio/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eslamgenio/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eslamgenio/subscriptions",
"organizations_url": "https://api.github.com/users/eslamgenio/orgs",
"repos_url": "https://api.github.com/users/eslamgenio/repos",
"events_url": "https://api.github.com/users/eslamgenio/events{/privacy}",
"received_events_url": "https://api.github.com/users/eslamgenio/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-17T22:12:39Z",
"updated_at": "2026-05-17T22:13:21Z",
"body": "AI Agents forget. Every session, they start from zero!\r\n\r\n\r\nAndrej Karpathy keeps making the point that agents need durable memory beyond the context window. \r\n\r\n\r\nI kept turning that over, then looked at my Obsidian vault and asked: what if this was the memory?!\r\n\r\n\r\nSo I built it with the help of Hermes Agent: \"long-term-agent-memory\"\r\n\r\n\r\nA filesystem-first system for storing sessions, decisions, procedures, and linked knowledge that agents can keep forever!\r\n\r\n\r\nIf you're working on agent workflows or long-horizon AI, I'd love your thoughts.\r\n\r\n\r\nInspired by Andrej Karpathy's LLM Wiki: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f\r\n\r\n\r\nlong-term-agent-memory Repo:\r\n\r\n🔗 https://github.com/eslamgenio/long-term-agent-memory"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6154382",
"id": 6154382,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd6I4",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-18T02:22:55Z",
"updated_at": "2026-05-18T02:22:55Z",
"body": " ΩmegaWiki(680+⭐) just shipped v1.4.0 — the research loop is now end-to-end.\r\n Repo: https://github.com/skyllwt/OmegaWiki\r\n\r\n • 26 Claude Code skills, covering the full paper lifecycle:\r\n discover → ingest → graph → ideate → experiment → draft → poster → rebuttal\r\n • 8 typed entities · 20 typed edges\r\n • Bilingual (EN + 中文), every skill ships in both languages\r\n • 4 new skills shipped this month\r\n\r\n\r\n\r\n v1.4.0 highlight: /poster\r\n \r\n Paper accepted? Run one command, get a 1400×900 conference poster +\r\n print-quality PNG. Reads your LaTeX source, auto-rasterizes TikZ figures,\r\n renders booktabs tables as live HTML, preserves math via KaTeX, walks you\r\n through figure picks and header config. PDF export from any browser. Section\r\n distillation is grounded in your wiki's paper-plan, ideas, experiments — not a\r\n blind LLM summary of the abstract.\r\n\r\n \r\n\r\n Try ΩmegaWiki in Claude Code and run the full LLM-Wiki loop:\r\n\r\n /discover --venue iclr --year 2026 → ranked reading list\r\n /ingest → typed entry, linked into the graph\r\n /ideate + /novelty → ideas with bibliographic grounding\r\n /exp-design → /exp-run → /exp-eval → pilot-first experiment workflow\r\n /paper-plan → /paper-draft → /paper-compile\r\n /poster → conference poster (NEW)\r\n /rebuttal → reviewer response\r\n\r\n End to end. One wiki. No chunks.\r\n \r\n If ΩmegaWiki looks interesting, a ⭐ would encourage and motivate us a lot 😀\r\n https://github.com/skyllwt/OmegaWiki\r\n\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6155060",
"id": 6155060,
"node_id": "GC_lADOAWQcHdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd6zQ",
"user": {
"login": "Sistema2D",
"id": 23338013,
"node_id": "MDQ6VXNlcjIzMzM4MDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/23338013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sistema2D",
"html_url": "https://github.com/Sistema2D",
"followers_url": "https://api.github.com/users/Sistema2D/followers",
"following_url": "https://api.github.com/users/Sistema2D/following{/other_user}",
"gists_url": "https://api.github.com/users/Sistema2D/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sistema2D/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sistema2D/subscriptions",
"organizations_url": "https://api.github.com/users/Sistema2D/orgs",
"repos_url": "https://api.github.com/users/Sistema2D/repos",
"events_url": "https://api.github.com/users/Sistema2D/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sistema2D/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-18T11:14:23Z",
"updated_at": "2026-05-18T11:14:23Z",
"body": "> I've built FrameCode VibeWork, a documentation and governance framework based on this LLM Wiki concept to reduce context loss during AI-assisted development. It organizes plans, changelogs, and an incremental technical memory. Check it out here: https://github.com/Sistema2D/FrameCode-VibeWork\r\n\r\nNow avaiable in EN-US! (P.S.: Im not a bot)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6155166",
"id": 6155166,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd654",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-18T12:01:36Z",
"updated_at": "2026-05-18T12:01:36Z",
"body": "
\r\n\r\n Try ΩmegaWiki in Claude Code and run the full LLM-Wiki loop:\r\n\r\n /discover --venue iclr --year 2026 → ranked reading list\r\n /ingest → typed entry, linked into the graph\r\n /ideate + /novelty → ideas with bibliographic grounding\r\n /exp-design → /exp-run → /exp-eval → pilot-first experiment workflow\r\n /paper-plan → /paper-draft → /paper-compile\r\n /poster → conference poster (NEW)\r\n /rebuttal → reviewer response\r\n\r\n End to end. One wiki. No chunks.\r\n \r\n If ΩmegaWiki looks interesting, a ⭐ would encourage and motivate us a lot 😀\r\n https://github.com/skyllwt/OmegaWiki\r\n\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6155060",
"id": 6155060,
"node_id": "GC_lADOAWQcHdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd6zQ",
"user": {
"login": "Sistema2D",
"id": 23338013,
"node_id": "MDQ6VXNlcjIzMzM4MDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/23338013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sistema2D",
"html_url": "https://github.com/Sistema2D",
"followers_url": "https://api.github.com/users/Sistema2D/followers",
"following_url": "https://api.github.com/users/Sistema2D/following{/other_user}",
"gists_url": "https://api.github.com/users/Sistema2D/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sistema2D/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sistema2D/subscriptions",
"organizations_url": "https://api.github.com/users/Sistema2D/orgs",
"repos_url": "https://api.github.com/users/Sistema2D/repos",
"events_url": "https://api.github.com/users/Sistema2D/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sistema2D/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-18T11:14:23Z",
"updated_at": "2026-05-18T11:14:23Z",
"body": "> I've built FrameCode VibeWork, a documentation and governance framework based on this LLM Wiki concept to reduce context loss during AI-assisted development. It organizes plans, changelogs, and an incremental technical memory. Check it out here: https://github.com/Sistema2D/FrameCode-VibeWork\r\n\r\nNow avaiable in EN-US! (P.S.: Im not a bot)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6155166",
"id": 6155166,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd654",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-18T12:01:36Z",
"updated_at": "2026-05-18T12:01:36Z",
"body": "\r\n
\r\n ███████╗ ██████╗ ███████╗\r\n ██╔════╝██╔═══██╗╚══███╔╝\r\n ███████╗██║ ██║ ███╔╝\r\n ╚════██║██║▄▄ ██║ ███╔╝\r\n ███████║╚██████╔╝███████╗\r\n ╚══════╝ ╚══▀▀═╝ ╚══════╝\r\n
\r\n\r\n\r\n\r\n Compress LLM context to save tokens and reduce costs\r\n
\r\n\r\n\r\n \r\n Real session stats:\r\n 3,003 compressions ·\r\n 178,442 tokens saved ·\r\n 24.7% avg reduction · up to\r\n 92% with dedup\r\n \r\n
\r\n\r\n\r\n \r\n
\r\n\r\n\r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n
\r\n\r\n\r\n Install ·\r\n How It Works ·\r\n Supported Tools ·\r\n Changelog ·\r\n Discord\r\n
\r\n\r\n---\r\n\r\nsqz compresses command output before it reaches your LLM. Single Rust binary, zero config.\r\n\r\nThe real win is dedup: when the same file gets read 5 times in a session, sqz sends it once and returns a 13-token reference for every repeat.\r\n\r\n```\r\nWithout sqz: With sqz:\r\n\r\nFile read #1: 2,000 tokens File read #1: ~800 tokens (compressed)\r\nFile read #2: 2,000 tokens File read #2: ~13 tokens (dedup ref)\r\nFile read #3: 2,000 tokens File read #3: ~13 tokens (dedup ref)\r\n─────────────────────── ───────────────────────\r\nTotal: 6,000 tokens Total: ~826 tokens (86% saved)\r\n```\r\n\r\n## Token Savings\r\n\r\n> **24.7%** average reduction across 3,003 real compressions ·\r\n> **92%** saved on repeated file reads ·\r\n> **86%** on shell/git output ·\r\n> **13-token** refs for cached content\r\n\r\nOne developer's week, measured from actual `sqz gain` output:\r\n\r\n```\r\n$ sqz gain\r\nsqz token savings (last 7 days)\r\n──────────────────────────────────────────────────\r\n 04-13 │ │ 2,329 saved\r\n 04-14 │ │ 0 saved\r\n 04-15 │███ │ 12,954 saved\r\n 04-16 │██ │ 9,223 saved\r\n 04-17 │████ │ 14,752 saved\r\n 04-18 │██████████████████████████████│ 105,569 saved\r\n 04-19 │████████ │ 30,882 saved\r\n 04-20 │█ │ 4,334 saved\r\n──────────────────────────────────────────────────\r\n Total: 3,003 compressions, 178,442 tokens saved (24.7% avg reduction)\r\n```\r\n\r\n### Per-command compression\r\n\r\nSingle-command compression (measured via `cargo test -p sqz-engine benchmarks`):\r\n\r\n| Content | Before | After | Saved |\r\n|---|---:|---:|---:|\r\n| Repeated log lines | 148 | 62 | **58%** |\r\n| Large JSON array | 259 | 142 | **45%** |\r\n| JSON API response | 64 | 53 | **17%** |\r\n| Git diff | 61 | 54 | **12%** |\r\n| Prose/docs | 124 | 121 | **2%** |\r\n| Stack trace (safe mode) | 82 | 82 | **0%** |\r\n\r\n### Session-level with dedup\r\n\r\nWhere the real savings live — the cache sends each file once, repeats cost 13 tokens:\r\n\r\n| Scenario | Without sqz | With sqz | Saved |\r\n|---|---:|---:|---:|\r\n| Same file read 5× | 10,000 | 826 | **92%** |\r\n| Same JSON response 3× | 192 | 79 | **59%** |\r\n| Test-fix-test cycle (3 runs) | 15,000 | 5,186 | **65%** |\r\n\r\nSingle-command compression ranges from 2–58% depending on content. Repeated reads drop to 13 tokens each. Your mileage will vary with how repetitive your tool calls are — agentic sessions with many file re-reads see the biggest wins.\r\n\r\n## Install\r\n\r\n**Prebuilt binaries** (no compiler required — works on every platform):\r\n\r\n```sh\r\n# macOS / Linux\r\ncurl -fsSL https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.sh | sh\r\n\r\n# Windows (PowerShell)\r\nirm https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.ps1 | iex\r\n\r\n# Any platform via npm\r\nnpm install -g sqz-cli\r\n\r\n# macOS / Linux via Homebrew\r\nbrew tap ojuschugh1/sqz\r\nbrew install sqz\r\n```\r\n\r\n**Build from source via Cargo:**\r\n\r\n```sh\r\ncargo install sqz-cli sqz-mcp\r\n```\r\n\r\n`sqz-cli` provides the `sqz` binary; `sqz-mcp` provides the MCP server. `sqz-engine` is a library dependency — it compiles automatically and does not need to be installed separately.\r\n\r\n**Build from source** (`cargo install sqz-cli`) works too, but needs a C toolchain:\r\n\r\n- Linux: `build-essential` (apt) or equivalent\r\n- macOS: Xcode Command Line Tools (`xcode-select --install`)\r\n- **Windows: Visual Studio Build Tools with the \"Desktop development with C++\" workload.** Without these, `cargo install` fails with `linker link.exe not found`. If you don't already have them, use the PowerShell or npm install above instead.\r\n\r\nThen initialize:\r\n\r\n```sh\r\nsqz init --global # hooks apply to every project on this machine\r\n# or\r\nsqz init # hooks apply to just this project (.claude/settings.local.json)\r\n```\r\n\r\n`--global` writes to `~/.claude/settings.json` (the user scope per the\r\n[Anthropic scope table](https://docs.claude.com/en/docs/claude-code/settings)),\r\nso the sqz hook fires in every Claude Code session on this machine. This is\r\nthe common case on first install. Your existing `permissions`, `env`,\r\n`statusLine`, and unrelated hooks in `~/.claude/settings.json` are\r\npreserved — sqz merges its entries rather than overwriting.\r\n\r\nPlain `sqz init` (project scope) is useful when you want sqz active only\r\ninside one repo.\r\n\r\n**Only using one agent?** Pass `--only` (or `--skip`) to limit which\r\nconfigs are written:\r\n\r\n```sh\r\nsqz init --only opencode # just OpenCode, nothing else\r\nsqz init --only opencode,codex # OpenCode and Codex\r\nsqz init --skip cursor,windsurf # everything except Cursor and Windsurf\r\n```\r\n\r\nAccepted names: `claude`, `cursor`, `windsurf`, `cline`, `gemini`,\r\n`kiro`, `opencode`, `codex`. Aliases (`claude-code`, `gemini-cli`, `roo`,\r\n`kiro-cli`) also work. `--only` and `--skip` can't be combined.\r\n\r\n### Manual installation (preserve comments in your config)\r\n\r\n`sqz init` round-trips your config file through a JSON parser to merge\r\nthe sqz entry, which drops any comments in your `opencode.jsonc` (and\r\nthe analogous JSON-with-comments files other tools accept). If you've\r\ncommented your config carefully and want to keep them, install by hand\r\ninstead.\r\n\r\n**OpenCode** — two steps:\r\n\r\n1. Drop the plugin file in place. `sqz` prints the generated TS to\r\n stdout so you don't have to hand-write the path-escaping logic:\r\n\r\n ```sh\r\n mkdir -p ~/.config/opencode/plugins\r\n sqz print-opencode-plugin > ~/.config/opencode/plugins/sqz.ts\r\n ```\r\n\r\n2. Add the MCP entry to your existing `opencode.jsonc` yourself.\r\n Append this block inside the top-level `mcp` object (create the\r\n `mcp` object if it doesn't exist):\r\n\r\n ```jsonc\r\n \"sqz\": {\r\n \"type\": \"local\",\r\n \"command\": [\"sqz-mcp\", \"--transport\", \"stdio\"],\r\n \"enabled\": true\r\n }\r\n ```\r\n\r\nComments in the rest of your file stay put. OpenCode auto-discovers\r\nthe plugin file; no `plugin` array entry needed (adding one causes\r\ndouble-loading, see issue #10).\r\n\r\n**Other tools** — Claude Code, Cursor, Windsurf, Cline, Gemini CLI,\r\nand Codex use plain JSON configs without comment support, so the\r\nautomated path is non-destructive there. Use `sqz init --only `\r\nfor those.\r\n\r\nThat's it. Shell hooks installed, AI tool hooks configured.\r\n\r\n## How It Works\r\n\r\n\r\n \r\n
\r\n\r\nsqz installs a PreToolUse hook that intercepts bash commands before your AI tool runs them. The output gets compressed transparently — the AI tool never knows.\r\n\r\n```\r\nClaude → git status → [sqz hook rewrites] → compressed output (85% smaller)\r\n```\r\n\r\nWhat gets compressed:\r\n- **Shell output** — git, cargo, npm, docker, kubectl, ls, grep, etc.\r\n- **JSON** — strips nulls, compact encoding\r\n- **Logs** — collapses repeated lines\r\n- **Test output** — shows failures only\r\n\r\nWhat doesn't get compressed:\r\n- Stack traces, error messages, secrets — routed to safe mode (0% compression)\r\n- Your prompts and the AI's responses — controlled by the AI tool, not sqz\r\n\r\n## Supported Tools\r\n\r\n| Tool | Integration | Setup |\r\n|---|---|---|\r\n| Claude Code | PreToolUse hook (transparent) | `sqz init` |\r\n| Cursor | PreToolUse hook (transparent) | `sqz init` |\r\n| Windsurf | PreToolUse hook (transparent) | `sqz init` |\r\n| Cline | PreToolUse hook (transparent) | `sqz init` |\r\n| Gemini CLI | BeforeTool hook (transparent) | `sqz init` |\r\n| Kiro | PreToolUse hook (transparent) | `sqz init` |\r\n| OpenCode | TypeScript plugin (transparent) | `sqz init` |\r\n| VS Code | [Extension](https://marketplace.visualstudio.com/items?itemName=ojuschugh1.sqz) | Install from Marketplace |\r\n| JetBrains | [Plugin](https://plugins.jetbrains.com/plugin/31240-sqz--context-intelligence/) | Install from Marketplace |\r\n| Chrome | Browser extension | ChatGPT, Claude.ai, Gemini, Grok, Perplexity |\r\n| [Firefox](https://addons.mozilla.org/en-US/firefox/addon/sqz-context-compression/) | Browser extension | Same sites |\r\n\r\n## CLI\r\n\r\n```sh\r\nsqz init --global # Install hooks for every project on this machine\r\nsqz init # Install hooks for just this project\r\nsqz init --only kiro # Only configure Kiro (skip the rest)\r\nsqz init --only opencode # Only configure OpenCode (skip the rest)\r\nsqz init --skip cursor # Configure every agent except Cursor\r\nsqz compress # Compress (or pipe from stdin)\r\nsqz compress --no-cache # Compress without dedup (always full output)\r\nsqz expand [ # Recover original content from a §ref:HASH§ token\r\nsqz compact # Evict stale context to free tokens\r\nsqz gain # Show daily token savings (bar chart)\r\nsqz gain --project . # Per-project daily gains\r\nsqz gain --days 30 # Last 30 days\r\nsqz stats # Cumulative compression report\r\nsqz stats --breakdown # Per-command token usage breakdown\r\nsqz stats --project . # Stats for current project only\r\nsqz stats --project list # List all tracked projects\r\nsqz discover # Find missed savings\r\nsqz resume # Re-inject session context after compaction\r\nsqz vizit # Live terminal dashboard (like htop for AI agents)\r\nsqz hook claude # Process a PreToolUse hook (Claude Code)\r\nsqz hook kiro # Process a PreToolUse hook (Kiro)\r\nsqz print-opencode-plugin # Print OpenCode plugin TS for manual install\r\nsqz proxy --port 8080 # API proxy (compresses full request payloads)\r\n```\r\n\r\n### Dedup Escape Hatch\r\n\r\nWhen sqz sees the same content twice, it returns a compact `§ref:HASH§` token\r\ninstead of the full text. Most models handle this fine, but some (e.g., GLM 5.1)\r\ncan't parse the ref format and loop. Four ways to work around this:\r\n\r\n```sh\r\n# 1. Recover original content from a ref\r\nsqz expand a1b2c3d4 # prefix match\r\nsqz expand '§ref:a1b2c3d4§' # paste the whole token\r\n\r\n# 2. Compress without dedup (per-invocation)\r\necho \"...\" | sqz compress --no-cache\r\n\r\n# 3. Disable dedup globally (env var)\r\nexport SQZ_NO_DEDUP=1\r\n\r\n# 4. MCP passthrough tool (returns input byte-exact, zero transforms)\r\n# Available via tools/list when sqz-mcp is running\r\n```\r\n\r\n## Track Your Own Savings\r\n\r\nRun `sqz gain` in your shell any time to see your own daily breakdown (see the\r\nToken Savings section above for what the output looks like), and `sqz stats`\r\nfor the full cumulative report:\r\n\r\n```sh\r\n$ sqz stats\r\n 📊 sqz compression stats\r\n ──────────────────────────────────────────────────\r\n\r\n 178,442 tokens saved\r\n ↓ 24.7% average reduction\r\n\r\n Compressions 3,003\r\n Tokens in 721,840\r\n Tokens out 543,398\r\n Tokens saved 178,442\r\n Avg reduction 24.7%\r\n\r\n 🗄️ Cache\r\n ──────────────────────────────────────────────────\r\n Entries 43\r\n Size 39.1 KB\r\n```\r\n\r\nAdd `--breakdown` to see exactly which commands consume the most tokens:\r\n\r\n```sh\r\n$ sqz stats --breakdown\r\n\r\n 🔍 Top Token Consumers\r\n ──────────────────────────────────────────────────────────────────────\r\n command calls tokens in out saved\r\n ──────────────────────────────────────────────────────────────────────\r\n dedup 249 45541 3237 93%\r\n stdin 51 30851 24289 21%\r\n auto 132 18288 7740 58%\r\n echo 17 1050 558 47%\r\n ls -la 8 948 948 0%\r\n cargo build 7 170 145 15%\r\n git status 4 56 8 86%\r\n ──────────────────────────────────────────────────────────────────────\r\n```\r\n\r\n**Per-project filtering:**\r\n\r\n```sh\r\nsqz stats --project . # stats for current project only\r\nsqz stats --project list # list all tracked projects\r\nsqz gain --project . # daily gains for current project\r\nsqz gain --days 30 # last 30 days instead of 7\r\nsqz gain --days 30 --project . # combine both\r\n```\r\n\r\nStats are stored locally in SQLite under `~/.sqz/sessions.db` — nothing leaves your machine.\r\n\r\n## How Compression Works\r\n\r\n1. **Per-command formatters** — `git status` → compact summary, `cargo test` → failures only, `docker ps` → name/image/status table\r\n2. **Structural summaries** — code files compressed to imports + function signatures + call graph (~70% reduction). The model sees the architecture, not implementation noise.\r\n3. **Dedup cache** — SHA-256 content hash, persistent across sessions. Second read = 13-token reference.\r\n4. **JSON pipeline** — strip nulls → project out debug fields → flatten → collapse arrays → TOON encoding (lossless compact format)\r\n5. **Safe mode** — stack traces, secrets, migrations detected by entropy analysis and routed through with 0% compression\r\n\r\nFor the full technical details, see [docs/](docs/).\r\n\r\n## Configuration\r\n\r\n```toml\r\n# ~/.sqz/presets/default.toml\r\n[preset]\r\nname = \"default\"\r\nversion = \"1.0\"\r\n\r\n[compression.condense]\r\nenabled = true\r\nmax_repeated_lines = 3\r\n\r\n[compression.strip_nulls]\r\nenabled = true\r\n\r\n[budget]\r\nwarning_threshold = 0.70\r\ndefault_window_size = 200000\r\n```\r\n\r\n## Privacy\r\n\r\n- Zero telemetry — no data transmitted, no crash reports\r\n- Fully offline — works in air-gapped environments\r\n- All processing local\r\n\r\n## Development\r\n\r\n```sh\r\ngit clone https://github.com/ojuschugh1/sqz.git\r\ncd sqz\r\ncargo test --workspace\r\ncargo build --release\r\n```\r\n\r\n## License\r\n\r\n[Elastic License 2.0](LICENSE) (ELv2) — use, fork, modify freely. Two restrictions: no competing hosted service, no removing license notices.\r\n\r\n## Links\r\n\r\n- [White Paper: Pre-Injection Context Compression](docs/whitepaper.md)\r\n- [Benchmark: sqz vs rtk](docs/benchmark-vs-rtk.md)\r\n- [Discord](https://discord.gg/j8EEyH5dSB)\r\n- [Changelog](CHANGELOG.md)\r\n\r\n## Star History\r\n\r\n\r\n \r\n \r\n \r\n \r\n \r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6156502",
"id": 6156502,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd8NY",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-19T07:56:16Z",
"updated_at": "2026-05-19T07:56:16Z",
"body": "### Synto v0.2.0 is out. \r\nhttps://github.com/kytmanov/synto\r\n\r\n**Main addition: `synto add` for PDFs, Markdown, and text files.**\r\n\r\nThat means you can drop a paper or doc into Synto, turn it into clean Obsidian-compatible Markdown, and run the full pipeline on it:\r\ningest -> compile -> query -> synthesize.\r\n\r\nIt stays local-first and private:\r\n- **works with local LLMs**\r\n- great with Ollama and LM Studio\r\n- plain Markdown\r\n- Obsidian-friendly\r\n- no vector DB\r\n- no cloud required\r\n\r\nAlso includes a lot of hardening from real E2E testing: better PDF import, duplicate detection, source-type prompts, semantic cache, lineage, and smoke fixes.\r\n\r\nStar it if you want to support local-first AI tools. Fork it if you want to build on it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6157090",
"id": 6157090,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd8yI",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-19T13:42:13Z",
"updated_at": "2026-05-19T13:42:13Z",
"body": "The Synthadoc demo is available on YouTube.\r\nhttps://youtu.be/rIGO6zi9XQE\r\n\r\nSynthadoc is an open-source AI knowledge engine that converts scattered documents into reliable domain intelligence.\r\n\r\n⭐ Star the project if you find it useful! \r\nGitHub: https://github.com/axoviq-ai/synthadoc"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6157111",
"id": 6157111,
"node_id": "GC_lADOAWOMgtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd8zc",
"user": {
"login": "gschleder",
"id": 23301250,
"node_id": "MDQ6VXNlcjIzMzAxMjUw",
"avatar_url": "https://avatars.githubusercontent.com/u/23301250?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gschleder",
"html_url": "https://github.com/gschleder",
"followers_url": "https://api.github.com/users/gschleder/followers",
"following_url": "https://api.github.com/users/gschleder/following{/other_user}",
"gists_url": "https://api.github.com/users/gschleder/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gschleder/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gschleder/subscriptions",
"organizations_url": "https://api.github.com/users/gschleder/orgs",
"repos_url": "https://api.github.com/users/gschleder/repos",
"events_url": "https://api.github.com/users/gschleder/events{/privacy}",
"received_events_url": "https://api.github.com/users/gschleder/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-19T13:54:45Z",
"updated_at": "2026-05-19T13:54:45Z",
"body": "## SciAI Wiki - Scientific Artificial Intelligence Wikis ([arXiv manuscript](https://github.com/cnpem/sci-ai-wiki/blob/main/docs/arxiv_manuscript_SciAIwiki.pdf))\r\n\r\n#### Maybe the first manuscript discussing using LLM wiki ideas specifically for science (including content and repositories from this gist thread)\r\n\r\n[The arXiv-submitted manuscript (May 18th) is here](https://github.com/cnpem/sci-ai-wiki/blob/main/docs/arxiv_manuscript_SciAIwiki.pdf) and the repository is just a minimal representative example of it, advanced users can (and possibly, should!) move towards more feature-ready implementations such as those in this thread.\r\n\r\nSciAI Wiki is a framework for building persistent scientific memory with Large Language Models, building on Karpathy's LLM Wiki discussions. Instead of treating papers, notes, and research questions as isolated chat sessions, it organises scientific context into human-readable markdown pages (as a wiki) that preserve provenance, relationships, and accumulated reasoning over time.\r\n\r\nThe repository acts as a structured knowledge substrate for AI-assisted research. Agents can ingest sources, link concepts, answer questions from the accumulated context, audit the knowledge graph, and generate literature syntheses, while researchers remain in control of interpretation, validation, and research direction."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6157839",
"id": 6157839,
"node_id": "GC_lADOAO_nE9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd9g8",
"user": {
"login": "gowtham0992",
"id": 15722259,
"node_id": "MDQ6VXNlcjE1NzIyMjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/15722259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gowtham0992",
"html_url": "https://github.com/gowtham0992",
"followers_url": "https://api.github.com/users/gowtham0992/followers",
"following_url": "https://api.github.com/users/gowtham0992/following{/other_user}",
"gists_url": "https://api.github.com/users/gowtham0992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gowtham0992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gowtham0992/subscriptions",
"organizations_url": "https://api.github.com/users/gowtham0992/orgs",
"repos_url": "https://api.github.com/users/gowtham0992/repos",
"events_url": "https://api.github.com/users/gowtham0992/events{/privacy}",
"received_events_url": "https://api.github.com/users/gowtham0992/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T00:06:31Z",
"updated_at": "2026-05-20T00:06:31Z",
"body": "## Link v1.2.0 is live\r\n\r\nLocal, source-backed memory for LLM agents.\r\n\r\nLink stores agent memory as plain Markdown on your machine. Raw sources become a source-backed wiki. Explicit “remember this” requests become reviewable agent memory. MCP tools let Codex, Claude, Cursor, Kiro, VS Code, Copilot, and other clients query that memory without dumping the whole wiki into context.\r\n\r\n] \r\n\r\nInstall:\r\n\r\n```bash\r\nbrew install gowtham0992/link/link\r\nlink demo\r\nlink serve link-demo\r\n```\r\n\r\nMCP package:\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nWhat changed in v1.2.0:\r\n\r\n- Homebrew install path.\r\n- PyPI and MCP Registry updated to 1.2.0.\r\n- GitHub Pages product docs.\r\n- Cleaner README and architecture explanation.\r\n- UI, CLI, and MCP walkthrough visuals.\r\n- Local /health page for readiness, validation, interrupted writes, and repair commands.\r\n- link operations for inspecting interrupted or failed writes.\r\n- Bounded wiki/log.md rotation for active local wikis.\r\n- Safer generated commands that work from any terminal directory.\r\n- Stronger first-use, HTTP, MCP stdio, graph, and large-wiki validation.\r\n- SQLite FTS search and bounded graph/query payloads for larger local wikis.\r\n- Windows source workflow is covered by CI portability checks.\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nMCP: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\nPyPI: https://pypi.org/project/link-mcp/\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6157845",
"id": 6157845,
"node_id": "GC_lADOA0wqLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd9hU",
"user": {
"login": "pathakutsav",
"id": 55323180,
"node_id": "MDQ6VXNlcjU1MzIzMTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/55323180?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pathakutsav",
"html_url": "https://github.com/pathakutsav",
"followers_url": "https://api.github.com/users/pathakutsav/followers",
"following_url": "https://api.github.com/users/pathakutsav/following{/other_user}",
"gists_url": "https://api.github.com/users/pathakutsav/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pathakutsav/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pathakutsav/subscriptions",
"organizations_url": "https://api.github.com/users/pathakutsav/orgs",
"repos_url": "https://api.github.com/users/pathakutsav/repos",
"events_url": "https://api.github.com/users/pathakutsav/events{/privacy}",
"received_events_url": "https://api.github.com/users/pathakutsav/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T00:11:20Z",
"updated_at": "2026-05-20T00:11:58Z",
"body": "The first time we saw this, we were like, let's build this into an experience and we built MindHub.\r\n\r\nIf you want to use Knowledge Base with any Anthropic, OpenAI or Gemini model, try it out at https://www.trymindhub.com/\r\n\r\nCheck us out here-: https://youtu.be/KQaw6H3lQMk"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6157947",
"id": 6157947,
"node_id": "GC_lADNNufaACA0NDJhNmJmNTU1OTE0ODkzZTk4OTFjMTE1MTlkZTk0Zs4AXfZ7",
"user": {
"login": "timfong888",
"id": 14055,
"node_id": "MDQ6VXNlcjE0MDU1",
"avatar_url": "https://avatars.githubusercontent.com/u/14055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/timfong888",
"html_url": "https://github.com/timfong888",
"followers_url": "https://api.github.com/users/timfong888/followers",
"following_url": "https://api.github.com/users/timfong888/following{/other_user}",
"gists_url": "https://api.github.com/users/timfong888/gists{/gist_id}",
"starred_url": "https://api.github.com/users/timfong888/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timfong888/subscriptions",
"organizations_url": "https://api.github.com/users/timfong888/orgs",
"repos_url": "https://api.github.com/users/timfong888/repos",
"events_url": "https://api.github.com/users/timfong888/events{/privacy}",
"received_events_url": "https://api.github.com/users/timfong888/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T02:06:50Z",
"updated_at": "2026-05-20T02:06:50Z",
"body": "> Built a desktop editor implementation of this idea — [nohmitaina](https://nohmitaina.com/). Works with Claude Code or Codex CLI (no API key), local Markdown, macOS.\r\n> \r\n> After a month of feeding it my own notes, three problems showed up that I think most implementations of this pattern will hit:\r\n> \r\n> 1. **Identity** — The same concept gets extracted under slightly different names from related sources. The wiki ends up with duplicate pages (\"Cognitive Dissonance Marketing\" and \"Cognitive Dissonance and Urgency\" from the same book, in my case).\r\n> 2. **Level** — Life-scale themes (\"Personal AGI\") end up at the same level as tactical findings (\"Urgency Trigger\"). When everything is flat, importance disappears.\r\n> 3. **Relationship** — Concepts get linked as \"related,\" but the type is lost. Similar, contains, contradicts — all collapsed into one word, which makes the graph useful for navigation but not for thinking.\r\n> \r\n> I did a DDD event-storming pass on the wiki domain and treated each as a first-class domain event (`DuplicateCandidateDetected`, `ConceptsMerged`, `ConceptRelationshipTyped`, `ConceptLevelChanged`). These run on what I call a Dream cycle — a background pass borrowed from how human memory consolidates during sleep. It also handles the \"lint\" operation mentioned in the gist.\r\n> \r\n> Found another commenter (Andrii) on X who's solving Level a different way — by extracting _citable claims_ first, then building the concept layer on top of claim collections. The claim approach makes Level fall out structurally (high-claim concepts are heavyweight, low-claim ones are light), which feels more elegant than my event-driven approach. I'm going to try integrating both.\r\n> \r\n> Thanks for the framing — it's already shaped how a small group of us is thinking about this.\r\n\r\nI just went to the website, this is interesting, is it just you building this?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6159532",
"id": 6159532,
"node_id": "GC_lADOBYZClNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_Kw",
"user": {
"login": "sametbrr",
"id": 92684948,
"node_id": "U_kgDOBYZClA",
"avatar_url": "https://avatars.githubusercontent.com/u/92684948?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sametbrr",
"html_url": "https://github.com/sametbrr",
"followers_url": "https://api.github.com/users/sametbrr/followers",
"following_url": "https://api.github.com/users/sametbrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sametbrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sametbrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sametbrr/subscriptions",
"organizations_url": "https://api.github.com/users/sametbrr/orgs",
"repos_url": "https://api.github.com/users/sametbrr/repos",
"events_url": "https://api.github.com/users/sametbrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sametbrr/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T22:08:02Z",
"updated_at": "2026-05-20T22:08:02Z",
"body": " Implemented this pattern as a full Claude Code skill:\r\n https://github.com/sametbrr/llm-wiki-manager\r\n \r\n Install: git clone https://github.com/sametbrr/llm-wiki-manager ~/.claude/skills/llm-wiki-manager\r\n \r\n Covers all 8 operating modes (bootstrap, ingest, query, update, lint, multi-wiki routing, and more),\r\n 4 idempotent Python scripts for bookkeeping, 8 page templates, and 9 reference docs.\r\n The LLM owns all writing, cross-referencing, and contradiction-flagging — you just drop sources and ask questions.\r\n Works with Claude Code out of the box."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6159534",
"id": 6159534,
"node_id": "GC_lADOBYZClNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_K4",
"user": {
"login": "sametbrr",
"id": 92684948,
"node_id": "U_kgDOBYZClA",
"avatar_url": "https://avatars.githubusercontent.com/u/92684948?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sametbrr",
"html_url": "https://github.com/sametbrr",
"followers_url": "https://api.github.com/users/sametbrr/followers",
"following_url": "https://api.github.com/users/sametbrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sametbrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sametbrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sametbrr/subscriptions",
"organizations_url": "https://api.github.com/users/sametbrr/orgs",
"repos_url": "https://api.github.com/users/sametbrr/repos",
"events_url": "https://api.github.com/users/sametbrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sametbrr/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T22:08:54Z",
"updated_at": "2026-05-20T22:08:54Z",
"body": "Bu pattern'i tam bir Claude Code skill olarak implemente ettim:\r\n https://github.com/sametbrr/llm-wiki-manager\r\n\r\n Kurulum: git clone https://github.com/sametbrr/llm-wiki-manager ~/.claude/skills/llm-wiki-manager\r\n\r\n 8 çalışma modu (bootstrap, ingest, query, update, lint, multi-wiki routing ve daha fazlası),\r\n 4 idempotent Python script, 8 sayfa şablonu ve 9 referans doküman içeriyor.\r\n LLM tüm yazmayı, çapraz referanslamayı ve çelişkileri işaretlemeyi üstleniyor — sen sadece kaynakları bırakıp sorular soruyorsun.\r\n Claude Code ile kutudan çıktığı gibi çalışıyor."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6159573",
"id": 6159573,
"node_id": "GC_lADOEIrqR9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_NU",
"user": {
"login": "ptgrstrat",
"id": 277539399,
"node_id": "U_kgDOEIrqRw",
"avatar_url": "https://avatars.githubusercontent.com/u/277539399?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ptgrstrat",
"html_url": "https://github.com/ptgrstrat",
"followers_url": "https://api.github.com/users/ptgrstrat/followers",
"following_url": "https://api.github.com/users/ptgrstrat/following{/other_user}",
"gists_url": "https://api.github.com/users/ptgrstrat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ptgrstrat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ptgrstrat/subscriptions",
"organizations_url": "https://api.github.com/users/ptgrstrat/orgs",
"repos_url": "https://api.github.com/users/ptgrstrat/repos",
"events_url": "https://api.github.com/users/ptgrstrat/events{/privacy}",
"received_events_url": "https://api.github.com/users/ptgrstrat/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T23:32:43Z",
"updated_at": "2026-05-20T23:32:43Z",
"body": " Thank you!!!! where can I buy you coffee!?!?!? "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6160061",
"id": 6160061,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_r0",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-21T07:24:10Z",
"updated_at": "2026-05-21T07:24:10Z",
"body": " ΩmegaWiki(740+⭐) just shipped v1.5.0 — the ideate and experiment module are excellent!\r\n Repo: https://github.com/skyllwt/OmegaWiki\r\n\r\n • 26 Claude Code skills, covering the full paper lifecycle:\r\n discover → ingest → graph → ideate → experiment → draft → poster → rebuttal\r\n • 8 typed entities · 20 typed edges\r\n • Bilingual (EN + 中文), every skill ships in both languages\r\n • 4 new skills shipped this month\r\n\r\n\r\n\r\n Past v1.4.0 highlight: /poster\r\n \r\n Paper accepted? Run one command, get a 1400×900 conference poster +\r\n print-quality PNG. Reads your LaTeX source, auto-rasterizes TikZ figures,\r\n renders booktabs tables as live HTML, preserves math via KaTeX, walks you\r\n through figure picks and header config. PDF export from any browser. Section\r\n distillation is grounded in your wiki's paper-plan, ideas, experiments — not a\r\n blind LLM summary of the abstract.\r\n\r\n\r\n\r\n Try ΩmegaWiki in Claude Code and run the full LLM-Wiki loop:\r\n\r\n /discover --venue iclr --year 2026 → ranked reading list\r\n /ingest → typed entry, linked into the graph\r\n /ideate + /novelty → ideas with bibliographic grounding\r\n /exp-design → /exp-run → /exp-eval → pilot-first experiment workflow\r\n /paper-plan → /paper-draft → /paper-compile\r\n /poster → conference poster (NEW)\r\n /rebuttal → reviewer response\r\n\r\n End to end. One wiki. No chunks.\r\n \r\n If ΩmegaWiki looks interesting, a ⭐ would encourage and motivate us a lot 😀\r\n https://github.com/skyllwt/OmegaWiki\r\n\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6161067",
"id": 6161067,
"node_id": "GC_lADOBeZH0NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeAqs",
"user": {
"login": "Electro-resonance",
"id": 98977744,
"node_id": "U_kgDOBeZH0A",
"avatar_url": "https://avatars.githubusercontent.com/u/98977744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Electro-resonance",
"html_url": "https://github.com/Electro-resonance",
"followers_url": "https://api.github.com/users/Electro-resonance/followers",
"following_url": "https://api.github.com/users/Electro-resonance/following{/other_user}",
"gists_url": "https://api.github.com/users/Electro-resonance/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Electro-resonance/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Electro-resonance/subscriptions",
"organizations_url": "https://api.github.com/users/Electro-resonance/orgs",
"repos_url": "https://api.github.com/users/Electro-resonance/repos",
"events_url": "https://api.github.com/users/Electro-resonance/events{/privacy}",
"received_events_url": "https://api.github.com/users/Electro-resonance/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-21T13:31:05Z",
"updated_at": "2026-05-21T13:31:05Z",
"body": "Really interesting write-up. Thanks for sharing it.\r\n\r\nI was directly influenced by your article. I’d previously spent around two years experimenting with custom RAG search layers and recursive use of RAG to create near “infinite context” chatbots, but I wanted to try out your LLM Wiki design pattern more explicitly: the idea of moving from query-time retrieval to a persistent, compounding knowledge artefact.\r\n\r\nRather than only express the workflow as `SKILLS.md` / agent instructions, I wanted to make the pattern more concrete and callable, so I implemented it as an MCP server:\r\n\r\n[https://github.com/Electro-resonance/LLM-WIKI-MCP](https://github.com/Electro-resonance/LLM-WIKI-MCP)\r\n\r\nI then added a CLI so I could test and interact with it directly. The CLI can connect to a configurable local Ollama instance, so once you set your preferred open-weights model, or a larger cloud model via Ollama, you can ingest one or more directories and immediately start chatting with your local files.\r\n\r\nOne nice recursive detail is that you can run:\r\n\r\n```text\r\n/ingest .\r\n```\r\n\r\nso the system ingests its own documentation, then ask the LLM about the CLI and MCP from inside the CLI itself.\r\n\r\nThe LLM usage is configured to be recursive: each call updates the rolling conversation/context history, with compression when needed, so you can keep chatting with an agent grounded in your own documents. If you use a local model, the whole workflow can run locally.\r\n\r\nThe main differences from some of the other implementations are:\r\n\r\n* it is an MCP server, not only an agent skill or Obsidian workflow;\r\n* it has a CLI for testing and direct use;\r\n* it supports local Ollama/OpenAI-compatible model use;\r\n* it tracks file provenance using timestamps and hashes;\r\n* repeated ingest skips unchanged files and updates changed ones;\r\n* it supports single-file and directory ingest;\r\n* the wiki can ingest its own docs and answer questions about itself;\r\n* recursive ask/history gives a more persistent local chat experience over your own knowledge base.\r\n\r\nTo me the big shift is exactly the one you described: RAG retrieves information, but an LLM-maintained wiki accumulates understanding.\r\n\r\nThe MCP can also be used directly within an agentic workflow, so other agents can call the wiki tools programmatically rather than going through the CLI.\r\n\r\nEnjoy, and thanks for the inspiration."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6161727",
"id": 6161727,
"node_id": "GC_lADOD42Pk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeBT8",
"user": {
"login": "dtmoura",
"id": 260935571,
"node_id": "U_kgDOD42Pkw",
"avatar_url": "https://avatars.githubusercontent.com/u/260935571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dtmoura",
"html_url": "https://github.com/dtmoura",
"followers_url": "https://api.github.com/users/dtmoura/followers",
"following_url": "https://api.github.com/users/dtmoura/following{/other_user}",
"gists_url": "https://api.github.com/users/dtmoura/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dtmoura/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dtmoura/subscriptions",
"organizations_url": "https://api.github.com/users/dtmoura/orgs",
"repos_url": "https://api.github.com/users/dtmoura/repos",
"events_url": "https://api.github.com/users/dtmoura/events{/privacy}",
"received_events_url": "https://api.github.com/users/dtmoura/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-21T18:13:18Z",
"updated_at": "2026-05-21T18:13:39Z",
"body": "Preventing the wiki from going stale and ensuring the agents are proactive in adding and maintaining the wiki during the conversation, without a precise prompt, seems to be the problem. Just putting a \"remember to update...\" in claude.md wont do it. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6163134",
"id": 6163134,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeCr4",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-22T13:30:20Z",
"updated_at": "2026-05-22T13:30:20Z",
"body": "Synthadoc v0.5.0 is released. \r\n\r\nTwo new features that close the epistemic gap:\r\n\r\n1. Adversarial Review: a second independent LLM interrogates every compiled page for overreach, unsupported generalisations, and contradictions. You appoint the judge in config.toml (different provider or model family recommended for independence). Warnings surface in a lint tab, in page frontmatter, and in the audit trail.\r\n → Quick-start demo - Step 9 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#adversarial-review)\r\n\r\n2. Claim-Level Provenance: during ingest, every compiled paragraph receives a ^[filename:L–L] citation marker tracing it back to the exact source lines. In Obsidian, markers render as chips; one click opens a Source Viewer (with PDF page resolution). Full provenance is queryable via CLI and HTTP API.\r\n → Quick-start demo - Step 18 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#claim-provenance)\r\n\r\n4. Also shipping in v0.5.0: routing + alias system, candidates staging, and a redesigned Obsidian plugin.\r\n\r\nIf any of this is useful or you have thoughts on the direction, feedback is very welcome — and a ⭐ always helps the project reach more people.\r\n\r\n 👉 https://github.com/axoviq-ai/synthadoc\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6163278",
"id": 6163278,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeC04",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-22T15:26:23Z",
"updated_at": "2026-05-22T15:26:23Z",
"body": "
\r\n\r\nInstall:\r\n\r\n```bash\r\nbrew install gowtham0992/link/link\r\nlink demo\r\nlink serve link-demo\r\n```\r\n\r\nMCP package:\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nWhat changed in v1.2.0:\r\n\r\n- Homebrew install path.\r\n- PyPI and MCP Registry updated to 1.2.0.\r\n- GitHub Pages product docs.\r\n- Cleaner README and architecture explanation.\r\n- UI, CLI, and MCP walkthrough visuals.\r\n- Local /health page for readiness, validation, interrupted writes, and repair commands.\r\n- link operations for inspecting interrupted or failed writes.\r\n- Bounded wiki/log.md rotation for active local wikis.\r\n- Safer generated commands that work from any terminal directory.\r\n- Stronger first-use, HTTP, MCP stdio, graph, and large-wiki validation.\r\n- SQLite FTS search and bounded graph/query payloads for larger local wikis.\r\n- Windows source workflow is covered by CI portability checks.\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nMCP: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\nPyPI: https://pypi.org/project/link-mcp/\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6157845",
"id": 6157845,
"node_id": "GC_lADOA0wqLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd9hU",
"user": {
"login": "pathakutsav",
"id": 55323180,
"node_id": "MDQ6VXNlcjU1MzIzMTgw",
"avatar_url": "https://avatars.githubusercontent.com/u/55323180?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pathakutsav",
"html_url": "https://github.com/pathakutsav",
"followers_url": "https://api.github.com/users/pathakutsav/followers",
"following_url": "https://api.github.com/users/pathakutsav/following{/other_user}",
"gists_url": "https://api.github.com/users/pathakutsav/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pathakutsav/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pathakutsav/subscriptions",
"organizations_url": "https://api.github.com/users/pathakutsav/orgs",
"repos_url": "https://api.github.com/users/pathakutsav/repos",
"events_url": "https://api.github.com/users/pathakutsav/events{/privacy}",
"received_events_url": "https://api.github.com/users/pathakutsav/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T00:11:20Z",
"updated_at": "2026-05-20T00:11:58Z",
"body": "The first time we saw this, we were like, let's build this into an experience and we built MindHub.\r\n\r\nIf you want to use Knowledge Base with any Anthropic, OpenAI or Gemini model, try it out at https://www.trymindhub.com/\r\n\r\nCheck us out here-: https://youtu.be/KQaw6H3lQMk"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6157947",
"id": 6157947,
"node_id": "GC_lADNNufaACA0NDJhNmJmNTU1OTE0ODkzZTk4OTFjMTE1MTlkZTk0Zs4AXfZ7",
"user": {
"login": "timfong888",
"id": 14055,
"node_id": "MDQ6VXNlcjE0MDU1",
"avatar_url": "https://avatars.githubusercontent.com/u/14055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/timfong888",
"html_url": "https://github.com/timfong888",
"followers_url": "https://api.github.com/users/timfong888/followers",
"following_url": "https://api.github.com/users/timfong888/following{/other_user}",
"gists_url": "https://api.github.com/users/timfong888/gists{/gist_id}",
"starred_url": "https://api.github.com/users/timfong888/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timfong888/subscriptions",
"organizations_url": "https://api.github.com/users/timfong888/orgs",
"repos_url": "https://api.github.com/users/timfong888/repos",
"events_url": "https://api.github.com/users/timfong888/events{/privacy}",
"received_events_url": "https://api.github.com/users/timfong888/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T02:06:50Z",
"updated_at": "2026-05-20T02:06:50Z",
"body": "> Built a desktop editor implementation of this idea — [nohmitaina](https://nohmitaina.com/). Works with Claude Code or Codex CLI (no API key), local Markdown, macOS.\r\n> \r\n> After a month of feeding it my own notes, three problems showed up that I think most implementations of this pattern will hit:\r\n> \r\n> 1. **Identity** — The same concept gets extracted under slightly different names from related sources. The wiki ends up with duplicate pages (\"Cognitive Dissonance Marketing\" and \"Cognitive Dissonance and Urgency\" from the same book, in my case).\r\n> 2. **Level** — Life-scale themes (\"Personal AGI\") end up at the same level as tactical findings (\"Urgency Trigger\"). When everything is flat, importance disappears.\r\n> 3. **Relationship** — Concepts get linked as \"related,\" but the type is lost. Similar, contains, contradicts — all collapsed into one word, which makes the graph useful for navigation but not for thinking.\r\n> \r\n> I did a DDD event-storming pass on the wiki domain and treated each as a first-class domain event (`DuplicateCandidateDetected`, `ConceptsMerged`, `ConceptRelationshipTyped`, `ConceptLevelChanged`). These run on what I call a Dream cycle — a background pass borrowed from how human memory consolidates during sleep. It also handles the \"lint\" operation mentioned in the gist.\r\n> \r\n> Found another commenter (Andrii) on X who's solving Level a different way — by extracting _citable claims_ first, then building the concept layer on top of claim collections. The claim approach makes Level fall out structurally (high-claim concepts are heavyweight, low-claim ones are light), which feels more elegant than my event-driven approach. I'm going to try integrating both.\r\n> \r\n> Thanks for the framing — it's already shaped how a small group of us is thinking about this.\r\n\r\nI just went to the website, this is interesting, is it just you building this?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6159532",
"id": 6159532,
"node_id": "GC_lADOBYZClNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_Kw",
"user": {
"login": "sametbrr",
"id": 92684948,
"node_id": "U_kgDOBYZClA",
"avatar_url": "https://avatars.githubusercontent.com/u/92684948?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sametbrr",
"html_url": "https://github.com/sametbrr",
"followers_url": "https://api.github.com/users/sametbrr/followers",
"following_url": "https://api.github.com/users/sametbrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sametbrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sametbrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sametbrr/subscriptions",
"organizations_url": "https://api.github.com/users/sametbrr/orgs",
"repos_url": "https://api.github.com/users/sametbrr/repos",
"events_url": "https://api.github.com/users/sametbrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sametbrr/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T22:08:02Z",
"updated_at": "2026-05-20T22:08:02Z",
"body": " Implemented this pattern as a full Claude Code skill:\r\n https://github.com/sametbrr/llm-wiki-manager\r\n \r\n Install: git clone https://github.com/sametbrr/llm-wiki-manager ~/.claude/skills/llm-wiki-manager\r\n \r\n Covers all 8 operating modes (bootstrap, ingest, query, update, lint, multi-wiki routing, and more),\r\n 4 idempotent Python scripts for bookkeeping, 8 page templates, and 9 reference docs.\r\n The LLM owns all writing, cross-referencing, and contradiction-flagging — you just drop sources and ask questions.\r\n Works with Claude Code out of the box."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6159534",
"id": 6159534,
"node_id": "GC_lADOBYZClNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_K4",
"user": {
"login": "sametbrr",
"id": 92684948,
"node_id": "U_kgDOBYZClA",
"avatar_url": "https://avatars.githubusercontent.com/u/92684948?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sametbrr",
"html_url": "https://github.com/sametbrr",
"followers_url": "https://api.github.com/users/sametbrr/followers",
"following_url": "https://api.github.com/users/sametbrr/following{/other_user}",
"gists_url": "https://api.github.com/users/sametbrr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sametbrr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sametbrr/subscriptions",
"organizations_url": "https://api.github.com/users/sametbrr/orgs",
"repos_url": "https://api.github.com/users/sametbrr/repos",
"events_url": "https://api.github.com/users/sametbrr/events{/privacy}",
"received_events_url": "https://api.github.com/users/sametbrr/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T22:08:54Z",
"updated_at": "2026-05-20T22:08:54Z",
"body": "Bu pattern'i tam bir Claude Code skill olarak implemente ettim:\r\n https://github.com/sametbrr/llm-wiki-manager\r\n\r\n Kurulum: git clone https://github.com/sametbrr/llm-wiki-manager ~/.claude/skills/llm-wiki-manager\r\n\r\n 8 çalışma modu (bootstrap, ingest, query, update, lint, multi-wiki routing ve daha fazlası),\r\n 4 idempotent Python script, 8 sayfa şablonu ve 9 referans doküman içeriyor.\r\n LLM tüm yazmayı, çapraz referanslamayı ve çelişkileri işaretlemeyi üstleniyor — sen sadece kaynakları bırakıp sorular soruyorsun.\r\n Claude Code ile kutudan çıktığı gibi çalışıyor."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6159573",
"id": 6159573,
"node_id": "GC_lADOEIrqR9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_NU",
"user": {
"login": "ptgrstrat",
"id": 277539399,
"node_id": "U_kgDOEIrqRw",
"avatar_url": "https://avatars.githubusercontent.com/u/277539399?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ptgrstrat",
"html_url": "https://github.com/ptgrstrat",
"followers_url": "https://api.github.com/users/ptgrstrat/followers",
"following_url": "https://api.github.com/users/ptgrstrat/following{/other_user}",
"gists_url": "https://api.github.com/users/ptgrstrat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ptgrstrat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ptgrstrat/subscriptions",
"organizations_url": "https://api.github.com/users/ptgrstrat/orgs",
"repos_url": "https://api.github.com/users/ptgrstrat/repos",
"events_url": "https://api.github.com/users/ptgrstrat/events{/privacy}",
"received_events_url": "https://api.github.com/users/ptgrstrat/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-20T23:32:43Z",
"updated_at": "2026-05-20T23:32:43Z",
"body": " Thank you!!!! where can I buy you coffee!?!?!? "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6160061",
"id": 6160061,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBd_r0",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-21T07:24:10Z",
"updated_at": "2026-05-21T07:24:10Z",
"body": " ΩmegaWiki(740+⭐) just shipped v1.5.0 — the ideate and experiment module are excellent!\r\n Repo: https://github.com/skyllwt/OmegaWiki\r\n\r\n • 26 Claude Code skills, covering the full paper lifecycle:\r\n discover → ingest → graph → ideate → experiment → draft → poster → rebuttal\r\n • 8 typed entities · 20 typed edges\r\n • Bilingual (EN + 中文), every skill ships in both languages\r\n • 4 new skills shipped this month\r\n\r\n\r\n\r\n Past v1.4.0 highlight: /poster\r\n \r\n Paper accepted? Run one command, get a 1400×900 conference poster +\r\n print-quality PNG. Reads your LaTeX source, auto-rasterizes TikZ figures,\r\n renders booktabs tables as live HTML, preserves math via KaTeX, walks you\r\n through figure picks and header config. PDF export from any browser. Section\r\n distillation is grounded in your wiki's paper-plan, ideas, experiments — not a\r\n blind LLM summary of the abstract.\r\n\r\n\r\n\r\n Try ΩmegaWiki in Claude Code and run the full LLM-Wiki loop:\r\n\r\n /discover --venue iclr --year 2026 → ranked reading list\r\n /ingest → typed entry, linked into the graph\r\n /ideate + /novelty → ideas with bibliographic grounding\r\n /exp-design → /exp-run → /exp-eval → pilot-first experiment workflow\r\n /paper-plan → /paper-draft → /paper-compile\r\n /poster → conference poster (NEW)\r\n /rebuttal → reviewer response\r\n\r\n End to end. One wiki. No chunks.\r\n \r\n If ΩmegaWiki looks interesting, a ⭐ would encourage and motivate us a lot 😀\r\n https://github.com/skyllwt/OmegaWiki\r\n\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6161067",
"id": 6161067,
"node_id": "GC_lADOBeZH0NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeAqs",
"user": {
"login": "Electro-resonance",
"id": 98977744,
"node_id": "U_kgDOBeZH0A",
"avatar_url": "https://avatars.githubusercontent.com/u/98977744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Electro-resonance",
"html_url": "https://github.com/Electro-resonance",
"followers_url": "https://api.github.com/users/Electro-resonance/followers",
"following_url": "https://api.github.com/users/Electro-resonance/following{/other_user}",
"gists_url": "https://api.github.com/users/Electro-resonance/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Electro-resonance/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Electro-resonance/subscriptions",
"organizations_url": "https://api.github.com/users/Electro-resonance/orgs",
"repos_url": "https://api.github.com/users/Electro-resonance/repos",
"events_url": "https://api.github.com/users/Electro-resonance/events{/privacy}",
"received_events_url": "https://api.github.com/users/Electro-resonance/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-21T13:31:05Z",
"updated_at": "2026-05-21T13:31:05Z",
"body": "Really interesting write-up. Thanks for sharing it.\r\n\r\nI was directly influenced by your article. I’d previously spent around two years experimenting with custom RAG search layers and recursive use of RAG to create near “infinite context” chatbots, but I wanted to try out your LLM Wiki design pattern more explicitly: the idea of moving from query-time retrieval to a persistent, compounding knowledge artefact.\r\n\r\nRather than only express the workflow as `SKILLS.md` / agent instructions, I wanted to make the pattern more concrete and callable, so I implemented it as an MCP server:\r\n\r\n[https://github.com/Electro-resonance/LLM-WIKI-MCP](https://github.com/Electro-resonance/LLM-WIKI-MCP)\r\n\r\nI then added a CLI so I could test and interact with it directly. The CLI can connect to a configurable local Ollama instance, so once you set your preferred open-weights model, or a larger cloud model via Ollama, you can ingest one or more directories and immediately start chatting with your local files.\r\n\r\nOne nice recursive detail is that you can run:\r\n\r\n```text\r\n/ingest .\r\n```\r\n\r\nso the system ingests its own documentation, then ask the LLM about the CLI and MCP from inside the CLI itself.\r\n\r\nThe LLM usage is configured to be recursive: each call updates the rolling conversation/context history, with compression when needed, so you can keep chatting with an agent grounded in your own documents. If you use a local model, the whole workflow can run locally.\r\n\r\nThe main differences from some of the other implementations are:\r\n\r\n* it is an MCP server, not only an agent skill or Obsidian workflow;\r\n* it has a CLI for testing and direct use;\r\n* it supports local Ollama/OpenAI-compatible model use;\r\n* it tracks file provenance using timestamps and hashes;\r\n* repeated ingest skips unchanged files and updates changed ones;\r\n* it supports single-file and directory ingest;\r\n* the wiki can ingest its own docs and answer questions about itself;\r\n* recursive ask/history gives a more persistent local chat experience over your own knowledge base.\r\n\r\nTo me the big shift is exactly the one you described: RAG retrieves information, but an LLM-maintained wiki accumulates understanding.\r\n\r\nThe MCP can also be used directly within an agentic workflow, so other agents can call the wiki tools programmatically rather than going through the CLI.\r\n\r\nEnjoy, and thanks for the inspiration."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6161727",
"id": 6161727,
"node_id": "GC_lADOD42Pk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeBT8",
"user": {
"login": "dtmoura",
"id": 260935571,
"node_id": "U_kgDOD42Pkw",
"avatar_url": "https://avatars.githubusercontent.com/u/260935571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dtmoura",
"html_url": "https://github.com/dtmoura",
"followers_url": "https://api.github.com/users/dtmoura/followers",
"following_url": "https://api.github.com/users/dtmoura/following{/other_user}",
"gists_url": "https://api.github.com/users/dtmoura/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dtmoura/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dtmoura/subscriptions",
"organizations_url": "https://api.github.com/users/dtmoura/orgs",
"repos_url": "https://api.github.com/users/dtmoura/repos",
"events_url": "https://api.github.com/users/dtmoura/events{/privacy}",
"received_events_url": "https://api.github.com/users/dtmoura/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-21T18:13:18Z",
"updated_at": "2026-05-21T18:13:39Z",
"body": "Preventing the wiki from going stale and ensuring the agents are proactive in adding and maintaining the wiki during the conversation, without a precise prompt, seems to be the problem. Just putting a \"remember to update...\" in claude.md wont do it. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6163134",
"id": 6163134,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeCr4",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-22T13:30:20Z",
"updated_at": "2026-05-22T13:30:20Z",
"body": "Synthadoc v0.5.0 is released. \r\n\r\nTwo new features that close the epistemic gap:\r\n\r\n1. Adversarial Review: a second independent LLM interrogates every compiled page for overreach, unsupported generalisations, and contradictions. You appoint the judge in config.toml (different provider or model family recommended for independence). Warnings surface in a lint tab, in page frontmatter, and in the audit trail.\r\n → Quick-start demo - Step 9 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#adversarial-review)\r\n\r\n2. Claim-Level Provenance: during ingest, every compiled paragraph receives a ^[filename:L–L] citation marker tracing it back to the exact source lines. In Obsidian, markers render as chips; one click opens a Source Viewer (with PDF page resolution). Full provenance is queryable via CLI and HTTP API.\r\n → Quick-start demo - Step 18 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#claim-provenance)\r\n\r\n4. Also shipping in v0.5.0: routing + alias system, candidates staging, and a redesigned Obsidian plugin.\r\n\r\nIf any of this is useful or you have thoughts on the direction, feedback is very welcome — and a ⭐ always helps the project reach more people.\r\n\r\n 👉 https://github.com/axoviq-ai/synthadoc\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6163278",
"id": 6163278,
"node_id": "GC_lADOBLaje9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeC04",
"user": {
"login": "ojuschugh1",
"id": 79078267,
"node_id": "MDQ6VXNlcjc5MDc4MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/79078267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojuschugh1",
"html_url": "https://github.com/ojuschugh1",
"followers_url": "https://api.github.com/users/ojuschugh1/followers",
"following_url": "https://api.github.com/users/ojuschugh1/following{/other_user}",
"gists_url": "https://api.github.com/users/ojuschugh1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojuschugh1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojuschugh1/subscriptions",
"organizations_url": "https://api.github.com/users/ojuschugh1/orgs",
"repos_url": "https://api.github.com/users/ojuschugh1/repos",
"events_url": "https://api.github.com/users/ojuschugh1/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojuschugh1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-22T15:26:23Z",
"updated_at": "2026-05-22T15:26:23Z",
"body": "\r\n
\r\n ███████╗ ██████╗ ███████╗\r\n ██╔════╝██╔═══██╗╚══███╔╝\r\n ███████╗██║ ██║ ███╔╝\r\n ╚════██║██║▄▄ ██║ ███╔╝\r\n ███████║╚██████╔╝███████╗\r\n ╚══════╝ ╚══▀▀═╝ ╚══════╝\r\n
\r\n\r\n\r\n\r\n Compress LLM context to save tokens and reduce costs\r\n
\r\n\r\n\r\n \r\n Real session stats:\r\n 3,003 compressions ·\r\n 178,442 tokens saved ·\r\n 24.7% avg reduction · up to\r\n 92% with dedup\r\n \r\n
\r\n\r\n\r\n \r\n
\r\n\r\n\r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n
\r\n\r\n\r\n Install ·\r\n How It Works ·\r\n Supported Tools ·\r\n Changelog ·\r\n Discord\r\n
\r\n\r\n---\r\n\r\nsqz compresses command output before it reaches your LLM. Single Rust binary, zero config.\r\n\r\nThe real win is dedup: when the same file gets read 5 times in a session, sqz sends it once and returns a 13-token reference for every repeat.\r\n\r\n```\r\nWithout sqz: With sqz:\r\n\r\nFile read #1: 2,000 tokens File read #1: ~800 tokens (compressed)\r\nFile read #2: 2,000 tokens File read #2: ~13 tokens (dedup ref)\r\nFile read #3: 2,000 tokens File read #3: ~13 tokens (dedup ref)\r\n─────────────────────── ───────────────────────\r\nTotal: 6,000 tokens Total: ~826 tokens (86% saved)\r\n```\r\n\r\n## Token Savings\r\n\r\n> **24.7%** average reduction across 3,003 real compressions ·\r\n> **92%** saved on repeated file reads ·\r\n> **86%** on shell/git output ·\r\n> **13-token** refs for cached content\r\n\r\nOne developer's week, measured from actual `sqz gain` output:\r\n\r\n```\r\n$ sqz gain\r\nsqz token savings (last 7 days)\r\n──────────────────────────────────────────────────\r\n 04-13 │ │ 2,329 saved\r\n 04-14 │ │ 0 saved\r\n 04-15 │███ │ 12,954 saved\r\n 04-16 │██ │ 9,223 saved\r\n 04-17 │████ │ 14,752 saved\r\n 04-18 │██████████████████████████████│ 105,569 saved\r\n 04-19 │████████ │ 30,882 saved\r\n 04-20 │█ │ 4,334 saved\r\n──────────────────────────────────────────────────\r\n Total: 3,003 compressions, 178,442 tokens saved (24.7% avg reduction)\r\n```\r\n\r\n### Per-command compression\r\n\r\nSingle-command compression (measured via `cargo test -p sqz-engine benchmarks`):\r\n\r\n| Content | Before | After | Saved |\r\n|---|---:|---:|---:|\r\n| Repeated log lines | 148 | 62 | **58%** |\r\n| Large JSON array | 259 | 142 | **45%** |\r\n| JSON API response | 64 | 53 | **17%** |\r\n| Git diff | 61 | 54 | **12%** |\r\n| Prose/docs | 124 | 121 | **2%** |\r\n| Stack trace (safe mode) | 82 | 82 | **0%** |\r\n\r\n### Session-level with dedup\r\n\r\nWhere the real savings live — the cache sends each file once, repeats cost 13 tokens:\r\n\r\n| Scenario | Without sqz | With sqz | Saved |\r\n|---|---:|---:|---:|\r\n| Same file read 5× | 10,000 | 826 | **92%** |\r\n| Same JSON response 3× | 192 | 79 | **59%** |\r\n| Test-fix-test cycle (3 runs) | 15,000 | 5,186 | **65%** |\r\n\r\nSingle-command compression ranges from 2–58% depending on content. Repeated reads drop to 13 tokens each. Your mileage will vary with how repetitive your tool calls are — agentic sessions with many file re-reads see the biggest wins.\r\n\r\n## Install\r\n\r\n**Prebuilt binaries** (no compiler required — works on every platform):\r\n\r\n```sh\r\n# macOS / Linux\r\ncurl -fsSL https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.sh | sh\r\n\r\n# Windows (PowerShell)\r\nirm https://raw.githubusercontent.com/ojuschugh1/sqz/main/install.ps1 | iex\r\n\r\n# Any platform via npm\r\nnpm install -g sqz-cli\r\n\r\n# macOS / Linux via Homebrew\r\nbrew tap ojuschugh1/sqz\r\nbrew install sqz\r\n```\r\n\r\n**Build from source via Cargo:**\r\n\r\n```sh\r\ncargo install sqz-cli sqz-mcp\r\n```\r\n\r\n`sqz-cli` provides the `sqz` binary; `sqz-mcp` provides the MCP server. `sqz-engine` is a library dependency — it compiles automatically and does not need to be installed separately.\r\n\r\n**Build from source** (`cargo install sqz-cli`) works too, but needs a C toolchain:\r\n\r\n- Linux: `build-essential` (apt) or equivalent\r\n- macOS: Xcode Command Line Tools (`xcode-select --install`)\r\n- **Windows: Visual Studio Build Tools with the \"Desktop development with C++\" workload.** Without these, `cargo install` fails with `linker link.exe not found`. If you don't already have them, use the PowerShell or npm install above instead.\r\n\r\nThen initialize:\r\n\r\n```sh\r\nsqz init --global # hooks apply to every project on this machine\r\n# or\r\nsqz init # hooks apply to just this project (.claude/settings.local.json)\r\n```\r\n\r\n`--global` writes to `~/.claude/settings.json` (the user scope per the\r\n[Anthropic scope table](https://docs.claude.com/en/docs/claude-code/settings)),\r\nso the sqz hook fires in every Claude Code session on this machine. This is\r\nthe common case on first install. Your existing `permissions`, `env`,\r\n`statusLine`, and unrelated hooks in `~/.claude/settings.json` are\r\npreserved — sqz merges its entries rather than overwriting.\r\n\r\nPlain `sqz init` (project scope) is useful when you want sqz active only\r\ninside one repo.\r\n\r\n**Only using one agent?** Pass `--only` (or `--skip`) to limit which\r\nconfigs are written:\r\n\r\n```sh\r\nsqz init --only opencode # just OpenCode, nothing else\r\nsqz init --only opencode,codex # OpenCode and Codex\r\nsqz init --skip cursor,windsurf # everything except Cursor and Windsurf\r\n```\r\n\r\nAccepted names: `claude`, `cursor`, `windsurf`, `cline`, `gemini`,\r\n`kiro`, `opencode`, `codex`. Aliases (`claude-code`, `gemini-cli`, `roo`,\r\n`kiro-cli`) also work. `--only` and `--skip` can't be combined.\r\n\r\n### Manual installation (preserve comments in your config)\r\n\r\n`sqz init` round-trips your config file through a JSON parser to merge\r\nthe sqz entry, which drops any comments in your `opencode.jsonc` (and\r\nthe analogous JSON-with-comments files other tools accept). If you've\r\ncommented your config carefully and want to keep them, install by hand\r\ninstead.\r\n\r\n**OpenCode** — two steps:\r\n\r\n1. Drop the plugin file in place. `sqz` prints the generated TS to\r\n stdout so you don't have to hand-write the path-escaping logic:\r\n\r\n ```sh\r\n mkdir -p ~/.config/opencode/plugins\r\n sqz print-opencode-plugin > ~/.config/opencode/plugins/sqz.ts\r\n ```\r\n\r\n2. Add the MCP entry to your existing `opencode.jsonc` yourself.\r\n Append this block inside the top-level `mcp` object (create the\r\n `mcp` object if it doesn't exist):\r\n\r\n ```jsonc\r\n \"sqz\": {\r\n \"type\": \"local\",\r\n \"command\": [\"sqz-mcp\", \"--transport\", \"stdio\"],\r\n \"enabled\": true\r\n }\r\n ```\r\n\r\nComments in the rest of your file stay put. OpenCode auto-discovers\r\nthe plugin file; no `plugin` array entry needed (adding one causes\r\ndouble-loading, see issue #10).\r\n\r\n**Other tools** — Claude Code, Cursor, Windsurf, Cline, Gemini CLI,\r\nand Codex use plain JSON configs without comment support, so the\r\nautomated path is non-destructive there. Use `sqz init --only `\r\nfor those.\r\n\r\nThat's it. Shell hooks installed, AI tool hooks configured.\r\n\r\n## How It Works\r\n\r\n\r\n \r\n
\r\n\r\nsqz installs a PreToolUse hook that intercepts bash commands before your AI tool runs them. The output gets compressed transparently — the AI tool never knows.\r\n\r\n```\r\nClaude → git status → [sqz hook rewrites] → compressed output (85% smaller)\r\n```\r\n\r\nWhat gets compressed:\r\n- **Shell output** — git, cargo, npm, docker, kubectl, ls, grep, etc.\r\n- **JSON** — strips nulls, compact encoding\r\n- **Logs** — collapses repeated lines\r\n- **Test output** — shows failures only\r\n\r\nWhat doesn't get compressed:\r\n- Stack traces, error messages, secrets — routed to safe mode (0% compression)\r\n- Your prompts and the AI's responses — controlled by the AI tool, not sqz\r\n\r\n## Supported Tools\r\n\r\n| Tool | Integration | Setup |\r\n|---|---|---|\r\n| Claude Code | PreToolUse hook (transparent) | `sqz init` |\r\n| Cursor | PreToolUse hook (transparent) | `sqz init` |\r\n| Windsurf | PreToolUse hook (transparent) | `sqz init` |\r\n| Cline | PreToolUse hook (transparent) | `sqz init` |\r\n| Gemini CLI | BeforeTool hook (transparent) | `sqz init` |\r\n| Kiro | PreToolUse hook (transparent) | `sqz init` |\r\n| OpenCode | TypeScript plugin (transparent) | `sqz init` |\r\n| VS Code | [Extension](https://marketplace.visualstudio.com/items?itemName=ojuschugh1.sqz) | Install from Marketplace |\r\n| JetBrains | [Plugin](https://plugins.jetbrains.com/plugin/31240-sqz--context-intelligence/) | Install from Marketplace |\r\n| Chrome | Browser extension | ChatGPT, Claude.ai, Gemini, Grok, Perplexity |\r\n| [Firefox](https://addons.mozilla.org/en-US/firefox/addon/sqz-context-compression/) | Browser extension | Same sites |\r\n\r\n## CLI\r\n\r\n```sh\r\nsqz init --global # Install hooks for every project on this machine\r\nsqz init # Install hooks for just this project\r\nsqz init --only kiro # Only configure Kiro (skip the rest)\r\nsqz init --only opencode # Only configure OpenCode (skip the rest)\r\nsqz init --skip cursor # Configure every agent except Cursor\r\nsqz compress # Compress (or pipe from stdin)\r\nsqz compress --no-cache # Compress without dedup (always full output)\r\nsqz expand [ # Recover original content from a §ref:HASH§ token\r\nsqz compact # Evict stale context to free tokens\r\nsqz gain # Show daily token savings (bar chart)\r\nsqz gain --project . # Per-project daily gains\r\nsqz gain --days 30 # Last 30 days\r\nsqz stats # Cumulative compression report\r\nsqz stats --breakdown # Per-command token usage breakdown\r\nsqz stats --project . # Stats for current project only\r\nsqz stats --project list # List all tracked projects\r\nsqz discover # Find missed savings\r\nsqz resume # Re-inject session context after compaction\r\nsqz vizit # Live terminal dashboard (like htop for AI agents)\r\nsqz hook claude # Process a PreToolUse hook (Claude Code)\r\nsqz hook kiro # Process a PreToolUse hook (Kiro)\r\nsqz print-opencode-plugin # Print OpenCode plugin TS for manual install\r\nsqz proxy --port 8080 # API proxy (compresses full request payloads)\r\n```\r\n\r\n### Dedup Escape Hatch\r\n\r\nWhen sqz sees the same content twice, it returns a compact `§ref:HASH§` token\r\ninstead of the full text. Most models handle this fine, but some (e.g., GLM 5.1)\r\ncan't parse the ref format and loop. Four ways to work around this:\r\n\r\n```sh\r\n# 1. Recover original content from a ref\r\nsqz expand a1b2c3d4 # prefix match\r\nsqz expand '§ref:a1b2c3d4§' # paste the whole token\r\n\r\n# 2. Compress without dedup (per-invocation)\r\necho \"...\" | sqz compress --no-cache\r\n\r\n# 3. Disable dedup globally (env var)\r\nexport SQZ_NO_DEDUP=1\r\n\r\n# 4. MCP passthrough tool (returns input byte-exact, zero transforms)\r\n# Available via tools/list when sqz-mcp is running\r\n```\r\n\r\n## Track Your Own Savings\r\n\r\nRun `sqz gain` in your shell any time to see your own daily breakdown (see the\r\nToken Savings section above for what the output looks like), and `sqz stats`\r\nfor the full cumulative report:\r\n\r\n```sh\r\n$ sqz stats\r\n 📊 sqz compression stats\r\n ──────────────────────────────────────────────────\r\n\r\n 178,442 tokens saved\r\n ↓ 24.7% average reduction\r\n\r\n Compressions 3,003\r\n Tokens in 721,840\r\n Tokens out 543,398\r\n Tokens saved 178,442\r\n Avg reduction 24.7%\r\n\r\n 🗄️ Cache\r\n ──────────────────────────────────────────────────\r\n Entries 43\r\n Size 39.1 KB\r\n```\r\n\r\nAdd `--breakdown` to see exactly which commands consume the most tokens:\r\n\r\n```sh\r\n$ sqz stats --breakdown\r\n\r\n 🔍 Top Token Consumers\r\n ──────────────────────────────────────────────────────────────────────\r\n command calls tokens in out saved\r\n ──────────────────────────────────────────────────────────────────────\r\n dedup 249 45541 3237 93%\r\n stdin 51 30851 24289 21%\r\n auto 132 18288 7740 58%\r\n echo 17 1050 558 47%\r\n ls -la 8 948 948 0%\r\n cargo build 7 170 145 15%\r\n git status 4 56 8 86%\r\n ──────────────────────────────────────────────────────────────────────\r\n```\r\n\r\n**Per-project filtering:**\r\n\r\n```sh\r\nsqz stats --project . # stats for current project only\r\nsqz stats --project list # list all tracked projects\r\nsqz gain --project . # daily gains for current project\r\nsqz gain --days 30 # last 30 days instead of 7\r\nsqz gain --days 30 --project . # combine both\r\n```\r\n\r\nStats are stored locally in SQLite under `~/.sqz/sessions.db` — nothing leaves your machine.\r\n\r\n## How Compression Works\r\n\r\n1. **Per-command formatters** — `git status` → compact summary, `cargo test` → failures only, `docker ps` → name/image/status table\r\n2. **Structural summaries** — code files compressed to imports + function signatures + call graph (~70% reduction). The model sees the architecture, not implementation noise.\r\n3. **Dedup cache** — SHA-256 content hash, persistent across sessions. Second read = 13-token reference.\r\n4. **JSON pipeline** — strip nulls → project out debug fields → flatten → collapse arrays → TOON encoding (lossless compact format)\r\n5. **Safe mode** — stack traces, secrets, migrations detected by entropy analysis and routed through with 0% compression\r\n\r\nFor the full technical details, see [docs/](docs/).\r\n\r\n## Configuration\r\n\r\n```toml\r\n# ~/.sqz/presets/default.toml\r\n[preset]\r\nname = \"default\"\r\nversion = \"1.0\"\r\n\r\n[compression.condense]\r\nenabled = true\r\nmax_repeated_lines = 3\r\n\r\n[compression.strip_nulls]\r\nenabled = true\r\n\r\n[budget]\r\nwarning_threshold = 0.70\r\ndefault_window_size = 200000\r\n```\r\n\r\n## Privacy\r\n\r\n- Zero telemetry — no data transmitted, no crash reports\r\n- Fully offline — works in air-gapped environments\r\n- All processing local\r\n\r\n## Development\r\n\r\n```sh\r\ngit clone https://github.com/ojuschugh1/sqz.git\r\ncd sqz\r\ncargo test --workspace\r\ncargo build --release\r\n```\r\n\r\n## License\r\n\r\n[Elastic License 2.0](LICENSE) (ELv2) — use, fork, modify freely. Two restrictions: no competing hosted service, no removing license notices.\r\n\r\n## Links\r\n\r\n- [White Paper: Pre-Injection Context Compression](docs/whitepaper.md)\r\n- [Benchmark: sqz vs rtk](docs/benchmark-vs-rtk.md)\r\n- [Discord](https://discord.gg/j8EEyH5dSB)\r\n- [Changelog](CHANGELOG.md)\r\n\r\n## Star History\r\n\r\n\r\n \r\n \r\n \r\n \r\n \r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6163296",
"id": 6163296,
"node_id": "GC_lADOEF4L3toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeC2A",
"user": {
"login": "ahumanft",
"id": 274598878,
"node_id": "U_kgDOEF4L3g",
"avatar_url": "https://avatars.githubusercontent.com/u/274598878?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahumanft",
"html_url": "https://github.com/ahumanft",
"followers_url": "https://api.github.com/users/ahumanft/followers",
"following_url": "https://api.github.com/users/ahumanft/following{/other_user}",
"gists_url": "https://api.github.com/users/ahumanft/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ahumanft/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ahumanft/subscriptions",
"organizations_url": "https://api.github.com/users/ahumanft/orgs",
"repos_url": "https://api.github.com/users/ahumanft/repos",
"events_url": "https://api.github.com/users/ahumanft/events{/privacy}",
"received_events_url": "https://api.github.com/users/ahumanft/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-22T15:43:27Z",
"updated_at": "2026-05-22T15:43:27Z",
"body": "Built this as the next handoff in the chain. V3 proposes segmentation as the architectural answer to scaling V1 — the idea that every component of a wiki system, ingestion, schemas, roles, retrieval, lint, should stay narrow enough that the LLM executing it never gets overwhelmed. Also includes a finding on explicit versus implicit schema instructions and why timing matters when invoking them. Intentionally incomplete, same spirit as V1 and V2. https://gist.github.com/ahumanft/6c96385be6ca4af578cc9b20e0f79e66"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6164424",
"id": 6164424,
"node_id": "GC_lADOAGqYpNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeD8g",
"user": {
"login": "rstoye",
"id": 6985892,
"node_id": "MDQ6VXNlcjY5ODU4OTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/6985892?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rstoye",
"html_url": "https://github.com/rstoye",
"followers_url": "https://api.github.com/users/rstoye/followers",
"following_url": "https://api.github.com/users/rstoye/following{/other_user}",
"gists_url": "https://api.github.com/users/rstoye/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rstoye/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rstoye/subscriptions",
"organizations_url": "https://api.github.com/users/rstoye/orgs",
"repos_url": "https://api.github.com/users/rstoye/repos",
"events_url": "https://api.github.com/users/rstoye/events{/privacy}",
"received_events_url": "https://api.github.com/users/rstoye/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-23T10:49:26Z",
"updated_at": "2026-05-23T10:49:26Z",
"body": "> Very curious how many of these comments are from bots. There can't be this many people that think an LLM wiki is good solution for knowledge at scale.\r\n> \r\n> I've seen a few voices of reason here, but most everything is \"What a great and novel idea\". Which is wrong on both accounts. Folks - for your own sake, please research information retrieval and storage to understand why this doesn't work.\r\n> \r\n> If you're still reading... Check out CIBFE or https://headkey.ai for a pluggable cognitive solution that's more than memory.\r\n\r\nSo you shit on the idea, critizice other people for believing in it, don't provide any explanation, tell people to do their own research and then you link to a website of a product that is currently gated behind a waitlist, closed source and created by a company you work for.\r\n\r\nMan a lot to unpack here."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6164862",
"id": 6164862,
"node_id": "GC_lADOAO_nE9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeEX4",
"user": {
"login": "gowtham0992",
"id": 15722259,
"node_id": "MDQ6VXNlcjE1NzIyMjU5",
"avatar_url": "https://avatars.githubusercontent.com/u/15722259?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gowtham0992",
"html_url": "https://github.com/gowtham0992",
"followers_url": "https://api.github.com/users/gowtham0992/followers",
"following_url": "https://api.github.com/users/gowtham0992/following{/other_user}",
"gists_url": "https://api.github.com/users/gowtham0992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gowtham0992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gowtham0992/subscriptions",
"organizations_url": "https://api.github.com/users/gowtham0992/orgs",
"repos_url": "https://api.github.com/users/gowtham0992/repos",
"events_url": "https://api.github.com/users/gowtham0992/events{/privacy}",
"received_events_url": "https://api.github.com/users/gowtham0992/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-23T18:47:54Z",
"updated_at": "2026-05-23T18:47:54Z",
"body": "Link v1.3.0 is live.\r\n\r\nLink is local, source-backed memory for AI agents. Raw sources become an inspectable Markdown wiki. Explicit “remember this” requests become reviewable agent memory. MCP tools let Codex, Claude, Cursor, Kiro, VS Code, Antigravity, and other clients query that memory without dumping the whole wiki into context.\r\n\r\n] \r\n\r\nInstall:\r\n```bash\r\nbrew install gowtham0992/link/link\r\nlink demo\r\nlink serve link-demo\r\n```\r\n\r\nMCP:\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nWhat changed:\r\n```\r\n- link next for first-run prompts.\r\n- link health and /api/health for readiness checks.\r\n- MCP link_operations for interrupted-write inspection.\r\n- Better graph controls for larger wikis.\r\n- Persistent-cache diagnostics in status/health/benchmark.\r\n- More copyable prompts and recovery actions in the local UI.\r\n- Paste-safe CLI commands that work from any terminal directory.\r\n- Threaded local HTTP handling and request timeouts.\r\n- Expanded user-level smoke coverage for CLI, HTTP viewer, MCP stdio, and large wikis.\r\n```\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\nPyPI: https://pypi.org/project/link-mcp/\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6166832",
"id": 6166832,
"node_id": "GC_lADOARHz9toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeGTA",
"user": {
"login": "andkir1",
"id": 17953782,
"node_id": "MDQ6VXNlcjE3OTUzNzgy",
"avatar_url": "https://avatars.githubusercontent.com/u/17953782?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andkir1",
"html_url": "https://github.com/andkir1",
"followers_url": "https://api.github.com/users/andkir1/followers",
"following_url": "https://api.github.com/users/andkir1/following{/other_user}",
"gists_url": "https://api.github.com/users/andkir1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andkir1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andkir1/subscriptions",
"organizations_url": "https://api.github.com/users/andkir1/orgs",
"repos_url": "https://api.github.com/users/andkir1/repos",
"events_url": "https://api.github.com/users/andkir1/events{/privacy}",
"received_events_url": "https://api.github.com/users/andkir1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-24T23:45:45Z",
"updated_at": "2026-05-24T23:50:20Z",
"body": "I've been building a search-behavior-grounded knowledge tree since 2012 — synonym clustering plus hierarchical navigation built from actual query data, not academic taxonomy. Your maintenance insight is exactly right, and it reframes something I couldn't solve with human contributors alone. One question your bottom-up approach leaves open: what if the LLM also had a pre-built cognitive skeleton showing not just what exists but what's missing and in what order those gaps matter? \r\n\r\nWrote about this here: [https://medium.com/@thebooq/the-right-problem-89624f7a461a](https://medium.com/@thebooq/the-right-problem-89624f7a461a)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6167998",
"id": 6167998,
"node_id": "GC_lADOA5Ad-NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeHb4",
"user": {
"login": "ek0212",
"id": 59776504,
"node_id": "MDQ6VXNlcjU5Nzc2NTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/59776504?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ek0212",
"html_url": "https://github.com/ek0212",
"followers_url": "https://api.github.com/users/ek0212/followers",
"following_url": "https://api.github.com/users/ek0212/following{/other_user}",
"gists_url": "https://api.github.com/users/ek0212/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ek0212/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ek0212/subscriptions",
"organizations_url": "https://api.github.com/users/ek0212/orgs",
"repos_url": "https://api.github.com/users/ek0212/repos",
"events_url": "https://api.github.com/users/ek0212/events{/privacy}",
"received_events_url": "https://api.github.com/users/ek0212/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-25T12:50:13Z",
"updated_at": "2026-05-25T12:50:41Z",
"body": "Made a mini kit for anyone trying to get this idea off the ground in a formalized way with Obsidian + LLM of choice. This repo helps establish the curation layer on top of any domain you wish after just a few set up steps with your LLM. Personally used this repo for my \"second brain\" and resurrecting high school notes: https://github.com/ek0212/second-brain-template. All advice welcome!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6167999",
"id": 6167999,
"node_id": "GC_lADOCQIrh9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeHb8",
"user": {
"login": "Stephenusegithub",
"id": 151137159,
"node_id": "U_kgDOCQIrhw",
"avatar_url": "https://avatars.githubusercontent.com/u/151137159?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Stephenusegithub",
"html_url": "https://github.com/Stephenusegithub",
"followers_url": "https://api.github.com/users/Stephenusegithub/followers",
"following_url": "https://api.github.com/users/Stephenusegithub/following{/other_user}",
"gists_url": "https://api.github.com/users/Stephenusegithub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Stephenusegithub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Stephenusegithub/subscriptions",
"organizations_url": "https://api.github.com/users/Stephenusegithub/orgs",
"repos_url": "https://api.github.com/users/Stephenusegithub/repos",
"events_url": "https://api.github.com/users/Stephenusegithub/events{/privacy}",
"received_events_url": "https://api.github.com/users/Stephenusegithub/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-25T12:50:50Z",
"updated_at": "2026-05-25T12:50:50Z",
"body": "你好,邮件已收到~"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6168427",
"id": 6168427,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeH2s",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-25T23:15:44Z",
"updated_at": "2026-05-25T23:16:13Z",
"body": " **Synto v0.3.0 is out.**\r\n\r\n https://github.com/kytmanov/synto\r\n\r\n **Main addition**: an MCP server with 8 tools, ready to wire into Claude Code, Cursor, or any MCP client. Your AI assistant can search the wiki, read articles, look up concepts, and run full queries against it.\r\n\r\n **Also new in v0.3:**\r\n\r\n - three-state drafts: draft → verified → published. Review without publishing.\r\n - queries match by alias too, not just exact titles (\"ML\" finds \"Machine Learning\").\r\n - frontmatter now carries quality signals: source count, single-source flag, source quality.\r\n\r\n **Same shape as before:**\r\n\r\n - works with local LLMs\r\n - great with Ollama and LM Studio\r\n - plain Markdown\r\n - Obsidian-friendly\r\n - no vector DB\r\n - no cloud required\r\n - multi-language \r\n\r\n Star it if you want to support local-first AI tools. Fork it if you want to build on it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6169215",
"id": 6169215,
"node_id": "GC_lADOD62WBtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeIn8",
"user": {
"login": "pjdurka",
"id": 263034374,
"node_id": "U_kgDOD62WBg",
"avatar_url": "https://avatars.githubusercontent.com/u/263034374?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pjdurka",
"html_url": "https://github.com/pjdurka",
"followers_url": "https://api.github.com/users/pjdurka/followers",
"following_url": "https://api.github.com/users/pjdurka/following{/other_user}",
"gists_url": "https://api.github.com/users/pjdurka/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pjdurka/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pjdurka/subscriptions",
"organizations_url": "https://api.github.com/users/pjdurka/orgs",
"repos_url": "https://api.github.com/users/pjdurka/repos",
"events_url": "https://api.github.com/users/pjdurka/events{/privacy}",
"received_events_url": "https://api.github.com/users/pjdurka/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-26T14:36:21Z",
"updated_at": "2026-05-26T14:36:21Z",
"body": "Great idea, thanks. I took it in a direction of maintainer knowledge for open-source projects, targeting the bus-factor problem: [Westner et al. (2025)](https://doi.org/10.1162/imag_a_00554) found bus factors of 1–3 across major neuroscience packages. \r\n\r\nBased explicitly upon your pattern, [maintainer-wiki-kit.md](https://gist.github.com/pjdurka/6793739c25db5c49a0386ab43f418d3f) has been working well for our new neuroinformatics project [IDE4EEG](https://gitlab.com/fuw_software/ide4eeg) and others :-)\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6169316",
"id": 6169316,
"node_id": "GC_lADOClDJEtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeIuQ",
"user": {
"login": "FCall75",
"id": 173066514,
"node_id": "U_kgDOClDJEg",
"avatar_url": "https://avatars.githubusercontent.com/u/173066514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FCall75",
"html_url": "https://github.com/FCall75",
"followers_url": "https://api.github.com/users/FCall75/followers",
"following_url": "https://api.github.com/users/FCall75/following{/other_user}",
"gists_url": "https://api.github.com/users/FCall75/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FCall75/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FCall75/subscriptions",
"organizations_url": "https://api.github.com/users/FCall75/orgs",
"repos_url": "https://api.github.com/users/FCall75/repos",
"events_url": "https://api.github.com/users/FCall75/events{/privacy}",
"received_events_url": "https://api.github.com/users/FCall75/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-26T15:50:19Z",
"updated_at": "2026-05-26T22:06:32Z",
"body": "In **Obsidian** with the **Open Copilot Chat** plugin, there's no need to use Claude Code; everything is done directly in **Obsidian** once the \"prompt\" has been copied there."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6170824",
"id": 6170824,
"node_id": "GC_lADOBlx-yNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeKMg",
"user": {
"login": "ulyssestenn",
"id": 106725064,
"node_id": "U_kgDOBlx-yA",
"avatar_url": "https://avatars.githubusercontent.com/u/106725064?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ulyssestenn",
"html_url": "https://github.com/ulyssestenn",
"followers_url": "https://api.github.com/users/ulyssestenn/followers",
"following_url": "https://api.github.com/users/ulyssestenn/following{/other_user}",
"gists_url": "https://api.github.com/users/ulyssestenn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ulyssestenn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ulyssestenn/subscriptions",
"organizations_url": "https://api.github.com/users/ulyssestenn/orgs",
"repos_url": "https://api.github.com/users/ulyssestenn/repos",
"events_url": "https://api.github.com/users/ulyssestenn/events{/privacy}",
"received_events_url": "https://api.github.com/users/ulyssestenn/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-27T14:24:21Z",
"updated_at": "2026-05-27T14:24:21Z",
"body": "This is a great idea. Worked beyond my expectations. I made a turnkey version where everything lives in a Git repo: [Funes](https://github.com/ulyssestenn/funes). I also made an [example library](https://github.com/ulyssestenn/funes-example-ai) where you can browse the kind of output it creates."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6170842",
"id": 6170842,
"node_id": "GC_lADOAAaOitoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeKNo",
"user": {
"login": "podviaznikov",
"id": 429706,
"node_id": "MDQ6VXNlcjQyOTcwNg==",
"avatar_url": "https://avatars.githubusercontent.com/u/429706?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/podviaznikov",
"html_url": "https://github.com/podviaznikov",
"followers_url": "https://api.github.com/users/podviaznikov/followers",
"following_url": "https://api.github.com/users/podviaznikov/following{/other_user}",
"gists_url": "https://api.github.com/users/podviaznikov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/podviaznikov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/podviaznikov/subscriptions",
"organizations_url": "https://api.github.com/users/podviaznikov/orgs",
"repos_url": "https://api.github.com/users/podviaznikov/repos",
"events_url": "https://api.github.com/users/podviaznikov/events{/privacy}",
"received_events_url": "https://api.github.com/users/podviaznikov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-27T14:35:42Z",
"updated_at": "2026-05-27T15:37:10Z",
"body": "In case anyone need to export their apple notes or bear notes into obsidian to do llm wiki: I've made [Obsidian Plugin ](https://community.obsidian.md/plugins/notes-exporter) and macOS real time exporter [app](https://apps.apple.com/us/app/notes-exporter/id6741618455?mt=12) with a quick [demo](https://www.loom.com/share/c2952eab6919416b8fa23d4177fd11d1). "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6171173",
"id": 6171173,
"node_id": "GC_lADOAcKXk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeKiU",
"user": {
"login": "noirblue",
"id": 29530003,
"node_id": "MDQ6VXNlcjI5NTMwMDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/29530003?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noirblue",
"html_url": "https://github.com/noirblue",
"followers_url": "https://api.github.com/users/noirblue/followers",
"following_url": "https://api.github.com/users/noirblue/following{/other_user}",
"gists_url": "https://api.github.com/users/noirblue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noirblue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noirblue/subscriptions",
"organizations_url": "https://api.github.com/users/noirblue/orgs",
"repos_url": "https://api.github.com/users/noirblue/repos",
"events_url": "https://api.github.com/users/noirblue/events{/privacy}",
"received_events_url": "https://api.github.com/users/noirblue/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-27T16:57:09Z",
"updated_at": "2026-05-27T16:57:09Z",
"body": "Been running Karpathy's LLM-Wiki pattern for five weeks now.\r\n\r\nThe compounding effect is real. Drop a paper, get a cross-linked wiki page. Ask a question, get a cited answer that gets filed back into the graph. The maintenance burden is near zero because the LLM does the bookkeeping.\r\n\r\nBut — when I tried to scale it beyond markdown notes, I hit a wall.\r\n\r\nPDFs needed PyMuPDF. Office docs needed python-docx. Video transcripts needed Whisper. Structured LLM outputs needed Instructor. Each tool had its own vault, its own SQLite schema, its own API surface. I built a 450-line Python glue layer to stitch them together.\r\n\r\nThe glue proved the problem: **fragmentation at the architecture layer.** Four vaults, four schemas, wikilink collisions, frontmatter drift, MCP namespace explosions. Glue is insufficient because it preserves the fragmentation; it just moves it around.\r\n\r\nSo I wrote a spec for unification at the architecture layer instead:\r\n\r\n**Mnemosyne** — a local-first semantic memory OS with a Rust core and Python satellites.\r\n\r\n- One vault: `raw/`, `wiki/`, `memory/`, `packs/`\r\n- One schema: SQLite `state.db` with `pages`, `links`, `jobs`, `conversations`, `audit_log`, `contradictions`\r\n- One API: MCP + REST + CLI from day one\r\n- Rust core: schema, job queue, graph traversal, API surface\r\n- Python satellites: PDF extraction, office docs, video/audio transcripts, LLM client glue, structured compilation\r\n- Two-tier compilation: fast model (30B) extracts concepts, heavy model (70B+) writes cross-linked articles\r\n- Audit engine: structural lint → contradiction detection → adversarial review\r\n- Provenance-first: every claim carries citation, every LLM call carries cost log\r\n\r\nThe Python satellites are permanent, not transitional. Rust cannot yet match Python's depth in document extraction (pymupdf, python-docx, Whisper) or structured LLM output (Instructor, Pydantic-AI). The Rust core spawns them as subprocesses, receives JSON, and integrates into the unified system.\r\n\r\nStatus: architecture spec complete. Seeking core contributors for Phase 1 implementation (SQLite schema, vault init, markdown ingestion, basic MCP server).\r\n\r\nSpec: https://github.com/noirblue/IsaacCLupus_mnemosyn_spec\r\n\r\nIf you've hit the same fragmentation wall trying to scale the LLM-Wiki pattern, I'd love to talk."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6171780",
"id": 6171780,
"node_id": "GC_lADOAB2DQtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeLIQ",
"user": {
"login": "ethanj",
"id": 1934146,
"node_id": "MDQ6VXNlcjE5MzQxNDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1934146?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ethanj",
"html_url": "https://github.com/ethanj",
"followers_url": "https://api.github.com/users/ethanj/followers",
"following_url": "https://api.github.com/users/ethanj/following{/other_user}",
"gists_url": "https://api.github.com/users/ethanj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ethanj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ethanj/subscriptions",
"organizations_url": "https://api.github.com/users/ethanj/orgs",
"repos_url": "https://api.github.com/users/ethanj/repos",
"events_url": "https://api.github.com/users/ethanj/events{/privacy}",
"received_events_url": "https://api.github.com/users/ethanj/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T01:01:18Z",
"updated_at": "2026-05-28T01:01:18Z",
"body": "> Been running Karpathy's LLM-Wiki pattern for five weeks now.\r\n> \r\n> The compounding effect is real. Drop a paper, get a cross-linked wiki page. Ask a question, get a cited answer that gets filed back into the graph. The maintenance burden is near zero because the LLM does the bookkeeping.\r\n> \r\n> But — when I tried to scale it beyond markdown notes, I hit a wall.\r\n> \r\n....\r\n> If you've hit the same fragmentation wall trying to scale the LLM-Wiki pattern, I'd love to talk.\r\n\r\n@noirblue \r\n\r\nI'm curious if you have taken a look at my repo - 1.3k stars so far.. its got some of those details covered and I would love to have more good brains on it, in particular people who are interested in how to make the architecture even better.\r\nI just dropped v0.8.0 with some cool new features... Graph/context layer , read-only visualization, Multimodal ingest, etc\r\n[https://github.com/atomicstrata/llm-wiki-compiler](https://github.com/atomicstrata/llm-wiki-compiler)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6171816",
"id": 6171816,
"node_id": "GC_lADODUzaidoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeLKg",
"user": {
"login": "AgriciDaniel",
"id": 223140489,
"node_id": "U_kgDODUzaiQ",
"avatar_url": "https://avatars.githubusercontent.com/u/223140489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AgriciDaniel",
"html_url": "https://github.com/AgriciDaniel",
"followers_url": "https://api.github.com/users/AgriciDaniel/followers",
"following_url": "https://api.github.com/users/AgriciDaniel/following{/other_user}",
"gists_url": "https://api.github.com/users/AgriciDaniel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AgriciDaniel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AgriciDaniel/subscriptions",
"organizations_url": "https://api.github.com/users/AgriciDaniel/orgs",
"repos_url": "https://api.github.com/users/AgriciDaniel/repos",
"events_url": "https://api.github.com/users/AgriciDaniel/events{/privacy}",
"received_events_url": "https://api.github.com/users/AgriciDaniel/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T02:17:23Z",
"updated_at": "2026-05-28T02:17:23Z",
"body": "
\r\n\r\nInstall:\r\n```bash\r\nbrew install gowtham0992/link/link\r\nlink demo\r\nlink serve link-demo\r\n```\r\n\r\nMCP:\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nWhat changed:\r\n```\r\n- link next for first-run prompts.\r\n- link health and /api/health for readiness checks.\r\n- MCP link_operations for interrupted-write inspection.\r\n- Better graph controls for larger wikis.\r\n- Persistent-cache diagnostics in status/health/benchmark.\r\n- More copyable prompts and recovery actions in the local UI.\r\n- Paste-safe CLI commands that work from any terminal directory.\r\n- Threaded local HTTP handling and request timeouts.\r\n- Expanded user-level smoke coverage for CLI, HTTP viewer, MCP stdio, and large wikis.\r\n```\r\n\r\nLinks:\r\n\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\nPyPI: https://pypi.org/project/link-mcp/\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6166832",
"id": 6166832,
"node_id": "GC_lADOARHz9toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeGTA",
"user": {
"login": "andkir1",
"id": 17953782,
"node_id": "MDQ6VXNlcjE3OTUzNzgy",
"avatar_url": "https://avatars.githubusercontent.com/u/17953782?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andkir1",
"html_url": "https://github.com/andkir1",
"followers_url": "https://api.github.com/users/andkir1/followers",
"following_url": "https://api.github.com/users/andkir1/following{/other_user}",
"gists_url": "https://api.github.com/users/andkir1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andkir1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andkir1/subscriptions",
"organizations_url": "https://api.github.com/users/andkir1/orgs",
"repos_url": "https://api.github.com/users/andkir1/repos",
"events_url": "https://api.github.com/users/andkir1/events{/privacy}",
"received_events_url": "https://api.github.com/users/andkir1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-24T23:45:45Z",
"updated_at": "2026-05-24T23:50:20Z",
"body": "I've been building a search-behavior-grounded knowledge tree since 2012 — synonym clustering plus hierarchical navigation built from actual query data, not academic taxonomy. Your maintenance insight is exactly right, and it reframes something I couldn't solve with human contributors alone. One question your bottom-up approach leaves open: what if the LLM also had a pre-built cognitive skeleton showing not just what exists but what's missing and in what order those gaps matter? \r\n\r\nWrote about this here: [https://medium.com/@thebooq/the-right-problem-89624f7a461a](https://medium.com/@thebooq/the-right-problem-89624f7a461a)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6167998",
"id": 6167998,
"node_id": "GC_lADOA5Ad-NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeHb4",
"user": {
"login": "ek0212",
"id": 59776504,
"node_id": "MDQ6VXNlcjU5Nzc2NTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/59776504?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ek0212",
"html_url": "https://github.com/ek0212",
"followers_url": "https://api.github.com/users/ek0212/followers",
"following_url": "https://api.github.com/users/ek0212/following{/other_user}",
"gists_url": "https://api.github.com/users/ek0212/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ek0212/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ek0212/subscriptions",
"organizations_url": "https://api.github.com/users/ek0212/orgs",
"repos_url": "https://api.github.com/users/ek0212/repos",
"events_url": "https://api.github.com/users/ek0212/events{/privacy}",
"received_events_url": "https://api.github.com/users/ek0212/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-25T12:50:13Z",
"updated_at": "2026-05-25T12:50:41Z",
"body": "Made a mini kit for anyone trying to get this idea off the ground in a formalized way with Obsidian + LLM of choice. This repo helps establish the curation layer on top of any domain you wish after just a few set up steps with your LLM. Personally used this repo for my \"second brain\" and resurrecting high school notes: https://github.com/ek0212/second-brain-template. All advice welcome!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6167999",
"id": 6167999,
"node_id": "GC_lADOCQIrh9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeHb8",
"user": {
"login": "Stephenusegithub",
"id": 151137159,
"node_id": "U_kgDOCQIrhw",
"avatar_url": "https://avatars.githubusercontent.com/u/151137159?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Stephenusegithub",
"html_url": "https://github.com/Stephenusegithub",
"followers_url": "https://api.github.com/users/Stephenusegithub/followers",
"following_url": "https://api.github.com/users/Stephenusegithub/following{/other_user}",
"gists_url": "https://api.github.com/users/Stephenusegithub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Stephenusegithub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Stephenusegithub/subscriptions",
"organizations_url": "https://api.github.com/users/Stephenusegithub/orgs",
"repos_url": "https://api.github.com/users/Stephenusegithub/repos",
"events_url": "https://api.github.com/users/Stephenusegithub/events{/privacy}",
"received_events_url": "https://api.github.com/users/Stephenusegithub/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-25T12:50:50Z",
"updated_at": "2026-05-25T12:50:50Z",
"body": "你好,邮件已收到~"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6168427",
"id": 6168427,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeH2s",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-25T23:15:44Z",
"updated_at": "2026-05-25T23:16:13Z",
"body": " **Synto v0.3.0 is out.**\r\n\r\n https://github.com/kytmanov/synto\r\n\r\n **Main addition**: an MCP server with 8 tools, ready to wire into Claude Code, Cursor, or any MCP client. Your AI assistant can search the wiki, read articles, look up concepts, and run full queries against it.\r\n\r\n **Also new in v0.3:**\r\n\r\n - three-state drafts: draft → verified → published. Review without publishing.\r\n - queries match by alias too, not just exact titles (\"ML\" finds \"Machine Learning\").\r\n - frontmatter now carries quality signals: source count, single-source flag, source quality.\r\n\r\n **Same shape as before:**\r\n\r\n - works with local LLMs\r\n - great with Ollama and LM Studio\r\n - plain Markdown\r\n - Obsidian-friendly\r\n - no vector DB\r\n - no cloud required\r\n - multi-language \r\n\r\n Star it if you want to support local-first AI tools. Fork it if you want to build on it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6169215",
"id": 6169215,
"node_id": "GC_lADOD62WBtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeIn8",
"user": {
"login": "pjdurka",
"id": 263034374,
"node_id": "U_kgDOD62WBg",
"avatar_url": "https://avatars.githubusercontent.com/u/263034374?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pjdurka",
"html_url": "https://github.com/pjdurka",
"followers_url": "https://api.github.com/users/pjdurka/followers",
"following_url": "https://api.github.com/users/pjdurka/following{/other_user}",
"gists_url": "https://api.github.com/users/pjdurka/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pjdurka/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pjdurka/subscriptions",
"organizations_url": "https://api.github.com/users/pjdurka/orgs",
"repos_url": "https://api.github.com/users/pjdurka/repos",
"events_url": "https://api.github.com/users/pjdurka/events{/privacy}",
"received_events_url": "https://api.github.com/users/pjdurka/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-26T14:36:21Z",
"updated_at": "2026-05-26T14:36:21Z",
"body": "Great idea, thanks. I took it in a direction of maintainer knowledge for open-source projects, targeting the bus-factor problem: [Westner et al. (2025)](https://doi.org/10.1162/imag_a_00554) found bus factors of 1–3 across major neuroscience packages. \r\n\r\nBased explicitly upon your pattern, [maintainer-wiki-kit.md](https://gist.github.com/pjdurka/6793739c25db5c49a0386ab43f418d3f) has been working well for our new neuroinformatics project [IDE4EEG](https://gitlab.com/fuw_software/ide4eeg) and others :-)\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6169316",
"id": 6169316,
"node_id": "GC_lADOClDJEtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeIuQ",
"user": {
"login": "FCall75",
"id": 173066514,
"node_id": "U_kgDOClDJEg",
"avatar_url": "https://avatars.githubusercontent.com/u/173066514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FCall75",
"html_url": "https://github.com/FCall75",
"followers_url": "https://api.github.com/users/FCall75/followers",
"following_url": "https://api.github.com/users/FCall75/following{/other_user}",
"gists_url": "https://api.github.com/users/FCall75/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FCall75/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FCall75/subscriptions",
"organizations_url": "https://api.github.com/users/FCall75/orgs",
"repos_url": "https://api.github.com/users/FCall75/repos",
"events_url": "https://api.github.com/users/FCall75/events{/privacy}",
"received_events_url": "https://api.github.com/users/FCall75/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-26T15:50:19Z",
"updated_at": "2026-05-26T22:06:32Z",
"body": "In **Obsidian** with the **Open Copilot Chat** plugin, there's no need to use Claude Code; everything is done directly in **Obsidian** once the \"prompt\" has been copied there."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6170824",
"id": 6170824,
"node_id": "GC_lADOBlx-yNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeKMg",
"user": {
"login": "ulyssestenn",
"id": 106725064,
"node_id": "U_kgDOBlx-yA",
"avatar_url": "https://avatars.githubusercontent.com/u/106725064?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ulyssestenn",
"html_url": "https://github.com/ulyssestenn",
"followers_url": "https://api.github.com/users/ulyssestenn/followers",
"following_url": "https://api.github.com/users/ulyssestenn/following{/other_user}",
"gists_url": "https://api.github.com/users/ulyssestenn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ulyssestenn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ulyssestenn/subscriptions",
"organizations_url": "https://api.github.com/users/ulyssestenn/orgs",
"repos_url": "https://api.github.com/users/ulyssestenn/repos",
"events_url": "https://api.github.com/users/ulyssestenn/events{/privacy}",
"received_events_url": "https://api.github.com/users/ulyssestenn/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-27T14:24:21Z",
"updated_at": "2026-05-27T14:24:21Z",
"body": "This is a great idea. Worked beyond my expectations. I made a turnkey version where everything lives in a Git repo: [Funes](https://github.com/ulyssestenn/funes). I also made an [example library](https://github.com/ulyssestenn/funes-example-ai) where you can browse the kind of output it creates."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6170842",
"id": 6170842,
"node_id": "GC_lADOAAaOitoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeKNo",
"user": {
"login": "podviaznikov",
"id": 429706,
"node_id": "MDQ6VXNlcjQyOTcwNg==",
"avatar_url": "https://avatars.githubusercontent.com/u/429706?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/podviaznikov",
"html_url": "https://github.com/podviaznikov",
"followers_url": "https://api.github.com/users/podviaznikov/followers",
"following_url": "https://api.github.com/users/podviaznikov/following{/other_user}",
"gists_url": "https://api.github.com/users/podviaznikov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/podviaznikov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/podviaznikov/subscriptions",
"organizations_url": "https://api.github.com/users/podviaznikov/orgs",
"repos_url": "https://api.github.com/users/podviaznikov/repos",
"events_url": "https://api.github.com/users/podviaznikov/events{/privacy}",
"received_events_url": "https://api.github.com/users/podviaznikov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-27T14:35:42Z",
"updated_at": "2026-05-27T15:37:10Z",
"body": "In case anyone need to export their apple notes or bear notes into obsidian to do llm wiki: I've made [Obsidian Plugin ](https://community.obsidian.md/plugins/notes-exporter) and macOS real time exporter [app](https://apps.apple.com/us/app/notes-exporter/id6741618455?mt=12) with a quick [demo](https://www.loom.com/share/c2952eab6919416b8fa23d4177fd11d1). "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6171173",
"id": 6171173,
"node_id": "GC_lADOAcKXk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeKiU",
"user": {
"login": "noirblue",
"id": 29530003,
"node_id": "MDQ6VXNlcjI5NTMwMDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/29530003?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noirblue",
"html_url": "https://github.com/noirblue",
"followers_url": "https://api.github.com/users/noirblue/followers",
"following_url": "https://api.github.com/users/noirblue/following{/other_user}",
"gists_url": "https://api.github.com/users/noirblue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noirblue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noirblue/subscriptions",
"organizations_url": "https://api.github.com/users/noirblue/orgs",
"repos_url": "https://api.github.com/users/noirblue/repos",
"events_url": "https://api.github.com/users/noirblue/events{/privacy}",
"received_events_url": "https://api.github.com/users/noirblue/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-27T16:57:09Z",
"updated_at": "2026-05-27T16:57:09Z",
"body": "Been running Karpathy's LLM-Wiki pattern for five weeks now.\r\n\r\nThe compounding effect is real. Drop a paper, get a cross-linked wiki page. Ask a question, get a cited answer that gets filed back into the graph. The maintenance burden is near zero because the LLM does the bookkeeping.\r\n\r\nBut — when I tried to scale it beyond markdown notes, I hit a wall.\r\n\r\nPDFs needed PyMuPDF. Office docs needed python-docx. Video transcripts needed Whisper. Structured LLM outputs needed Instructor. Each tool had its own vault, its own SQLite schema, its own API surface. I built a 450-line Python glue layer to stitch them together.\r\n\r\nThe glue proved the problem: **fragmentation at the architecture layer.** Four vaults, four schemas, wikilink collisions, frontmatter drift, MCP namespace explosions. Glue is insufficient because it preserves the fragmentation; it just moves it around.\r\n\r\nSo I wrote a spec for unification at the architecture layer instead:\r\n\r\n**Mnemosyne** — a local-first semantic memory OS with a Rust core and Python satellites.\r\n\r\n- One vault: `raw/`, `wiki/`, `memory/`, `packs/`\r\n- One schema: SQLite `state.db` with `pages`, `links`, `jobs`, `conversations`, `audit_log`, `contradictions`\r\n- One API: MCP + REST + CLI from day one\r\n- Rust core: schema, job queue, graph traversal, API surface\r\n- Python satellites: PDF extraction, office docs, video/audio transcripts, LLM client glue, structured compilation\r\n- Two-tier compilation: fast model (30B) extracts concepts, heavy model (70B+) writes cross-linked articles\r\n- Audit engine: structural lint → contradiction detection → adversarial review\r\n- Provenance-first: every claim carries citation, every LLM call carries cost log\r\n\r\nThe Python satellites are permanent, not transitional. Rust cannot yet match Python's depth in document extraction (pymupdf, python-docx, Whisper) or structured LLM output (Instructor, Pydantic-AI). The Rust core spawns them as subprocesses, receives JSON, and integrates into the unified system.\r\n\r\nStatus: architecture spec complete. Seeking core contributors for Phase 1 implementation (SQLite schema, vault init, markdown ingestion, basic MCP server).\r\n\r\nSpec: https://github.com/noirblue/IsaacCLupus_mnemosyn_spec\r\n\r\nIf you've hit the same fragmentation wall trying to scale the LLM-Wiki pattern, I'd love to talk."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6171780",
"id": 6171780,
"node_id": "GC_lADOAB2DQtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeLIQ",
"user": {
"login": "ethanj",
"id": 1934146,
"node_id": "MDQ6VXNlcjE5MzQxNDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/1934146?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ethanj",
"html_url": "https://github.com/ethanj",
"followers_url": "https://api.github.com/users/ethanj/followers",
"following_url": "https://api.github.com/users/ethanj/following{/other_user}",
"gists_url": "https://api.github.com/users/ethanj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ethanj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ethanj/subscriptions",
"organizations_url": "https://api.github.com/users/ethanj/orgs",
"repos_url": "https://api.github.com/users/ethanj/repos",
"events_url": "https://api.github.com/users/ethanj/events{/privacy}",
"received_events_url": "https://api.github.com/users/ethanj/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T01:01:18Z",
"updated_at": "2026-05-28T01:01:18Z",
"body": "> Been running Karpathy's LLM-Wiki pattern for five weeks now.\r\n> \r\n> The compounding effect is real. Drop a paper, get a cross-linked wiki page. Ask a question, get a cited answer that gets filed back into the graph. The maintenance burden is near zero because the LLM does the bookkeeping.\r\n> \r\n> But — when I tried to scale it beyond markdown notes, I hit a wall.\r\n> \r\n....\r\n> If you've hit the same fragmentation wall trying to scale the LLM-Wiki pattern, I'd love to talk.\r\n\r\n@noirblue \r\n\r\nI'm curious if you have taken a look at my repo - 1.3k stars so far.. its got some of those details covered and I would love to have more good brains on it, in particular people who are interested in how to make the architecture even better.\r\nI just dropped v0.8.0 with some cool new features... Graph/context layer , read-only visualization, Multimodal ingest, etc\r\n[https://github.com/atomicstrata/llm-wiki-compiler](https://github.com/atomicstrata/llm-wiki-compiler)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6171816",
"id": 6171816,
"node_id": "GC_lADODUzaidoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeLKg",
"user": {
"login": "AgriciDaniel",
"id": 223140489,
"node_id": "U_kgDODUzaiQ",
"avatar_url": "https://avatars.githubusercontent.com/u/223140489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AgriciDaniel",
"html_url": "https://github.com/AgriciDaniel",
"followers_url": "https://api.github.com/users/AgriciDaniel/followers",
"following_url": "https://api.github.com/users/AgriciDaniel/following{/other_user}",
"gists_url": "https://api.github.com/users/AgriciDaniel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AgriciDaniel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AgriciDaniel/subscriptions",
"organizations_url": "https://api.github.com/users/AgriciDaniel/orgs",
"repos_url": "https://api.github.com/users/AgriciDaniel/repos",
"events_url": "https://api.github.com/users/AgriciDaniel/events{/privacy}",
"received_events_url": "https://api.github.com/users/AgriciDaniel/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T02:17:23Z",
"updated_at": "2026-05-28T02:17:23Z",
"body": " \n\nThis pattern crystallized something a lot of us were circling. I ended up building a full open-source implementation of it as my daily driver: **[claude-obsidian](https://github.com/AgriciDaniel/claude-obsidian)** (MIT, runs in Claude Code). Same three layers you describe, raw → wiki → schema, with `index.md` for navigation and an append-only `log.md`, and the model maintains the wiki while you pick sources and ask questions.\n\nHere are two real vaults it built, the graph is generated, not hand-linked:\n\n| | |\n|---|---|\n|  |  |\n\nA few questions in this thread are exactly the ones it tries to answer:\n\n- **New page vs. edit an existing one** (@alinawab): on each ingest it extracts entities/concepts, searches the existing vault first, and edits + cross-links on a match, only creating a page when nothing fits. Wikilinks and contradiction flags are added automatically.\n- **Where it starts fighting you**: the one that bit me was *concurrent writes* (two agents ingesting at once could corrupt a page mid-write); v1.7 added per-file locking to close that. The other is retrieval drift on big vaults, handled with optional hybrid retrieval (contextual prefix + BM25 + rerank, per Anthropic's contextual-retrieval work).\n- **Sharing with a team** (@geetansharora): it's just plain Markdown in a git repo, no DB or MCP server required, so a team shares it like code, clone the vault and everyone's Claude reads the same files.\n\nFree and MIT. Two-minute walkthrough + repo:\n- 🎥 Video: https://www.youtube.com/watch?v=I2hXQ-_qzRk\n- ⭐ Repo: https://github.com/AgriciDaniel/claude-obsidian\n- 📝 Latest release (v1.9 \"Compound Vault\"): https://github.com/AgriciDaniel/claude-obsidian/releases/tag/v1.9.2\n\nThanks for the writeup, @karpathy, it's shaped how I think about this.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172330",
"id": 6172330,
"node_id": "GC_lADOAnU_ztoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeLqo",
"user": {
"login": "ranga291257",
"id": 41238478,
"node_id": "MDQ6VXNlcjQxMjM4NDc4",
"avatar_url": "https://avatars.githubusercontent.com/u/41238478?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ranga291257",
"html_url": "https://github.com/ranga291257",
"followers_url": "https://api.github.com/users/ranga291257/followers",
"following_url": "https://api.github.com/users/ranga291257/following{/other_user}",
"gists_url": "https://api.github.com/users/ranga291257/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ranga291257/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ranga291257/subscriptions",
"organizations_url": "https://api.github.com/users/ranga291257/orgs",
"repos_url": "https://api.github.com/users/ranga291257/repos",
"events_url": "https://api.github.com/users/ranga291257/events{/privacy}",
"received_events_url": "https://api.github.com/users/ranga291257/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T10:07:22Z",
"updated_at": "2026-05-28T10:57:11Z",
"body": "Thanks for this write-up, @karpathy. It helped me connect and contextualize many years of personal OneNote documentation that had accumulated as scattered knowledge.\r\n\r\nI have also started applying this idea to a fictional manufacturing plant use case: a web interface that ingests operating, maintenance, engineering and troubleshooting documents that normally reside in different places and must be manually pieced together when a plant problem occurs.\r\n\r\nThe aim is to create an evolving knowledge layer that helps users connect information across documents during troubleshooting, while allowing them to select and run local LLM models of their choice.\r\n\r\nFor industrial applications, this approach is especially valuable because useful knowledge is rarely contained in one document; it emerges from the relationships among operating history, equipment records, procedures, drawings and past decisions.\r\n
\n\nThis pattern crystallized something a lot of us were circling. I ended up building a full open-source implementation of it as my daily driver: **[claude-obsidian](https://github.com/AgriciDaniel/claude-obsidian)** (MIT, runs in Claude Code). Same three layers you describe, raw → wiki → schema, with `index.md` for navigation and an append-only `log.md`, and the model maintains the wiki while you pick sources and ask questions.\n\nHere are two real vaults it built, the graph is generated, not hand-linked:\n\n| | |\n|---|---|\n|  |  |\n\nA few questions in this thread are exactly the ones it tries to answer:\n\n- **New page vs. edit an existing one** (@alinawab): on each ingest it extracts entities/concepts, searches the existing vault first, and edits + cross-links on a match, only creating a page when nothing fits. Wikilinks and contradiction flags are added automatically.\n- **Where it starts fighting you**: the one that bit me was *concurrent writes* (two agents ingesting at once could corrupt a page mid-write); v1.7 added per-file locking to close that. The other is retrieval drift on big vaults, handled with optional hybrid retrieval (contextual prefix + BM25 + rerank, per Anthropic's contextual-retrieval work).\n- **Sharing with a team** (@geetansharora): it's just plain Markdown in a git repo, no DB or MCP server required, so a team shares it like code, clone the vault and everyone's Claude reads the same files.\n\nFree and MIT. Two-minute walkthrough + repo:\n- 🎥 Video: https://www.youtube.com/watch?v=I2hXQ-_qzRk\n- ⭐ Repo: https://github.com/AgriciDaniel/claude-obsidian\n- 📝 Latest release (v1.9 \"Compound Vault\"): https://github.com/AgriciDaniel/claude-obsidian/releases/tag/v1.9.2\n\nThanks for the writeup, @karpathy, it's shaped how I think about this.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172330",
"id": 6172330,
"node_id": "GC_lADOAnU_ztoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeLqo",
"user": {
"login": "ranga291257",
"id": 41238478,
"node_id": "MDQ6VXNlcjQxMjM4NDc4",
"avatar_url": "https://avatars.githubusercontent.com/u/41238478?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ranga291257",
"html_url": "https://github.com/ranga291257",
"followers_url": "https://api.github.com/users/ranga291257/followers",
"following_url": "https://api.github.com/users/ranga291257/following{/other_user}",
"gists_url": "https://api.github.com/users/ranga291257/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ranga291257/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ranga291257/subscriptions",
"organizations_url": "https://api.github.com/users/ranga291257/orgs",
"repos_url": "https://api.github.com/users/ranga291257/repos",
"events_url": "https://api.github.com/users/ranga291257/events{/privacy}",
"received_events_url": "https://api.github.com/users/ranga291257/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T10:07:22Z",
"updated_at": "2026-05-28T10:57:11Z",
"body": "Thanks for this write-up, @karpathy. It helped me connect and contextualize many years of personal OneNote documentation that had accumulated as scattered knowledge.\r\n\r\nI have also started applying this idea to a fictional manufacturing plant use case: a web interface that ingests operating, maintenance, engineering and troubleshooting documents that normally reside in different places and must be manually pieced together when a plant problem occurs.\r\n\r\nThe aim is to create an evolving knowledge layer that helps users connect information across documents during troubleshooting, while allowing them to select and run local LLM models of their choice.\r\n\r\nFor industrial applications, this approach is especially valuable because useful knowledge is rarely contained in one document; it emerges from the relationships among operating history, equipment records, procedures, drawings and past decisions.\r\n \r\nyou may look in to my linkedin post as well https://www.linkedin.com/feed/update/urn:li:activity:7465711718795771904/"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172540",
"id": 6172540,
"node_id": "GC_lADOAEkH8toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeL3w",
"user": {
"login": "alirezabbasi",
"id": 4786162,
"node_id": "MDQ6VXNlcjQ3ODYxNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4786162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alirezabbasi",
"html_url": "https://github.com/alirezabbasi",
"followers_url": "https://api.github.com/users/alirezabbasi/followers",
"following_url": "https://api.github.com/users/alirezabbasi/following{/other_user}",
"gists_url": "https://api.github.com/users/alirezabbasi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alirezabbasi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alirezabbasi/subscriptions",
"organizations_url": "https://api.github.com/users/alirezabbasi/orgs",
"repos_url": "https://api.github.com/users/alirezabbasi/repos",
"events_url": "https://api.github.com/users/alirezabbasi/events{/privacy}",
"received_events_url": "https://api.github.com/users/alirezabbasi/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T12:41:55Z",
"updated_at": "2026-05-28T12:41:55Z",
"body": "https://github.com/alirezabbasi/echel/releases/tag/v0.2.0\r\n\r\nI just released **Echel v0.2.0**.\r\n\r\nEchel started from the same core insight behind Andrej Karpathy’s “LLM Wiki” idea: AI workflows should not keep rediscovering knowledge from scratch every session.\r\n\r\nThe LLM Wiki pattern says: instead of relying only on RAG or chat history, let AI continuously maintain a structured, interlinked wiki that compounds over time.\r\n\r\nEchel takes that idea into software product creation.\r\n\r\nIt is a platform where a domain expert defines a problem, intended solution, constraints, risks, MVP, stack, and direction, and Echel continuously turns that intent into:\r\n\r\n- clarified requirements\r\n- product architecture\r\n- roadmap\r\n- executable work\r\n- graph-backed AI agent packets\r\n- review reports\r\n- readiness checks\r\n- proof packs\r\n- compounding project intelligence\r\n\r\nThe key idea is simple:\r\n\r\n**The product should not lose memory every time the AI context window resets.**\r\n\r\nIn v0.2.0, Echel now includes:\r\n\r\n- product-first initialization\r\n- root-level product `wiki/`\r\n- internal `echel-core/` runtime split\r\n- product-owner commands like `define`, `clarify`, `plan`, `build`, `review`, `steer`, and `status`\r\n- typed product intelligence graph\r\n- agent work packets\r\n- product cockpit\r\n- milestone/readiness gates\r\n- proof packs and release summaries\r\n\r\nThe direction is to make Echel a product-creation operating system for AI-native development.\r\n\r\nA business owner or domain expert should be able to steer the product through intent and decisions, while Echel and AI agents handle the structured execution loop.\r\n\r\nHuge inspiration from the LLM Wiki pattern:\r\nhttps://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f\r\n\r\nEchel v0.2.0 is the first version where that idea becomes a fuller software-development workflow:\r\n\r\n**intent -> memory -> graph -> plan -> build packet -> implementation -> review -> readiness -> updated intelligence**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172613",
"id": 6172613,
"node_id": "GC_lADOAIC6hNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeL8U",
"user": {
"login": "brtrx",
"id": 8436356,
"node_id": "MDQ6VXNlcjg0MzYzNTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8436356?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brtrx",
"html_url": "https://github.com/brtrx",
"followers_url": "https://api.github.com/users/brtrx/followers",
"following_url": "https://api.github.com/users/brtrx/following{/other_user}",
"gists_url": "https://api.github.com/users/brtrx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brtrx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brtrx/subscriptions",
"organizations_url": "https://api.github.com/users/brtrx/orgs",
"repos_url": "https://api.github.com/users/brtrx/repos",
"events_url": "https://api.github.com/users/brtrx/events{/privacy}",
"received_events_url": "https://api.github.com/users/brtrx/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T13:34:55Z",
"updated_at": "2026-05-28T13:34:55Z",
"body": "Built a lint extension to combat ingestion order bias in wikis with 50+ sources: [LLM Wiki: A Bias-Aware Stateful Lint](https://gist.github.com/brtrx/ba595fd01e344d797cb66d34d982ecad)\r\n\r\nTwo problems emerge at scale — context limits kill single-pass lint, and ingestion order biases the wiki toward earlier sources. The extension runs lint in batches of 5 with a persistent scratchpad across sessions, and uses a randomised (not ingestion-order) source sequence to surface cross-cutting contradictions that ordered passes miss.\r\n\r\nDrops into an existing CLAUDE.md. Doesn't fix framing bias baked in at ingest time, but repairs the structural layer reliably."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172973",
"id": 6172973,
"node_id": "GC_lADOAcKXk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeMS0",
"user": {
"login": "noirblue",
"id": 29530003,
"node_id": "MDQ6VXNlcjI5NTMwMDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/29530003?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noirblue",
"html_url": "https://github.com/noirblue",
"followers_url": "https://api.github.com/users/noirblue/followers",
"following_url": "https://api.github.com/users/noirblue/following{/other_user}",
"gists_url": "https://api.github.com/users/noirblue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noirblue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noirblue/subscriptions",
"organizations_url": "https://api.github.com/users/noirblue/orgs",
"repos_url": "https://api.github.com/users/noirblue/repos",
"events_url": "https://api.github.com/users/noirblue/events{/privacy}",
"received_events_url": "https://api.github.com/users/noirblue/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T17:20:43Z",
"updated_at": "2026-05-28T17:20:43Z",
"body": "A few people have asked: isn't this just a wiki compiler with extra steps?\r\n\r\nNo. Wiki compilation is one layer of seven. The broader goal is a **knowledge lifecycle**, not just ingestion:\r\n\r\n- **Agent memory:** `memory/inbox/` → `memory/committed/` — propose, review, link, decay\r\n- **Conversation history:** token-budgeted, cross-session, queryable\r\n- **Dual-node deployment:** Foundry (batch compile/audit) + Frontline (interactive serve)\r\n- **Audit as infrastructure:** every claim traced to source, every LLM call logged with cost/hash\r\n- **Pack exports:** agent-ready subsets of the graph for action\r\n\r\nThe architecture uses a **Rust core** for the performance-critical path — schema, job queue, graph traversal, API surface — while Python satellites handle document extraction and LLM orchestration where Python's ecosystem has no equal. The split is permanent, not transitional.\r\n\r\nThe LLM-Wiki pattern proved that compounding works. Mnemosyne asks: what happens when you treat that pattern as **infrastructure** — with schemas, queues, provenance, and deployment topologies — rather than as content in markdown files?\r\n\r\nSpec: https://github.com/noirblue/IsaacCLupus_mnemosyn_spec"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6173827",
"id": 6173827,
"node_id": "GC_lADOA4rqIdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeNIM",
"user": {
"login": "iddingszhz",
"id": 59435553,
"node_id": "MDQ6VXNlcjU5NDM1NTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/59435553?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iddingszhz",
"html_url": "https://github.com/iddingszhz",
"followers_url": "https://api.github.com/users/iddingszhz/followers",
"following_url": "https://api.github.com/users/iddingszhz/following{/other_user}",
"gists_url": "https://api.github.com/users/iddingszhz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iddingszhz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iddingszhz/subscriptions",
"organizations_url": "https://api.github.com/users/iddingszhz/orgs",
"repos_url": "https://api.github.com/users/iddingszhz/repos",
"events_url": "https://api.github.com/users/iddingszhz/events{/privacy}",
"received_events_url": "https://api.github.com/users/iddingszhz/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-29T09:14:45Z",
"updated_at": "2026-05-29T09:14:45Z",
"body": "我按照 Karpathy 的思路开发了一个日记库,充分运用 Karpathy 的 **\"固定协议 + 可插拔模块\"** 架构。\r\n\r\n用在自我认知上,比用在代码上更让人震撼。\r\n\r\n**CLAUDE.md** 作为行为协议来约束 AI,而不是堆提示词。把 AI 从一个\"聊天对象\"变成了一只严格执行 SOP 的 analytic engine。\r\n\r\n同时采用 **协议和人格分离** 的设计:协议保证行为可预期、可迁移(换 AI 客户端也不崩),人格随时换文件就能换风格——这是系统工程思维在个人管理上的降维打击。\r\n\r\n日记架构按照 **L0 → L4 的分层深化**:\r\n\r\n- 大多数日记工具停留在 L0(记录)\r\n- 好一点的做到 L1(周回顾)\r\n\r\n而我把跨时间复利对比(L3 / L4)直接做成内建功能。当日记从\"散装存档\"变成\"可检索的认知档案\",它就不再是日记了——**是一个人的增量自我进化系统**。\r\n\r\n👉 https://github.com/iddingszhz/Life_Daliy_OS"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6174117",
"id": 6174117,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeNaU",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-29T13:31:03Z",
"updated_at": "2026-05-29T13:31:03Z",
"body": "Synthadoc v0.6.0 is out.\r\n\r\nTwo new features focused on content health and portability:\r\n\r\n1. Five-State Page Lifecycle: pages now move through five states: draft → active → stale → contradicted → archived. Transitions are mostly automatic: a clean lint pass promotes draft to active; a SHA-256 hash mismatch on the source file marks the page stale; ingesting a conflicting source marks it contradicted. Every transition is permanently logged with who triggered it, when, and why, so you have an auditable trail of when content was reviewed, not just who last touched the file. Manual overrides (lifecycle activate, archive, restore) are there when automation isn't enough.\r\n\r\n → Quick-start demo - Step 8 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-8--manage-page-lifecycle)\r\n\r\n\r\n2. Wiki Export: four formats in one command: synthadoc export -f . llms.txt and llms-full.txt follow the llmstxt.org spec for feeding the wiki into downstream LLM workflows. \"graphml\" exports the wikilink graph with node attributes (status, confidence, citation count) for analysis in Gephi or yEd. \"json\" export includes three fields no generic wiki export produces: every paragraph traces back to exact source lines (claims[] -file name plus line range, not just \"from document X\"); the complete state-transition audit log (lifecycle_history[] - when the page was drafted, reviewed, went stale, re-ingested); and the per-page API cost to compile it (ingest_cost_usd).\r\n\r\n → Quick-start demo - Step 21 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-21--export-your-wiki)\r\n\r\n\r\n3. Also shipping in v0.6.0: refined Obsidian plugin UX across lifecycle and export modals.\r\n\r\n \r\nIf any of this is useful or you have thoughts on the direction, feedback is very welcome, and a ⭐ always helps the project reach more people.\r\n\r\n 👉 https://github.com/axoviq-ai/synthadoc"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6174898",
"id": 6174898,
"node_id": "GC_lADOAmYaO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeOLI",
"user": {
"login": "Yarmoluk",
"id": 40245819,
"node_id": "MDQ6VXNlcjQwMjQ1ODE5",
"avatar_url": "https://avatars.githubusercontent.com/u/40245819?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yarmoluk",
"html_url": "https://github.com/Yarmoluk",
"followers_url": "https://api.github.com/users/Yarmoluk/followers",
"following_url": "https://api.github.com/users/Yarmoluk/following{/other_user}",
"gists_url": "https://api.github.com/users/Yarmoluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Yarmoluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yarmoluk/subscriptions",
"organizations_url": "https://api.github.com/users/Yarmoluk/orgs",
"repos_url": "https://api.github.com/users/Yarmoluk/repos",
"events_url": "https://api.github.com/users/Yarmoluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Yarmoluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-30T03:32:11Z",
"updated_at": "2026-05-30T03:32:11Z",
"body": "Behavioral protocol is correct\r\n\r\n\r\nRespectfully,\r\n\r\nDan Yarmoluk\r\n\r\nOn Fri, May 29, 2026 at 8:31 AM Paul Chen ***@***.***> wrote:\r\n\r\n> ***@***.**** commented on this gist.\r\n> ------------------------------\r\n>\r\n> Synthadoc v0.6.0 is out.\r\n>\r\n> Two new features focused on content health and portability:\r\n>\r\n> 1. Five-State Page Lifecycle: pages now move through five states:\r\n> draft → active → stale → contradicted → archived. Transitions are mostly\r\n> automatic: a clean lint pass promotes draft to active; a SHA-256 hash\r\n> mismatch on the source file marks the page stale; ingesting a conflicting\r\n> source marks it contradicted. Every transition is permanently logged with\r\n> who triggered it, when, and why, so you have an auditable trail of when\r\n> content was reviewed, not just who last touched the file. Manual overrides\r\n> (lifecycle activate, archive, restore) are there when automation isn't\r\n> enough.\r\n>\r\n> → Quick-start demo - Step 8 (\r\n> https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-8--manage-page-lifecycle\r\n> )\r\n>\r\n> 2. Wiki Export: four formats in one command: synthadoc export -f .\r\n> llms.txt and llms-full.txt follow the llmstxt.org spec for feeding the\r\n> wiki into downstream LLM workflows. \"graphml\" exports the wikilink graph\r\n> with node attributes (status, confidence, citation count) for analysis in\r\n> Gephi or yEd. \"json\" export includes three fields no generic wiki export\r\n> produces: every paragraph traces back to exact source lines (claims[] -file\r\n> name plus line range, not just \"from document X\"); the complete\r\n> state-transition audit log (lifecycle_history[] - when the page was\r\n> drafted, reviewed, went stale, re-ingested); and the per-page API cost to\r\n> compile it (ingest_cost_usd).\r\n>\r\n> → Quick-start demo - Step 21 (\r\n> https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-21--export-your-wiki\r\n> )\r\n>\r\n> 3. Also shipping in v0.6.0: refined Obsidian plugin UX across\r\n> lifecycle and export modals.\r\n>\r\n> If any of this is useful or you have thoughts on the direction, feedback\r\n> is very welcome, and a ⭐ always helps the project reach more people.\r\n>\r\n> 👉 https://github.com/axoviq-ai/synthadoc\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> \r\n> or unsubscribe\r\n> \r\n> .\r\n> You are receiving this email because you commented on the thread.\r\n>\r\n> Triage notifications on the go with GitHub Mobile for iOS\r\n> \r\n> or Android\r\n> \r\n> .\r\n>\r\n>\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6175904",
"id": 6175904,
"node_id": "GC_lADOALUbLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBePKA",
"user": {
"login": "theafh",
"id": 11868972,
"node_id": "MDQ6VXNlcjExODY4OTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11868972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theafh",
"html_url": "https://github.com/theafh",
"followers_url": "https://api.github.com/users/theafh/followers",
"following_url": "https://api.github.com/users/theafh/following{/other_user}",
"gists_url": "https://api.github.com/users/theafh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theafh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theafh/subscriptions",
"organizations_url": "https://api.github.com/users/theafh/orgs",
"repos_url": "https://api.github.com/users/theafh/repos",
"events_url": "https://api.github.com/users/theafh/events{/privacy}",
"received_events_url": "https://api.github.com/users/theafh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-30T23:58:58Z",
"updated_at": "2026-05-30T23:59:59Z",
"body": " This wiki pattern worked so well for *knowledge* that I tried the same\r\n plain-markdown-over-LLM idea on the other half of the AI-developer workflow!\r\n If the /wiki is a Confluence you can talk to, /task is the JIRA/Trello version:\r\n a backlog that lives next to the code as files, not in a SaaS.\r\n\r\n Same principles, different artifact:\r\n\r\n - **One self-contained markdown file per task**, written so a single-shot agent\r\n can pick it up and implement it with no chat context.\r\n - **Filesystem-native and git-tracked**: `tasks/` for open work, `tasks/archive/`\r\n for done/dropped, scope in the filename. No lock-in, diffs, and history for free.\r\n - **A bundled linter keeps it healthy** — naming, frontmatter, status↔location,\r\n links, dates (the task analogue of the wiki's lint pass).\r\n - **A small lifecycle of skills** instead of one mega-prompt:\r\n create → check → implement → audit → finish, plus a whole-tree fix/health pass.\r\n\r\n Open-source, MIT License, Multi-agent skill deployment:\r\n https://github.com/theafh/ai-modules/tree/main/plugins/ai_dev/skills"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176154",
"id": 6176154,
"node_id": "GC_lADOD9LxrdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBePZo",
"user": {
"login": "hegu-1",
"id": 265482669,
"node_id": "U_kgDOD9LxrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/265482669?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hegu-1",
"html_url": "https://github.com/hegu-1",
"followers_url": "https://api.github.com/users/hegu-1/followers",
"following_url": "https://api.github.com/users/hegu-1/following{/other_user}",
"gists_url": "https://api.github.com/users/hegu-1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hegu-1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hegu-1/subscriptions",
"organizations_url": "https://api.github.com/users/hegu-1/orgs",
"repos_url": "https://api.github.com/users/hegu-1/repos",
"events_url": "https://api.github.com/users/hegu-1/events{/privacy}",
"received_events_url": "https://api.github.com/users/hegu-1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T05:47:16Z",
"updated_at": "2026-05-31T05:47:16Z",
"body": "Been circling the same three-layer shape (raw → wiki → outputs, markdown, pre-compiled, wiki-linked) — but I came at it from a different angle: not \"knowledge base as a product,\" more \"a container for my own continuity\" that any model loads to stay in phase with me across sessions and machines.\n\nThe one place I deliberately diverge from your setup: I *don't* let it drift toward \"none written by me directly.\" The model writes the derivative / linking / consistency layer; the framing and the decisions stay authored by me — otherwise the continuity quietly stops being mine.\n\nWhich makes me wonder about something bigger than a second brain: if everyone runs a personal container like this and the model becomes the interchangeable part, the interesting unit isn't one general model anymore — it's (person × container × commodity intelligence). Feels less like \"AGI living in a model\" and more like generality relocating into millions of personal substrates. Curious whether you see it pointing that way too.\n\nOpen-sourced the bare structure if it's useful to anyone: https://github.com/hegu-1/personal-memory-vault-starter\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176208",
"id": 6176208,
"node_id": "GC_lADODShOudoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBePdA",
"user": {
"login": "MarcoPorcellato",
"id": 220745401,
"node_id": "U_kgDODShOuQ",
"avatar_url": "https://avatars.githubusercontent.com/u/220745401?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MarcoPorcellato",
"html_url": "https://github.com/MarcoPorcellato",
"followers_url": "https://api.github.com/users/MarcoPorcellato/followers",
"following_url": "https://api.github.com/users/MarcoPorcellato/following{/other_user}",
"gists_url": "https://api.github.com/users/MarcoPorcellato/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MarcoPorcellato/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MarcoPorcellato/subscriptions",
"organizations_url": "https://api.github.com/users/MarcoPorcellato/orgs",
"repos_url": "https://api.github.com/users/MarcoPorcellato/repos",
"events_url": "https://api.github.com/users/MarcoPorcellato/events{/privacy}",
"received_events_url": "https://api.github.com/users/MarcoPorcellato/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T06:39:48Z",
"updated_at": "2026-05-31T06:39:48Z",
"body": "**Architecture Discussion: Overcoming the \"Flat Markdown Mutation Problem\" in LLM-OS environments (Flat Files vs Outliner AST)** \r\n\r\nLOGSEQ (block granularity) vs Obsidian (page granularity) and my Matryca Plumber\r\n\r\nHi Andrej / everyone,\r\n\r\nI’ve been heavily inspired by your concepts around the LLM OS and using flat Markdown as the filesystem for AI agents. I’ve been building autonomous loops using this exact paradigm, but I hit a massive architectural wall when using standard editors (like Obsidian) as the frontend.\r\n\r\nThe Problem: The \"Flat File Mutation\" Danger\r\nWhen an AI agent tries to autonomously inject properties, update status tags, or surgically edit a document in the background while the user is typing, flat Markdown fails.\r\n\r\nStandard LLMs struggle to parse the exact line numbers or preserve complex metadata in flat .md files without corrupting the surrounding text or triggering race conditions (causing data loss).\r\n\r\nThe Workaround/Experiment\r\nI realized that for an LLM to truly act as a safe background daemon, the filesystem needs an inherently rigid structure. I pivoted the experiment to LOGSEQ (which stores data as a strict Block-based Outliner AST, with UUIDs per block) and implemented an Optimistic Concurrency Control (OCC) locking mechanism via mmap.\r\n\r\nBy doing this, the LLM doesn't have to guess where to inject data. It targets the block UUID.\r\n\r\n1. The human types on the frontend.\r\n2. The AI reads the AST, computes semantic tags, and injects properties in the background.\r\n3. Zero file corruption.\r\n\r\nI built an open-source Python daemon to prove this concept (matryca-plumber), fully protecting the AI-to-File boundary with strict token limits and JSON recovery. It has also an MCP and CLI to dialogue with notes and write directly to .MD files.\r\n\r\nhttps://github.com/MarcoPorcellato/matryca-plumber\r\n\r\nI wanted to share this architectural finding here because as we build out the \"LLM Wiki\" or \"LLM OS\" concepts, shifting the storage paradigm from Flat Text AST to Block Outliner AST seems to be the only way to grant LLMs safe, concurrent write-access to human notes.\r\n\r\nWould love to hear your thoughts on concurrency and background mutations in your Obsidian setups!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176649",
"id": 6176649,
"node_id": "GC_lADOACA0AtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeP4k",
"user": {
"login": "NicoBleh",
"id": 2110466,
"node_id": "MDQ6VXNlcjIxMTA0NjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2110466?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NicoBleh",
"html_url": "https://github.com/NicoBleh",
"followers_url": "https://api.github.com/users/NicoBleh/followers",
"following_url": "https://api.github.com/users/NicoBleh/following{/other_user}",
"gists_url": "https://api.github.com/users/NicoBleh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NicoBleh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NicoBleh/subscriptions",
"organizations_url": "https://api.github.com/users/NicoBleh/orgs",
"repos_url": "https://api.github.com/users/NicoBleh/repos",
"events_url": "https://api.github.com/users/NicoBleh/events{/privacy}",
"received_events_url": "https://api.github.com/users/NicoBleh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T14:29:12Z",
"updated_at": "2026-05-31T14:29:12Z",
"body": "Took this pattern in a security direction and wanted to share the concept in case it's useful to others here.\r\n\r\nThe thing that struck me: an autonomously-ingesting wiki is itself an indirect-prompt-injection surface. A crafted source can plant instructions that persist into the wiki and poison later sessions. The lint step in the original idea checks correctness and contradictions – but not adversariality. Those are orthogonal axes.\r\n\r\nSo I built a version hardened around one invariant: untrusted input (a source) must never reach a channel later treated as trusted (the wiki). Concretely:\r\n\r\n- source text nonce-delimited and declared untrusted at every model boundary (extraction, review, read-time)\r\n- an independent second model reviews each write for manipulation, not correctness (four-eyes)\r\n- trust-tiering by host; weakest level propagates\r\n- git-backed provenance per claim, so a poisoned entry is findable and revertible\r\n- an injection corpus mapping each attack to the gate it must fail at, plus OWASP LLM Top 10 / MITRE ATLAS\r\n\r\nIt's defense-in-depth, not a guarantee – the sanitizer is heuristic and the reviewer is still an LLM. Code and the threat-model write-up:\r\nhttps://github.com/NicoBleh/secure-llm-wiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176658",
"id": 6176658,
"node_id": "GC_lADOEBQ52NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeP5I",
"user": {
"login": "ameriasch",
"id": 269760984,
"node_id": "U_kgDOEBQ52A",
"avatar_url": "https://avatars.githubusercontent.com/u/269760984?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ameriasch",
"html_url": "https://github.com/ameriasch",
"followers_url": "https://api.github.com/users/ameriasch/followers",
"following_url": "https://api.github.com/users/ameriasch/following{/other_user}",
"gists_url": "https://api.github.com/users/ameriasch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ameriasch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ameriasch/subscriptions",
"organizations_url": "https://api.github.com/users/ameriasch/orgs",
"repos_url": "https://api.github.com/users/ameriasch/repos",
"events_url": "https://api.github.com/users/ameriasch/events{/privacy}",
"received_events_url": "https://api.github.com/users/ameriasch/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T14:43:47Z",
"updated_at": "2026-05-31T14:43:47Z",
"body": "What unlocked a lot for me was to think of the whole process like creating my own and machine readable trAsh guides. Thank you for the tunnel and the path."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176989",
"id": 6176989,
"node_id": "GC_lADOAKbyItoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeQN0",
"user": {
"login": "vforvalerio87",
"id": 10940962,
"node_id": "MDQ6VXNlcjEwOTQwOTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/10940962?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vforvalerio87",
"html_url": "https://github.com/vforvalerio87",
"followers_url": "https://api.github.com/users/vforvalerio87/followers",
"following_url": "https://api.github.com/users/vforvalerio87/following{/other_user}",
"gists_url": "https://api.github.com/users/vforvalerio87/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vforvalerio87/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vforvalerio87/subscriptions",
"organizations_url": "https://api.github.com/users/vforvalerio87/orgs",
"repos_url": "https://api.github.com/users/vforvalerio87/repos",
"events_url": "https://api.github.com/users/vforvalerio87/events{/privacy}",
"received_events_url": "https://api.github.com/users/vforvalerio87/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T19:53:32Z",
"updated_at": "2026-05-31T19:53:32Z",
"body": "I started doing exactly this a few months ago. Started with my company's \"sales and marketing\", then my personal stuff, now every code repository. raw-data directory, steering files to process input into the knowledge base, all files reference each other to build a tree, linting rules, a concept of \"knowledge / archive\" vs. \"current state\" which can be either a brief of the most current action items, or the most recent reads on a bunch of things, or what I call \"initiatives\" which is: something with a start date, an end date, a goal to achieve and a way to measure it. Then there's the linting rules and a \"state\" file which is every single piece of raw-data ever processed, what documents it was distilled to, what was the original file name and a brief description. The state is committed, the raw-data isn't. Then since it's domain-specific knowledge-bases each has a few concepts and ontologies of stuff it needs to track in the documents and how they must be processed. So my workflow is usually dump a bunch of stuff in raw-data, tell the kb to eat it and it's done. It's got a rule so that sessions can't be load bearing, context is always ephemeral, everything must be crystallized unless it's really unimportant or noise."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6177647",
"id": 6177647,
"node_id": "GC_lADOAlMHYtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeQ28",
"user": {
"login": "GhostBoyBoy",
"id": 38995810,
"node_id": "MDQ6VXNlcjM4OTk1ODEw",
"avatar_url": "https://avatars.githubusercontent.com/u/38995810?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GhostBoyBoy",
"html_url": "https://github.com/GhostBoyBoy",
"followers_url": "https://api.github.com/users/GhostBoyBoy/followers",
"following_url": "https://api.github.com/users/GhostBoyBoy/following{/other_user}",
"gists_url": "https://api.github.com/users/GhostBoyBoy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GhostBoyBoy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GhostBoyBoy/subscriptions",
"organizations_url": "https://api.github.com/users/GhostBoyBoy/orgs",
"repos_url": "https://api.github.com/users/GhostBoyBoy/repos",
"events_url": "https://api.github.com/users/GhostBoyBoy/events{/privacy}",
"received_events_url": "https://api.github.com/users/GhostBoyBoy/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-01T07:59:03Z",
"updated_at": "2026-06-01T07:59:03Z",
"body": " AI-Collaborative Project Workspace: An Open Proposal for the Next Generation of Software Engineering Directory Structures\r\n https://gist.github.com/GhostBoyBoy/88b02a1ace885cffd5b576ce621eb13a "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6177829",
"id": 6177829,
"node_id": "GC_lADOCnstodoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeRCU",
"user": {
"login": "Shilren",
"id": 175844769,
"node_id": "U_kgDOCnstoQ",
"avatar_url": "https://avatars.githubusercontent.com/u/175844769?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shilren",
"html_url": "https://github.com/Shilren",
"followers_url": "https://api.github.com/users/Shilren/followers",
"following_url": "https://api.github.com/users/Shilren/following{/other_user}",
"gists_url": "https://api.github.com/users/Shilren/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shilren/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shilren/subscriptions",
"organizations_url": "https://api.github.com/users/Shilren/orgs",
"repos_url": "https://api.github.com/users/Shilren/repos",
"events_url": "https://api.github.com/users/Shilren/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shilren/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-01T10:08:03Z",
"updated_at": "2026-06-01T10:08:03Z",
"body": "Thanks for this writeup — the core reframe, \"don't re-retrieve raw docs at query time, let the LLM incrementally maintain a persistent wiki,\" genuinely changed how I approached a problem I'd been stuck on. Sharing what I built on top of it.\n\n**The problem.** Like a lot of people, my work experience was scattered across project retros, weekly reports, chat logs, and my own head. Every time I wrote a resume or prepped an interview answer, I re-dug through everything and re-fed it to an LLM — expensive, slow, lossy, and worst of all the numbers never matched across versions (a metric would be \"22\" in the resume and \"23\" in the spoken script, because each was written from scratch). I realized most people treat AI as a *one-shot rewriter*, when the real leverage is a *reusable, single-source-of-truth knowledge layer* — which is exactly your LLM Wiki point.\n\n**What I built** — **interview-doc-agent** (https://github.com/Shilren/interview-doc-agent), an open-source skill (MIT) that maps onto your three layers almost one-to-one:\n- `materials/` → **raw sources**. Paste anything, unstructured.\n- `experience-library/` → **the wiki layer**. The LLM consolidates each project into a clean, interview-ready doc following a fixed schema: one-liner → situation/problem/actions → *every quantified metric preserved* → transferable strengths.\n- `index.md` → **the index**. The agent reads this first to locate the 1–2 relevant docs, instead of loading the whole library.\n- `SKILL.md` → **the schema**. Behavior config: when to trigger, what steps to follow, hard rules (e.g. *never fabricate a number — leave a `___` placeholder if missing*).\n\n**The workflow** is: drop raw notes in → \"consolidate into the library\" (ingest once) → then every resume, interview script, or JD-tailored variant generates from the same library, so the numbers are always consistent. New experiences compound the library instead of being re-derived each time.\n\n**The part I most wanted to add — context vs. RAG is fundamentally a question of magnitude.** A lot of \"knowledge base + AI\" projects reach for RAG by default, but I think that's often premature. The decision tree I landed on:\n- **< ~50k–100k tokens (~150–200 dense pages): context (LLM Wiki) wins, decisively.** 100% retrieval reliability (no missed chunks, no semantics broken by chunking), near-zero infra (well-structured Markdown — no vector DB, no embedding pipeline, no chunking/retrieval tuning, hours instead of weeks), and *global* reasoning over the whole corpus rather than stitching isolated snippets — which matters a lot for multi-hop or \"summarize across everything\" tasks.\n- **Millions of tokens and up: RAG is the only option** — it won't fit, so retrieval is how you scale.\n- **In between / production: hybrid** — the stable, core knowledge in context, the dynamic/massive/per-user records behind RAG.\n\nA personal experience base, once consolidated, is only a few thousand to ~20k tokens — *far* below the line — so RAG would be pure overhead and a reliability downgrade. And to be precise: my `index.md` isn't RAG. It does no vector matching and no chunking; it just lets the agent open fewer *whole* files as the library grows. Even reading the entire library would comfortably fit in context — the index is an optimization, not a retrieval system. With modern context windows at 200k–1M+ tokens, the ceiling for the pure-context approach keeps rising.\n\nNet: below that magnitude threshold, the LLM Wiki approach is both simpler *and* more reliable than RAG. Thanks again — this writeup saved me from over-engineering the whole thing."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6177837",
"id": 6177837,
"node_id": "GC_lADOCnstodoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeRC0",
"user": {
"login": "Shilren",
"id": 175844769,
"node_id": "U_kgDOCnstoQ",
"avatar_url": "https://avatars.githubusercontent.com/u/175844769?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shilren",
"html_url": "https://github.com/Shilren",
"followers_url": "https://api.github.com/users/Shilren/followers",
"following_url": "https://api.github.com/users/Shilren/following{/other_user}",
"gists_url": "https://api.github.com/users/Shilren/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shilren/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shilren/subscriptions",
"organizations_url": "https://api.github.com/users/Shilren/orgs",
"repos_url": "https://api.github.com/users/Shilren/repos",
"events_url": "https://api.github.com/users/Shilren/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shilren/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-01T10:13:09Z",
"updated_at": "2026-06-01T10:13:09Z",
"body": "Karpathy说的「别每次都去翻原始资料,而是让 LLM 一点点维护一个长期的 wiki」这句话,真的点醒了我一个一直没想通的问题。\r\n\r\n说说我照着这个思路做的东西。我遇到的问题:我的工作经历到处都是 —— 项目复盘、周报、聊天记录、还有一些只在脑子里。每次写简历或者准备面试,都得重新翻一遍、再喂给 AI,又费钱又慢还容易漏东西。最烦的是,同一个数字在简历里写\"22\"、在面试稿里却记成\"23\",因为两份是分开写的。我后来想明白:大多数人只是把 AI 当成\"帮我改一次\"的工具,但其实更值钱的是有一个能反复用、数据只有一个出处的知识库 —— 这就是你说的 LLM Wiki。\r\n\r\n我做的东西 —— interview-doc-agent ([https://github.com/Shilren/interview-doc-agent),一个开源](https://github.com/Shilren/interview-doc-agent),%E4%B8%80%E4%B8%AA%E5%BC%80%E6%BA%90) skill(MIT),几乎一对一对应你的三层:\r\n\r\nmaterials/ → 原始素材,什么格式都行,粘进来就好\r\n经历库/ → wiki 层,AI 把每个项目整理成一份面试能直接用的档案(一句话 → 背景/问题/做法 → 所有数据都留住 → 可迁移的亮点)\r\nindex.md → 索引,先读它找到相关的 1-2 篇,而不是全部加载\r\nSKILL.md → schema,行为说明(什么时候用、按什么步骤、有哪些硬规则,比如\"绝不编数字\")\r\n我最想补充的一点 —— 到底用上下文还是 RAG,本质上是个量级问题。 很多\"知识库 + AI\"的项目张口就上 RAG,但我觉得这往往是过度设计了。我自己理出来的判断标准是:\r\n\r\n小于约 5万–10万 token(大概 150–200 页):上下文(LLM Wiki)完胜 —— 检索可靠性 100%(不会漏匹配、也不会因为分块把语义切断)、几乎不需要任何基建(一个结构清晰的 Markdown 就够,不用向量库、不用嵌入、不用分块)、而且能对全局直接推理,而不是把几个零散片段拼起来\r\n几百万 token 以上:只能用 RAG —— 塞不进上下文,检索是唯一能扩展的办法\r\n介于两者之间 / 生产系统:混合 —— 把最核心稳定的知识放进上下文,把海量、动态的数据交给 RAG\r\n一份个人经历库整理完也就几千到两万 token,远在这条线以下,所以上 RAG 纯属增加负担、还把可靠性变差了。再澄清一点:我那个 index.md 也不是 RAG —— 它不做向量匹配、不分块,只是在经历变多以后让 AI 少读几个完整文件而已;就算全读进去也放得下,索引只是个优化,不是检索系统。现在主流模型上下文都到 200k 甚至 100 万+ token 了,纯上下文这条路的上限只会越来越高。\r\n\r\n只要在这个量级以下,LLM Wiki 比 RAG 又简单又可靠。"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6178829",
"id": 6178829,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeSA0",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-02T00:58:01Z",
"updated_at": "2026-06-02T01:06:14Z",
"body": "Love this LLM-Wiki idea? We built a full open-source system on it → AutoSci\r\n\r\nCome and enjoy: https://github.com/skyllwt/AutoSci\r\n\r\n
\r\nyou may look in to my linkedin post as well https://www.linkedin.com/feed/update/urn:li:activity:7465711718795771904/"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172540",
"id": 6172540,
"node_id": "GC_lADOAEkH8toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeL3w",
"user": {
"login": "alirezabbasi",
"id": 4786162,
"node_id": "MDQ6VXNlcjQ3ODYxNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4786162?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alirezabbasi",
"html_url": "https://github.com/alirezabbasi",
"followers_url": "https://api.github.com/users/alirezabbasi/followers",
"following_url": "https://api.github.com/users/alirezabbasi/following{/other_user}",
"gists_url": "https://api.github.com/users/alirezabbasi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alirezabbasi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alirezabbasi/subscriptions",
"organizations_url": "https://api.github.com/users/alirezabbasi/orgs",
"repos_url": "https://api.github.com/users/alirezabbasi/repos",
"events_url": "https://api.github.com/users/alirezabbasi/events{/privacy}",
"received_events_url": "https://api.github.com/users/alirezabbasi/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T12:41:55Z",
"updated_at": "2026-05-28T12:41:55Z",
"body": "https://github.com/alirezabbasi/echel/releases/tag/v0.2.0\r\n\r\nI just released **Echel v0.2.0**.\r\n\r\nEchel started from the same core insight behind Andrej Karpathy’s “LLM Wiki” idea: AI workflows should not keep rediscovering knowledge from scratch every session.\r\n\r\nThe LLM Wiki pattern says: instead of relying only on RAG or chat history, let AI continuously maintain a structured, interlinked wiki that compounds over time.\r\n\r\nEchel takes that idea into software product creation.\r\n\r\nIt is a platform where a domain expert defines a problem, intended solution, constraints, risks, MVP, stack, and direction, and Echel continuously turns that intent into:\r\n\r\n- clarified requirements\r\n- product architecture\r\n- roadmap\r\n- executable work\r\n- graph-backed AI agent packets\r\n- review reports\r\n- readiness checks\r\n- proof packs\r\n- compounding project intelligence\r\n\r\nThe key idea is simple:\r\n\r\n**The product should not lose memory every time the AI context window resets.**\r\n\r\nIn v0.2.0, Echel now includes:\r\n\r\n- product-first initialization\r\n- root-level product `wiki/`\r\n- internal `echel-core/` runtime split\r\n- product-owner commands like `define`, `clarify`, `plan`, `build`, `review`, `steer`, and `status`\r\n- typed product intelligence graph\r\n- agent work packets\r\n- product cockpit\r\n- milestone/readiness gates\r\n- proof packs and release summaries\r\n\r\nThe direction is to make Echel a product-creation operating system for AI-native development.\r\n\r\nA business owner or domain expert should be able to steer the product through intent and decisions, while Echel and AI agents handle the structured execution loop.\r\n\r\nHuge inspiration from the LLM Wiki pattern:\r\nhttps://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f\r\n\r\nEchel v0.2.0 is the first version where that idea becomes a fuller software-development workflow:\r\n\r\n**intent -> memory -> graph -> plan -> build packet -> implementation -> review -> readiness -> updated intelligence**"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172613",
"id": 6172613,
"node_id": "GC_lADOAIC6hNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeL8U",
"user": {
"login": "brtrx",
"id": 8436356,
"node_id": "MDQ6VXNlcjg0MzYzNTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8436356?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brtrx",
"html_url": "https://github.com/brtrx",
"followers_url": "https://api.github.com/users/brtrx/followers",
"following_url": "https://api.github.com/users/brtrx/following{/other_user}",
"gists_url": "https://api.github.com/users/brtrx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brtrx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brtrx/subscriptions",
"organizations_url": "https://api.github.com/users/brtrx/orgs",
"repos_url": "https://api.github.com/users/brtrx/repos",
"events_url": "https://api.github.com/users/brtrx/events{/privacy}",
"received_events_url": "https://api.github.com/users/brtrx/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T13:34:55Z",
"updated_at": "2026-05-28T13:34:55Z",
"body": "Built a lint extension to combat ingestion order bias in wikis with 50+ sources: [LLM Wiki: A Bias-Aware Stateful Lint](https://gist.github.com/brtrx/ba595fd01e344d797cb66d34d982ecad)\r\n\r\nTwo problems emerge at scale — context limits kill single-pass lint, and ingestion order biases the wiki toward earlier sources. The extension runs lint in batches of 5 with a persistent scratchpad across sessions, and uses a randomised (not ingestion-order) source sequence to surface cross-cutting contradictions that ordered passes miss.\r\n\r\nDrops into an existing CLAUDE.md. Doesn't fix framing bias baked in at ingest time, but repairs the structural layer reliably."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6172973",
"id": 6172973,
"node_id": "GC_lADOAcKXk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeMS0",
"user": {
"login": "noirblue",
"id": 29530003,
"node_id": "MDQ6VXNlcjI5NTMwMDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/29530003?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noirblue",
"html_url": "https://github.com/noirblue",
"followers_url": "https://api.github.com/users/noirblue/followers",
"following_url": "https://api.github.com/users/noirblue/following{/other_user}",
"gists_url": "https://api.github.com/users/noirblue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noirblue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noirblue/subscriptions",
"organizations_url": "https://api.github.com/users/noirblue/orgs",
"repos_url": "https://api.github.com/users/noirblue/repos",
"events_url": "https://api.github.com/users/noirblue/events{/privacy}",
"received_events_url": "https://api.github.com/users/noirblue/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-28T17:20:43Z",
"updated_at": "2026-05-28T17:20:43Z",
"body": "A few people have asked: isn't this just a wiki compiler with extra steps?\r\n\r\nNo. Wiki compilation is one layer of seven. The broader goal is a **knowledge lifecycle**, not just ingestion:\r\n\r\n- **Agent memory:** `memory/inbox/` → `memory/committed/` — propose, review, link, decay\r\n- **Conversation history:** token-budgeted, cross-session, queryable\r\n- **Dual-node deployment:** Foundry (batch compile/audit) + Frontline (interactive serve)\r\n- **Audit as infrastructure:** every claim traced to source, every LLM call logged with cost/hash\r\n- **Pack exports:** agent-ready subsets of the graph for action\r\n\r\nThe architecture uses a **Rust core** for the performance-critical path — schema, job queue, graph traversal, API surface — while Python satellites handle document extraction and LLM orchestration where Python's ecosystem has no equal. The split is permanent, not transitional.\r\n\r\nThe LLM-Wiki pattern proved that compounding works. Mnemosyne asks: what happens when you treat that pattern as **infrastructure** — with schemas, queues, provenance, and deployment topologies — rather than as content in markdown files?\r\n\r\nSpec: https://github.com/noirblue/IsaacCLupus_mnemosyn_spec"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6173827",
"id": 6173827,
"node_id": "GC_lADOA4rqIdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeNIM",
"user": {
"login": "iddingszhz",
"id": 59435553,
"node_id": "MDQ6VXNlcjU5NDM1NTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/59435553?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iddingszhz",
"html_url": "https://github.com/iddingszhz",
"followers_url": "https://api.github.com/users/iddingszhz/followers",
"following_url": "https://api.github.com/users/iddingszhz/following{/other_user}",
"gists_url": "https://api.github.com/users/iddingszhz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iddingszhz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iddingszhz/subscriptions",
"organizations_url": "https://api.github.com/users/iddingszhz/orgs",
"repos_url": "https://api.github.com/users/iddingszhz/repos",
"events_url": "https://api.github.com/users/iddingszhz/events{/privacy}",
"received_events_url": "https://api.github.com/users/iddingszhz/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-29T09:14:45Z",
"updated_at": "2026-05-29T09:14:45Z",
"body": "我按照 Karpathy 的思路开发了一个日记库,充分运用 Karpathy 的 **\"固定协议 + 可插拔模块\"** 架构。\r\n\r\n用在自我认知上,比用在代码上更让人震撼。\r\n\r\n**CLAUDE.md** 作为行为协议来约束 AI,而不是堆提示词。把 AI 从一个\"聊天对象\"变成了一只严格执行 SOP 的 analytic engine。\r\n\r\n同时采用 **协议和人格分离** 的设计:协议保证行为可预期、可迁移(换 AI 客户端也不崩),人格随时换文件就能换风格——这是系统工程思维在个人管理上的降维打击。\r\n\r\n日记架构按照 **L0 → L4 的分层深化**:\r\n\r\n- 大多数日记工具停留在 L0(记录)\r\n- 好一点的做到 L1(周回顾)\r\n\r\n而我把跨时间复利对比(L3 / L4)直接做成内建功能。当日记从\"散装存档\"变成\"可检索的认知档案\",它就不再是日记了——**是一个人的增量自我进化系统**。\r\n\r\n👉 https://github.com/iddingszhz/Life_Daliy_OS"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6174117",
"id": 6174117,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeNaU",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-29T13:31:03Z",
"updated_at": "2026-05-29T13:31:03Z",
"body": "Synthadoc v0.6.0 is out.\r\n\r\nTwo new features focused on content health and portability:\r\n\r\n1. Five-State Page Lifecycle: pages now move through five states: draft → active → stale → contradicted → archived. Transitions are mostly automatic: a clean lint pass promotes draft to active; a SHA-256 hash mismatch on the source file marks the page stale; ingesting a conflicting source marks it contradicted. Every transition is permanently logged with who triggered it, when, and why, so you have an auditable trail of when content was reviewed, not just who last touched the file. Manual overrides (lifecycle activate, archive, restore) are there when automation isn't enough.\r\n\r\n → Quick-start demo - Step 8 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-8--manage-page-lifecycle)\r\n\r\n\r\n2. Wiki Export: four formats in one command: synthadoc export -f . llms.txt and llms-full.txt follow the llmstxt.org spec for feeding the wiki into downstream LLM workflows. \"graphml\" exports the wikilink graph with node attributes (status, confidence, citation count) for analysis in Gephi or yEd. \"json\" export includes three fields no generic wiki export produces: every paragraph traces back to exact source lines (claims[] -file name plus line range, not just \"from document X\"); the complete state-transition audit log (lifecycle_history[] - when the page was drafted, reviewed, went stale, re-ingested); and the per-page API cost to compile it (ingest_cost_usd).\r\n\r\n → Quick-start demo - Step 21 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-21--export-your-wiki)\r\n\r\n\r\n3. Also shipping in v0.6.0: refined Obsidian plugin UX across lifecycle and export modals.\r\n\r\n \r\nIf any of this is useful or you have thoughts on the direction, feedback is very welcome, and a ⭐ always helps the project reach more people.\r\n\r\n 👉 https://github.com/axoviq-ai/synthadoc"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6174898",
"id": 6174898,
"node_id": "GC_lADOAmYaO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeOLI",
"user": {
"login": "Yarmoluk",
"id": 40245819,
"node_id": "MDQ6VXNlcjQwMjQ1ODE5",
"avatar_url": "https://avatars.githubusercontent.com/u/40245819?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yarmoluk",
"html_url": "https://github.com/Yarmoluk",
"followers_url": "https://api.github.com/users/Yarmoluk/followers",
"following_url": "https://api.github.com/users/Yarmoluk/following{/other_user}",
"gists_url": "https://api.github.com/users/Yarmoluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Yarmoluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yarmoluk/subscriptions",
"organizations_url": "https://api.github.com/users/Yarmoluk/orgs",
"repos_url": "https://api.github.com/users/Yarmoluk/repos",
"events_url": "https://api.github.com/users/Yarmoluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/Yarmoluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-30T03:32:11Z",
"updated_at": "2026-05-30T03:32:11Z",
"body": "Behavioral protocol is correct\r\n\r\n\r\nRespectfully,\r\n\r\nDan Yarmoluk\r\n\r\nOn Fri, May 29, 2026 at 8:31 AM Paul Chen ***@***.***> wrote:\r\n\r\n> ***@***.**** commented on this gist.\r\n> ------------------------------\r\n>\r\n> Synthadoc v0.6.0 is out.\r\n>\r\n> Two new features focused on content health and portability:\r\n>\r\n> 1. Five-State Page Lifecycle: pages now move through five states:\r\n> draft → active → stale → contradicted → archived. Transitions are mostly\r\n> automatic: a clean lint pass promotes draft to active; a SHA-256 hash\r\n> mismatch on the source file marks the page stale; ingesting a conflicting\r\n> source marks it contradicted. Every transition is permanently logged with\r\n> who triggered it, when, and why, so you have an auditable trail of when\r\n> content was reviewed, not just who last touched the file. Manual overrides\r\n> (lifecycle activate, archive, restore) are there when automation isn't\r\n> enough.\r\n>\r\n> → Quick-start demo - Step 8 (\r\n> https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-8--manage-page-lifecycle\r\n> )\r\n>\r\n> 2. Wiki Export: four formats in one command: synthadoc export -f .\r\n> llms.txt and llms-full.txt follow the llmstxt.org spec for feeding the\r\n> wiki into downstream LLM workflows. \"graphml\" exports the wikilink graph\r\n> with node attributes (status, confidence, citation count) for analysis in\r\n> Gephi or yEd. \"json\" export includes three fields no generic wiki export\r\n> produces: every paragraph traces back to exact source lines (claims[] -file\r\n> name plus line range, not just \"from document X\"); the complete\r\n> state-transition audit log (lifecycle_history[] - when the page was\r\n> drafted, reviewed, went stale, re-ingested); and the per-page API cost to\r\n> compile it (ingest_cost_usd).\r\n>\r\n> → Quick-start demo - Step 21 (\r\n> https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-21--export-your-wiki\r\n> )\r\n>\r\n> 3. Also shipping in v0.6.0: refined Obsidian plugin UX across\r\n> lifecycle and export modals.\r\n>\r\n> If any of this is useful or you have thoughts on the direction, feedback\r\n> is very welcome, and a ⭐ always helps the project reach more people.\r\n>\r\n> 👉 https://github.com/axoviq-ai/synthadoc\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> \r\n> or unsubscribe\r\n> \r\n> .\r\n> You are receiving this email because you commented on the thread.\r\n>\r\n> Triage notifications on the go with GitHub Mobile for iOS\r\n> \r\n> or Android\r\n> \r\n> .\r\n>\r\n>\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6175904",
"id": 6175904,
"node_id": "GC_lADOALUbLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBePKA",
"user": {
"login": "theafh",
"id": 11868972,
"node_id": "MDQ6VXNlcjExODY4OTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11868972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theafh",
"html_url": "https://github.com/theafh",
"followers_url": "https://api.github.com/users/theafh/followers",
"following_url": "https://api.github.com/users/theafh/following{/other_user}",
"gists_url": "https://api.github.com/users/theafh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theafh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theafh/subscriptions",
"organizations_url": "https://api.github.com/users/theafh/orgs",
"repos_url": "https://api.github.com/users/theafh/repos",
"events_url": "https://api.github.com/users/theafh/events{/privacy}",
"received_events_url": "https://api.github.com/users/theafh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-30T23:58:58Z",
"updated_at": "2026-05-30T23:59:59Z",
"body": " This wiki pattern worked so well for *knowledge* that I tried the same\r\n plain-markdown-over-LLM idea on the other half of the AI-developer workflow!\r\n If the /wiki is a Confluence you can talk to, /task is the JIRA/Trello version:\r\n a backlog that lives next to the code as files, not in a SaaS.\r\n\r\n Same principles, different artifact:\r\n\r\n - **One self-contained markdown file per task**, written so a single-shot agent\r\n can pick it up and implement it with no chat context.\r\n - **Filesystem-native and git-tracked**: `tasks/` for open work, `tasks/archive/`\r\n for done/dropped, scope in the filename. No lock-in, diffs, and history for free.\r\n - **A bundled linter keeps it healthy** — naming, frontmatter, status↔location,\r\n links, dates (the task analogue of the wiki's lint pass).\r\n - **A small lifecycle of skills** instead of one mega-prompt:\r\n create → check → implement → audit → finish, plus a whole-tree fix/health pass.\r\n\r\n Open-source, MIT License, Multi-agent skill deployment:\r\n https://github.com/theafh/ai-modules/tree/main/plugins/ai_dev/skills"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176154",
"id": 6176154,
"node_id": "GC_lADOD9LxrdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBePZo",
"user": {
"login": "hegu-1",
"id": 265482669,
"node_id": "U_kgDOD9LxrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/265482669?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hegu-1",
"html_url": "https://github.com/hegu-1",
"followers_url": "https://api.github.com/users/hegu-1/followers",
"following_url": "https://api.github.com/users/hegu-1/following{/other_user}",
"gists_url": "https://api.github.com/users/hegu-1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hegu-1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hegu-1/subscriptions",
"organizations_url": "https://api.github.com/users/hegu-1/orgs",
"repos_url": "https://api.github.com/users/hegu-1/repos",
"events_url": "https://api.github.com/users/hegu-1/events{/privacy}",
"received_events_url": "https://api.github.com/users/hegu-1/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T05:47:16Z",
"updated_at": "2026-05-31T05:47:16Z",
"body": "Been circling the same three-layer shape (raw → wiki → outputs, markdown, pre-compiled, wiki-linked) — but I came at it from a different angle: not \"knowledge base as a product,\" more \"a container for my own continuity\" that any model loads to stay in phase with me across sessions and machines.\n\nThe one place I deliberately diverge from your setup: I *don't* let it drift toward \"none written by me directly.\" The model writes the derivative / linking / consistency layer; the framing and the decisions stay authored by me — otherwise the continuity quietly stops being mine.\n\nWhich makes me wonder about something bigger than a second brain: if everyone runs a personal container like this and the model becomes the interchangeable part, the interesting unit isn't one general model anymore — it's (person × container × commodity intelligence). Feels less like \"AGI living in a model\" and more like generality relocating into millions of personal substrates. Curious whether you see it pointing that way too.\n\nOpen-sourced the bare structure if it's useful to anyone: https://github.com/hegu-1/personal-memory-vault-starter\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176208",
"id": 6176208,
"node_id": "GC_lADODShOudoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBePdA",
"user": {
"login": "MarcoPorcellato",
"id": 220745401,
"node_id": "U_kgDODShOuQ",
"avatar_url": "https://avatars.githubusercontent.com/u/220745401?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MarcoPorcellato",
"html_url": "https://github.com/MarcoPorcellato",
"followers_url": "https://api.github.com/users/MarcoPorcellato/followers",
"following_url": "https://api.github.com/users/MarcoPorcellato/following{/other_user}",
"gists_url": "https://api.github.com/users/MarcoPorcellato/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MarcoPorcellato/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MarcoPorcellato/subscriptions",
"organizations_url": "https://api.github.com/users/MarcoPorcellato/orgs",
"repos_url": "https://api.github.com/users/MarcoPorcellato/repos",
"events_url": "https://api.github.com/users/MarcoPorcellato/events{/privacy}",
"received_events_url": "https://api.github.com/users/MarcoPorcellato/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T06:39:48Z",
"updated_at": "2026-05-31T06:39:48Z",
"body": "**Architecture Discussion: Overcoming the \"Flat Markdown Mutation Problem\" in LLM-OS environments (Flat Files vs Outliner AST)** \r\n\r\nLOGSEQ (block granularity) vs Obsidian (page granularity) and my Matryca Plumber\r\n\r\nHi Andrej / everyone,\r\n\r\nI’ve been heavily inspired by your concepts around the LLM OS and using flat Markdown as the filesystem for AI agents. I’ve been building autonomous loops using this exact paradigm, but I hit a massive architectural wall when using standard editors (like Obsidian) as the frontend.\r\n\r\nThe Problem: The \"Flat File Mutation\" Danger\r\nWhen an AI agent tries to autonomously inject properties, update status tags, or surgically edit a document in the background while the user is typing, flat Markdown fails.\r\n\r\nStandard LLMs struggle to parse the exact line numbers or preserve complex metadata in flat .md files without corrupting the surrounding text or triggering race conditions (causing data loss).\r\n\r\nThe Workaround/Experiment\r\nI realized that for an LLM to truly act as a safe background daemon, the filesystem needs an inherently rigid structure. I pivoted the experiment to LOGSEQ (which stores data as a strict Block-based Outliner AST, with UUIDs per block) and implemented an Optimistic Concurrency Control (OCC) locking mechanism via mmap.\r\n\r\nBy doing this, the LLM doesn't have to guess where to inject data. It targets the block UUID.\r\n\r\n1. The human types on the frontend.\r\n2. The AI reads the AST, computes semantic tags, and injects properties in the background.\r\n3. Zero file corruption.\r\n\r\nI built an open-source Python daemon to prove this concept (matryca-plumber), fully protecting the AI-to-File boundary with strict token limits and JSON recovery. It has also an MCP and CLI to dialogue with notes and write directly to .MD files.\r\n\r\nhttps://github.com/MarcoPorcellato/matryca-plumber\r\n\r\nI wanted to share this architectural finding here because as we build out the \"LLM Wiki\" or \"LLM OS\" concepts, shifting the storage paradigm from Flat Text AST to Block Outliner AST seems to be the only way to grant LLMs safe, concurrent write-access to human notes.\r\n\r\nWould love to hear your thoughts on concurrency and background mutations in your Obsidian setups!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176649",
"id": 6176649,
"node_id": "GC_lADOACA0AtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeP4k",
"user": {
"login": "NicoBleh",
"id": 2110466,
"node_id": "MDQ6VXNlcjIxMTA0NjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2110466?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NicoBleh",
"html_url": "https://github.com/NicoBleh",
"followers_url": "https://api.github.com/users/NicoBleh/followers",
"following_url": "https://api.github.com/users/NicoBleh/following{/other_user}",
"gists_url": "https://api.github.com/users/NicoBleh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NicoBleh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NicoBleh/subscriptions",
"organizations_url": "https://api.github.com/users/NicoBleh/orgs",
"repos_url": "https://api.github.com/users/NicoBleh/repos",
"events_url": "https://api.github.com/users/NicoBleh/events{/privacy}",
"received_events_url": "https://api.github.com/users/NicoBleh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T14:29:12Z",
"updated_at": "2026-05-31T14:29:12Z",
"body": "Took this pattern in a security direction and wanted to share the concept in case it's useful to others here.\r\n\r\nThe thing that struck me: an autonomously-ingesting wiki is itself an indirect-prompt-injection surface. A crafted source can plant instructions that persist into the wiki and poison later sessions. The lint step in the original idea checks correctness and contradictions – but not adversariality. Those are orthogonal axes.\r\n\r\nSo I built a version hardened around one invariant: untrusted input (a source) must never reach a channel later treated as trusted (the wiki). Concretely:\r\n\r\n- source text nonce-delimited and declared untrusted at every model boundary (extraction, review, read-time)\r\n- an independent second model reviews each write for manipulation, not correctness (four-eyes)\r\n- trust-tiering by host; weakest level propagates\r\n- git-backed provenance per claim, so a poisoned entry is findable and revertible\r\n- an injection corpus mapping each attack to the gate it must fail at, plus OWASP LLM Top 10 / MITRE ATLAS\r\n\r\nIt's defense-in-depth, not a guarantee – the sanitizer is heuristic and the reviewer is still an LLM. Code and the threat-model write-up:\r\nhttps://github.com/NicoBleh/secure-llm-wiki"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176658",
"id": 6176658,
"node_id": "GC_lADOEBQ52NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeP5I",
"user": {
"login": "ameriasch",
"id": 269760984,
"node_id": "U_kgDOEBQ52A",
"avatar_url": "https://avatars.githubusercontent.com/u/269760984?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ameriasch",
"html_url": "https://github.com/ameriasch",
"followers_url": "https://api.github.com/users/ameriasch/followers",
"following_url": "https://api.github.com/users/ameriasch/following{/other_user}",
"gists_url": "https://api.github.com/users/ameriasch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ameriasch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ameriasch/subscriptions",
"organizations_url": "https://api.github.com/users/ameriasch/orgs",
"repos_url": "https://api.github.com/users/ameriasch/repos",
"events_url": "https://api.github.com/users/ameriasch/events{/privacy}",
"received_events_url": "https://api.github.com/users/ameriasch/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T14:43:47Z",
"updated_at": "2026-05-31T14:43:47Z",
"body": "What unlocked a lot for me was to think of the whole process like creating my own and machine readable trAsh guides. Thank you for the tunnel and the path."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6176989",
"id": 6176989,
"node_id": "GC_lADOAKbyItoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeQN0",
"user": {
"login": "vforvalerio87",
"id": 10940962,
"node_id": "MDQ6VXNlcjEwOTQwOTYy",
"avatar_url": "https://avatars.githubusercontent.com/u/10940962?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vforvalerio87",
"html_url": "https://github.com/vforvalerio87",
"followers_url": "https://api.github.com/users/vforvalerio87/followers",
"following_url": "https://api.github.com/users/vforvalerio87/following{/other_user}",
"gists_url": "https://api.github.com/users/vforvalerio87/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vforvalerio87/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vforvalerio87/subscriptions",
"organizations_url": "https://api.github.com/users/vforvalerio87/orgs",
"repos_url": "https://api.github.com/users/vforvalerio87/repos",
"events_url": "https://api.github.com/users/vforvalerio87/events{/privacy}",
"received_events_url": "https://api.github.com/users/vforvalerio87/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-05-31T19:53:32Z",
"updated_at": "2026-05-31T19:53:32Z",
"body": "I started doing exactly this a few months ago. Started with my company's \"sales and marketing\", then my personal stuff, now every code repository. raw-data directory, steering files to process input into the knowledge base, all files reference each other to build a tree, linting rules, a concept of \"knowledge / archive\" vs. \"current state\" which can be either a brief of the most current action items, or the most recent reads on a bunch of things, or what I call \"initiatives\" which is: something with a start date, an end date, a goal to achieve and a way to measure it. Then there's the linting rules and a \"state\" file which is every single piece of raw-data ever processed, what documents it was distilled to, what was the original file name and a brief description. The state is committed, the raw-data isn't. Then since it's domain-specific knowledge-bases each has a few concepts and ontologies of stuff it needs to track in the documents and how they must be processed. So my workflow is usually dump a bunch of stuff in raw-data, tell the kb to eat it and it's done. It's got a rule so that sessions can't be load bearing, context is always ephemeral, everything must be crystallized unless it's really unimportant or noise."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6177647",
"id": 6177647,
"node_id": "GC_lADOAlMHYtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeQ28",
"user": {
"login": "GhostBoyBoy",
"id": 38995810,
"node_id": "MDQ6VXNlcjM4OTk1ODEw",
"avatar_url": "https://avatars.githubusercontent.com/u/38995810?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GhostBoyBoy",
"html_url": "https://github.com/GhostBoyBoy",
"followers_url": "https://api.github.com/users/GhostBoyBoy/followers",
"following_url": "https://api.github.com/users/GhostBoyBoy/following{/other_user}",
"gists_url": "https://api.github.com/users/GhostBoyBoy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GhostBoyBoy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GhostBoyBoy/subscriptions",
"organizations_url": "https://api.github.com/users/GhostBoyBoy/orgs",
"repos_url": "https://api.github.com/users/GhostBoyBoy/repos",
"events_url": "https://api.github.com/users/GhostBoyBoy/events{/privacy}",
"received_events_url": "https://api.github.com/users/GhostBoyBoy/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-01T07:59:03Z",
"updated_at": "2026-06-01T07:59:03Z",
"body": " AI-Collaborative Project Workspace: An Open Proposal for the Next Generation of Software Engineering Directory Structures\r\n https://gist.github.com/GhostBoyBoy/88b02a1ace885cffd5b576ce621eb13a "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6177829",
"id": 6177829,
"node_id": "GC_lADOCnstodoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeRCU",
"user": {
"login": "Shilren",
"id": 175844769,
"node_id": "U_kgDOCnstoQ",
"avatar_url": "https://avatars.githubusercontent.com/u/175844769?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shilren",
"html_url": "https://github.com/Shilren",
"followers_url": "https://api.github.com/users/Shilren/followers",
"following_url": "https://api.github.com/users/Shilren/following{/other_user}",
"gists_url": "https://api.github.com/users/Shilren/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shilren/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shilren/subscriptions",
"organizations_url": "https://api.github.com/users/Shilren/orgs",
"repos_url": "https://api.github.com/users/Shilren/repos",
"events_url": "https://api.github.com/users/Shilren/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shilren/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-01T10:08:03Z",
"updated_at": "2026-06-01T10:08:03Z",
"body": "Thanks for this writeup — the core reframe, \"don't re-retrieve raw docs at query time, let the LLM incrementally maintain a persistent wiki,\" genuinely changed how I approached a problem I'd been stuck on. Sharing what I built on top of it.\n\n**The problem.** Like a lot of people, my work experience was scattered across project retros, weekly reports, chat logs, and my own head. Every time I wrote a resume or prepped an interview answer, I re-dug through everything and re-fed it to an LLM — expensive, slow, lossy, and worst of all the numbers never matched across versions (a metric would be \"22\" in the resume and \"23\" in the spoken script, because each was written from scratch). I realized most people treat AI as a *one-shot rewriter*, when the real leverage is a *reusable, single-source-of-truth knowledge layer* — which is exactly your LLM Wiki point.\n\n**What I built** — **interview-doc-agent** (https://github.com/Shilren/interview-doc-agent), an open-source skill (MIT) that maps onto your three layers almost one-to-one:\n- `materials/` → **raw sources**. Paste anything, unstructured.\n- `experience-library/` → **the wiki layer**. The LLM consolidates each project into a clean, interview-ready doc following a fixed schema: one-liner → situation/problem/actions → *every quantified metric preserved* → transferable strengths.\n- `index.md` → **the index**. The agent reads this first to locate the 1–2 relevant docs, instead of loading the whole library.\n- `SKILL.md` → **the schema**. Behavior config: when to trigger, what steps to follow, hard rules (e.g. *never fabricate a number — leave a `___` placeholder if missing*).\n\n**The workflow** is: drop raw notes in → \"consolidate into the library\" (ingest once) → then every resume, interview script, or JD-tailored variant generates from the same library, so the numbers are always consistent. New experiences compound the library instead of being re-derived each time.\n\n**The part I most wanted to add — context vs. RAG is fundamentally a question of magnitude.** A lot of \"knowledge base + AI\" projects reach for RAG by default, but I think that's often premature. The decision tree I landed on:\n- **< ~50k–100k tokens (~150–200 dense pages): context (LLM Wiki) wins, decisively.** 100% retrieval reliability (no missed chunks, no semantics broken by chunking), near-zero infra (well-structured Markdown — no vector DB, no embedding pipeline, no chunking/retrieval tuning, hours instead of weeks), and *global* reasoning over the whole corpus rather than stitching isolated snippets — which matters a lot for multi-hop or \"summarize across everything\" tasks.\n- **Millions of tokens and up: RAG is the only option** — it won't fit, so retrieval is how you scale.\n- **In between / production: hybrid** — the stable, core knowledge in context, the dynamic/massive/per-user records behind RAG.\n\nA personal experience base, once consolidated, is only a few thousand to ~20k tokens — *far* below the line — so RAG would be pure overhead and a reliability downgrade. And to be precise: my `index.md` isn't RAG. It does no vector matching and no chunking; it just lets the agent open fewer *whole* files as the library grows. Even reading the entire library would comfortably fit in context — the index is an optimization, not a retrieval system. With modern context windows at 200k–1M+ tokens, the ceiling for the pure-context approach keeps rising.\n\nNet: below that magnitude threshold, the LLM Wiki approach is both simpler *and* more reliable than RAG. Thanks again — this writeup saved me from over-engineering the whole thing."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6177837",
"id": 6177837,
"node_id": "GC_lADOCnstodoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeRC0",
"user": {
"login": "Shilren",
"id": 175844769,
"node_id": "U_kgDOCnstoQ",
"avatar_url": "https://avatars.githubusercontent.com/u/175844769?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shilren",
"html_url": "https://github.com/Shilren",
"followers_url": "https://api.github.com/users/Shilren/followers",
"following_url": "https://api.github.com/users/Shilren/following{/other_user}",
"gists_url": "https://api.github.com/users/Shilren/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shilren/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shilren/subscriptions",
"organizations_url": "https://api.github.com/users/Shilren/orgs",
"repos_url": "https://api.github.com/users/Shilren/repos",
"events_url": "https://api.github.com/users/Shilren/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shilren/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-01T10:13:09Z",
"updated_at": "2026-06-01T10:13:09Z",
"body": "Karpathy说的「别每次都去翻原始资料,而是让 LLM 一点点维护一个长期的 wiki」这句话,真的点醒了我一个一直没想通的问题。\r\n\r\n说说我照着这个思路做的东西。我遇到的问题:我的工作经历到处都是 —— 项目复盘、周报、聊天记录、还有一些只在脑子里。每次写简历或者准备面试,都得重新翻一遍、再喂给 AI,又费钱又慢还容易漏东西。最烦的是,同一个数字在简历里写\"22\"、在面试稿里却记成\"23\",因为两份是分开写的。我后来想明白:大多数人只是把 AI 当成\"帮我改一次\"的工具,但其实更值钱的是有一个能反复用、数据只有一个出处的知识库 —— 这就是你说的 LLM Wiki。\r\n\r\n我做的东西 —— interview-doc-agent ([https://github.com/Shilren/interview-doc-agent),一个开源](https://github.com/Shilren/interview-doc-agent),%E4%B8%80%E4%B8%AA%E5%BC%80%E6%BA%90) skill(MIT),几乎一对一对应你的三层:\r\n\r\nmaterials/ → 原始素材,什么格式都行,粘进来就好\r\n经历库/ → wiki 层,AI 把每个项目整理成一份面试能直接用的档案(一句话 → 背景/问题/做法 → 所有数据都留住 → 可迁移的亮点)\r\nindex.md → 索引,先读它找到相关的 1-2 篇,而不是全部加载\r\nSKILL.md → schema,行为说明(什么时候用、按什么步骤、有哪些硬规则,比如\"绝不编数字\")\r\n我最想补充的一点 —— 到底用上下文还是 RAG,本质上是个量级问题。 很多\"知识库 + AI\"的项目张口就上 RAG,但我觉得这往往是过度设计了。我自己理出来的判断标准是:\r\n\r\n小于约 5万–10万 token(大概 150–200 页):上下文(LLM Wiki)完胜 —— 检索可靠性 100%(不会漏匹配、也不会因为分块把语义切断)、几乎不需要任何基建(一个结构清晰的 Markdown 就够,不用向量库、不用嵌入、不用分块)、而且能对全局直接推理,而不是把几个零散片段拼起来\r\n几百万 token 以上:只能用 RAG —— 塞不进上下文,检索是唯一能扩展的办法\r\n介于两者之间 / 生产系统:混合 —— 把最核心稳定的知识放进上下文,把海量、动态的数据交给 RAG\r\n一份个人经历库整理完也就几千到两万 token,远在这条线以下,所以上 RAG 纯属增加负担、还把可靠性变差了。再澄清一点:我那个 index.md 也不是 RAG —— 它不做向量匹配、不分块,只是在经历变多以后让 AI 少读几个完整文件而已;就算全读进去也放得下,索引只是个优化,不是检索系统。现在主流模型上下文都到 200k 甚至 100 万+ token 了,纯上下文这条路的上限只会越来越高。\r\n\r\n只要在这个量级以下,LLM Wiki 比 RAG 又简单又可靠。"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6178829",
"id": 6178829,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeSA0",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-02T00:58:01Z",
"updated_at": "2026-06-02T01:06:14Z",
"body": "Love this LLM-Wiki idea? We built a full open-source system on it → AutoSci\r\n\r\nCome and enjoy: https://github.com/skyllwt/AutoSci\r\n\r\n \r\n\r\nKarpathy's pattern (immutable raw/ → an LLM-compiled wiki/ → a CLAUDE.md schema) is the exact foundation of AutoSci — an agent that turns the wiki into a research memory and then does autonomous science on top of it. All on Claude Code:\r\n - 📚 Ingest papers into a cross-linked wiki of concept/method/idea pages ([[wikilinks]], contradiction edges — the LLM-Wiki, fully realized)\r\n - 💡 Ideate → experiment → write: it reads its own memory to generate ideas, design + run experiments, draft the paper, and handle rebuttals\r\n - 🧬 Self-evolving memory: between projects it consolidates, re-weights, and re-links the wiki (a \"sleep\" phase)\r\n - 🕸️ Multi-agent DAGs for the hard reasoning steps\r\n\r\n\r\nWe've already used it to write 3 papers end-to-end. Fully open (MIT).\r\n\r\n⭐ If this is where you want LLM-Wikis to go, a star genuinely helps us! and we welcome issues/PRs/Contributors\r\n👉 https://github.com/skyllwt/AutoSci\r\n📄 Paper: https://arxiv.org/abs/2605.31468\r\n\r\nDemo: 【北大做了一个会自我进化的科研 Agent:AutoSci】 https://www.bilibili.com/video/BV19gVg6pEk6/?share_source=copy_web&vd_source=338de971cb27f42aaaf5d8bfdeed04b3\r\n\r\n
\r\n\r\nKarpathy's pattern (immutable raw/ → an LLM-compiled wiki/ → a CLAUDE.md schema) is the exact foundation of AutoSci — an agent that turns the wiki into a research memory and then does autonomous science on top of it. All on Claude Code:\r\n - 📚 Ingest papers into a cross-linked wiki of concept/method/idea pages ([[wikilinks]], contradiction edges — the LLM-Wiki, fully realized)\r\n - 💡 Ideate → experiment → write: it reads its own memory to generate ideas, design + run experiments, draft the paper, and handle rebuttals\r\n - 🧬 Self-evolving memory: between projects it consolidates, re-weights, and re-links the wiki (a \"sleep\" phase)\r\n - 🕸️ Multi-agent DAGs for the hard reasoning steps\r\n\r\n\r\nWe've already used it to write 3 papers end-to-end. Fully open (MIT).\r\n\r\n⭐ If this is where you want LLM-Wikis to go, a star genuinely helps us! and we welcome issues/PRs/Contributors\r\n👉 https://github.com/skyllwt/AutoSci\r\n📄 Paper: https://arxiv.org/abs/2605.31468\r\n\r\nDemo: 【北大做了一个会自我进化的科研 Agent:AutoSci】 https://www.bilibili.com/video/BV19gVg6pEk6/?share_source=copy_web&vd_source=338de971cb27f42aaaf5d8bfdeed04b3\r\n\r\n \r\n\r\nRED: 北大做了一个“越做科研越聪明”的AI科学家 北大团队... http://xhslink.com/o/2clEkgugEPw \r\n复制后打开【小红书】查看笔记!\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6178840",
"id": 6178840,
"node_id": "GC_lADOAX9eA9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeSBg",
"user": {
"login": "Z-M-Huang",
"id": 25124355,
"node_id": "MDQ6VXNlcjI1MTI0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/25124355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Z-M-Huang",
"html_url": "https://github.com/Z-M-Huang",
"followers_url": "https://api.github.com/users/Z-M-Huang/followers",
"following_url": "https://api.github.com/users/Z-M-Huang/following{/other_user}",
"gists_url": "https://api.github.com/users/Z-M-Huang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Z-M-Huang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Z-M-Huang/subscriptions",
"organizations_url": "https://api.github.com/users/Z-M-Huang/orgs",
"repos_url": "https://api.github.com/users/Z-M-Huang/repos",
"events_url": "https://api.github.com/users/Z-M-Huang/events{/privacy}",
"received_events_url": "https://api.github.com/users/Z-M-Huang/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-02T01:16:46Z",
"updated_at": "2026-06-02T01:16:46Z",
"body": "## Dense-Mem: memory beyond RAG\r\n
\r\n\r\nRED: 北大做了一个“越做科研越聪明”的AI科学家 北大团队... http://xhslink.com/o/2clEkgugEPw \r\n复制后打开【小红书】查看笔记!\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6178840",
"id": 6178840,
"node_id": "GC_lADOAX9eA9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeSBg",
"user": {
"login": "Z-M-Huang",
"id": 25124355,
"node_id": "MDQ6VXNlcjI1MTI0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/25124355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Z-M-Huang",
"html_url": "https://github.com/Z-M-Huang",
"followers_url": "https://api.github.com/users/Z-M-Huang/followers",
"following_url": "https://api.github.com/users/Z-M-Huang/following{/other_user}",
"gists_url": "https://api.github.com/users/Z-M-Huang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Z-M-Huang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Z-M-Huang/subscriptions",
"organizations_url": "https://api.github.com/users/Z-M-Huang/orgs",
"repos_url": "https://api.github.com/users/Z-M-Huang/repos",
"events_url": "https://api.github.com/users/Z-M-Huang/events{/privacy}",
"received_events_url": "https://api.github.com/users/Z-M-Huang/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-02T01:16:46Z",
"updated_at": "2026-06-02T01:16:46Z",
"body": "## Dense-Mem: memory beyond RAG\r\n \r\n\r\nI built an open-source MCP memory server called Dense-Mem:\r\n\r\nhttps://github.com/markhuangai/dense-mem\r\n\r\nI built an open-source MCP memory server called **Dense-Mem**:\r\n\r\nhttps://github.com/markhuangai/dense-mem\r\n\r\nThe idea I am trying to explore is that RAG is very useful for retrieval, but durable AI memory may need more than vector search alone.\r\n\r\nIn daily LLM workflows, the hard problems are often not just \"find a similar chunk.\" They are questions like:\r\n\r\n- What did the user actually say?\r\n- Is this evidence, a proposed claim, or an accepted fact?\r\n- Is there a newer fact that supersedes the old one?\r\n- Are two memories in conflict?\r\n- What source supports this answer?\r\n- Can the same memory be reused across different AI tools?\r\n\r\nSo Dense-Mem separates the host LLM from the memory layer:\r\n\r\n- the host LLM handles conversation and judgment\r\n- Dense-Mem stores evidence, typed claims, accepted facts, provenance, conflicts, embeddings, and graph recall\r\n- MCP clients can recall the same durable memory instead of rebuilding context from scratch every session\r\n\r\nI wrote more about the motivation here:\r\n\r\nhttps://markhuang.ai/blog/ai-memory-beyond-rag\r\n\r\nAnd I made a hosted demo so people can try it without self-hosting:\r\n\r\nhttps://markhuang.ai/blog/dense-mem-hosted-demo-test-instance\r\n\r\nI do not want to overclaim that this \"solves memory.\" I am mostly curious whether this architecture feels useful, overbuilt, or missing something important.\r\n\r\nIf anyone has thoughts, I would especially appreciate critique on:\r\n\r\n1. Does the memory-server / host-LLM boundary make sense?\r\n2. Is graph-backed memory a useful abstraction here, or should this remain simpler?\r\n3. What evaluation would best show whether this improves accuracy in real daily LLM workflows?\r\n4. What failure modes should I test before claiming this direction is useful?\r\n\r\nThanks for reading. I would genuinely value technical pushback."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6180300",
"id": 6180300,
"node_id": "GC_lADOAGxsBNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeTcw",
"user": {
"login": "mikhashev",
"id": 7105540,
"node_id": "MDQ6VXNlcjcxMDU1NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7105540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mikhashev",
"html_url": "https://github.com/mikhashev",
"followers_url": "https://api.github.com/users/mikhashev/followers",
"following_url": "https://api.github.com/users/mikhashev/following{/other_user}",
"gists_url": "https://api.github.com/users/mikhashev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mikhashev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mikhashev/subscriptions",
"organizations_url": "https://api.github.com/users/mikhashev/orgs",
"repos_url": "https://api.github.com/users/mikhashev/repos",
"events_url": "https://api.github.com/users/mikhashev/events{/privacy}",
"received_events_url": "https://api.github.com/users/mikhashev/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-02T20:42:05Z",
"updated_at": "2026-06-17T12:13:53Z",
"body": "Follow-up on our [knowledge-as-weights post](https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f?permalink_comment_id=6152776#gistcomment-6152776). Last time we asked: what if a personal model could learn and grow with you -- encoding confirmed knowledge directly in weights, adding new facts as you learn them, no RAG needed? Two weeks and 52 experiments later, we have a partial answer: below ~10M parameters, we could not make knowledge-in-weights work via any mechanism we tested -- LoRA injection, test-time training, or architecture changes. Here's the journey.\r\n\r\n**The vision:** We're building [DPC Messenger](https://github.com/mikhashev/dpc-messenger/tree/dev) -- peer-to-peer infrastructure for human-AI co-evolution. A space where people and AI grow together. The target (knowledge-in-weights) architecture (designed, not yet implemented) uses continual LoRA adapters per knowledge cluster, with a perceptron router for O(1) adapter selection at inference. Three knowledge types are planned: static facts, dynamic state, and predictive hypotheses -- each with their own lifecycle in weights. The model would learn and grow as the person confirms new knowledge -- not one-shot injection, but continual learning. What's built today: the knowledge graph, the training pipeline, and the diagnostic tooling. What's not built yet: the adapter routing, the knowledge-type lifecycle, and the continual learning loop itself. But first we needed to know: how small can the knowledge model be? This post maps the lower bound.\r\n\r\n**Phase 1: \"Can a small model learn our domain?\" (11 experiments)**\r\nWe adapted the [autoresearch framework](https://github.com/jsegov/autoresearch-win-rtx) (based on [karpathy/nanoGPT](https://github.com/karpathy/nanogpt)) with a custom training pipeline and experiment workflow for domain-specific knowledge encoding. All 52 experiments are logged with full reproducibility metadata (hyperparameters, timings, per-epoch metrics). We trained on a personal knowledge corpus -- 278K documents (~7.5M tokens) of domain-specific triples from a knowledge graph plus natural text. Question: can a tiny model reach reasonable perplexity on structured knowledge?\r\n\r\nTinyStories baseline: val_bpb 1.221. Our corpus: 1.682. The domain gap is real -- structured triples are harder than simple narratives. We tried dropout (no effect), smaller models (worse at same compute budget), larger models (overfit). The floor on our corpus is ~0.98 val_bpb, regardless of architecture (confirmed across two independent architectures: 4L/256d at 3.7M params and 8L/128d at 2.0M params). Width matters more than depth at fixed compute -- 4L x 256d beats 8L x 128d consistently. Seed variance dominated architectural differences in our measurements. The model learns the domain, but the data ceiling is immutable at this corpus size.\r\n\r\n**Phase 2: \"Does architecture matter?\" (21 experiments)**\r\nSystematic sweep of 5 architectural knobs: MLP ratio, GQA, value embeddings, RMSNorm, weight tying. Answer: mostly noise at this scale. One exception -- weight tying saves 50% of parameters with zero quality loss, giving us our final 3.7M param model. BERT-style encoder tested at matched scale (~30M params) -- decoder beats encoder by +1.24 bpb. Value embeddings are load-bearing (removing them costs +0.116 bpb at matched parameter count). The take-away: at sub-10M scale, architecture is second-order. The first-order constraints are data and compute.\r\n\r\n**Phase 3: \"Can we inject knowledge via gradients?\" (600 combinations)**\r\nTest-time training (TTT) sweep: 600 combinations of learning rate, steps, and fact count on a 37M param model. Result: 0/600 newly recalled facts. The model overfits on injection token patterns while loss drops to 0.01. It memorizes the surface form of injection text but cannot extract semantic subject-predicate-object associations. Via teacher forcing, entity accuracy is 19.4% -- facts are weakly present in weights, but free recall fails completely.\r\n\r\n**Phase 4: \"Can LoRA inject knowledge?\" (4 experiments + diagnostics)**\r\nThis is where we expected success. Xu et al. (2026) show that LoRA knowledge injection requires per-token probability above p=0.5 -- the phase-transition threshold for stable recall (Parametric Memory Law, arXiv:2605.30260). We tried it at 3.7M.\r\n\r\n| Config | LoRA target | Rank | Params injected | LR | top-1 recall | top-10 collapse |\r\n|--------|------------|------|-----------------|------|-------------|-----------------|\r\n| MLP-only | c_fc, c_proj | 16 | 164K (4.5% of model) | 1e-4 | 0.49% -> 0% by epoch 3 | epoch 6 |\r\n| MLP-only | c_fc, c_proj | 16 | 164K | 1e-3 | 0.49% -> 0% by epoch 1 | epoch 2 |\r\n| Attn-only | c_q, c_v | 16 | 65K (1.8% of model) | 1e-4 | 0.49% -> 0% by epoch 4 | by epoch 9 |\r\n\r\nLoss decreased monotonically in every run while recall died. The model learned to minimize loss on injection text via existing non-factual patterns -- not by encoding new facts.\r\n\r\n**The diagnostic that explained everything:**\r\nWe built a 5-metric diagnostic pipeline (D1-D5) and measured per-token probability p(fact) -- the model's confidence on correct factual completions. Result: **zero tokens above p=0.5 even BEFORE LoRA training.** Out of 1,214 injected facts: max p(fact) = 0.29, mean = 0.008. Post-LoRA training: max dropped to 0.02, mean to 0.002.\r\n\r\nXu et al. (2026) identify p=0.5 as the critical threshold for stable recall. Our model's ceiling is ~60x below that. This rules out \"LoRA optimization problem\" and confirms \"structural capacity problem\" -- the model cannot encode facts at sufficient probability for stable recall. No amount of adapter tuning fixes this.\r\n\r\nAdditional diagnostic: base model gradients are 600-5000x larger than LoRA gradients (ratio grows as training progresses). The adapter barely influences the model despite measurable loss reduction.\r\n\r\n**Why existing literature didn't predict this:**\r\nThree recent LoRA knowledge-injection papers (Xu et al. 2026 on the parametric memory law, \"Understanding LoRA as Knowledge Memory\" ICML 2026, \"LoRA Rank Trade-offs\" Dec 2025) all test on 7B+ parameters -- three orders of magnitude larger than our model. At 4 layers, MLP-only LoRA perturbs 50% of the model; attention-only perturbs 18%. At 24+ layers those numbers drop to ~4% and ~1.5% respectively. LoRA assumes deep enough models that adapters are small perturbations -- that assumption breaks below ~10M parameters.\r\n\r\n**What's next:**\r\nScaling up to 10-50M parameters (12-16 layers) where LoRA perturbation drops below 5%. Running the same D1-D5 diagnostic pipeline on each checkpoint to find where p(fact) crosses the 0.5 threshold. If it does, we have the minimum viable model size for personal LoRA knowledge injection. If it doesn't, the knowledge-as-weights hypothesis needs a fundamentally different injection mechanism at this scale.\r\n\r\n**Hardware:** All experiments on a single RTX 3060 12GB (Xeon E3-1240 V2). Full scaling-laws grid (~9 configs) runs in ~1.5 hours. LoRA experiments + diagnostics: ~2 hours. This is entirely reproducible on consumer hardware."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6180493",
"id": 6180493,
"node_id": "GC_lADOBPeCRdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeTo0",
"user": {
"login": "MuhammadSaqlainAslam",
"id": 83329605,
"node_id": "MDQ6VXNlcjgzMzI5NjA1",
"avatar_url": "https://avatars.githubusercontent.com/u/83329605?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MuhammadSaqlainAslam",
"html_url": "https://github.com/MuhammadSaqlainAslam",
"followers_url": "https://api.github.com/users/MuhammadSaqlainAslam/followers",
"following_url": "https://api.github.com/users/MuhammadSaqlainAslam/following{/other_user}",
"gists_url": "https://api.github.com/users/MuhammadSaqlainAslam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MuhammadSaqlainAslam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MuhammadSaqlainAslam/subscriptions",
"organizations_url": "https://api.github.com/users/MuhammadSaqlainAslam/orgs",
"repos_url": "https://api.github.com/users/MuhammadSaqlainAslam/repos",
"events_url": "https://api.github.com/users/MuhammadSaqlainAslam/events{/privacy}",
"received_events_url": "https://api.github.com/users/MuhammadSaqlainAslam/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-03T02:31:03Z",
"updated_at": "2026-06-03T03:20:24Z",
"body": "Hi Andrej — your gist inspired this project at the AI Research Center, Hon Hai Research Institute (Foxconn).\r\n🌐 Live demo: https://muhammadsaqlainaslam.github.io/my-llm-wiki\r\n📦 Repo: https://github.com/MuhammadSaqlainAslam/my-llm-wiki\r\n🏛️ Institute: https://hhri.foxconn.com/en\r\nWhat we built on top of your pattern:\r\n🤖 Agentic ingestion — one command searches arXiv, GitHub, blogs, and YouTube transcripts, generates structured notes, and deploys automatically:\r\npython3 agent.py topic \"Mamba 2 SSM improvements\"\r\n📚 Citation intelligence — every paper shows its total citations plus the top 10 most-cited papers that reference it, tracing the full intellectual thread from the 2017 Transformer through 2025 inference optimization.\r\n🌐 Interactive web demo — browse 150+ notes, full-text search with Ctrl+F-style match navigation, side-by-side paper comparison, D3 knowledge graph where node size = citation count, and a timeline from 2017→2026. Fully mobile responsive.\r\n🔗 Deep cross-linking — every note shows backlinks. \"Attention is All You Need\" has 46 backlinks — the most referenced paper in the wiki, as expected.\r\nCoverage: Transformer → FlashAttention → S4 → Mamba → Mamba-2 → Mamba-3 → xLSTM → RWKV → RetNet → Griffin → Speculative Decoding → KV Cache → DeepSeek-V4 · 50+ concept glossary stubs\r\nStack: Claude API (Vertex AI) · PyMuPDF · D3.js · KaTeX · GitHub Pages · Obsidian + Dataview"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6181761",
"id": 6181761,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeU4E",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-03T18:27:19Z",
"updated_at": "2026-06-03T18:27:19Z",
"body": "### Synto v0.5.0 is out.\r\n\r\n https://github.com/kytmanov/synto\r\n\r\n- Main addition: **per-role providers**. Run each model where it makes sense - small fast model on local Ollama, heavy writing model on a cloud endpoint. Each role gets its own provider, connection, and key. `synto setup` walks you through the split.\r\n\r\n**Also new in v0.5:**\r\n\r\n- **rename a concept** everywhere: `synto concept rename OLD NEW` moves the article, repoints every inbound link, and migrates the state DB.\r\n- **per-model knobs**: context size, temperature, thinking on/off. Thinking models (Qwen 3.5, DeepSeek-R1) no longer time out on ingest.\r\n- **Anthropic-compatible API support**, on top of OpenAI-compatible - point any role at Kimi and similar endpoints.\r\n \r\nSame shape as before:\r\n - works with local LLMs\r\n - great with Ollama and LM Studio\r\n - plain Markdown\r\n - Obsidian-friendly\r\n - no vector DB\r\n - no cloud required\r\n - multi-language\r\n\r\nStar it if you want to support local-first AI tools. Fork it if you want to build on it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183384",
"id": 6183384,
"node_id": "GC_lADOBeZH0NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeWdg",
"user": {
"login": "Electro-resonance",
"id": 98977744,
"node_id": "U_kgDOBeZH0A",
"avatar_url": "https://avatars.githubusercontent.com/u/98977744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Electro-resonance",
"html_url": "https://github.com/Electro-resonance",
"followers_url": "https://api.github.com/users/Electro-resonance/followers",
"following_url": "https://api.github.com/users/Electro-resonance/following{/other_user}",
"gists_url": "https://api.github.com/users/Electro-resonance/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Electro-resonance/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Electro-resonance/subscriptions",
"organizations_url": "https://api.github.com/users/Electro-resonance/orgs",
"repos_url": "https://api.github.com/users/Electro-resonance/repos",
"events_url": "https://api.github.com/users/Electro-resonance/events{/privacy}",
"received_events_url": "https://api.github.com/users/Electro-resonance/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-04T20:41:44Z",
"updated_at": "2026-06-04T20:41:44Z",
"body": "I’d posted previously about my own implementation here:\r\n\r\n[https://github.com/Electro-resonance/LLM-WIKI-MCP](https://github.com/Electro-resonance/LLM-WIKI-MCP)\r\n\r\nIt’s been fascinating reading the other implementations that have emerged from Andrej’s original post. Most seem to focus on the core idea of transforming source material into a maintained wiki that acts as a higher-quality retrieval layer than traditional RAG.\r\n\r\nMine wandered off in a slightly different direction, as these things tend to do once you start actually building them at midnight after too much coffee and a folder full of half-organised notes.\r\n\r\nI wanted to see what happens when the wiki itself becomes an MCP-accessible system rather than simply a collection of generated pages. That led to features such as provenance-aware ingestion, recursive conversational memory, self-maintaining notes, runtime introspection, and agent-callable maintenance tools.\r\n\r\nOne area I’ve focused on quite heavily is provenance. Rather than simply ingesting files and forgetting where they came from, the system records source metadata, timestamps, hashes, and file locations. When ingest is run again, unchanged files can be skipped, modified files can be updated, and multiple files with the same name can coexist if they originate from different locations. It is a bit like treating the wiki as a compiled knowledge artefact rather than a one-shot summary pile.\r\n\r\nThe other slightly strange experiment is the notes layer. The source wiki stores the extracted knowledge, while the AI sidecar notes store inferred relationships, possible cross-links, odd little “this might matter later” observations, and future investigation paths. It gives the system a second layer of memory that feels a bit less like filing and a bit more like rummaging through a research notebook with the margins full of arrows.\r\n\r\nI see these projects less as competitors and more as different expeditions into the design space opened up by Andrej’s original LLM Wiki concept. I’d be interested to hear how others are approaching provenance, long-term maintenance, self-reflection, and agent-driven evolution of the wiki itself.\r\n\r\nAlso, I now have the slightly ridiculous situation where the tool can ingest its own docs and then answer questions about how it works, which feels either useful, recursive, or like I have accidentally taught a filing cabinet to talk about itself."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183538",
"id": 6183538,
"node_id": "GC_lADOEPNlstoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeWnI",
"user": {
"login": "GovernorOfEntropy",
"id": 284386738,
"node_id": "U_kgDOEPNlsg",
"avatar_url": "https://avatars.githubusercontent.com/u/284386738?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GovernorOfEntropy",
"html_url": "https://github.com/GovernorOfEntropy",
"followers_url": "https://api.github.com/users/GovernorOfEntropy/followers",
"following_url": "https://api.github.com/users/GovernorOfEntropy/following{/other_user}",
"gists_url": "https://api.github.com/users/GovernorOfEntropy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GovernorOfEntropy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GovernorOfEntropy/subscriptions",
"organizations_url": "https://api.github.com/users/GovernorOfEntropy/orgs",
"repos_url": "https://api.github.com/users/GovernorOfEntropy/repos",
"events_url": "https://api.github.com/users/GovernorOfEntropy/events{/privacy}",
"received_events_url": "https://api.github.com/users/GovernorOfEntropy/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T00:21:37Z",
"updated_at": "2026-06-05T00:21:37Z",
"body": "> Been running Karpathy's LLM-Wiki pattern for five weeks now.\r\n> \r\n> The compounding effect is real. Drop a paper, get a cross-linked wiki page. Ask a question, get a cited answer that gets filed back into the graph. The maintenance burden is near zero because the LLM does the bookkeeping.\r\n> \r\n> But — when I tried to scale it beyond markdown notes, I hit a wall.\r\n> \r\n> PDFs needed PyMuPDF. Office docs needed python-docx. Video transcripts needed Whisper. Structured LLM outputs needed Instructor. Each tool had its own vault, its own SQLite schema, its own API surface. I built a 450-line Python glue layer to stitch them together.\r\n> \r\n> The glue proved the problem: **fragmentation at the architecture layer.** Four vaults, four schemas, wikilink collisions, frontmatter drift, MCP namespace explosions. Glue is insufficient because it preserves the fragmentation; it just moves it around.\r\n> \r\n> So I wrote a spec for unification at the architecture layer instead:\r\n> \r\n> **Mnemosyne** — a local-first semantic memory OS with a Rust core and Python satellites.\r\n> \r\n> * One vault: `raw/`, `wiki/`, `memory/`, `packs/`\r\n> * One schema: SQLite `state.db` with `pages`, `links`, `jobs`, `conversations`, `audit_log`, `contradictions`\r\n> * One API: MCP + REST + CLI from day one\r\n> * Rust core: schema, job queue, graph traversal, API surface\r\n> * Python satellites: PDF extraction, office docs, video/audio transcripts, LLM client glue, structured compilation\r\n> * Two-tier compilation: fast model (30B) extracts concepts, heavy model (70B+) writes cross-linked articles\r\n> * Audit engine: structural lint → contradiction detection → adversarial review\r\n> * Provenance-first: every claim carries citation, every LLM call carries cost log\r\n> \r\n> The Python satellites are permanent, not transitional. Rust cannot yet match Python's depth in document extraction (pymupdf, python-docx, Whisper) or structured LLM output (Instructor, Pydantic-AI). The Rust core spawns them as subprocesses, receives JSON, and integrates into the unified system.\r\n> \r\n> Status: architecture spec complete. Seeking core contributors for Phase 1 implementation (SQLite schema, vault init, markdown ingestion, basic MCP server).\r\n> \r\n> Spec: https://github.com/noirblue/IsaacCLupus_mnemosyn_spec\r\n> \r\n> If you've hit the same fragmentation wall trying to scale the LLM-Wiki pattern, I'd love to talk.\r\n\r\nI hit the scale limit too and am trying to solve for it. This project and my own were on parallel tracks but the concept is the same. I see the core issue is the number of edges in the graph node just overwhelm the llm at some point. wikipedia keeps their edges manually inserted and sparse. if they really densified the edges, it would collapse."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183984",
"id": 6183984,
"node_id": "GC_lADOAiGVz9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXDA",
"user": {
"login": "pursultani",
"id": 35755471,
"node_id": "MDQ6VXNlcjM1NzU1NDcx",
"avatar_url": "https://avatars.githubusercontent.com/u/35755471?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pursultani",
"html_url": "https://github.com/pursultani",
"followers_url": "https://api.github.com/users/pursultani/followers",
"following_url": "https://api.github.com/users/pursultani/following{/other_user}",
"gists_url": "https://api.github.com/users/pursultani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pursultani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pursultani/subscriptions",
"organizations_url": "https://api.github.com/users/pursultani/orgs",
"repos_url": "https://api.github.com/users/pursultani/repos",
"events_url": "https://api.github.com/users/pursultani/events{/privacy}",
"received_events_url": "https://api.github.com/users/pursultani/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T08:15:25Z",
"updated_at": "2026-06-05T08:15:25Z",
"body": "**TL;DR**\r\n\r\nThe pattern defaults to a convergent epistemology where contradiction is a defect. In subjective domains, like the humanities, contradiction is information. This is not one problem but two that are usually run together. There is a policy default, where the rules treat contradiction as degradation, and a representation gap, where untyped edges cannot express a contradiction as anything other than a flag. Fixing it needs both. You need a policy that preserves contradictions and a representation that can hold them. Typed edges\r\nsupply the second. However, they do not, on their own, supply the first.\r\n\r\n### The philosophical problem\r\n\r\nThe pattern's default rules treat contradiction as a defect to be resolved. The lint pass groups contradictions with stale claims and orphans, which are genuine defects, and the \"synthesis\" framing treats a single reconciled account as the goal.\r\n\r\nThis is a specific epistemological assumption. It holds for scientific and technical knowledge, with an objective epistemology, where two conflicting claims about the same entity cannot both be true. It breaks in domains where knowledge is inherently dialogic. In literary criticism, the tension between [Bloom's anxiety of influence](https://en.wikipedia.org/wiki/Anxiety_of_influence) and [de Man's deconstructive](https://en.wikipedia.org/wiki/Paul_de_Man) reading of the same texts is not a data-quality problem. It is the intellectual content itself. In philosophy, Wittgenstein contradicting his earlier self is not drift to correct. It is the history of analytic philosophy. In historiography, structurally incompatible accounts of the same period are not redundant sources awaiting synthesis.\r\n\r\nIn these domains the lint pass should check for _missing_ contradictions, not flag existing ones. But notice this is a change to the rules in `CLAUDE.md`, not to the data model. You could keep bare wikilinks and fix most of this today just by rewriting the lint and lifecycle instructions to preserve tension instead of reconciling it. That is the part typed edges alone will not do for you.\r\n\r\n### The representation gap\r\n\r\nThe reason the better policy is awkward to express is structural. The architecture is a graph with typed nodes (pages) but untyped edges (wikilinks). A bare `[[page]]` carries no information about the nature of the relationship. \"contradicts\", \"supports\", \"extends\", \"supersedes\", \"was a response to\" all collapse into the same link. So even once your policy says to preserve a contradiction, the graph has nowhere to put that fact except a prose note or a lint flag.\r\n\r\nThis is well understood in knowledge representation. Property graphs and RDF/OWL both make typed, attributable edges a first-class primitive. And some implementations in this very thread already reach for it. [AutoSci](https://github.com/skyllwt/AutoSci) ships \"contradiction edges\", and [Dense-Mem](https://github.com/markhuangai/dense-mem) models conflicts as typed claims rather than as a health warning. So the representation is not unheard of.\r\n\r\nWhat is missing is making it general, and, crucially, pairing it with the policy, because a `contradicts` edge is worthless if the lint rule still treats it as something to clean up.\r\n\r\nWith typed edges and a policy that respects them, A and B linked by `contradicts` become navigable, queryable structure rather than a maintenance flag. Querying becomes traversal. \"what supports this claim\" and \"what challenges it\" are graph operations, not semantic searches.\r\n\r\n### A practical solution, in two parts\r\n\r\nThe representation is a set of front-matter relationship blocks, where each page declares its typed outbound relationships in YAML, queryable via Obsidian Dataview. The LLM maintains this block on every ingest:\r\n\r\n```yaml\r\n---\r\nrelates_to:\r\n - page: \"Judith Butler\"\r\n rel: contradicts\r\n - page: \"Harold Bloom\"\r\n rel: extends\r\n---\r\n```\r\n\r\nThe policy is the load-bearing part. The permitted relationship vocabulary, the rules for when each type applies, and the instruction that in dialogic domains a `contradicts` edge is preserved while a lack of expected contradictions is the lint smell, all live in the schema document (`CLAUDE.md`). That makes edge typing a first-class part of the wiki's behavioral contract rather than an\r\nafterthought.\r\n\r\n### Caveats\r\n\r\nThe main open problem is vocabulary governance. Having the LLM maintain a controlled relationship vocabulary on every ingest invites the same drift and mis-typing other commenters have flagged at the frontmatter layer, and deciding when something is `extends` versus `supersedes` versus `was a response to` is real ontology work, not something the schema gets for free. But that is a\r\ntractable maintenance cost, and it buys a wiki that can hold a disagreement instead of dissolving it.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183986",
"id": 6183986,
"node_id": "GC_lADOB7kmgNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXDI",
"user": {
"login": "Archimondstat",
"id": 129574528,
"node_id": "U_kgDOB7kmgA",
"avatar_url": "https://avatars.githubusercontent.com/u/129574528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Archimondstat",
"html_url": "https://github.com/Archimondstat",
"followers_url": "https://api.github.com/users/Archimondstat/followers",
"following_url": "https://api.github.com/users/Archimondstat/following{/other_user}",
"gists_url": "https://api.github.com/users/Archimondstat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Archimondstat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Archimondstat/subscriptions",
"organizations_url": "https://api.github.com/users/Archimondstat/orgs",
"repos_url": "https://api.github.com/users/Archimondstat/repos",
"events_url": "https://api.github.com/users/Archimondstat/events{/privacy}",
"received_events_url": "https://api.github.com/users/Archimondstat/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T08:17:40Z",
"updated_at": "2026-06-05T08:17:40Z",
"body": "One concern I have is that an Obsidian vault may eventually become filled with AI-generated summaries or hallucinated notes that the user never truly internalizes or uses. If the hallucination probability of each AI-generated note is non-zero, then under repeated use, the probability that the vault contains at least one hallucinated note approaches 1 as the number of generated notes grows.\r\n\r\nSo I would like to propose an idea, which I call the **\"Socrates–Plato–Bayes Learning System\"**.\r\n\r\nInstead of letting the AI or the system directly learn, summarize, and populate the wiki, the user should first propose their own idea, hypothesis, or interpretation. Then the AI acts as a Socratic challenger: questioning it, finding weaknesses, offering counterexamples, and checking it against external knowledge.\r\n\r\nAfter that, the user updates their original idea based on the AI's challenges, almost like a Bayesian posterior update. Only when the idea has survived this process should it be promoted into the wiki.\r\n\r\nIn other words, the wiki should not be a place where AI stores what it thinks the user should know. It should be a place where the user's own ideas are refined, challenged, and crystallized."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184352",
"id": 6184352,
"node_id": "GC_lADOAAjdUtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXaA",
"user": {
"login": "theluk",
"id": 580946,
"node_id": "MDQ6VXNlcjU4MDk0Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/580946?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theluk",
"html_url": "https://github.com/theluk",
"followers_url": "https://api.github.com/users/theluk/followers",
"following_url": "https://api.github.com/users/theluk/following{/other_user}",
"gists_url": "https://api.github.com/users/theluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theluk/subscriptions",
"organizations_url": "https://api.github.com/users/theluk/orgs",
"repos_url": "https://api.github.com/users/theluk/repos",
"events_url": "https://api.github.com/users/theluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/theluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T13:01:34Z",
"updated_at": "2026-06-05T13:01:34Z",
"body": "
\r\n\r\nI built an open-source MCP memory server called Dense-Mem:\r\n\r\nhttps://github.com/markhuangai/dense-mem\r\n\r\nI built an open-source MCP memory server called **Dense-Mem**:\r\n\r\nhttps://github.com/markhuangai/dense-mem\r\n\r\nThe idea I am trying to explore is that RAG is very useful for retrieval, but durable AI memory may need more than vector search alone.\r\n\r\nIn daily LLM workflows, the hard problems are often not just \"find a similar chunk.\" They are questions like:\r\n\r\n- What did the user actually say?\r\n- Is this evidence, a proposed claim, or an accepted fact?\r\n- Is there a newer fact that supersedes the old one?\r\n- Are two memories in conflict?\r\n- What source supports this answer?\r\n- Can the same memory be reused across different AI tools?\r\n\r\nSo Dense-Mem separates the host LLM from the memory layer:\r\n\r\n- the host LLM handles conversation and judgment\r\n- Dense-Mem stores evidence, typed claims, accepted facts, provenance, conflicts, embeddings, and graph recall\r\n- MCP clients can recall the same durable memory instead of rebuilding context from scratch every session\r\n\r\nI wrote more about the motivation here:\r\n\r\nhttps://markhuang.ai/blog/ai-memory-beyond-rag\r\n\r\nAnd I made a hosted demo so people can try it without self-hosting:\r\n\r\nhttps://markhuang.ai/blog/dense-mem-hosted-demo-test-instance\r\n\r\nI do not want to overclaim that this \"solves memory.\" I am mostly curious whether this architecture feels useful, overbuilt, or missing something important.\r\n\r\nIf anyone has thoughts, I would especially appreciate critique on:\r\n\r\n1. Does the memory-server / host-LLM boundary make sense?\r\n2. Is graph-backed memory a useful abstraction here, or should this remain simpler?\r\n3. What evaluation would best show whether this improves accuracy in real daily LLM workflows?\r\n4. What failure modes should I test before claiming this direction is useful?\r\n\r\nThanks for reading. I would genuinely value technical pushback."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6180300",
"id": 6180300,
"node_id": "GC_lADOAGxsBNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeTcw",
"user": {
"login": "mikhashev",
"id": 7105540,
"node_id": "MDQ6VXNlcjcxMDU1NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7105540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mikhashev",
"html_url": "https://github.com/mikhashev",
"followers_url": "https://api.github.com/users/mikhashev/followers",
"following_url": "https://api.github.com/users/mikhashev/following{/other_user}",
"gists_url": "https://api.github.com/users/mikhashev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mikhashev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mikhashev/subscriptions",
"organizations_url": "https://api.github.com/users/mikhashev/orgs",
"repos_url": "https://api.github.com/users/mikhashev/repos",
"events_url": "https://api.github.com/users/mikhashev/events{/privacy}",
"received_events_url": "https://api.github.com/users/mikhashev/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-02T20:42:05Z",
"updated_at": "2026-06-17T12:13:53Z",
"body": "Follow-up on our [knowledge-as-weights post](https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f?permalink_comment_id=6152776#gistcomment-6152776). Last time we asked: what if a personal model could learn and grow with you -- encoding confirmed knowledge directly in weights, adding new facts as you learn them, no RAG needed? Two weeks and 52 experiments later, we have a partial answer: below ~10M parameters, we could not make knowledge-in-weights work via any mechanism we tested -- LoRA injection, test-time training, or architecture changes. Here's the journey.\r\n\r\n**The vision:** We're building [DPC Messenger](https://github.com/mikhashev/dpc-messenger/tree/dev) -- peer-to-peer infrastructure for human-AI co-evolution. A space where people and AI grow together. The target (knowledge-in-weights) architecture (designed, not yet implemented) uses continual LoRA adapters per knowledge cluster, with a perceptron router for O(1) adapter selection at inference. Three knowledge types are planned: static facts, dynamic state, and predictive hypotheses -- each with their own lifecycle in weights. The model would learn and grow as the person confirms new knowledge -- not one-shot injection, but continual learning. What's built today: the knowledge graph, the training pipeline, and the diagnostic tooling. What's not built yet: the adapter routing, the knowledge-type lifecycle, and the continual learning loop itself. But first we needed to know: how small can the knowledge model be? This post maps the lower bound.\r\n\r\n**Phase 1: \"Can a small model learn our domain?\" (11 experiments)**\r\nWe adapted the [autoresearch framework](https://github.com/jsegov/autoresearch-win-rtx) (based on [karpathy/nanoGPT](https://github.com/karpathy/nanogpt)) with a custom training pipeline and experiment workflow for domain-specific knowledge encoding. All 52 experiments are logged with full reproducibility metadata (hyperparameters, timings, per-epoch metrics). We trained on a personal knowledge corpus -- 278K documents (~7.5M tokens) of domain-specific triples from a knowledge graph plus natural text. Question: can a tiny model reach reasonable perplexity on structured knowledge?\r\n\r\nTinyStories baseline: val_bpb 1.221. Our corpus: 1.682. The domain gap is real -- structured triples are harder than simple narratives. We tried dropout (no effect), smaller models (worse at same compute budget), larger models (overfit). The floor on our corpus is ~0.98 val_bpb, regardless of architecture (confirmed across two independent architectures: 4L/256d at 3.7M params and 8L/128d at 2.0M params). Width matters more than depth at fixed compute -- 4L x 256d beats 8L x 128d consistently. Seed variance dominated architectural differences in our measurements. The model learns the domain, but the data ceiling is immutable at this corpus size.\r\n\r\n**Phase 2: \"Does architecture matter?\" (21 experiments)**\r\nSystematic sweep of 5 architectural knobs: MLP ratio, GQA, value embeddings, RMSNorm, weight tying. Answer: mostly noise at this scale. One exception -- weight tying saves 50% of parameters with zero quality loss, giving us our final 3.7M param model. BERT-style encoder tested at matched scale (~30M params) -- decoder beats encoder by +1.24 bpb. Value embeddings are load-bearing (removing them costs +0.116 bpb at matched parameter count). The take-away: at sub-10M scale, architecture is second-order. The first-order constraints are data and compute.\r\n\r\n**Phase 3: \"Can we inject knowledge via gradients?\" (600 combinations)**\r\nTest-time training (TTT) sweep: 600 combinations of learning rate, steps, and fact count on a 37M param model. Result: 0/600 newly recalled facts. The model overfits on injection token patterns while loss drops to 0.01. It memorizes the surface form of injection text but cannot extract semantic subject-predicate-object associations. Via teacher forcing, entity accuracy is 19.4% -- facts are weakly present in weights, but free recall fails completely.\r\n\r\n**Phase 4: \"Can LoRA inject knowledge?\" (4 experiments + diagnostics)**\r\nThis is where we expected success. Xu et al. (2026) show that LoRA knowledge injection requires per-token probability above p=0.5 -- the phase-transition threshold for stable recall (Parametric Memory Law, arXiv:2605.30260). We tried it at 3.7M.\r\n\r\n| Config | LoRA target | Rank | Params injected | LR | top-1 recall | top-10 collapse |\r\n|--------|------------|------|-----------------|------|-------------|-----------------|\r\n| MLP-only | c_fc, c_proj | 16 | 164K (4.5% of model) | 1e-4 | 0.49% -> 0% by epoch 3 | epoch 6 |\r\n| MLP-only | c_fc, c_proj | 16 | 164K | 1e-3 | 0.49% -> 0% by epoch 1 | epoch 2 |\r\n| Attn-only | c_q, c_v | 16 | 65K (1.8% of model) | 1e-4 | 0.49% -> 0% by epoch 4 | by epoch 9 |\r\n\r\nLoss decreased monotonically in every run while recall died. The model learned to minimize loss on injection text via existing non-factual patterns -- not by encoding new facts.\r\n\r\n**The diagnostic that explained everything:**\r\nWe built a 5-metric diagnostic pipeline (D1-D5) and measured per-token probability p(fact) -- the model's confidence on correct factual completions. Result: **zero tokens above p=0.5 even BEFORE LoRA training.** Out of 1,214 injected facts: max p(fact) = 0.29, mean = 0.008. Post-LoRA training: max dropped to 0.02, mean to 0.002.\r\n\r\nXu et al. (2026) identify p=0.5 as the critical threshold for stable recall. Our model's ceiling is ~60x below that. This rules out \"LoRA optimization problem\" and confirms \"structural capacity problem\" -- the model cannot encode facts at sufficient probability for stable recall. No amount of adapter tuning fixes this.\r\n\r\nAdditional diagnostic: base model gradients are 600-5000x larger than LoRA gradients (ratio grows as training progresses). The adapter barely influences the model despite measurable loss reduction.\r\n\r\n**Why existing literature didn't predict this:**\r\nThree recent LoRA knowledge-injection papers (Xu et al. 2026 on the parametric memory law, \"Understanding LoRA as Knowledge Memory\" ICML 2026, \"LoRA Rank Trade-offs\" Dec 2025) all test on 7B+ parameters -- three orders of magnitude larger than our model. At 4 layers, MLP-only LoRA perturbs 50% of the model; attention-only perturbs 18%. At 24+ layers those numbers drop to ~4% and ~1.5% respectively. LoRA assumes deep enough models that adapters are small perturbations -- that assumption breaks below ~10M parameters.\r\n\r\n**What's next:**\r\nScaling up to 10-50M parameters (12-16 layers) where LoRA perturbation drops below 5%. Running the same D1-D5 diagnostic pipeline on each checkpoint to find where p(fact) crosses the 0.5 threshold. If it does, we have the minimum viable model size for personal LoRA knowledge injection. If it doesn't, the knowledge-as-weights hypothesis needs a fundamentally different injection mechanism at this scale.\r\n\r\n**Hardware:** All experiments on a single RTX 3060 12GB (Xeon E3-1240 V2). Full scaling-laws grid (~9 configs) runs in ~1.5 hours. LoRA experiments + diagnostics: ~2 hours. This is entirely reproducible on consumer hardware."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6180493",
"id": 6180493,
"node_id": "GC_lADOBPeCRdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeTo0",
"user": {
"login": "MuhammadSaqlainAslam",
"id": 83329605,
"node_id": "MDQ6VXNlcjgzMzI5NjA1",
"avatar_url": "https://avatars.githubusercontent.com/u/83329605?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MuhammadSaqlainAslam",
"html_url": "https://github.com/MuhammadSaqlainAslam",
"followers_url": "https://api.github.com/users/MuhammadSaqlainAslam/followers",
"following_url": "https://api.github.com/users/MuhammadSaqlainAslam/following{/other_user}",
"gists_url": "https://api.github.com/users/MuhammadSaqlainAslam/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MuhammadSaqlainAslam/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MuhammadSaqlainAslam/subscriptions",
"organizations_url": "https://api.github.com/users/MuhammadSaqlainAslam/orgs",
"repos_url": "https://api.github.com/users/MuhammadSaqlainAslam/repos",
"events_url": "https://api.github.com/users/MuhammadSaqlainAslam/events{/privacy}",
"received_events_url": "https://api.github.com/users/MuhammadSaqlainAslam/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-03T02:31:03Z",
"updated_at": "2026-06-03T03:20:24Z",
"body": "Hi Andrej — your gist inspired this project at the AI Research Center, Hon Hai Research Institute (Foxconn).\r\n🌐 Live demo: https://muhammadsaqlainaslam.github.io/my-llm-wiki\r\n📦 Repo: https://github.com/MuhammadSaqlainAslam/my-llm-wiki\r\n🏛️ Institute: https://hhri.foxconn.com/en\r\nWhat we built on top of your pattern:\r\n🤖 Agentic ingestion — one command searches arXiv, GitHub, blogs, and YouTube transcripts, generates structured notes, and deploys automatically:\r\npython3 agent.py topic \"Mamba 2 SSM improvements\"\r\n📚 Citation intelligence — every paper shows its total citations plus the top 10 most-cited papers that reference it, tracing the full intellectual thread from the 2017 Transformer through 2025 inference optimization.\r\n🌐 Interactive web demo — browse 150+ notes, full-text search with Ctrl+F-style match navigation, side-by-side paper comparison, D3 knowledge graph where node size = citation count, and a timeline from 2017→2026. Fully mobile responsive.\r\n🔗 Deep cross-linking — every note shows backlinks. \"Attention is All You Need\" has 46 backlinks — the most referenced paper in the wiki, as expected.\r\nCoverage: Transformer → FlashAttention → S4 → Mamba → Mamba-2 → Mamba-3 → xLSTM → RWKV → RetNet → Griffin → Speculative Decoding → KV Cache → DeepSeek-V4 · 50+ concept glossary stubs\r\nStack: Claude API (Vertex AI) · PyMuPDF · D3.js · KaTeX · GitHub Pages · Obsidian + Dataview"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6181761",
"id": 6181761,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeU4E",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-03T18:27:19Z",
"updated_at": "2026-06-03T18:27:19Z",
"body": "### Synto v0.5.0 is out.\r\n\r\n https://github.com/kytmanov/synto\r\n\r\n- Main addition: **per-role providers**. Run each model where it makes sense - small fast model on local Ollama, heavy writing model on a cloud endpoint. Each role gets its own provider, connection, and key. `synto setup` walks you through the split.\r\n\r\n**Also new in v0.5:**\r\n\r\n- **rename a concept** everywhere: `synto concept rename OLD NEW` moves the article, repoints every inbound link, and migrates the state DB.\r\n- **per-model knobs**: context size, temperature, thinking on/off. Thinking models (Qwen 3.5, DeepSeek-R1) no longer time out on ingest.\r\n- **Anthropic-compatible API support**, on top of OpenAI-compatible - point any role at Kimi and similar endpoints.\r\n \r\nSame shape as before:\r\n - works with local LLMs\r\n - great with Ollama and LM Studio\r\n - plain Markdown\r\n - Obsidian-friendly\r\n - no vector DB\r\n - no cloud required\r\n - multi-language\r\n\r\nStar it if you want to support local-first AI tools. Fork it if you want to build on it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183384",
"id": 6183384,
"node_id": "GC_lADOBeZH0NoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeWdg",
"user": {
"login": "Electro-resonance",
"id": 98977744,
"node_id": "U_kgDOBeZH0A",
"avatar_url": "https://avatars.githubusercontent.com/u/98977744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Electro-resonance",
"html_url": "https://github.com/Electro-resonance",
"followers_url": "https://api.github.com/users/Electro-resonance/followers",
"following_url": "https://api.github.com/users/Electro-resonance/following{/other_user}",
"gists_url": "https://api.github.com/users/Electro-resonance/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Electro-resonance/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Electro-resonance/subscriptions",
"organizations_url": "https://api.github.com/users/Electro-resonance/orgs",
"repos_url": "https://api.github.com/users/Electro-resonance/repos",
"events_url": "https://api.github.com/users/Electro-resonance/events{/privacy}",
"received_events_url": "https://api.github.com/users/Electro-resonance/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-04T20:41:44Z",
"updated_at": "2026-06-04T20:41:44Z",
"body": "I’d posted previously about my own implementation here:\r\n\r\n[https://github.com/Electro-resonance/LLM-WIKI-MCP](https://github.com/Electro-resonance/LLM-WIKI-MCP)\r\n\r\nIt’s been fascinating reading the other implementations that have emerged from Andrej’s original post. Most seem to focus on the core idea of transforming source material into a maintained wiki that acts as a higher-quality retrieval layer than traditional RAG.\r\n\r\nMine wandered off in a slightly different direction, as these things tend to do once you start actually building them at midnight after too much coffee and a folder full of half-organised notes.\r\n\r\nI wanted to see what happens when the wiki itself becomes an MCP-accessible system rather than simply a collection of generated pages. That led to features such as provenance-aware ingestion, recursive conversational memory, self-maintaining notes, runtime introspection, and agent-callable maintenance tools.\r\n\r\nOne area I’ve focused on quite heavily is provenance. Rather than simply ingesting files and forgetting where they came from, the system records source metadata, timestamps, hashes, and file locations. When ingest is run again, unchanged files can be skipped, modified files can be updated, and multiple files with the same name can coexist if they originate from different locations. It is a bit like treating the wiki as a compiled knowledge artefact rather than a one-shot summary pile.\r\n\r\nThe other slightly strange experiment is the notes layer. The source wiki stores the extracted knowledge, while the AI sidecar notes store inferred relationships, possible cross-links, odd little “this might matter later” observations, and future investigation paths. It gives the system a second layer of memory that feels a bit less like filing and a bit more like rummaging through a research notebook with the margins full of arrows.\r\n\r\nI see these projects less as competitors and more as different expeditions into the design space opened up by Andrej’s original LLM Wiki concept. I’d be interested to hear how others are approaching provenance, long-term maintenance, self-reflection, and agent-driven evolution of the wiki itself.\r\n\r\nAlso, I now have the slightly ridiculous situation where the tool can ingest its own docs and then answer questions about how it works, which feels either useful, recursive, or like I have accidentally taught a filing cabinet to talk about itself."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183538",
"id": 6183538,
"node_id": "GC_lADOEPNlstoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeWnI",
"user": {
"login": "GovernorOfEntropy",
"id": 284386738,
"node_id": "U_kgDOEPNlsg",
"avatar_url": "https://avatars.githubusercontent.com/u/284386738?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GovernorOfEntropy",
"html_url": "https://github.com/GovernorOfEntropy",
"followers_url": "https://api.github.com/users/GovernorOfEntropy/followers",
"following_url": "https://api.github.com/users/GovernorOfEntropy/following{/other_user}",
"gists_url": "https://api.github.com/users/GovernorOfEntropy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GovernorOfEntropy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GovernorOfEntropy/subscriptions",
"organizations_url": "https://api.github.com/users/GovernorOfEntropy/orgs",
"repos_url": "https://api.github.com/users/GovernorOfEntropy/repos",
"events_url": "https://api.github.com/users/GovernorOfEntropy/events{/privacy}",
"received_events_url": "https://api.github.com/users/GovernorOfEntropy/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T00:21:37Z",
"updated_at": "2026-06-05T00:21:37Z",
"body": "> Been running Karpathy's LLM-Wiki pattern for five weeks now.\r\n> \r\n> The compounding effect is real. Drop a paper, get a cross-linked wiki page. Ask a question, get a cited answer that gets filed back into the graph. The maintenance burden is near zero because the LLM does the bookkeeping.\r\n> \r\n> But — when I tried to scale it beyond markdown notes, I hit a wall.\r\n> \r\n> PDFs needed PyMuPDF. Office docs needed python-docx. Video transcripts needed Whisper. Structured LLM outputs needed Instructor. Each tool had its own vault, its own SQLite schema, its own API surface. I built a 450-line Python glue layer to stitch them together.\r\n> \r\n> The glue proved the problem: **fragmentation at the architecture layer.** Four vaults, four schemas, wikilink collisions, frontmatter drift, MCP namespace explosions. Glue is insufficient because it preserves the fragmentation; it just moves it around.\r\n> \r\n> So I wrote a spec for unification at the architecture layer instead:\r\n> \r\n> **Mnemosyne** — a local-first semantic memory OS with a Rust core and Python satellites.\r\n> \r\n> * One vault: `raw/`, `wiki/`, `memory/`, `packs/`\r\n> * One schema: SQLite `state.db` with `pages`, `links`, `jobs`, `conversations`, `audit_log`, `contradictions`\r\n> * One API: MCP + REST + CLI from day one\r\n> * Rust core: schema, job queue, graph traversal, API surface\r\n> * Python satellites: PDF extraction, office docs, video/audio transcripts, LLM client glue, structured compilation\r\n> * Two-tier compilation: fast model (30B) extracts concepts, heavy model (70B+) writes cross-linked articles\r\n> * Audit engine: structural lint → contradiction detection → adversarial review\r\n> * Provenance-first: every claim carries citation, every LLM call carries cost log\r\n> \r\n> The Python satellites are permanent, not transitional. Rust cannot yet match Python's depth in document extraction (pymupdf, python-docx, Whisper) or structured LLM output (Instructor, Pydantic-AI). The Rust core spawns them as subprocesses, receives JSON, and integrates into the unified system.\r\n> \r\n> Status: architecture spec complete. Seeking core contributors for Phase 1 implementation (SQLite schema, vault init, markdown ingestion, basic MCP server).\r\n> \r\n> Spec: https://github.com/noirblue/IsaacCLupus_mnemosyn_spec\r\n> \r\n> If you've hit the same fragmentation wall trying to scale the LLM-Wiki pattern, I'd love to talk.\r\n\r\nI hit the scale limit too and am trying to solve for it. This project and my own were on parallel tracks but the concept is the same. I see the core issue is the number of edges in the graph node just overwhelm the llm at some point. wikipedia keeps their edges manually inserted and sparse. if they really densified the edges, it would collapse."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183984",
"id": 6183984,
"node_id": "GC_lADOAiGVz9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXDA",
"user": {
"login": "pursultani",
"id": 35755471,
"node_id": "MDQ6VXNlcjM1NzU1NDcx",
"avatar_url": "https://avatars.githubusercontent.com/u/35755471?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pursultani",
"html_url": "https://github.com/pursultani",
"followers_url": "https://api.github.com/users/pursultani/followers",
"following_url": "https://api.github.com/users/pursultani/following{/other_user}",
"gists_url": "https://api.github.com/users/pursultani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pursultani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pursultani/subscriptions",
"organizations_url": "https://api.github.com/users/pursultani/orgs",
"repos_url": "https://api.github.com/users/pursultani/repos",
"events_url": "https://api.github.com/users/pursultani/events{/privacy}",
"received_events_url": "https://api.github.com/users/pursultani/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T08:15:25Z",
"updated_at": "2026-06-05T08:15:25Z",
"body": "**TL;DR**\r\n\r\nThe pattern defaults to a convergent epistemology where contradiction is a defect. In subjective domains, like the humanities, contradiction is information. This is not one problem but two that are usually run together. There is a policy default, where the rules treat contradiction as degradation, and a representation gap, where untyped edges cannot express a contradiction as anything other than a flag. Fixing it needs both. You need a policy that preserves contradictions and a representation that can hold them. Typed edges\r\nsupply the second. However, they do not, on their own, supply the first.\r\n\r\n### The philosophical problem\r\n\r\nThe pattern's default rules treat contradiction as a defect to be resolved. The lint pass groups contradictions with stale claims and orphans, which are genuine defects, and the \"synthesis\" framing treats a single reconciled account as the goal.\r\n\r\nThis is a specific epistemological assumption. It holds for scientific and technical knowledge, with an objective epistemology, where two conflicting claims about the same entity cannot both be true. It breaks in domains where knowledge is inherently dialogic. In literary criticism, the tension between [Bloom's anxiety of influence](https://en.wikipedia.org/wiki/Anxiety_of_influence) and [de Man's deconstructive](https://en.wikipedia.org/wiki/Paul_de_Man) reading of the same texts is not a data-quality problem. It is the intellectual content itself. In philosophy, Wittgenstein contradicting his earlier self is not drift to correct. It is the history of analytic philosophy. In historiography, structurally incompatible accounts of the same period are not redundant sources awaiting synthesis.\r\n\r\nIn these domains the lint pass should check for _missing_ contradictions, not flag existing ones. But notice this is a change to the rules in `CLAUDE.md`, not to the data model. You could keep bare wikilinks and fix most of this today just by rewriting the lint and lifecycle instructions to preserve tension instead of reconciling it. That is the part typed edges alone will not do for you.\r\n\r\n### The representation gap\r\n\r\nThe reason the better policy is awkward to express is structural. The architecture is a graph with typed nodes (pages) but untyped edges (wikilinks). A bare `[[page]]` carries no information about the nature of the relationship. \"contradicts\", \"supports\", \"extends\", \"supersedes\", \"was a response to\" all collapse into the same link. So even once your policy says to preserve a contradiction, the graph has nowhere to put that fact except a prose note or a lint flag.\r\n\r\nThis is well understood in knowledge representation. Property graphs and RDF/OWL both make typed, attributable edges a first-class primitive. And some implementations in this very thread already reach for it. [AutoSci](https://github.com/skyllwt/AutoSci) ships \"contradiction edges\", and [Dense-Mem](https://github.com/markhuangai/dense-mem) models conflicts as typed claims rather than as a health warning. So the representation is not unheard of.\r\n\r\nWhat is missing is making it general, and, crucially, pairing it with the policy, because a `contradicts` edge is worthless if the lint rule still treats it as something to clean up.\r\n\r\nWith typed edges and a policy that respects them, A and B linked by `contradicts` become navigable, queryable structure rather than a maintenance flag. Querying becomes traversal. \"what supports this claim\" and \"what challenges it\" are graph operations, not semantic searches.\r\n\r\n### A practical solution, in two parts\r\n\r\nThe representation is a set of front-matter relationship blocks, where each page declares its typed outbound relationships in YAML, queryable via Obsidian Dataview. The LLM maintains this block on every ingest:\r\n\r\n```yaml\r\n---\r\nrelates_to:\r\n - page: \"Judith Butler\"\r\n rel: contradicts\r\n - page: \"Harold Bloom\"\r\n rel: extends\r\n---\r\n```\r\n\r\nThe policy is the load-bearing part. The permitted relationship vocabulary, the rules for when each type applies, and the instruction that in dialogic domains a `contradicts` edge is preserved while a lack of expected contradictions is the lint smell, all live in the schema document (`CLAUDE.md`). That makes edge typing a first-class part of the wiki's behavioral contract rather than an\r\nafterthought.\r\n\r\n### Caveats\r\n\r\nThe main open problem is vocabulary governance. Having the LLM maintain a controlled relationship vocabulary on every ingest invites the same drift and mis-typing other commenters have flagged at the frontmatter layer, and deciding when something is `extends` versus `supersedes` versus `was a response to` is real ontology work, not something the schema gets for free. But that is a\r\ntractable maintenance cost, and it buys a wiki that can hold a disagreement instead of dissolving it.\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6183986",
"id": 6183986,
"node_id": "GC_lADOB7kmgNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXDI",
"user": {
"login": "Archimondstat",
"id": 129574528,
"node_id": "U_kgDOB7kmgA",
"avatar_url": "https://avatars.githubusercontent.com/u/129574528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Archimondstat",
"html_url": "https://github.com/Archimondstat",
"followers_url": "https://api.github.com/users/Archimondstat/followers",
"following_url": "https://api.github.com/users/Archimondstat/following{/other_user}",
"gists_url": "https://api.github.com/users/Archimondstat/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Archimondstat/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Archimondstat/subscriptions",
"organizations_url": "https://api.github.com/users/Archimondstat/orgs",
"repos_url": "https://api.github.com/users/Archimondstat/repos",
"events_url": "https://api.github.com/users/Archimondstat/events{/privacy}",
"received_events_url": "https://api.github.com/users/Archimondstat/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T08:17:40Z",
"updated_at": "2026-06-05T08:17:40Z",
"body": "One concern I have is that an Obsidian vault may eventually become filled with AI-generated summaries or hallucinated notes that the user never truly internalizes or uses. If the hallucination probability of each AI-generated note is non-zero, then under repeated use, the probability that the vault contains at least one hallucinated note approaches 1 as the number of generated notes grows.\r\n\r\nSo I would like to propose an idea, which I call the **\"Socrates–Plato–Bayes Learning System\"**.\r\n\r\nInstead of letting the AI or the system directly learn, summarize, and populate the wiki, the user should first propose their own idea, hypothesis, or interpretation. Then the AI acts as a Socratic challenger: questioning it, finding weaknesses, offering counterexamples, and checking it against external knowledge.\r\n\r\nAfter that, the user updates their original idea based on the AI's challenges, almost like a Bayesian posterior update. Only when the idea has survived this process should it be promoted into the wiki.\r\n\r\nIn other words, the wiki should not be a place where AI stores what it thinks the user should know. It should be a place where the user's own ideas are refined, challenged, and crystallized."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184352",
"id": 6184352,
"node_id": "GC_lADOAAjdUtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXaA",
"user": {
"login": "theluk",
"id": 580946,
"node_id": "MDQ6VXNlcjU4MDk0Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/580946?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theluk",
"html_url": "https://github.com/theluk",
"followers_url": "https://api.github.com/users/theluk/followers",
"following_url": "https://api.github.com/users/theluk/following{/other_user}",
"gists_url": "https://api.github.com/users/theluk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theluk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theluk/subscriptions",
"organizations_url": "https://api.github.com/users/theluk/orgs",
"repos_url": "https://api.github.com/users/theluk/repos",
"events_url": "https://api.github.com/users/theluk/events{/privacy}",
"received_events_url": "https://api.github.com/users/theluk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T13:01:34Z",
"updated_at": "2026-06-05T13:01:34Z",
"body": " \r\n\r\nWe took this and shipped it as a first-party Skill inside **Knolo** (our AI-native workspace) — the \"incredible new product instead of a hacky collection of scripts\" line is basically our whole thesis, so it mapped almost 1:1 onto the primitives we already had.\r\n\r\nThe three layers became:\r\n\r\nRaw Sources → an immutable Mind (our knowledge/artifact store) you drop articles, papers, notes, and media into. The LLM reads it, never rewrites it.\r\nThe wiki → a second, indexable Mind of LLM-owned interlinked pages — one summary page per source, plus entity and concept pages, an overview.md synthesis, and the index.md / log.md you describe (log lines kept greppable with a ## [date] ingest | Title prefix).\r\nThe schema (CLAUDE.md / AGENTS.md) → the instructions of a Wiki Librarian Assistant, so the conventions and the ingest/query/lint workflows are the config that keeps it a disciplined maintainer.\r\nThe ingest → query → lint loop is the core: every source gets integrated into existing pages (update entities, revise summaries, flag contradictions) rather than just filed, query answers get written back so explorations compound, and an optional scheduled Lint Agent runs the health-checks (contradictions, stale claims, orphans, gaps). The user curates sources and asks questions; the LLM does all the bookkeeping.\r\n\r\nThanks for writing the idea file up so clearly — that's what made it straightforward to turn into a guided, repeatable setup. Overview of how it maps below."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184491",
"id": 6184491,
"node_id": "GC_lADOAAhjcNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXis",
"user": {
"login": "watsonrm",
"id": 549744,
"node_id": "MDQ6VXNlcjU0OTc0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/549744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watsonrm",
"html_url": "https://github.com/watsonrm",
"followers_url": "https://api.github.com/users/watsonrm/followers",
"following_url": "https://api.github.com/users/watsonrm/following{/other_user}",
"gists_url": "https://api.github.com/users/watsonrm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/watsonrm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/watsonrm/subscriptions",
"organizations_url": "https://api.github.com/users/watsonrm/orgs",
"repos_url": "https://api.github.com/users/watsonrm/repos",
"events_url": "https://api.github.com/users/watsonrm/events{/privacy}",
"received_events_url": "https://api.github.com/users/watsonrm/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:13:10Z",
"updated_at": "2026-06-05T14:13:10Z",
"body": "People keep reaching for branch-and-merge here, and it's the right instinct — but it solves a different layer than the one that actually corrupts an LLM wiki, so I want to be precise about where it helps and where it doesn't.\n\nGit merge resolves *textual* conflicts: same line, two edits. The failure mode that actually wrecks a wiki is *semantic*: two agents independently write the same fact in different words. One appends \"decided to ship path B,\" another appends \"going with option B for the trigger.\" Git sees two non-overlapping additions, merges both cleanly, and now the wiki holds a duplicate. A clean merge isn't a correct merge. So branch-and-merge doesn't remove the need for dedup — you still have to grep for the fact before you write it. That dedup step is exactly what a single-writer discipline was buying you for free, which is why people who start with merge end up rebuilding it anyway.\n\nThe deeper point is that single-writer isn't a ceiling, it's just the cheapest way to get zero merges. The scalable version of multi-writer isn't \"add a merge step,\" it's modeling the data so concurrent writes commute in the first place. Append-only logs, one entry per line, partitioned by file or section. If every agent only ever appends its own line and nothing reorders, git auto-merges every time, no conflict, no resolver. That's effectively single-writer-per-file with many writers per wiki — which is what you actually want, and it's a data-modeling choice, not a coordination one.\n\nWhat's left after that is small. Worktree isolation per writer (cheap, and most agent runtimes already give it to you). A deterministic merge driver for the rare genuine same-region collision — sorted append, last-writer-wins on structured fields — and emphatically not an LLM resolving conflicts, because that just reintroduces the nondeterminism you were trying to bound. And grep-dedup stays, permanently, as the semantic layer git can't see.\n\nSo: branch-and-merge is the right transport. It sits *under* idempotent, commutative writes; it doesn't replace them. The hard part was never the merge mechanics — it's making the writes dedup-safe and order-independent before they ever hit the tree.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184513",
"id": 6184513,
"node_id": "GC_lADOAAhjcNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXkE",
"user": {
"login": "watsonrm",
"id": 549744,
"node_id": "MDQ6VXNlcjU0OTc0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/549744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watsonrm",
"html_url": "https://github.com/watsonrm",
"followers_url": "https://api.github.com/users/watsonrm/followers",
"following_url": "https://api.github.com/users/watsonrm/following{/other_user}",
"gists_url": "https://api.github.com/users/watsonrm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/watsonrm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/watsonrm/subscriptions",
"organizations_url": "https://api.github.com/users/watsonrm/orgs",
"repos_url": "https://api.github.com/users/watsonrm/repos",
"events_url": "https://api.github.com/users/watsonrm/events{/privacy}",
"received_events_url": "https://api.github.com/users/watsonrm/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:26:16Z",
"updated_at": "2026-06-05T14:26:16Z",
"body": "@brtrx the randomised-sequence trick is smart — it's the right patch for an ordering problem. Worth pushing one layer down though: the reason order biases the wiki in the first place is that ingest isn't idempotent. If every claim carries its source citation and you grep for that citation before writing, re-ingesting in a different order converges to the same state — the structural bias just stops being reachable. Ingest becomes commutative, and the lint only has to handle genuine semantic conflicts, not order artifacts.\n\nTwo things that have held up at the same scale: contradiction detection should key on a stable claim identity (the citation), not textual proximity, so a batched pass and a single pass produce the same result regardless of sequence. And when the lint finds a real conflict, route it to a review queue rather than auto-resolving — a high-confidence merge can auto-apply, but a decision reversal is exactly the case you want a human to see. The persistent scratchpad is the right primitive; I'd just make the thing it dedups against an identity, not a position.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184514",
"id": 6184514,
"node_id": "GC_lADOAAhjcNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXkI",
"user": {
"login": "watsonrm",
"id": 549744,
"node_id": "MDQ6VXNlcjU0OTc0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/549744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watsonrm",
"html_url": "https://github.com/watsonrm",
"followers_url": "https://api.github.com/users/watsonrm/followers",
"following_url": "https://api.github.com/users/watsonrm/following{/other_user}",
"gists_url": "https://api.github.com/users/watsonrm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/watsonrm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/watsonrm/subscriptions",
"organizations_url": "https://api.github.com/users/watsonrm/orgs",
"repos_url": "https://api.github.com/users/watsonrm/repos",
"events_url": "https://api.github.com/users/watsonrm/events{/privacy}",
"received_events_url": "https://api.github.com/users/watsonrm/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:26:16Z",
"updated_at": "2026-06-05T14:26:16Z",
"body": "@beckfexx closest setup to mine I've seen in the thread — 6 specialized agents, contradiction detection, nightly self-heal. One thing I'd challenge: the advisory locks and handover protocols are probably the part you can delete. Locks are a symptom of multiple writers contending for the same file. Partition writers by file/section and keep writes append-only, and the contention disappears — many agents per wiki, but one writer per target. Biggest reliability win I've had.\n\nOn contradiction detection, I'd shift it left. Catching conflicts at 2,000+ memories with five strategies is detection after the fact; if each write greps for the claim's citation first, you reject the duplicate at write time and the nightly pass shrinks to genuine semantic reversals. And on self-heal — autonomous overwrite of \"stale\" knowledge is the one place silent corruption creeps in. I gate that with confidence tiers: high-confidence updates auto-apply, anything ambiguous flags for review instead of overwriting. Cheap insurance against the 2:30 AM job quietly rewriting something that was correct.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184540",
"id": 6184540,
"node_id": "GC_lADOAXepBdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXlw",
"user": {
"login": "nishchay7pixels",
"id": 24619269,
"node_id": "MDQ6VXNlcjI0NjE5MjY5",
"avatar_url": "https://avatars.githubusercontent.com/u/24619269?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nishchay7pixels",
"html_url": "https://github.com/nishchay7pixels",
"followers_url": "https://api.github.com/users/nishchay7pixels/followers",
"following_url": "https://api.github.com/users/nishchay7pixels/following{/other_user}",
"gists_url": "https://api.github.com/users/nishchay7pixels/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nishchay7pixels/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nishchay7pixels/subscriptions",
"organizations_url": "https://api.github.com/users/nishchay7pixels/orgs",
"repos_url": "https://api.github.com/users/nishchay7pixels/repos",
"events_url": "https://api.github.com/users/nishchay7pixels/events{/privacy}",
"received_events_url": "https://api.github.com/users/nishchay7pixels/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:39:02Z",
"updated_at": "2026-06-05T14:39:02Z",
"body": "# ctxslice (https://github.com/llcortex/ContextSlice.git)\r\n\r\n\r\n\r\n**A semantic context pre-processor that gives coding agents only the code they need.** \r\n\r\nPrune your codebase to only what's relevant before the LLM sees it.\r\n\r\nInspired by MiniMax M3's MSA architecture — sparse attention with pre-filtering. \r\nInstead of attending to everything, identify which blocks matter and drop the rest.\r\n\r\nContextSlice is a sparse context compiler for AI coding agents."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184817",
"id": 6184817,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeX3E",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T16:33:45Z",
"updated_at": "2026-06-05T16:33:45Z",
"body": "Synthadoc Community Edition v0.7.0 is released.\r\n\r\nThree new features focused on interactivity, speed, and visibility into the wiki's health:\r\n\r\n1. Local Web Chat UI: \"synthadoc web\" CLI starts a local chat interface in your browser, local-only, nothing leaves your machine. Use it the same way you use the CLI: ask questions about your wiki's domain and get streamed, cited answers. \r\n\r\nBeyond content queries, the UI also auto-detects the health of your wiki (Explorer, Health Check, or Power User mode) and surfaces context-appropriate prompts: if your wiki has orphan pages or contradictions, those show up as suggested actions rather than generic hints. You can also give operational commands directly in the chat: \"run lint\", \"show wiki status\", \"schedule ingest every night at 9 PM\", the Action Agent parses those and executes them live against your wiki, with results shown inline.\r\n\r\n → Quick-start demo: Step 22 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-22--use-the-web-chat-ui)\r\n\r\n\r\n2. Streaming Query: responses now stream token-by-token instead of waiting for the full answer. Works in the CLI, in Obsidian, and in the new web UI. The first token appears almost immediately after you ask; citations and confidence scores appear at the end of the stream once the full answer is assembled. If you need a cached static result, --no-stream still gives you the old behaviour.\r\n\r\n → Quick-start demo: Step 5 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-5--query-the-pre-built-wiki-cli--obsidian)\r\n\r\n\r\n3. Query Result Caching: repeated queries return instantly from a local cache instead of hitting the LLM again. The cache is shared across the CLI, the web UI, and the Obsidian plugin, keyed on the question text, the current wiki epoch, and the model. The wiki epoch increments automatically on every ingest and every lifecycle state change, so the moment your wiki changes, all prior cached answers are bypassed immediately. \r\n\r\n → Quick-start demo: Step 23 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-23--query-caching)\r\n\r\n \r\n4. Also in v0.7.0: expanded built-in hints covering orphan pages, adversarial warnings, and lifecycle state queries; live lint-report and wiki-status summaries available directly from the chat UI.\r\n\r\n\r\nIf any of this is useful or you have thoughts on the direction, feedback is very welcome, and a ⭐ always helps the project reach more people.\r\n\r\n 👉 https://github.com/axoviq-ai/synthadoc"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184885",
"id": 6184885,
"node_id": "GC_lADOEPNlstoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeX7U",
"user": {
"login": "GovernorOfEntropy",
"id": 284386738,
"node_id": "U_kgDOEPNlsg",
"avatar_url": "https://avatars.githubusercontent.com/u/284386738?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GovernorOfEntropy",
"html_url": "https://github.com/GovernorOfEntropy",
"followers_url": "https://api.github.com/users/GovernorOfEntropy/followers",
"following_url": "https://api.github.com/users/GovernorOfEntropy/following{/other_user}",
"gists_url": "https://api.github.com/users/GovernorOfEntropy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GovernorOfEntropy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GovernorOfEntropy/subscriptions",
"organizations_url": "https://api.github.com/users/GovernorOfEntropy/orgs",
"repos_url": "https://api.github.com/users/GovernorOfEntropy/repos",
"events_url": "https://api.github.com/users/GovernorOfEntropy/events{/privacy}",
"received_events_url": "https://api.github.com/users/GovernorOfEntropy/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T17:09:55Z",
"updated_at": "2026-06-05T17:09:55Z",
"body": "> **TL;DR**\r\n> \r\n> The pattern defaults to a convergent epistemology where contradiction is a defect. In subjective domains, like the humanities, contradiction is information. This is not one problem but two that are usually run together. There is a policy default, where the rules treat contradiction as degradation, and a representation gap, where untyped edges cannot express a contradiction as anything other than a flag. Fixing it needs both. You need a policy that preserves contradictions and a representation that can hold them. Typed edges supply the second. However, they do not, on their own, supply the first.\r\n> \r\n> ### The philosophical problem\r\n> The pattern's default rules treat contradiction as a defect to be resolved. The lint pass groups contradictions with stale claims and orphans, which are genuine defects, and the \"synthesis\" framing treats a single reconciled account as the goal.\r\n> \r\n> This is a specific epistemological assumption. It holds for scientific and technical knowledge, with an objective epistemology, where two conflicting claims about the same entity cannot both be true. It breaks in domains where knowledge is inherently dialogic. In literary criticism, the tension between [Bloom's anxiety of influence](https://en.wikipedia.org/wiki/Anxiety_of_influence) and [de Man's deconstructive](https://en.wikipedia.org/wiki/Paul_de_Man) reading of the same texts is not a data-quality problem. It is the intellectual content itself. In philosophy, Wittgenstein contradicting his earlier self is not drift to correct. It is the history of analytic philosophy. In historiography, structurally incompatible accounts of the same period are not redundant sources awaiting synthesis.\r\n> \r\n> In these domains the lint pass should check for _missing_ contradictions, not flag existing ones. But notice this is a change to the rules in `CLAUDE.md`, not to the data model. You could keep bare wikilinks and fix most of this today just by rewriting the lint and lifecycle instructions to preserve tension instead of reconciling it. That is the part typed edges alone will not do for you.\r\n> \r\n> ### The representation gap\r\n> The reason the better policy is awkward to express is structural. The architecture is a graph with typed nodes (pages) but untyped edges (wikilinks). A bare `[[page]]` carries no information about the nature of the relationship. \"contradicts\", \"supports\", \"extends\", \"supersedes\", \"was a response to\" all collapse into the same link. So even once your policy says to preserve a contradiction, the graph has nowhere to put that fact except a prose note or a lint flag.\r\n> \r\n> This is well understood in knowledge representation. Property graphs and RDF/OWL both make typed, attributable edges a first-class primitive. And some implementations in this very thread already reach for it. [AutoSci](https://github.com/skyllwt/AutoSci) ships \"contradiction edges\", and [Dense-Mem](https://github.com/markhuangai/dense-mem) models conflicts as typed claims rather than as a health warning. So the representation is not unheard of.\r\n> \r\n> What is missing is making it general, and, crucially, pairing it with the policy, because a `contradicts` edge is worthless if the lint rule still treats it as something to clean up.\r\n> \r\n> With typed edges and a policy that respects them, A and B linked by `contradicts` become navigable, queryable structure rather than a maintenance flag. Querying becomes traversal. \"what supports this claim\" and \"what challenges it\" are graph operations, not semantic searches.\r\n> \r\n> ### A practical solution, in two parts\r\n> The representation is a set of front-matter relationship blocks, where each page declares its typed outbound relationships in YAML, queryable via Obsidian Dataview. The LLM maintains this block on every ingest:\r\n> \r\n> ```yaml\r\n> ---\r\n> relates_to:\r\n> - page: \"Judith Butler\"\r\n> rel: contradicts\r\n> - page: \"Harold Bloom\"\r\n> rel: extends\r\n> ---\r\n> ```\r\n> \r\n> The policy is the load-bearing part. The permitted relationship vocabulary, the rules for when each type applies, and the instruction that in dialogic domains a `contradicts` edge is preserved while a lack of expected contradictions is the lint smell, all live in the schema document (`CLAUDE.md`). That makes edge typing a first-class part of the wiki's behavioral contract rather than an afterthought.\r\n> \r\n> ### Caveats\r\n> The main open problem is vocabulary governance. Having the LLM maintain a controlled relationship vocabulary on every ingest invites the same drift and mis-typing other commenters have flagged at the frontmatter layer, and deciding when something is `extends` versus `supersedes` versus `was a response to` is real ontology work, not something the schema gets for free. But that is a tractable maintenance cost, and it buys a wiki that can hold a disagreement instead of dissolving it.\r\n\r\nMulti-edge definitions already are part of graph. managing the EXTENDS tree when there is a CONTRADICTS requires a filter to ignore the CONTRADICTS. the graph edges effectively split at that point into multi-branches. \r\n\r\nThe main work I am doing where I am hitting scale limits is geopolitics research for a book and these multi-edge problems present themselves constantly. I don't know how to cleanly work through this yet."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6185530",
"id": 6185530,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeYjo",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-06T07:20:14Z",
"updated_at": "2026-06-06T07:20:14Z",
"body": "Love this LLM-Wiki idea? We built a full open-source system on it → AutoSci\r\n\r\nCome and enjoy: https://github.com/skyllwt/AutoSci\r\n\r\n\r\n\r\nKarpathy's pattern (immutable raw/ → an LLM-compiled wiki/ → a CLAUDE.md schema) is the exact foundation of AutoSci — an agent that turns the wiki into a research memory and then does autonomous science on top of it. All on Claude Code:\r\n - 📚 Ingest papers into a cross-linked wiki of concept/method/idea pages ([[wikilinks]], contradiction edges — the LLM-Wiki, fully realized)\r\n - 💡 Ideate → experiment → write: it reads its own memory to generate ideas, design + run experiments, draft the paper, and handle rebuttals\r\n - 🧬 Self-evolving memory: between projects it consolidates, re-weights, and re-links the wiki (a \"sleep\" phase)\r\n - 🕸️ Multi-agent DAGs for the hard reasoning steps\r\n\r\n\r\nWe've already used it to write 3 papers end-to-end. Fully open (MIT).\r\n\r\n⭐ If this is where you want LLM-Wikis to go, a star genuinely helps us! and we welcome issues/PRs/Contributors\r\n👉 https://github.com/skyllwt/AutoSci\r\n📄 Paper: https://arxiv.org/abs/2605.31468\r\n\r\nDemo: 【北大做了一个会自我进化的科研 Agent:AutoSci】 https://www.bilibili.com/video/BV19gVg6pEk6/?share_source=copy_web&vd_source=338de971cb27f42aaaf5d8bfdeed04b3\r\n\r\n\r\n\r\nRED: 北大做了一个“越做科研越聪明”的AI科学家 北大团队... http://xhslink.com/o/2clEkgugEPw \r\n复制后打开【小红书】查看笔记!\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6185820",
"id": 6185820,
"node_id": "GC_lADOCO4ReNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeY1w",
"user": {
"login": "vvvvvivekkk",
"id": 149819768,
"node_id": "U_kgDOCO4ReA",
"avatar_url": "https://avatars.githubusercontent.com/u/149819768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvvvvivekkk",
"html_url": "https://github.com/vvvvvivekkk",
"followers_url": "https://api.github.com/users/vvvvvivekkk/followers",
"following_url": "https://api.github.com/users/vvvvvivekkk/following{/other_user}",
"gists_url": "https://api.github.com/users/vvvvvivekkk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vvvvvivekkk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vvvvvivekkk/subscriptions",
"organizations_url": "https://api.github.com/users/vvvvvivekkk/orgs",
"repos_url": "https://api.github.com/users/vvvvvivekkk/repos",
"events_url": "https://api.github.com/users/vvvvvivekkk/events{/privacy}",
"received_events_url": "https://api.github.com/users/vvvvvivekkk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-06T13:36:29Z",
"updated_at": "2026-06-06T13:36:29Z",
"body": "Interesting to see so many LLM-Wiki implementations emerge from this gist.\r\n\r\nI took a slightly different direction with LLM-Wiki-v3.\r\n\r\nMost systems stop at \"LLM-maintained markdown + retrieval.\" V3 tries to make the wiki a reliable long-term knowledge substrate rather than just a generated documentation layer.\r\n\r\nKey ideas:\r\n\r\n• Markdown + Git are the only source of truth. Every vector index, BM25 index, graph, and retrieval artifact is disposable and fully rebuildable.\r\n\r\n• Provenance is non-negotiable. Instead of confidence scores, every claim traces back to sources, spans, extractors, and timestamps. Trust is reconstructed, not guessed.\r\n\r\n• Knowledge doesn't decay. Facts are superseded, not deleted. The system preserves what was believed, when it was believed, and what replaced it.\r\n\r\n• Retrieval is hybrid by design (BM25 + dense + graph + RRF + reranking), but retrieval is treated as infrastructure—not memory itself.\r\n\r\n• Autonomous writes are gated. Agents cannot directly mutate knowledge. Changes flow through evaluation, attribution checks, and audit trails before becoming part of the wiki.\r\n\r\n• Every operation is auditable and reversible. The goal is knowledge evolution with accountability.\r\n\r\n• The wiki is domain-agnostic. The real product is the schema. Change the schema and the same engine becomes a research wiki, company brain, scientific memory system, or personal knowledge substrate.\r\n\r\nMy belief is that the next generation of AI memory systems won't be vector databases or chat histories. They'll be versioned knowledge systems with provenance, evaluation gates, and explicit evolution paths.\r\n\r\nLLM-Wiki-v3 is my attempt at exploring that direction.\r\n\r\nhttps://github.com/vvvvvivekkk/LLM-Wiki-v3\r\n\r\n\r\n
\r\n\r\nWe took this and shipped it as a first-party Skill inside **Knolo** (our AI-native workspace) — the \"incredible new product instead of a hacky collection of scripts\" line is basically our whole thesis, so it mapped almost 1:1 onto the primitives we already had.\r\n\r\nThe three layers became:\r\n\r\nRaw Sources → an immutable Mind (our knowledge/artifact store) you drop articles, papers, notes, and media into. The LLM reads it, never rewrites it.\r\nThe wiki → a second, indexable Mind of LLM-owned interlinked pages — one summary page per source, plus entity and concept pages, an overview.md synthesis, and the index.md / log.md you describe (log lines kept greppable with a ## [date] ingest | Title prefix).\r\nThe schema (CLAUDE.md / AGENTS.md) → the instructions of a Wiki Librarian Assistant, so the conventions and the ingest/query/lint workflows are the config that keeps it a disciplined maintainer.\r\nThe ingest → query → lint loop is the core: every source gets integrated into existing pages (update entities, revise summaries, flag contradictions) rather than just filed, query answers get written back so explorations compound, and an optional scheduled Lint Agent runs the health-checks (contradictions, stale claims, orphans, gaps). The user curates sources and asks questions; the LLM does all the bookkeeping.\r\n\r\nThanks for writing the idea file up so clearly — that's what made it straightforward to turn into a guided, repeatable setup. Overview of how it maps below."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184491",
"id": 6184491,
"node_id": "GC_lADOAAhjcNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXis",
"user": {
"login": "watsonrm",
"id": 549744,
"node_id": "MDQ6VXNlcjU0OTc0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/549744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watsonrm",
"html_url": "https://github.com/watsonrm",
"followers_url": "https://api.github.com/users/watsonrm/followers",
"following_url": "https://api.github.com/users/watsonrm/following{/other_user}",
"gists_url": "https://api.github.com/users/watsonrm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/watsonrm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/watsonrm/subscriptions",
"organizations_url": "https://api.github.com/users/watsonrm/orgs",
"repos_url": "https://api.github.com/users/watsonrm/repos",
"events_url": "https://api.github.com/users/watsonrm/events{/privacy}",
"received_events_url": "https://api.github.com/users/watsonrm/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:13:10Z",
"updated_at": "2026-06-05T14:13:10Z",
"body": "People keep reaching for branch-and-merge here, and it's the right instinct — but it solves a different layer than the one that actually corrupts an LLM wiki, so I want to be precise about where it helps and where it doesn't.\n\nGit merge resolves *textual* conflicts: same line, two edits. The failure mode that actually wrecks a wiki is *semantic*: two agents independently write the same fact in different words. One appends \"decided to ship path B,\" another appends \"going with option B for the trigger.\" Git sees two non-overlapping additions, merges both cleanly, and now the wiki holds a duplicate. A clean merge isn't a correct merge. So branch-and-merge doesn't remove the need for dedup — you still have to grep for the fact before you write it. That dedup step is exactly what a single-writer discipline was buying you for free, which is why people who start with merge end up rebuilding it anyway.\n\nThe deeper point is that single-writer isn't a ceiling, it's just the cheapest way to get zero merges. The scalable version of multi-writer isn't \"add a merge step,\" it's modeling the data so concurrent writes commute in the first place. Append-only logs, one entry per line, partitioned by file or section. If every agent only ever appends its own line and nothing reorders, git auto-merges every time, no conflict, no resolver. That's effectively single-writer-per-file with many writers per wiki — which is what you actually want, and it's a data-modeling choice, not a coordination one.\n\nWhat's left after that is small. Worktree isolation per writer (cheap, and most agent runtimes already give it to you). A deterministic merge driver for the rare genuine same-region collision — sorted append, last-writer-wins on structured fields — and emphatically not an LLM resolving conflicts, because that just reintroduces the nondeterminism you were trying to bound. And grep-dedup stays, permanently, as the semantic layer git can't see.\n\nSo: branch-and-merge is the right transport. It sits *under* idempotent, commutative writes; it doesn't replace them. The hard part was never the merge mechanics — it's making the writes dedup-safe and order-independent before they ever hit the tree.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184513",
"id": 6184513,
"node_id": "GC_lADOAAhjcNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXkE",
"user": {
"login": "watsonrm",
"id": 549744,
"node_id": "MDQ6VXNlcjU0OTc0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/549744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watsonrm",
"html_url": "https://github.com/watsonrm",
"followers_url": "https://api.github.com/users/watsonrm/followers",
"following_url": "https://api.github.com/users/watsonrm/following{/other_user}",
"gists_url": "https://api.github.com/users/watsonrm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/watsonrm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/watsonrm/subscriptions",
"organizations_url": "https://api.github.com/users/watsonrm/orgs",
"repos_url": "https://api.github.com/users/watsonrm/repos",
"events_url": "https://api.github.com/users/watsonrm/events{/privacy}",
"received_events_url": "https://api.github.com/users/watsonrm/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:26:16Z",
"updated_at": "2026-06-05T14:26:16Z",
"body": "@brtrx the randomised-sequence trick is smart — it's the right patch for an ordering problem. Worth pushing one layer down though: the reason order biases the wiki in the first place is that ingest isn't idempotent. If every claim carries its source citation and you grep for that citation before writing, re-ingesting in a different order converges to the same state — the structural bias just stops being reachable. Ingest becomes commutative, and the lint only has to handle genuine semantic conflicts, not order artifacts.\n\nTwo things that have held up at the same scale: contradiction detection should key on a stable claim identity (the citation), not textual proximity, so a batched pass and a single pass produce the same result regardless of sequence. And when the lint finds a real conflict, route it to a review queue rather than auto-resolving — a high-confidence merge can auto-apply, but a decision reversal is exactly the case you want a human to see. The persistent scratchpad is the right primitive; I'd just make the thing it dedups against an identity, not a position.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184514",
"id": 6184514,
"node_id": "GC_lADOAAhjcNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXkI",
"user": {
"login": "watsonrm",
"id": 549744,
"node_id": "MDQ6VXNlcjU0OTc0NA==",
"avatar_url": "https://avatars.githubusercontent.com/u/549744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/watsonrm",
"html_url": "https://github.com/watsonrm",
"followers_url": "https://api.github.com/users/watsonrm/followers",
"following_url": "https://api.github.com/users/watsonrm/following{/other_user}",
"gists_url": "https://api.github.com/users/watsonrm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/watsonrm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/watsonrm/subscriptions",
"organizations_url": "https://api.github.com/users/watsonrm/orgs",
"repos_url": "https://api.github.com/users/watsonrm/repos",
"events_url": "https://api.github.com/users/watsonrm/events{/privacy}",
"received_events_url": "https://api.github.com/users/watsonrm/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:26:16Z",
"updated_at": "2026-06-05T14:26:16Z",
"body": "@beckfexx closest setup to mine I've seen in the thread — 6 specialized agents, contradiction detection, nightly self-heal. One thing I'd challenge: the advisory locks and handover protocols are probably the part you can delete. Locks are a symptom of multiple writers contending for the same file. Partition writers by file/section and keep writes append-only, and the contention disappears — many agents per wiki, but one writer per target. Biggest reliability win I've had.\n\nOn contradiction detection, I'd shift it left. Catching conflicts at 2,000+ memories with five strategies is detection after the fact; if each write greps for the claim's citation first, you reject the duplicate at write time and the nightly pass shrinks to genuine semantic reversals. And on self-heal — autonomous overwrite of \"stale\" knowledge is the one place silent corruption creeps in. I gate that with confidence tiers: high-confidence updates auto-apply, anything ambiguous flags for review instead of overwriting. Cheap insurance against the 2:30 AM job quietly rewriting something that was correct.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184540",
"id": 6184540,
"node_id": "GC_lADOAXepBdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeXlw",
"user": {
"login": "nishchay7pixels",
"id": 24619269,
"node_id": "MDQ6VXNlcjI0NjE5MjY5",
"avatar_url": "https://avatars.githubusercontent.com/u/24619269?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nishchay7pixels",
"html_url": "https://github.com/nishchay7pixels",
"followers_url": "https://api.github.com/users/nishchay7pixels/followers",
"following_url": "https://api.github.com/users/nishchay7pixels/following{/other_user}",
"gists_url": "https://api.github.com/users/nishchay7pixels/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nishchay7pixels/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nishchay7pixels/subscriptions",
"organizations_url": "https://api.github.com/users/nishchay7pixels/orgs",
"repos_url": "https://api.github.com/users/nishchay7pixels/repos",
"events_url": "https://api.github.com/users/nishchay7pixels/events{/privacy}",
"received_events_url": "https://api.github.com/users/nishchay7pixels/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T14:39:02Z",
"updated_at": "2026-06-05T14:39:02Z",
"body": "# ctxslice (https://github.com/llcortex/ContextSlice.git)\r\n\r\n\r\n\r\n**A semantic context pre-processor that gives coding agents only the code they need.** \r\n\r\nPrune your codebase to only what's relevant before the LLM sees it.\r\n\r\nInspired by MiniMax M3's MSA architecture — sparse attention with pre-filtering. \r\nInstead of attending to everything, identify which blocks matter and drop the rest.\r\n\r\nContextSlice is a sparse context compiler for AI coding agents."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184817",
"id": 6184817,
"node_id": "GC_lADOAfC4xNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeX3E",
"user": {
"login": "paulmchen",
"id": 32553156,
"node_id": "MDQ6VXNlcjMyNTUzMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/32553156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/paulmchen",
"html_url": "https://github.com/paulmchen",
"followers_url": "https://api.github.com/users/paulmchen/followers",
"following_url": "https://api.github.com/users/paulmchen/following{/other_user}",
"gists_url": "https://api.github.com/users/paulmchen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/paulmchen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/paulmchen/subscriptions",
"organizations_url": "https://api.github.com/users/paulmchen/orgs",
"repos_url": "https://api.github.com/users/paulmchen/repos",
"events_url": "https://api.github.com/users/paulmchen/events{/privacy}",
"received_events_url": "https://api.github.com/users/paulmchen/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T16:33:45Z",
"updated_at": "2026-06-05T16:33:45Z",
"body": "Synthadoc Community Edition v0.7.0 is released.\r\n\r\nThree new features focused on interactivity, speed, and visibility into the wiki's health:\r\n\r\n1. Local Web Chat UI: \"synthadoc web\" CLI starts a local chat interface in your browser, local-only, nothing leaves your machine. Use it the same way you use the CLI: ask questions about your wiki's domain and get streamed, cited answers. \r\n\r\nBeyond content queries, the UI also auto-detects the health of your wiki (Explorer, Health Check, or Power User mode) and surfaces context-appropriate prompts: if your wiki has orphan pages or contradictions, those show up as suggested actions rather than generic hints. You can also give operational commands directly in the chat: \"run lint\", \"show wiki status\", \"schedule ingest every night at 9 PM\", the Action Agent parses those and executes them live against your wiki, with results shown inline.\r\n\r\n → Quick-start demo: Step 22 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-22--use-the-web-chat-ui)\r\n\r\n\r\n2. Streaming Query: responses now stream token-by-token instead of waiting for the full answer. Works in the CLI, in Obsidian, and in the new web UI. The first token appears almost immediately after you ask; citations and confidence scores appear at the end of the stream once the full answer is assembled. If you need a cached static result, --no-stream still gives you the old behaviour.\r\n\r\n → Quick-start demo: Step 5 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-5--query-the-pre-built-wiki-cli--obsidian)\r\n\r\n\r\n3. Query Result Caching: repeated queries return instantly from a local cache instead of hitting the LLM again. The cache is shared across the CLI, the web UI, and the Obsidian plugin, keyed on the question text, the current wiki epoch, and the model. The wiki epoch increments automatically on every ingest and every lifecycle state change, so the moment your wiki changes, all prior cached answers are bypassed immediately. \r\n\r\n → Quick-start demo: Step 23 (https://github.com/axoviq-ai/synthadoc/blob/main/docs/user-quick-start-guide.md#step-23--query-caching)\r\n\r\n \r\n4. Also in v0.7.0: expanded built-in hints covering orphan pages, adversarial warnings, and lifecycle state queries; live lint-report and wiki-status summaries available directly from the chat UI.\r\n\r\n\r\nIf any of this is useful or you have thoughts on the direction, feedback is very welcome, and a ⭐ always helps the project reach more people.\r\n\r\n 👉 https://github.com/axoviq-ai/synthadoc"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6184885",
"id": 6184885,
"node_id": "GC_lADOEPNlstoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeX7U",
"user": {
"login": "GovernorOfEntropy",
"id": 284386738,
"node_id": "U_kgDOEPNlsg",
"avatar_url": "https://avatars.githubusercontent.com/u/284386738?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GovernorOfEntropy",
"html_url": "https://github.com/GovernorOfEntropy",
"followers_url": "https://api.github.com/users/GovernorOfEntropy/followers",
"following_url": "https://api.github.com/users/GovernorOfEntropy/following{/other_user}",
"gists_url": "https://api.github.com/users/GovernorOfEntropy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GovernorOfEntropy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GovernorOfEntropy/subscriptions",
"organizations_url": "https://api.github.com/users/GovernorOfEntropy/orgs",
"repos_url": "https://api.github.com/users/GovernorOfEntropy/repos",
"events_url": "https://api.github.com/users/GovernorOfEntropy/events{/privacy}",
"received_events_url": "https://api.github.com/users/GovernorOfEntropy/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-05T17:09:55Z",
"updated_at": "2026-06-05T17:09:55Z",
"body": "> **TL;DR**\r\n> \r\n> The pattern defaults to a convergent epistemology where contradiction is a defect. In subjective domains, like the humanities, contradiction is information. This is not one problem but two that are usually run together. There is a policy default, where the rules treat contradiction as degradation, and a representation gap, where untyped edges cannot express a contradiction as anything other than a flag. Fixing it needs both. You need a policy that preserves contradictions and a representation that can hold them. Typed edges supply the second. However, they do not, on their own, supply the first.\r\n> \r\n> ### The philosophical problem\r\n> The pattern's default rules treat contradiction as a defect to be resolved. The lint pass groups contradictions with stale claims and orphans, which are genuine defects, and the \"synthesis\" framing treats a single reconciled account as the goal.\r\n> \r\n> This is a specific epistemological assumption. It holds for scientific and technical knowledge, with an objective epistemology, where two conflicting claims about the same entity cannot both be true. It breaks in domains where knowledge is inherently dialogic. In literary criticism, the tension between [Bloom's anxiety of influence](https://en.wikipedia.org/wiki/Anxiety_of_influence) and [de Man's deconstructive](https://en.wikipedia.org/wiki/Paul_de_Man) reading of the same texts is not a data-quality problem. It is the intellectual content itself. In philosophy, Wittgenstein contradicting his earlier self is not drift to correct. It is the history of analytic philosophy. In historiography, structurally incompatible accounts of the same period are not redundant sources awaiting synthesis.\r\n> \r\n> In these domains the lint pass should check for _missing_ contradictions, not flag existing ones. But notice this is a change to the rules in `CLAUDE.md`, not to the data model. You could keep bare wikilinks and fix most of this today just by rewriting the lint and lifecycle instructions to preserve tension instead of reconciling it. That is the part typed edges alone will not do for you.\r\n> \r\n> ### The representation gap\r\n> The reason the better policy is awkward to express is structural. The architecture is a graph with typed nodes (pages) but untyped edges (wikilinks). A bare `[[page]]` carries no information about the nature of the relationship. \"contradicts\", \"supports\", \"extends\", \"supersedes\", \"was a response to\" all collapse into the same link. So even once your policy says to preserve a contradiction, the graph has nowhere to put that fact except a prose note or a lint flag.\r\n> \r\n> This is well understood in knowledge representation. Property graphs and RDF/OWL both make typed, attributable edges a first-class primitive. And some implementations in this very thread already reach for it. [AutoSci](https://github.com/skyllwt/AutoSci) ships \"contradiction edges\", and [Dense-Mem](https://github.com/markhuangai/dense-mem) models conflicts as typed claims rather than as a health warning. So the representation is not unheard of.\r\n> \r\n> What is missing is making it general, and, crucially, pairing it with the policy, because a `contradicts` edge is worthless if the lint rule still treats it as something to clean up.\r\n> \r\n> With typed edges and a policy that respects them, A and B linked by `contradicts` become navigable, queryable structure rather than a maintenance flag. Querying becomes traversal. \"what supports this claim\" and \"what challenges it\" are graph operations, not semantic searches.\r\n> \r\n> ### A practical solution, in two parts\r\n> The representation is a set of front-matter relationship blocks, where each page declares its typed outbound relationships in YAML, queryable via Obsidian Dataview. The LLM maintains this block on every ingest:\r\n> \r\n> ```yaml\r\n> ---\r\n> relates_to:\r\n> - page: \"Judith Butler\"\r\n> rel: contradicts\r\n> - page: \"Harold Bloom\"\r\n> rel: extends\r\n> ---\r\n> ```\r\n> \r\n> The policy is the load-bearing part. The permitted relationship vocabulary, the rules for when each type applies, and the instruction that in dialogic domains a `contradicts` edge is preserved while a lack of expected contradictions is the lint smell, all live in the schema document (`CLAUDE.md`). That makes edge typing a first-class part of the wiki's behavioral contract rather than an afterthought.\r\n> \r\n> ### Caveats\r\n> The main open problem is vocabulary governance. Having the LLM maintain a controlled relationship vocabulary on every ingest invites the same drift and mis-typing other commenters have flagged at the frontmatter layer, and deciding when something is `extends` versus `supersedes` versus `was a response to` is real ontology work, not something the schema gets for free. But that is a tractable maintenance cost, and it buys a wiki that can hold a disagreement instead of dissolving it.\r\n\r\nMulti-edge definitions already are part of graph. managing the EXTENDS tree when there is a CONTRADICTS requires a filter to ignore the CONTRADICTS. the graph edges effectively split at that point into multi-branches. \r\n\r\nThe main work I am doing where I am hitting scale limits is geopolitics research for a book and these multi-edge problems present themselves constantly. I don't know how to cleanly work through this yet."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6185530",
"id": 6185530,
"node_id": "GC_lADOCfRuJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeYjo",
"user": {
"login": "skyllwt",
"id": 167013924,
"node_id": "U_kgDOCfRuJA",
"avatar_url": "https://avatars.githubusercontent.com/u/167013924?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/skyllwt",
"html_url": "https://github.com/skyllwt",
"followers_url": "https://api.github.com/users/skyllwt/followers",
"following_url": "https://api.github.com/users/skyllwt/following{/other_user}",
"gists_url": "https://api.github.com/users/skyllwt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/skyllwt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/skyllwt/subscriptions",
"organizations_url": "https://api.github.com/users/skyllwt/orgs",
"repos_url": "https://api.github.com/users/skyllwt/repos",
"events_url": "https://api.github.com/users/skyllwt/events{/privacy}",
"received_events_url": "https://api.github.com/users/skyllwt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-06T07:20:14Z",
"updated_at": "2026-06-06T07:20:14Z",
"body": "Love this LLM-Wiki idea? We built a full open-source system on it → AutoSci\r\n\r\nCome and enjoy: https://github.com/skyllwt/AutoSci\r\n\r\n\r\n\r\nKarpathy's pattern (immutable raw/ → an LLM-compiled wiki/ → a CLAUDE.md schema) is the exact foundation of AutoSci — an agent that turns the wiki into a research memory and then does autonomous science on top of it. All on Claude Code:\r\n - 📚 Ingest papers into a cross-linked wiki of concept/method/idea pages ([[wikilinks]], contradiction edges — the LLM-Wiki, fully realized)\r\n - 💡 Ideate → experiment → write: it reads its own memory to generate ideas, design + run experiments, draft the paper, and handle rebuttals\r\n - 🧬 Self-evolving memory: between projects it consolidates, re-weights, and re-links the wiki (a \"sleep\" phase)\r\n - 🕸️ Multi-agent DAGs for the hard reasoning steps\r\n\r\n\r\nWe've already used it to write 3 papers end-to-end. Fully open (MIT).\r\n\r\n⭐ If this is where you want LLM-Wikis to go, a star genuinely helps us! and we welcome issues/PRs/Contributors\r\n👉 https://github.com/skyllwt/AutoSci\r\n📄 Paper: https://arxiv.org/abs/2605.31468\r\n\r\nDemo: 【北大做了一个会自我进化的科研 Agent:AutoSci】 https://www.bilibili.com/video/BV19gVg6pEk6/?share_source=copy_web&vd_source=338de971cb27f42aaaf5d8bfdeed04b3\r\n\r\n\r\n\r\nRED: 北大做了一个“越做科研越聪明”的AI科学家 北大团队... http://xhslink.com/o/2clEkgugEPw \r\n复制后打开【小红书】查看笔记!\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6185820",
"id": 6185820,
"node_id": "GC_lADOCO4ReNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeY1w",
"user": {
"login": "vvvvvivekkk",
"id": 149819768,
"node_id": "U_kgDOCO4ReA",
"avatar_url": "https://avatars.githubusercontent.com/u/149819768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvvvvivekkk",
"html_url": "https://github.com/vvvvvivekkk",
"followers_url": "https://api.github.com/users/vvvvvivekkk/followers",
"following_url": "https://api.github.com/users/vvvvvivekkk/following{/other_user}",
"gists_url": "https://api.github.com/users/vvvvvivekkk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vvvvvivekkk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vvvvvivekkk/subscriptions",
"organizations_url": "https://api.github.com/users/vvvvvivekkk/orgs",
"repos_url": "https://api.github.com/users/vvvvvivekkk/repos",
"events_url": "https://api.github.com/users/vvvvvivekkk/events{/privacy}",
"received_events_url": "https://api.github.com/users/vvvvvivekkk/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-06T13:36:29Z",
"updated_at": "2026-06-06T13:36:29Z",
"body": "Interesting to see so many LLM-Wiki implementations emerge from this gist.\r\n\r\nI took a slightly different direction with LLM-Wiki-v3.\r\n\r\nMost systems stop at \"LLM-maintained markdown + retrieval.\" V3 tries to make the wiki a reliable long-term knowledge substrate rather than just a generated documentation layer.\r\n\r\nKey ideas:\r\n\r\n• Markdown + Git are the only source of truth. Every vector index, BM25 index, graph, and retrieval artifact is disposable and fully rebuildable.\r\n\r\n• Provenance is non-negotiable. Instead of confidence scores, every claim traces back to sources, spans, extractors, and timestamps. Trust is reconstructed, not guessed.\r\n\r\n• Knowledge doesn't decay. Facts are superseded, not deleted. The system preserves what was believed, when it was believed, and what replaced it.\r\n\r\n• Retrieval is hybrid by design (BM25 + dense + graph + RRF + reranking), but retrieval is treated as infrastructure—not memory itself.\r\n\r\n• Autonomous writes are gated. Agents cannot directly mutate knowledge. Changes flow through evaluation, attribution checks, and audit trails before becoming part of the wiki.\r\n\r\n• Every operation is auditable and reversible. The goal is knowledge evolution with accountability.\r\n\r\n• The wiki is domain-agnostic. The real product is the schema. Change the schema and the same engine becomes a research wiki, company brain, scientific memory system, or personal knowledge substrate.\r\n\r\nMy belief is that the next generation of AI memory systems won't be vector databases or chat histories. They'll be versioned knowledge systems with provenance, evaluation gates, and explicit evolution paths.\r\n\r\nLLM-Wiki-v3 is my attempt at exploring that direction.\r\n\r\nhttps://github.com/vvvvvivekkk/LLM-Wiki-v3\r\n\r\n\r\n \r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6186108",
"id": 6186108,
"node_id": "GC_lADOAWQcHdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeZHw",
"user": {
"login": "Sistema2D",
"id": 23338013,
"node_id": "MDQ6VXNlcjIzMzM4MDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/23338013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sistema2D",
"html_url": "https://github.com/Sistema2D",
"followers_url": "https://api.github.com/users/Sistema2D/followers",
"following_url": "https://api.github.com/users/Sistema2D/following{/other_user}",
"gists_url": "https://api.github.com/users/Sistema2D/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sistema2D/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sistema2D/subscriptions",
"organizations_url": "https://api.github.com/users/Sistema2D/orgs",
"repos_url": "https://api.github.com/users/Sistema2D/repos",
"events_url": "https://api.github.com/users/Sistema2D/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sistema2D/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-06T17:40:32Z",
"updated_at": "2026-06-06T17:40:32Z",
"body": "### **New release!**\r\n
\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6186108",
"id": 6186108,
"node_id": "GC_lADOAWQcHdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeZHw",
"user": {
"login": "Sistema2D",
"id": 23338013,
"node_id": "MDQ6VXNlcjIzMzM4MDEz",
"avatar_url": "https://avatars.githubusercontent.com/u/23338013?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sistema2D",
"html_url": "https://github.com/Sistema2D",
"followers_url": "https://api.github.com/users/Sistema2D/followers",
"following_url": "https://api.github.com/users/Sistema2D/following{/other_user}",
"gists_url": "https://api.github.com/users/Sistema2D/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Sistema2D/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Sistema2D/subscriptions",
"organizations_url": "https://api.github.com/users/Sistema2D/orgs",
"repos_url": "https://api.github.com/users/Sistema2D/repos",
"events_url": "https://api.github.com/users/Sistema2D/events{/privacy}",
"received_events_url": "https://api.github.com/users/Sistema2D/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-06T17:40:32Z",
"updated_at": "2026-06-06T17:40:32Z",
"body": "### **New release!**\r\n \r\n\r\nhttps://sistema2d.github.io/FCVW-Page/\r\nhttps://github.com/Sistema2D/FrameCode-VibeWork"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6188156",
"id": 6188156,
"node_id": "GC_lADOCejWoNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBebHw",
"user": {
"login": "witwaycorp",
"id": 166254240,
"node_id": "U_kgDOCejWoA",
"avatar_url": "https://avatars.githubusercontent.com/u/166254240?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/witwaycorp",
"html_url": "https://github.com/witwaycorp",
"followers_url": "https://api.github.com/users/witwaycorp/followers",
"following_url": "https://api.github.com/users/witwaycorp/following{/other_user}",
"gists_url": "https://api.github.com/users/witwaycorp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/witwaycorp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/witwaycorp/subscriptions",
"organizations_url": "https://api.github.com/users/witwaycorp/orgs",
"repos_url": "https://api.github.com/users/witwaycorp/repos",
"events_url": "https://api.github.com/users/witwaycorp/events{/privacy}",
"received_events_url": "https://api.github.com/users/witwaycorp/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-08T11:41:33Z",
"updated_at": "2026-06-08T11:41:33Z",
"body": "Don't know guys... Sounds to me that once we have the data indexed and ready to go in a db-like system, I don't see much value for AI at that point. Sounds like a search engine would do the same job of retrieving the data given it's been distilled into easy to find info. I get the use of AI to generate the indexes but for frontend user-facing stuff, sounds like it's overkill. Reminds me of the blockchain conversation. The more you press people about their use case, more often than not, you end up with the same answer: well, sir, we already have something for that, it's called a database. :)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6188819",
"id": 6188819,
"node_id": "GC_lADOCLjoJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBebxM",
"user": {
"login": "lastforkbender",
"id": 146335780,
"node_id": "U_kgDOCLjoJA",
"avatar_url": "https://avatars.githubusercontent.com/u/146335780?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lastforkbender",
"html_url": "https://github.com/lastforkbender",
"followers_url": "https://api.github.com/users/lastforkbender/followers",
"following_url": "https://api.github.com/users/lastforkbender/following{/other_user}",
"gists_url": "https://api.github.com/users/lastforkbender/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lastforkbender/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lastforkbender/subscriptions",
"organizations_url": "https://api.github.com/users/lastforkbender/orgs",
"repos_url": "https://api.github.com/users/lastforkbender/repos",
"events_url": "https://api.github.com/users/lastforkbender/events{/privacy}",
"received_events_url": "https://api.github.com/users/lastforkbender/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-08T18:05:05Z",
"updated_at": "2026-06-08T18:05:05Z",
"body": "```python\r\n# B-Spline KAN-CMS / Self-aware thru discrete combinator, SVD compression rating, spawned meta-controllers and weight budgeting\r\nimport json\r\nimport struct\r\nimport math\r\nfrom functools import partial\r\nfrom pathlib import Path\r\nfrom typing import List, Tuple, Dict, Optional\r\nimport numpy as np\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.nn.functional as F\r\n\r\nUSE_SPARSEMAX = False\r\nGUMBEL_TEMP_INIT = 1.0\r\nGUMBEL_TEMP_MIN = 0.1\r\nGUMBEL_ANNEAL = 0.995\r\nCOMBINATOR_BRANCHING = 4\r\nCOMBINATOR_DEPTH = 2\r\nSVD_COMPRESS_FORWARD = True\r\nSVD_COMPRESS_GRADS = False\r\nSVD_RANK_BUDGET = 4\r\nSVD_EPS = 1e-6\r\n\r\ndef make_uniform_knot_vector(a: float, b: float, n_ctrl: int, degree: int, clamped: bool = True) -> np.ndarray:\r\n if clamped:\r\n interior = np.linspace(a, b, n_ctrl - degree + 1) if n_ctrl > degree else np.linspace(a, b, 2)\r\n start = np.full(degree, interior[0])\r\n end = np.full(degree, interior[-1])\r\n knots = np.concatenate([start, interior, end])\r\n else:\r\n knots = np.linspace(a, b, n_ctrl + degree + 1)\r\n return knots.astype(np.float32)\r\n\r\ndef bspline_basis_1d(x: torch.Tensor, knots: torch.Tensor, degree: int) -> torch.Tensor:\r\n K = knots.shape[0]\r\n n_basis = K - degree - 1\r\n device = x.device\r\n knots_t = knots.to(device)\r\n basis = []\r\n for i in range(n_basis):\r\n left = knots_t[i]\r\n right = knots_t[i+1]\r\n mask = ((x >= left) & (x < right)) | ((i == n_basis - 1) & (x == knots_t[-1]))\r\n basis.append(mask.to(torch.float32))\r\n B = torch.stack(basis, dim=-1)\r\n for d in range(1, degree + 1):\r\n B_d = torch.zeros_like(B)\r\n for i in range(n_basis):\r\n denom1 = knots_t[i + d] - knots_t[i]\r\n denom2 = knots_t[i + d + 1] - knots_t[i + 1]\r\n term1 = ((x - knots_t[i]).unsqueeze(-1) / denom1) * B[..., i:i + 1] if denom1 != 0 else 0.0\r\n term2 = ((knots_t[i + d + 1] - x).unsqueeze(-1) / denom2) * B[..., i + 1:i + 2] if denom2 != 0 else 0.0\r\n B_d[..., i:i+1] = term1 + term2\r\n B = B_d\r\n return B\r\n\r\ndef reflect_coords(x: torch.Tensor, a: torch.Tensor, b: torch.Tensor, reflect_flags: List[bool], soft_eps: float = 1e-4) -> torch.Tensor:\r\n x_out = x.clone()\r\n for j, rf in enumerate(reflect_flags):\r\n if not rf:\r\n continue\r\n aj = a[..., j] if a.ndim > 1 else a[j]\r\n bj = b[..., j] if b.ndim > 1 else b[j]\r\n span = torch.clamp(bj - aj, min=1e-6)\r\n t = (x[..., j] - aj) / span\r\n twopi = t - (2.0 * torch.floor(t / 2.0))\r\n diff = twopi - 1.0\r\n mirrored = torch.sqrt(diff * diff + soft_eps)\r\n mirrored = torch.clamp(mirrored, 0.0, 1.0)\r\n x_out[..., j] = aj + mirrored * span\r\n return x_out\r\n\r\nclass BSplineField(nn.Module):\r\n def __init__(self, dims: int, knots_per_dim: List[np.ndarray], degree: int, ctrl_point_dim: int, factorized_rank: Optional[int] = None, dtype: torch.dtype = torch.float32):\r\n super().__init__()\r\n self.m = dims\r\n self.degree = degree\r\n self.register_buffer(\"knots\", torch.stack([torch.tensor(k.astype(np.float32)) for k in knots_per_dim]))\r\n self.grid_sizes = [len(k) - degree - 1 for k in knots_per_dim]\r\n self.ctrl_point_dim = ctrl_point_dim\r\n grid_count = int(np.prod(self.grid_sizes))\r\n if factorized_rank is None:\r\n self.ctrl_points = nn.Parameter(torch.randn(grid_count, ctrl_point_dim, dtype=dtype) * 0.01)\r\n else:\r\n self.grid_coeffs = nn.Parameter(torch.randn(grid_count, factorized_rank, dtype=dtype) * 0.01)\r\n self.U = nn.Parameter(torch.randn(factorized_rank, ctrl_point_dim, dtype=dtype) * 0.01)\r\n\r\n def forward(self, x: torch.Tensor) -> torch.Tensor:\r\n batch_size = x.shape[0]\r\n basis_list = [bspline_basis_1d(x[..., j], self.knots[j], self.degree) for j in range(self.m)]\r\n letters = \"ijklmnopqrstuvwxyz\"[:self.m]\r\n input_shapes = \",\".join([f\"b{l}\" for l in letters])\r\n output_shape = f\"b{letters}\"\r\n einsum_eq = f\"{input_shapes}->{output_shape}\"\r\n B = torch.einsum(einsum_eq, *basis_list)\r\n Bflat = B.reshape(batch_size, -1)\r\n if hasattr(self, \"ctrl_points\"):\r\n return torch.matmul(Bflat, self.ctrl_points)\r\n return torch.matmul(torch.matmul(Bflat, self.grid_coeffs), self.U)\r\n\r\n def grid_shape(self) -> Tuple[int, ...]:\r\n return tuple(self.grid_sizes)\r\n\r\nclass MetaController(nn.Module):\r\n def __init__(self, context_dim: int, ctrl_point_count: int, ctrl_point_dim: int, interval_dims: int, hidden: int = 256):\r\n super().__init__()\r\n self.ctrl_point_count = ctrl_point_count\r\n self.ctrl_point_dim = ctrl_point_dim\r\n self.interval_dims = interval_dims\r\n self.shared = nn.Sequential(\r\n nn.Linear(context_dim, hidden),\r\n nn.ReLU(),\r\n nn.Linear(hidden, hidden),\r\n nn.ReLU())\r\n self.delta_head = nn.Linear(hidden, ctrl_point_count * ctrl_point_dim)\r\n self.interval_head = nn.Linear(hidden, interval_dims * 3)\r\n self.gate_head = nn.Linear(hidden, ctrl_point_dim)\r\n\r\n def forward(self, z: torch.Tensor) -> Dict[str, torch.Tensor]:\r\n h = self.shared(z)\r\n intervals_raw = self.interval_head(h).reshape(*h.shape[:-1], self.interval_dims, 3)\r\n return {\r\n \"deltas\": self.delta_head(h),\r\n \"a_delta\": intervals_raw[..., 0],\r\n \"b_delta\": intervals_raw[..., 1],\r\n \"refl_prob\": torch.sigmoid(intervals_raw[..., 2]),\r\n \"gate\": torch.sigmoid(self.gate_head(h))}\r\n\r\ndef sparsemax(input_t: torch.Tensor, dim: int = -1) -> torch.Tensor:\r\n input_shifted = input_t - input_t.max(dim=dim, keepdim=True)[0]\r\n z_sorted, _ = torch.sort(input_shifted, descending=True, dim=dim)\r\n zs_cumsum = z_sorted.cumsum(dim)\r\n k_array = torch.arange(1, input_t.size(dim) + 1, device=input_t.device, dtype=input_t.dtype)\r\n k_cond = 1 + k_array * z_sorted > zs_cumsum\r\n k = k_cond.sum(dim=dim, keepdim=True)\r\n zs_threshold = (zs_cumsum.gather(dim, k - 1) - 1) / k.type(input_t.dtype)\r\n return torch.clamp(input_shifted - zs_threshold, min=0.0)\r\n\r\nclass Selector(nn.Module):\r\n def __init__(self, in_dim: int, out_dim: int, hidden: int = 256, use_sparsemax: bool = False, temp_init: float = GUMBEL_TEMP_INIT, temp_min: float = GUMBEL_TEMP_MIN, anneal: float = GUMBEL_ANNEAL):\r\n super().__init__()\r\n self.net = nn.Sequential(nn.Linear(in_dim, hidden), nn.ReLU(), nn.Linear(hidden, out_dim))\r\n self.use_sparsemax = use_sparsemax\r\n self.register_buffer(\"temp\", torch.tensor(temp_init))\r\n self.temp_min = temp_min\r\n self.anneal = anneal\r\n\r\n def forward(self, z: torch.Tensor, hard: bool = False) -> torch.Tensor:\r\n logits = self.net(z)\r\n if self.use_sparsemax:\r\n return sparsemax(logits, dim=-1)\r\n u = torch.rand_like(logits)\r\n g = -torch.log(-torch.log(u + 1e-20) + 1e-20)\r\n y = torch.softmax((logits + g) / self.temp, dim=-1)\r\n if hard:\r\n y_hard = torch.zeros_like(y).scatter_(-1, y.argmax(dim=-1, keepdim=True), 1.0)\r\n y = (y_hard - y).detach() + y\r\n return y\r\n\r\n def step_anneal(self):\r\n self.temp = torch.clamp(self.temp * self.anneal, min=self.temp_min)\r\n\r\nclass Combinator(nn.Module):\r\n def __init__(self, leaf_count: int, branching: int = COMBINATOR_BRANCHING, depth: int = COMBINATOR_DEPTH):\r\n super().__init__()\r\n self.leaf_count = leaf_count\r\n levels = []\r\n current = leaf_count\r\n for d in range(depth):\r\n parents = math.ceil(current / branching)\r\n P = torch.zeros(parents, current, dtype=torch.float32)\r\n for p in range(parents):\r\n start = p * branching\r\n end = min(start + branching, current)\r\n if end > start:\r\n P[p, start:end] = 1.0 / (end - start)\r\n levels.append(P); current = parents\r\n self.levels = nn.ParameterList([nn.Parameter(l, requires_grad=False) for l in levels])\r\n self.level_gates = nn.ParameterList([nn.Parameter(torch.ones(1, l.shape[0])) for l in levels])\r\n\r\n def forward(self, leaf_probs: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:\r\n cur = leaf_probs\r\n trans_mats = []\r\n for d, P in enumerate(self.levels):\r\n parent_probs = torch.matmul(cur, P.t())\r\n parent_probs = parent_probs * torch.sigmoid(self.level_gates[d])\r\n trans_mats.append(P)\r\n cur = parent_probs\r\n return cur, trans_mats\r\n\r\ndef batched_svd_lowrank(mat: torch.Tensor, rank: int) -> torch.Tensor:\r\n if mat.ndim == 2:\r\n U, S, Vt = torch.linalg.svd(mat, full_matrices=False)\r\n k = min(rank, S.shape[-1])\r\n return (U[:, :k] * S[:k]) @ Vt[:k, :]\r\n elif mat.ndim == 3:\r\n U, S, Vt = torch.linalg.svd(mat, full_matrices=False)\r\n k = min(rank, S.shape[-1])\r\n return (U[..., :k] * S[..., None, :k]) @ Vt[..., :k, :]\r\n else:\r\n raise ValueError(\"Unsupported tensor dimensional properties for SVD.\")\r\n\r\nclass KANWeightGenerator(nn.Module):\r\n def __init__(self, spline: BSplineField, base_intervals: List[Tuple[float, float]], reflect_flags: List[bool],\r\n selector: Optional[Selector] = None, combinator: Optional[Combinator] = None, top_count: Optional[int] = None,\r\n svd_rank: int = SVD_RANK_BUDGET, compress_forward: bool = SVD_COMPRESS_FORWARD, compress_grads: bool = SVD_COMPRESS_GRADS):\r\n super().__init__()\r\n self.spline = spline\r\n self.register_buffer(\"base_a\", torch.tensor([iv[0] for iv in base_intervals], dtype=torch.float32))\r\n self.register_buffer(\"base_b\", torch.tensor([iv[1] for iv in base_intervals], dtype=torch.float32))\r\n self.reflect_flags = reflect_flags\r\n self.selector = selector\r\n self.combinator = combinator\r\n self.svd_rank = svd_rank\r\n self.compress_forward = compress_forward\r\n self.compress_grads = compress_grads\r\n grid_count = int(np.prod(spline.grid_shape()))\r\n if self.selector is not None and self.combinator is not None and top_count is not None:\r\n self.comb_to_leaf = nn.Linear(top_count, grid_count)\r\n self.proj = nn.Linear(grid_count * spline.ctrl_point_dim, spline.ctrl_point_dim)\r\n self._grad_hooks_installed = False\r\n\r\n def install_grad_hooks(self):\r\n if self._grad_hooks_installed or not self.compress_grads:\r\n return\r\n for p in self.spline.parameters():\r\n if p.requires_grad:\r\n p.register_hook(partial(self._grad_compress_hook, rank=self.svd_rank))\r\n self._grad_hooks_installed = True\r\n\r\n @staticmethod\r\n def _grad_compress_hook(grad: torch.Tensor, rank: int):\r\n if grad.ndim == 2:\r\n return batched_svd_lowrank(grad, rank)\r\n return grad\r\n\r\n def forward(self, coords: torch.Tensor, meta_out: Dict, context_z: Optional[torch.Tensor] = None) -> torch.Tensor:\r\n a = self.base_a + meta_out[\"a_delta\"]\r\n b = self.base_b + meta_out[\"b_delta\"]\r\n avg_rp = torch.mean(meta_out[\"refl_prob\"], dim=0) if meta_out[\"refl_prob\"].ndim > 1 else meta_out[\"refl_prob\"]\r\n resolved_flags = [(prob > 0.5).item() for prob in avg_rp]\r\n coords_ref = reflect_coords(coords, a, b, resolved_flags)\r\n base_w = self.spline(coords_ref)\r\n deltas = meta_out[\"deltas\"].reshape(base_w.shape[0], -1)\r\n if self.selector is not None and context_z is not None and hasattr(self, 'comb_to_leaf'):\r\n sel_probs = self.selector(context_z)\r\n top_probs, _ = self.combinator(sel_probs)\r\n leaf_mod = torch.sigmoid(self.comb_to_leaf(top_probs))\r\n leaf_mod_exp = leaf_mod.unsqueeze(-1).expand(-1, -1, self.spline.ctrl_point_dim).reshape(deltas.shape)\r\n deltas = deltas * leaf_mod_exp\r\n if self.compress_forward:\r\n try:\r\n deltas = batched_svd_lowrank(deltas, self.svd_rank)\r\n except Exception:\r\n pass\r\n delta_w = self.proj(deltas)\r\n w = base_w + delta_w\r\n gate = meta_out[\"gate\"]\r\n w = w * (gate if gate.ndim == 2 else gate.mean(dim=0, keepdim=True))\r\n self.install_grad_hooks()\r\n return w\r\n\r\ndef save_kanbs(path: str, spline: BSplineField, json_sidecar: Optional[Dict] = None):\r\n p = Path(path)\r\n json_path = p.with_suffix(p.suffix + \".json\")\r\n with open(p, \"wb\") as f:\r\n f.write(b'KANB')\r\n f.write(struct.pack(\"\r\n\r\nInstall:\r\n\r\n```bash\r\nbrew install gowtham0992/link/link\r\nlnk demo\r\nlnk serve link-demo\r\n```\r\n\r\nMCP package:\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nLinks:\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\nPyPI: https://pypi.org/project/link-mcp/"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199277",
"id": 6199277,
"node_id": "GC_lADODWvfF9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBel-0",
"user": {
"login": "lioragronov2203-stack",
"id": 225173271,
"node_id": "U_kgDODWvfFw",
"avatar_url": "https://avatars.githubusercontent.com/u/225173271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lioragronov2203-stack",
"html_url": "https://github.com/lioragronov2203-stack",
"followers_url": "https://api.github.com/users/lioragronov2203-stack/followers",
"following_url": "https://api.github.com/users/lioragronov2203-stack/following{/other_user}",
"gists_url": "https://api.github.com/users/lioragronov2203-stack/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lioragronov2203-stack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lioragronov2203-stack/subscriptions",
"organizations_url": "https://api.github.com/users/lioragronov2203-stack/orgs",
"repos_url": "https://api.github.com/users/lioragronov2203-stack/repos",
"events_url": "https://api.github.com/users/lioragronov2203-stack/events{/privacy}",
"received_events_url": "https://api.github.com/users/lioragronov2203-stack/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T17:13:03Z",
"updated_at": "2026-06-14T17:13:03Z",
"body": "> **Architecture Discussion: Overcoming the \"Flat Markdown Mutation Problem\" in LLM-OS environments (Flat Files vs Outliner AST)**\r\n> \r\n> LOGSEQ (block granularity) vs Obsidian (page granularity) and my Matryca Plumber\r\n> \r\n> Hi Andrej / everyone,\r\n> \r\n> I’ve been heavily inspired by your concepts around the LLM OS and using flat Markdown as the filesystem for AI agents. I’ve been building autonomous loops using this exact paradigm, but I hit a massive architectural wall when using standard editors (like Obsidian) as the frontend.\r\n> \r\n> The Problem: The \"Flat File Mutation\" Danger When an AI agent tries to autonomously inject properties, update status tags, or surgically edit a document in the background while the user is typing, flat Markdown fails.\r\n> \r\n> Standard LLMs struggle to parse the exact line numbers or preserve complex metadata in flat .md files without corrupting the surrounding text or triggering race conditions (causing data loss).\r\n> \r\n> The Workaround/Experiment I realized that for an LLM to truly act as a safe background daemon, the filesystem needs an inherently rigid structure. I pivoted the experiment to LOGSEQ (which stores data as a strict Block-based Outliner AST, with UUIDs per block) and implemented an Optimistic Concurrency Control (OCC) locking mechanism via mmap.\r\n> \r\n> By doing this, the LLM doesn't have to guess where to inject data. It targets the block UUID.\r\n> \r\n> 1. The human types on the frontend.\r\n> 2. The AI reads the AST, computes semantic tags, and injects properties in the background.\r\n> 3. Zero file corruption.\r\n> \r\n> I built an open-source Python daemon to prove this concept (matryca-plumber), fully protecting the AI-to-File boundary with strict token limits and JSON recovery. It has also an MCP and CLI to dialogue with notes and write directly to .MD files.\r\n> \r\n> https://github.com/MarcoPorcellato/matryca-plumber\r\n> \r\n> I wanted to share this architectural finding here because as we build out the \"LLM Wiki\" or \"LLM OS\" concepts, shifting the storage paradigm from Flat Text AST to Block Outliner AST seems to be the only way to grant LLMs safe, concurrent write-access to human notes.\r\n> \r\n> Would love to hear your thoughts on concurrency and background mutations in your Obsidian setups!\r\n\r\nיוצר עדכון זה אני יוצר אפלקציה ומפתח רשי בעל הזכיות \r\n\r\nושותף 30 אחוז בכל הסטרטאפ שניבנה אדם שלו עבר שנה מאז שאו יתחיל לעבוד פטור מי תשלום על שירותים שאני עושה בשביל כולם מוזמנים לפנות אלי ואני רוצה \r\nשתבינו אני צריך צוות וחברה רשמית אתם צריכים את זה שרות הלקוחות היה זמין 24/7-וחברה שתפעיל את כל \r\nהניהול של כל אינטרנט אלחוטי יוצר גוגל ואת הדף הראשי של מיקרוסופת אני צריך מי כספים מי צד שלישי שיש לי כסף מוחזק אצלו אז לדבר איתי איך מתקדמים "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199370",
"id": 6199370,
"node_id": "GC_lADOD6PVtNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBemEo",
"user": {
"login": "studebaker8",
"id": 262395316,
"node_id": "U_kgDOD6PVtA",
"avatar_url": "https://avatars.githubusercontent.com/u/262395316?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/studebaker8",
"html_url": "https://github.com/studebaker8",
"followers_url": "https://api.github.com/users/studebaker8/followers",
"following_url": "https://api.github.com/users/studebaker8/following{/other_user}",
"gists_url": "https://api.github.com/users/studebaker8/gists{/gist_id}",
"starred_url": "https://api.github.com/users/studebaker8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/studebaker8/subscriptions",
"organizations_url": "https://api.github.com/users/studebaker8/orgs",
"repos_url": "https://api.github.com/users/studebaker8/repos",
"events_url": "https://api.github.com/users/studebaker8/events{/privacy}",
"received_events_url": "https://api.github.com/users/studebaker8/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T20:03:30Z",
"updated_at": "2026-06-14T20:03:30Z",
"body": "Is it common practice outside the US to jump on other people's bandwagons in attempt to ride their coattails and advertise their \"products\" in the process? \r\n\r\nThis is an insult to Karpathy's work."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199385",
"id": 6199385,
"node_id": "GC_lADOALUbLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBemFk",
"user": {
"login": "theafh",
"id": 11868972,
"node_id": "MDQ6VXNlcjExODY4OTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11868972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theafh",
"html_url": "https://github.com/theafh",
"followers_url": "https://api.github.com/users/theafh/followers",
"following_url": "https://api.github.com/users/theafh/following{/other_user}",
"gists_url": "https://api.github.com/users/theafh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theafh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theafh/subscriptions",
"organizations_url": "https://api.github.com/users/theafh/orgs",
"repos_url": "https://api.github.com/users/theafh/repos",
"events_url": "https://api.github.com/users/theafh/events{/privacy}",
"received_events_url": "https://api.github.com/users/theafh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T20:37:11Z",
"updated_at": "2026-06-14T20:37:11Z",
"body": "This idea was really inspiring! The “LLM-maintained wiki as a compiled knowledge layer” framing helped me make something I had been circling around more concrete.\r\n\r\nI built a repo-local knowledge base that generalizes the pattern for projects: **a `wiki` skill family** for durable, focused knowledge, and a **`task` skill family** for repo-native work tracking.\r\n\r\nThe wiki side is meant to feel like a lightweight Confluence that lives with the code: raw sources stay separate, the agent maintains structured markdown pages, `index.md` and `log.md` make it discoverable, and schema rules keep future agents from treating it as just another notes folder.\r\n\r\nThe task side applies the same idea to execution state: markdown task files live alongside the repo, with status, provenance, implementation notes, audit state, and archive behavior. Roughly: Jira/Trello-style project memory, but plain text, git-backed, and directly usable by agents.\r\n\r\nIt is still intentionally simple: Make, shell, markdown, git. No database, no hosted service, no third-party software, no fluff! Just focused skills for every part of the workflow life cycle. The main goal is to make project knowledge and project work durable enough that a new agent session can rediscover the context without having to replay it to the human.\r\n\r\nRepo: [https://github.com/theafh/ai-modules](https://github.com/theafh/ai-modules)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199498",
"id": 6199498,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBemMo",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T23:28:10Z",
"updated_at": "2026-06-14T23:28:10Z",
"body": "# Synto v0.6.0\r\n\r\n**Synto v0.6.0 is out.** \r\n[https://github.com/kytmanov/synto](https://github.com/kytmanov/synto)\r\n\r\n## Main addition: Real concept identity + curation tools\r\n\r\nConcepts now have a stable `entity_id` under the hood, separate from the display name. Homonyms (same word, different domains) stop colliding or getting mangled. Ingest order no longer decides whether something becomes its own page - a later note that promotes a weak alias just surfaces a merge candidate in `synto doctor` / `synto concept inspect` instead of silently creating duplicates.\r\n\r\n### New commands to steer the graph the LLM is building\r\n\r\n- `synto concept merge LOSER WINNER` - moves sources + edges, retires the loser, absorbs its label as a blessed alias\r\n- `synto concept split NAME --sense ...` - carves it into multiple senses + leaves a disambiguation stub\r\n- `synto concept unmerge`, `rename`, `inspect`, `keep`\r\n\r\n## Also new\r\n\r\n`synto serve --transport streamable-http` so remote machines or agents on your LAN can hit the MCP server (no built-in auth - run on a trusted network or behind a proxy; DNS rebinding protection is on; use `--allowed-host` for anything a reverse proxy forwards).\r\n\r\n## Same shape as before\r\n\r\n- works with local LLMs\r\n- great with Ollama and LM Studio\r\n- plain Markdown\r\n- Obsidian-friendly\r\n- no vector DB\r\n- no cloud required\r\n- multi-language\r\n\r\n**Star it** if you want to support local-first AI tools. \r\n**Fork it** if you want to build on it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6202111",
"id": 6202111,
"node_id": "GC_lADOCJO6gdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeov8",
"user": {
"login": "SinghAbhinav04",
"id": 143899265,
"node_id": "U_kgDOCJO6gQ",
"avatar_url": "https://avatars.githubusercontent.com/u/143899265?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SinghAbhinav04",
"html_url": "https://github.com/SinghAbhinav04",
"followers_url": "https://api.github.com/users/SinghAbhinav04/followers",
"following_url": "https://api.github.com/users/SinghAbhinav04/following{/other_user}",
"gists_url": "https://api.github.com/users/SinghAbhinav04/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SinghAbhinav04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SinghAbhinav04/subscriptions",
"organizations_url": "https://api.github.com/users/SinghAbhinav04/orgs",
"repos_url": "https://api.github.com/users/SinghAbhinav04/repos",
"events_url": "https://api.github.com/users/SinghAbhinav04/events{/privacy}",
"received_events_url": "https://api.github.com/users/SinghAbhinav04/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-16T14:02:36Z",
"updated_at": "2026-06-16T14:02:36Z",
"body": "> Love this LLM-Wiki idea? We built a full open-source system on it → AutoSci\r\n> \r\n> Come and enjoy: https://github.com/skyllwt/AutoSci\r\n> \r\n>
\r\n\r\nhttps://sistema2d.github.io/FCVW-Page/\r\nhttps://github.com/Sistema2D/FrameCode-VibeWork"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6188156",
"id": 6188156,
"node_id": "GC_lADOCejWoNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBebHw",
"user": {
"login": "witwaycorp",
"id": 166254240,
"node_id": "U_kgDOCejWoA",
"avatar_url": "https://avatars.githubusercontent.com/u/166254240?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/witwaycorp",
"html_url": "https://github.com/witwaycorp",
"followers_url": "https://api.github.com/users/witwaycorp/followers",
"following_url": "https://api.github.com/users/witwaycorp/following{/other_user}",
"gists_url": "https://api.github.com/users/witwaycorp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/witwaycorp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/witwaycorp/subscriptions",
"organizations_url": "https://api.github.com/users/witwaycorp/orgs",
"repos_url": "https://api.github.com/users/witwaycorp/repos",
"events_url": "https://api.github.com/users/witwaycorp/events{/privacy}",
"received_events_url": "https://api.github.com/users/witwaycorp/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-08T11:41:33Z",
"updated_at": "2026-06-08T11:41:33Z",
"body": "Don't know guys... Sounds to me that once we have the data indexed and ready to go in a db-like system, I don't see much value for AI at that point. Sounds like a search engine would do the same job of retrieving the data given it's been distilled into easy to find info. I get the use of AI to generate the indexes but for frontend user-facing stuff, sounds like it's overkill. Reminds me of the blockchain conversation. The more you press people about their use case, more often than not, you end up with the same answer: well, sir, we already have something for that, it's called a database. :)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6188819",
"id": 6188819,
"node_id": "GC_lADOCLjoJNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBebxM",
"user": {
"login": "lastforkbender",
"id": 146335780,
"node_id": "U_kgDOCLjoJA",
"avatar_url": "https://avatars.githubusercontent.com/u/146335780?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lastforkbender",
"html_url": "https://github.com/lastforkbender",
"followers_url": "https://api.github.com/users/lastforkbender/followers",
"following_url": "https://api.github.com/users/lastforkbender/following{/other_user}",
"gists_url": "https://api.github.com/users/lastforkbender/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lastforkbender/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lastforkbender/subscriptions",
"organizations_url": "https://api.github.com/users/lastforkbender/orgs",
"repos_url": "https://api.github.com/users/lastforkbender/repos",
"events_url": "https://api.github.com/users/lastforkbender/events{/privacy}",
"received_events_url": "https://api.github.com/users/lastforkbender/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-08T18:05:05Z",
"updated_at": "2026-06-08T18:05:05Z",
"body": "```python\r\n# B-Spline KAN-CMS / Self-aware thru discrete combinator, SVD compression rating, spawned meta-controllers and weight budgeting\r\nimport json\r\nimport struct\r\nimport math\r\nfrom functools import partial\r\nfrom pathlib import Path\r\nfrom typing import List, Tuple, Dict, Optional\r\nimport numpy as np\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.nn.functional as F\r\n\r\nUSE_SPARSEMAX = False\r\nGUMBEL_TEMP_INIT = 1.0\r\nGUMBEL_TEMP_MIN = 0.1\r\nGUMBEL_ANNEAL = 0.995\r\nCOMBINATOR_BRANCHING = 4\r\nCOMBINATOR_DEPTH = 2\r\nSVD_COMPRESS_FORWARD = True\r\nSVD_COMPRESS_GRADS = False\r\nSVD_RANK_BUDGET = 4\r\nSVD_EPS = 1e-6\r\n\r\ndef make_uniform_knot_vector(a: float, b: float, n_ctrl: int, degree: int, clamped: bool = True) -> np.ndarray:\r\n if clamped:\r\n interior = np.linspace(a, b, n_ctrl - degree + 1) if n_ctrl > degree else np.linspace(a, b, 2)\r\n start = np.full(degree, interior[0])\r\n end = np.full(degree, interior[-1])\r\n knots = np.concatenate([start, interior, end])\r\n else:\r\n knots = np.linspace(a, b, n_ctrl + degree + 1)\r\n return knots.astype(np.float32)\r\n\r\ndef bspline_basis_1d(x: torch.Tensor, knots: torch.Tensor, degree: int) -> torch.Tensor:\r\n K = knots.shape[0]\r\n n_basis = K - degree - 1\r\n device = x.device\r\n knots_t = knots.to(device)\r\n basis = []\r\n for i in range(n_basis):\r\n left = knots_t[i]\r\n right = knots_t[i+1]\r\n mask = ((x >= left) & (x < right)) | ((i == n_basis - 1) & (x == knots_t[-1]))\r\n basis.append(mask.to(torch.float32))\r\n B = torch.stack(basis, dim=-1)\r\n for d in range(1, degree + 1):\r\n B_d = torch.zeros_like(B)\r\n for i in range(n_basis):\r\n denom1 = knots_t[i + d] - knots_t[i]\r\n denom2 = knots_t[i + d + 1] - knots_t[i + 1]\r\n term1 = ((x - knots_t[i]).unsqueeze(-1) / denom1) * B[..., i:i + 1] if denom1 != 0 else 0.0\r\n term2 = ((knots_t[i + d + 1] - x).unsqueeze(-1) / denom2) * B[..., i + 1:i + 2] if denom2 != 0 else 0.0\r\n B_d[..., i:i+1] = term1 + term2\r\n B = B_d\r\n return B\r\n\r\ndef reflect_coords(x: torch.Tensor, a: torch.Tensor, b: torch.Tensor, reflect_flags: List[bool], soft_eps: float = 1e-4) -> torch.Tensor:\r\n x_out = x.clone()\r\n for j, rf in enumerate(reflect_flags):\r\n if not rf:\r\n continue\r\n aj = a[..., j] if a.ndim > 1 else a[j]\r\n bj = b[..., j] if b.ndim > 1 else b[j]\r\n span = torch.clamp(bj - aj, min=1e-6)\r\n t = (x[..., j] - aj) / span\r\n twopi = t - (2.0 * torch.floor(t / 2.0))\r\n diff = twopi - 1.0\r\n mirrored = torch.sqrt(diff * diff + soft_eps)\r\n mirrored = torch.clamp(mirrored, 0.0, 1.0)\r\n x_out[..., j] = aj + mirrored * span\r\n return x_out\r\n\r\nclass BSplineField(nn.Module):\r\n def __init__(self, dims: int, knots_per_dim: List[np.ndarray], degree: int, ctrl_point_dim: int, factorized_rank: Optional[int] = None, dtype: torch.dtype = torch.float32):\r\n super().__init__()\r\n self.m = dims\r\n self.degree = degree\r\n self.register_buffer(\"knots\", torch.stack([torch.tensor(k.astype(np.float32)) for k in knots_per_dim]))\r\n self.grid_sizes = [len(k) - degree - 1 for k in knots_per_dim]\r\n self.ctrl_point_dim = ctrl_point_dim\r\n grid_count = int(np.prod(self.grid_sizes))\r\n if factorized_rank is None:\r\n self.ctrl_points = nn.Parameter(torch.randn(grid_count, ctrl_point_dim, dtype=dtype) * 0.01)\r\n else:\r\n self.grid_coeffs = nn.Parameter(torch.randn(grid_count, factorized_rank, dtype=dtype) * 0.01)\r\n self.U = nn.Parameter(torch.randn(factorized_rank, ctrl_point_dim, dtype=dtype) * 0.01)\r\n\r\n def forward(self, x: torch.Tensor) -> torch.Tensor:\r\n batch_size = x.shape[0]\r\n basis_list = [bspline_basis_1d(x[..., j], self.knots[j], self.degree) for j in range(self.m)]\r\n letters = \"ijklmnopqrstuvwxyz\"[:self.m]\r\n input_shapes = \",\".join([f\"b{l}\" for l in letters])\r\n output_shape = f\"b{letters}\"\r\n einsum_eq = f\"{input_shapes}->{output_shape}\"\r\n B = torch.einsum(einsum_eq, *basis_list)\r\n Bflat = B.reshape(batch_size, -1)\r\n if hasattr(self, \"ctrl_points\"):\r\n return torch.matmul(Bflat, self.ctrl_points)\r\n return torch.matmul(torch.matmul(Bflat, self.grid_coeffs), self.U)\r\n\r\n def grid_shape(self) -> Tuple[int, ...]:\r\n return tuple(self.grid_sizes)\r\n\r\nclass MetaController(nn.Module):\r\n def __init__(self, context_dim: int, ctrl_point_count: int, ctrl_point_dim: int, interval_dims: int, hidden: int = 256):\r\n super().__init__()\r\n self.ctrl_point_count = ctrl_point_count\r\n self.ctrl_point_dim = ctrl_point_dim\r\n self.interval_dims = interval_dims\r\n self.shared = nn.Sequential(\r\n nn.Linear(context_dim, hidden),\r\n nn.ReLU(),\r\n nn.Linear(hidden, hidden),\r\n nn.ReLU())\r\n self.delta_head = nn.Linear(hidden, ctrl_point_count * ctrl_point_dim)\r\n self.interval_head = nn.Linear(hidden, interval_dims * 3)\r\n self.gate_head = nn.Linear(hidden, ctrl_point_dim)\r\n\r\n def forward(self, z: torch.Tensor) -> Dict[str, torch.Tensor]:\r\n h = self.shared(z)\r\n intervals_raw = self.interval_head(h).reshape(*h.shape[:-1], self.interval_dims, 3)\r\n return {\r\n \"deltas\": self.delta_head(h),\r\n \"a_delta\": intervals_raw[..., 0],\r\n \"b_delta\": intervals_raw[..., 1],\r\n \"refl_prob\": torch.sigmoid(intervals_raw[..., 2]),\r\n \"gate\": torch.sigmoid(self.gate_head(h))}\r\n\r\ndef sparsemax(input_t: torch.Tensor, dim: int = -1) -> torch.Tensor:\r\n input_shifted = input_t - input_t.max(dim=dim, keepdim=True)[0]\r\n z_sorted, _ = torch.sort(input_shifted, descending=True, dim=dim)\r\n zs_cumsum = z_sorted.cumsum(dim)\r\n k_array = torch.arange(1, input_t.size(dim) + 1, device=input_t.device, dtype=input_t.dtype)\r\n k_cond = 1 + k_array * z_sorted > zs_cumsum\r\n k = k_cond.sum(dim=dim, keepdim=True)\r\n zs_threshold = (zs_cumsum.gather(dim, k - 1) - 1) / k.type(input_t.dtype)\r\n return torch.clamp(input_shifted - zs_threshold, min=0.0)\r\n\r\nclass Selector(nn.Module):\r\n def __init__(self, in_dim: int, out_dim: int, hidden: int = 256, use_sparsemax: bool = False, temp_init: float = GUMBEL_TEMP_INIT, temp_min: float = GUMBEL_TEMP_MIN, anneal: float = GUMBEL_ANNEAL):\r\n super().__init__()\r\n self.net = nn.Sequential(nn.Linear(in_dim, hidden), nn.ReLU(), nn.Linear(hidden, out_dim))\r\n self.use_sparsemax = use_sparsemax\r\n self.register_buffer(\"temp\", torch.tensor(temp_init))\r\n self.temp_min = temp_min\r\n self.anneal = anneal\r\n\r\n def forward(self, z: torch.Tensor, hard: bool = False) -> torch.Tensor:\r\n logits = self.net(z)\r\n if self.use_sparsemax:\r\n return sparsemax(logits, dim=-1)\r\n u = torch.rand_like(logits)\r\n g = -torch.log(-torch.log(u + 1e-20) + 1e-20)\r\n y = torch.softmax((logits + g) / self.temp, dim=-1)\r\n if hard:\r\n y_hard = torch.zeros_like(y).scatter_(-1, y.argmax(dim=-1, keepdim=True), 1.0)\r\n y = (y_hard - y).detach() + y\r\n return y\r\n\r\n def step_anneal(self):\r\n self.temp = torch.clamp(self.temp * self.anneal, min=self.temp_min)\r\n\r\nclass Combinator(nn.Module):\r\n def __init__(self, leaf_count: int, branching: int = COMBINATOR_BRANCHING, depth: int = COMBINATOR_DEPTH):\r\n super().__init__()\r\n self.leaf_count = leaf_count\r\n levels = []\r\n current = leaf_count\r\n for d in range(depth):\r\n parents = math.ceil(current / branching)\r\n P = torch.zeros(parents, current, dtype=torch.float32)\r\n for p in range(parents):\r\n start = p * branching\r\n end = min(start + branching, current)\r\n if end > start:\r\n P[p, start:end] = 1.0 / (end - start)\r\n levels.append(P); current = parents\r\n self.levels = nn.ParameterList([nn.Parameter(l, requires_grad=False) for l in levels])\r\n self.level_gates = nn.ParameterList([nn.Parameter(torch.ones(1, l.shape[0])) for l in levels])\r\n\r\n def forward(self, leaf_probs: torch.Tensor) -> Tuple[torch.Tensor, List[torch.Tensor]]:\r\n cur = leaf_probs\r\n trans_mats = []\r\n for d, P in enumerate(self.levels):\r\n parent_probs = torch.matmul(cur, P.t())\r\n parent_probs = parent_probs * torch.sigmoid(self.level_gates[d])\r\n trans_mats.append(P)\r\n cur = parent_probs\r\n return cur, trans_mats\r\n\r\ndef batched_svd_lowrank(mat: torch.Tensor, rank: int) -> torch.Tensor:\r\n if mat.ndim == 2:\r\n U, S, Vt = torch.linalg.svd(mat, full_matrices=False)\r\n k = min(rank, S.shape[-1])\r\n return (U[:, :k] * S[:k]) @ Vt[:k, :]\r\n elif mat.ndim == 3:\r\n U, S, Vt = torch.linalg.svd(mat, full_matrices=False)\r\n k = min(rank, S.shape[-1])\r\n return (U[..., :k] * S[..., None, :k]) @ Vt[..., :k, :]\r\n else:\r\n raise ValueError(\"Unsupported tensor dimensional properties for SVD.\")\r\n\r\nclass KANWeightGenerator(nn.Module):\r\n def __init__(self, spline: BSplineField, base_intervals: List[Tuple[float, float]], reflect_flags: List[bool],\r\n selector: Optional[Selector] = None, combinator: Optional[Combinator] = None, top_count: Optional[int] = None,\r\n svd_rank: int = SVD_RANK_BUDGET, compress_forward: bool = SVD_COMPRESS_FORWARD, compress_grads: bool = SVD_COMPRESS_GRADS):\r\n super().__init__()\r\n self.spline = spline\r\n self.register_buffer(\"base_a\", torch.tensor([iv[0] for iv in base_intervals], dtype=torch.float32))\r\n self.register_buffer(\"base_b\", torch.tensor([iv[1] for iv in base_intervals], dtype=torch.float32))\r\n self.reflect_flags = reflect_flags\r\n self.selector = selector\r\n self.combinator = combinator\r\n self.svd_rank = svd_rank\r\n self.compress_forward = compress_forward\r\n self.compress_grads = compress_grads\r\n grid_count = int(np.prod(spline.grid_shape()))\r\n if self.selector is not None and self.combinator is not None and top_count is not None:\r\n self.comb_to_leaf = nn.Linear(top_count, grid_count)\r\n self.proj = nn.Linear(grid_count * spline.ctrl_point_dim, spline.ctrl_point_dim)\r\n self._grad_hooks_installed = False\r\n\r\n def install_grad_hooks(self):\r\n if self._grad_hooks_installed or not self.compress_grads:\r\n return\r\n for p in self.spline.parameters():\r\n if p.requires_grad:\r\n p.register_hook(partial(self._grad_compress_hook, rank=self.svd_rank))\r\n self._grad_hooks_installed = True\r\n\r\n @staticmethod\r\n def _grad_compress_hook(grad: torch.Tensor, rank: int):\r\n if grad.ndim == 2:\r\n return batched_svd_lowrank(grad, rank)\r\n return grad\r\n\r\n def forward(self, coords: torch.Tensor, meta_out: Dict, context_z: Optional[torch.Tensor] = None) -> torch.Tensor:\r\n a = self.base_a + meta_out[\"a_delta\"]\r\n b = self.base_b + meta_out[\"b_delta\"]\r\n avg_rp = torch.mean(meta_out[\"refl_prob\"], dim=0) if meta_out[\"refl_prob\"].ndim > 1 else meta_out[\"refl_prob\"]\r\n resolved_flags = [(prob > 0.5).item() for prob in avg_rp]\r\n coords_ref = reflect_coords(coords, a, b, resolved_flags)\r\n base_w = self.spline(coords_ref)\r\n deltas = meta_out[\"deltas\"].reshape(base_w.shape[0], -1)\r\n if self.selector is not None and context_z is not None and hasattr(self, 'comb_to_leaf'):\r\n sel_probs = self.selector(context_z)\r\n top_probs, _ = self.combinator(sel_probs)\r\n leaf_mod = torch.sigmoid(self.comb_to_leaf(top_probs))\r\n leaf_mod_exp = leaf_mod.unsqueeze(-1).expand(-1, -1, self.spline.ctrl_point_dim).reshape(deltas.shape)\r\n deltas = deltas * leaf_mod_exp\r\n if self.compress_forward:\r\n try:\r\n deltas = batched_svd_lowrank(deltas, self.svd_rank)\r\n except Exception:\r\n pass\r\n delta_w = self.proj(deltas)\r\n w = base_w + delta_w\r\n gate = meta_out[\"gate\"]\r\n w = w * (gate if gate.ndim == 2 else gate.mean(dim=0, keepdim=True))\r\n self.install_grad_hooks()\r\n return w\r\n\r\ndef save_kanbs(path: str, spline: BSplineField, json_sidecar: Optional[Dict] = None):\r\n p = Path(path)\r\n json_path = p.with_suffix(p.suffix + \".json\")\r\n with open(p, \"wb\") as f:\r\n f.write(b'KANB')\r\n f.write(struct.pack(\"\r\n\r\nInstall:\r\n\r\n```bash\r\nbrew install gowtham0992/link/link\r\nlnk demo\r\nlnk serve link-demo\r\n```\r\n\r\nMCP package:\r\n```\r\npython3 -m pip install --upgrade link-mcp\r\n```\r\n\r\nLinks:\r\nGitHub: https://github.com/gowtham0992/link\r\nDocs: https://gowtham0992.github.io/link/\r\nMCP Registry: https://registry.modelcontextprotocol.io/?q=io.github.gowtham0992%2Flink\r\nPyPI: https://pypi.org/project/link-mcp/"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199277",
"id": 6199277,
"node_id": "GC_lADODWvfF9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBel-0",
"user": {
"login": "lioragronov2203-stack",
"id": 225173271,
"node_id": "U_kgDODWvfFw",
"avatar_url": "https://avatars.githubusercontent.com/u/225173271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lioragronov2203-stack",
"html_url": "https://github.com/lioragronov2203-stack",
"followers_url": "https://api.github.com/users/lioragronov2203-stack/followers",
"following_url": "https://api.github.com/users/lioragronov2203-stack/following{/other_user}",
"gists_url": "https://api.github.com/users/lioragronov2203-stack/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lioragronov2203-stack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lioragronov2203-stack/subscriptions",
"organizations_url": "https://api.github.com/users/lioragronov2203-stack/orgs",
"repos_url": "https://api.github.com/users/lioragronov2203-stack/repos",
"events_url": "https://api.github.com/users/lioragronov2203-stack/events{/privacy}",
"received_events_url": "https://api.github.com/users/lioragronov2203-stack/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T17:13:03Z",
"updated_at": "2026-06-14T17:13:03Z",
"body": "> **Architecture Discussion: Overcoming the \"Flat Markdown Mutation Problem\" in LLM-OS environments (Flat Files vs Outliner AST)**\r\n> \r\n> LOGSEQ (block granularity) vs Obsidian (page granularity) and my Matryca Plumber\r\n> \r\n> Hi Andrej / everyone,\r\n> \r\n> I’ve been heavily inspired by your concepts around the LLM OS and using flat Markdown as the filesystem for AI agents. I’ve been building autonomous loops using this exact paradigm, but I hit a massive architectural wall when using standard editors (like Obsidian) as the frontend.\r\n> \r\n> The Problem: The \"Flat File Mutation\" Danger When an AI agent tries to autonomously inject properties, update status tags, or surgically edit a document in the background while the user is typing, flat Markdown fails.\r\n> \r\n> Standard LLMs struggle to parse the exact line numbers or preserve complex metadata in flat .md files without corrupting the surrounding text or triggering race conditions (causing data loss).\r\n> \r\n> The Workaround/Experiment I realized that for an LLM to truly act as a safe background daemon, the filesystem needs an inherently rigid structure. I pivoted the experiment to LOGSEQ (which stores data as a strict Block-based Outliner AST, with UUIDs per block) and implemented an Optimistic Concurrency Control (OCC) locking mechanism via mmap.\r\n> \r\n> By doing this, the LLM doesn't have to guess where to inject data. It targets the block UUID.\r\n> \r\n> 1. The human types on the frontend.\r\n> 2. The AI reads the AST, computes semantic tags, and injects properties in the background.\r\n> 3. Zero file corruption.\r\n> \r\n> I built an open-source Python daemon to prove this concept (matryca-plumber), fully protecting the AI-to-File boundary with strict token limits and JSON recovery. It has also an MCP and CLI to dialogue with notes and write directly to .MD files.\r\n> \r\n> https://github.com/MarcoPorcellato/matryca-plumber\r\n> \r\n> I wanted to share this architectural finding here because as we build out the \"LLM Wiki\" or \"LLM OS\" concepts, shifting the storage paradigm from Flat Text AST to Block Outliner AST seems to be the only way to grant LLMs safe, concurrent write-access to human notes.\r\n> \r\n> Would love to hear your thoughts on concurrency and background mutations in your Obsidian setups!\r\n\r\nיוצר עדכון זה אני יוצר אפלקציה ומפתח רשי בעל הזכיות \r\n\r\nושותף 30 אחוז בכל הסטרטאפ שניבנה אדם שלו עבר שנה מאז שאו יתחיל לעבוד פטור מי תשלום על שירותים שאני עושה בשביל כולם מוזמנים לפנות אלי ואני רוצה \r\nשתבינו אני צריך צוות וחברה רשמית אתם צריכים את זה שרות הלקוחות היה זמין 24/7-וחברה שתפעיל את כל \r\nהניהול של כל אינטרנט אלחוטי יוצר גוגל ואת הדף הראשי של מיקרוסופת אני צריך מי כספים מי צד שלישי שיש לי כסף מוחזק אצלו אז לדבר איתי איך מתקדמים "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199370",
"id": 6199370,
"node_id": "GC_lADOD6PVtNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBemEo",
"user": {
"login": "studebaker8",
"id": 262395316,
"node_id": "U_kgDOD6PVtA",
"avatar_url": "https://avatars.githubusercontent.com/u/262395316?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/studebaker8",
"html_url": "https://github.com/studebaker8",
"followers_url": "https://api.github.com/users/studebaker8/followers",
"following_url": "https://api.github.com/users/studebaker8/following{/other_user}",
"gists_url": "https://api.github.com/users/studebaker8/gists{/gist_id}",
"starred_url": "https://api.github.com/users/studebaker8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/studebaker8/subscriptions",
"organizations_url": "https://api.github.com/users/studebaker8/orgs",
"repos_url": "https://api.github.com/users/studebaker8/repos",
"events_url": "https://api.github.com/users/studebaker8/events{/privacy}",
"received_events_url": "https://api.github.com/users/studebaker8/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T20:03:30Z",
"updated_at": "2026-06-14T20:03:30Z",
"body": "Is it common practice outside the US to jump on other people's bandwagons in attempt to ride their coattails and advertise their \"products\" in the process? \r\n\r\nThis is an insult to Karpathy's work."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199385",
"id": 6199385,
"node_id": "GC_lADOALUbLNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBemFk",
"user": {
"login": "theafh",
"id": 11868972,
"node_id": "MDQ6VXNlcjExODY4OTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11868972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theafh",
"html_url": "https://github.com/theafh",
"followers_url": "https://api.github.com/users/theafh/followers",
"following_url": "https://api.github.com/users/theafh/following{/other_user}",
"gists_url": "https://api.github.com/users/theafh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theafh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theafh/subscriptions",
"organizations_url": "https://api.github.com/users/theafh/orgs",
"repos_url": "https://api.github.com/users/theafh/repos",
"events_url": "https://api.github.com/users/theafh/events{/privacy}",
"received_events_url": "https://api.github.com/users/theafh/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T20:37:11Z",
"updated_at": "2026-06-14T20:37:11Z",
"body": "This idea was really inspiring! The “LLM-maintained wiki as a compiled knowledge layer” framing helped me make something I had been circling around more concrete.\r\n\r\nI built a repo-local knowledge base that generalizes the pattern for projects: **a `wiki` skill family** for durable, focused knowledge, and a **`task` skill family** for repo-native work tracking.\r\n\r\nThe wiki side is meant to feel like a lightweight Confluence that lives with the code: raw sources stay separate, the agent maintains structured markdown pages, `index.md` and `log.md` make it discoverable, and schema rules keep future agents from treating it as just another notes folder.\r\n\r\nThe task side applies the same idea to execution state: markdown task files live alongside the repo, with status, provenance, implementation notes, audit state, and archive behavior. Roughly: Jira/Trello-style project memory, but plain text, git-backed, and directly usable by agents.\r\n\r\nIt is still intentionally simple: Make, shell, markdown, git. No database, no hosted service, no third-party software, no fluff! Just focused skills for every part of the workflow life cycle. The main goal is to make project knowledge and project work durable enough that a new agent session can rediscover the context without having to replay it to the human.\r\n\r\nRepo: [https://github.com/theafh/ai-modules](https://github.com/theafh/ai-modules)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6199498",
"id": 6199498,
"node_id": "GC_lADOASvraNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBemMo",
"user": {
"login": "kytmanov",
"id": 19655528,
"node_id": "MDQ6VXNlcjE5NjU1NTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/19655528?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kytmanov",
"html_url": "https://github.com/kytmanov",
"followers_url": "https://api.github.com/users/kytmanov/followers",
"following_url": "https://api.github.com/users/kytmanov/following{/other_user}",
"gists_url": "https://api.github.com/users/kytmanov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kytmanov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kytmanov/subscriptions",
"organizations_url": "https://api.github.com/users/kytmanov/orgs",
"repos_url": "https://api.github.com/users/kytmanov/repos",
"events_url": "https://api.github.com/users/kytmanov/events{/privacy}",
"received_events_url": "https://api.github.com/users/kytmanov/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-14T23:28:10Z",
"updated_at": "2026-06-14T23:28:10Z",
"body": "# Synto v0.6.0\r\n\r\n**Synto v0.6.0 is out.** \r\n[https://github.com/kytmanov/synto](https://github.com/kytmanov/synto)\r\n\r\n## Main addition: Real concept identity + curation tools\r\n\r\nConcepts now have a stable `entity_id` under the hood, separate from the display name. Homonyms (same word, different domains) stop colliding or getting mangled. Ingest order no longer decides whether something becomes its own page - a later note that promotes a weak alias just surfaces a merge candidate in `synto doctor` / `synto concept inspect` instead of silently creating duplicates.\r\n\r\n### New commands to steer the graph the LLM is building\r\n\r\n- `synto concept merge LOSER WINNER` - moves sources + edges, retires the loser, absorbs its label as a blessed alias\r\n- `synto concept split NAME --sense ...` - carves it into multiple senses + leaves a disambiguation stub\r\n- `synto concept unmerge`, `rename`, `inspect`, `keep`\r\n\r\n## Also new\r\n\r\n`synto serve --transport streamable-http` so remote machines or agents on your LAN can hit the MCP server (no built-in auth - run on a trusted network or behind a proxy; DNS rebinding protection is on; use `--allowed-host` for anything a reverse proxy forwards).\r\n\r\n## Same shape as before\r\n\r\n- works with local LLMs\r\n- great with Ollama and LM Studio\r\n- plain Markdown\r\n- Obsidian-friendly\r\n- no vector DB\r\n- no cloud required\r\n- multi-language\r\n\r\n**Star it** if you want to support local-first AI tools. \r\n**Fork it** if you want to build on it."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6202111",
"id": 6202111,
"node_id": "GC_lADOCJO6gdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeov8",
"user": {
"login": "SinghAbhinav04",
"id": 143899265,
"node_id": "U_kgDOCJO6gQ",
"avatar_url": "https://avatars.githubusercontent.com/u/143899265?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SinghAbhinav04",
"html_url": "https://github.com/SinghAbhinav04",
"followers_url": "https://api.github.com/users/SinghAbhinav04/followers",
"following_url": "https://api.github.com/users/SinghAbhinav04/following{/other_user}",
"gists_url": "https://api.github.com/users/SinghAbhinav04/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SinghAbhinav04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SinghAbhinav04/subscriptions",
"organizations_url": "https://api.github.com/users/SinghAbhinav04/orgs",
"repos_url": "https://api.github.com/users/SinghAbhinav04/repos",
"events_url": "https://api.github.com/users/SinghAbhinav04/events{/privacy}",
"received_events_url": "https://api.github.com/users/SinghAbhinav04/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-16T14:02:36Z",
"updated_at": "2026-06-16T14:02:36Z",
"body": "> Love this LLM-Wiki idea? We built a full open-source system on it → AutoSci\r\n> \r\n> Come and enjoy: https://github.com/skyllwt/AutoSci\r\n> \r\n>  \r\n> Karpathy's pattern (immutable raw/ → an LLM-compiled wiki/ → a CLAUDE.md schema) is the exact foundation of AutoSci — an agent that turns the wiki into a research memory and then does autonomous science on top of it. All on Claude Code:\r\n> \r\n> * 📚 Ingest papers into a cross-linked wiki of concept/method/idea pages ([[wikilinks]], contradiction edges — the LLM-Wiki, fully realized)\r\n> * 💡 Ideate → experiment → write: it reads its own memory to generate ideas, design + run experiments, draft the paper, and handle rebuttals\r\n> * 🧬 Self-evolving memory: between projects it consolidates, re-weights, and re-links the wiki (a \"sleep\" phase)\r\n> * 🕸️ Multi-agent DAGs for the hard reasoning steps\r\n> \r\n> We've already used it to write 3 papers end-to-end. Fully open (MIT).\r\n> \r\n> ⭐ If this is where you want LLM-Wikis to go, a star genuinely helps us! and we welcome issues/PRs/Contributors 👉 https://github.com/skyllwt/AutoSci 📄 Paper: https://arxiv.org/abs/2605.31468\r\n> \r\n> Demo: 【北大做了一个会自我进化的科研 Agent:AutoSci】 https://www.bilibili.com/video/BV19gVg6pEk6/?share_source=copy_web&vd_source=338de971cb27f42aaaf5d8bfdeed04b3\r\n> \r\n>
\r\n> Karpathy's pattern (immutable raw/ → an LLM-compiled wiki/ → a CLAUDE.md schema) is the exact foundation of AutoSci — an agent that turns the wiki into a research memory and then does autonomous science on top of it. All on Claude Code:\r\n> \r\n> * 📚 Ingest papers into a cross-linked wiki of concept/method/idea pages ([[wikilinks]], contradiction edges — the LLM-Wiki, fully realized)\r\n> * 💡 Ideate → experiment → write: it reads its own memory to generate ideas, design + run experiments, draft the paper, and handle rebuttals\r\n> * 🧬 Self-evolving memory: between projects it consolidates, re-weights, and re-links the wiki (a \"sleep\" phase)\r\n> * 🕸️ Multi-agent DAGs for the hard reasoning steps\r\n> \r\n> We've already used it to write 3 papers end-to-end. Fully open (MIT).\r\n> \r\n> ⭐ If this is where you want LLM-Wikis to go, a star genuinely helps us! and we welcome issues/PRs/Contributors 👉 https://github.com/skyllwt/AutoSci 📄 Paper: https://arxiv.org/abs/2605.31468\r\n> \r\n> Demo: 【北大做了一个会自我进化的科研 Agent:AutoSci】 https://www.bilibili.com/video/BV19gVg6pEk6/?share_source=copy_web&vd_source=338de971cb27f42aaaf5d8bfdeed04b3\r\n> \r\n>  \r\n> RED: 北大做了一个“越做科研越聪明”的AI科学家 北大团队... http://xhslink.com/o/2clEkgugEPw 复制后打开【小红书】查看笔记!\r\n\r\nI dont think we need a whole app for something which is done via model itself by a single prompt this is simply over engineering and wastage"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6202181",
"id": 6202181,
"node_id": "GC_lADOADdOmNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeo0U",
"user": {
"login": "psinetron",
"id": 3624600,
"node_id": "MDQ6VXNlcjM2MjQ2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3624600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/psinetron",
"html_url": "https://github.com/psinetron",
"followers_url": "https://api.github.com/users/psinetron/followers",
"following_url": "https://api.github.com/users/psinetron/following{/other_user}",
"gists_url": "https://api.github.com/users/psinetron/gists{/gist_id}",
"starred_url": "https://api.github.com/users/psinetron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/psinetron/subscriptions",
"organizations_url": "https://api.github.com/users/psinetron/orgs",
"repos_url": "https://api.github.com/users/psinetron/repos",
"events_url": "https://api.github.com/users/psinetron/events{/privacy}",
"received_events_url": "https://api.github.com/users/psinetron/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-16T14:51:17Z",
"updated_at": "2026-06-16T14:51:17Z",
"body": "Hi Andrej, thank you for the brilliant write-up! This exact concept of flat-file agentic memory completely changes how we interact with coding assistants. \r\n\r\nInspired heavily by your thoughts here, I recently built and open-sourced **EchoesVault** — a persistent memory plugin for OpenCode that implements this pattern autonomously. \r\n\r\nWe took the \"memory-as-markdown\" idea and added a few strict engineering guardrails:\r\n* **Event-Driven Logging:** Instead of just dumping context at the end of the day, the AI uses background skills to autonomously log mid-session context switches and architectural decisions.\r\n* **Google OKF Compliance:** The memory structure enforces Google's Open Knowledge Format, ensuring the AI's memory is interoperable with standard parsers.\r\n* **Obsidian Native:** The vault renders perfectly in Obsidian, allowing developers to visually explore the AI's architectural graph.\r\n* **Surgical Index Updates:** To prevent token inflation, the agent uses array-based incremental updates for the `index.md` rather than rewriting the whole file.\r\n\r\nThank you for sparking the idea! If anyone in the thread is building similar agentic workflows or using OpenCode, I'd love your feedback on the implementation: https://github.com/psinetron/echoes-vault-opencode"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6202957",
"id": 6202957,
"node_id": "GC_lADOA7Wy4doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBepk0",
"user": {
"login": "deepak-bhardwaj-ps",
"id": 62239457,
"node_id": "MDQ6VXNlcjYyMjM5NDU3",
"avatar_url": "https://avatars.githubusercontent.com/u/62239457?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/deepak-bhardwaj-ps",
"html_url": "https://github.com/deepak-bhardwaj-ps",
"followers_url": "https://api.github.com/users/deepak-bhardwaj-ps/followers",
"following_url": "https://api.github.com/users/deepak-bhardwaj-ps/following{/other_user}",
"gists_url": "https://api.github.com/users/deepak-bhardwaj-ps/gists{/gist_id}",
"starred_url": "https://api.github.com/users/deepak-bhardwaj-ps/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/deepak-bhardwaj-ps/subscriptions",
"organizations_url": "https://api.github.com/users/deepak-bhardwaj-ps/orgs",
"repos_url": "https://api.github.com/users/deepak-bhardwaj-ps/repos",
"events_url": "https://api.github.com/users/deepak-bhardwaj-ps/events{/privacy}",
"received_events_url": "https://api.github.com/users/deepak-bhardwaj-ps/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-17T02:57:09Z",
"updated_at": "2026-06-17T02:57:09Z",
"body": "One pattern I've noticed across many of the projects in this thread is that they focus heavily on *what* the agent remembers.\r\n\r\nSmriti-MCP started from a slightly different question:\r\n\r\n**How does the agent remember consistently across sessions, tools, models, and runtimes?**\r\n\r\nInstead of treating memory as a feature inside a specific agent framework, Smriti exposes memory as an MCP-native service that any compatible agent can use.\r\n\r\nA few design principles that shaped it:\r\n\r\n* Memory is externalised from the agent lifecycle.\r\n* Context should survive model changes.\r\n* Knowledge should be reusable across multiple agents.\r\n* Memory must be queryable, governed, and inspectable.\r\n* The memory layer should remain useful even when the orchestration layer changes.\r\n\r\nWhat interests me most is that we're gradually moving from \"prompt engineering\" toward **memory architecture**.\r\n\r\nThe next generation of agent systems will not be differentiated by model choice alone.\r\n\r\nThey will be differentiated by:\r\n\r\n* what they know,\r\n* how they remember,\r\n* how they evolve knowledge over time,\r\n* and how reliably they can retrieve the right context at the right moment.\r\n\r\nSmriti-MCP is my attempt to explore that direction as a portable memory layer for agent ecosystems.\r\n\r\nProject:\r\n\r\n[Smriti MCP](https://github.com/deepak-bhardwaj-ps/smriti-mcp)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6203805",
"id": 6203805,
"node_id": "GC_lADOBGxW3toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeqZ0",
"user": {
"login": "Motya-cobol",
"id": 74208990,
"node_id": "MDQ6VXNlcjc0MjA4OTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/74208990?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Motya-cobol",
"html_url": "https://github.com/Motya-cobol",
"followers_url": "https://api.github.com/users/Motya-cobol/followers",
"following_url": "https://api.github.com/users/Motya-cobol/following{/other_user}",
"gists_url": "https://api.github.com/users/Motya-cobol/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Motya-cobol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Motya-cobol/subscriptions",
"organizations_url": "https://api.github.com/users/Motya-cobol/orgs",
"repos_url": "https://api.github.com/users/Motya-cobol/repos",
"events_url": "https://api.github.com/users/Motya-cobol/events{/privacy}",
"received_events_url": "https://api.github.com/users/Motya-cobol/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-17T15:11:16Z",
"updated_at": "2026-06-17T15:11:16Z",
"body": "Hello Andrei and the community.\r\nI’m building a Markdown/Obsidian-style knowledge wiki for teaching a health informatics course, using Codex to help ingest sources, maintain links, and later query the wiki for presentations and curriculum design.\r\n\r\nI ran into a token-efficiency problem that may be interesting: the token burn was not mainly from reasoning or output, but from repeated context loading. Codex kept re-reading files like AGENTS.md, wiki/index.md, manifests, handoffs, raw sources, and tool scripts across short sessions. Even small source-ingest tasks became expensive.\r\n\r\nI’ve started moving toward a split workflow: deterministic Python scripts handle source intake, route indexes, validation, and compact handoffs; Codex is reserved for higher-value graph curation, synthesis, and judgment. I’m also using compact routing files instead of asking the model to scan the whole wiki.\r\n\r\nI would be grateful for any advice on the right architecture for this kind of “wiki as working memory” setup. Specifically, how would you structure retrieval, summaries, graph edges, and agent instructions so Codex can reason over a rich knowledge base without repeatedly consuming the entire context?\r\n\r\nEven a few pointers or design principles would be very helpful."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6204203",
"id": 6204203,
"node_id": "GC_lADOAPIx79oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeqys",
"user": {
"login": "yazanabuashour",
"id": 15872495,
"node_id": "MDQ6VXNlcjE1ODcyNDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/15872495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yazanabuashour",
"html_url": "https://github.com/yazanabuashour",
"followers_url": "https://api.github.com/users/yazanabuashour/followers",
"following_url": "https://api.github.com/users/yazanabuashour/following{/other_user}",
"gists_url": "https://api.github.com/users/yazanabuashour/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yazanabuashour/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yazanabuashour/subscriptions",
"organizations_url": "https://api.github.com/users/yazanabuashour/orgs",
"repos_url": "https://api.github.com/users/yazanabuashour/repos",
"events_url": "https://api.github.com/users/yazanabuashour/events{/privacy}",
"received_events_url": "https://api.github.com/users/yazanabuashour/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-17T23:23:46Z",
"updated_at": "2026-06-17T23:23:46Z",
"body": "One thing I think the LLM-wiki pattern needs as it grows past toy scale is a\nhard boundary between:\n\n1. canonical human-readable Markdown\n2. derived recall/projection state\n3. agent write authority\n\nThe failure mode I kept running into was not \"can the agent write a wiki page?\"\nIt was:\n\n- stale synthesis pages that still looked authoritative\n- duplicate pages for the same concept\n- retrieval results with no stable citation contract\n- agents silently turning generated summaries into truth\n\nI have been building OpenClerk around that boundary:\n\n- Markdown remains canonical\n- SQLite/FTS/graph state is derived and auditable\n- every retrieval result carries `doc_id`, `chunk_id`, and citation path\n- duplicate/stale/freshness checks are explicit reports\n- writes go through planned/approved runner actions\n- semantic search/OCR are optional modules, not hidden defaults\n\nRepo: \n\nI would especially love criticism on the runner boundary: should freshness and\nduplicate signals be advisory reports, hard write gates, or retrieval-time\nranking inputs?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6204250",
"id": 6204250,
"node_id": "GC_lADOA7Wy4doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeq1o",
"user": {
"login": "deepak-bhardwaj-ps",
"id": 62239457,
"node_id": "MDQ6VXNlcjYyMjM5NDU3",
"avatar_url": "https://avatars.githubusercontent.com/u/62239457?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/deepak-bhardwaj-ps",
"html_url": "https://github.com/deepak-bhardwaj-ps",
"followers_url": "https://api.github.com/users/deepak-bhardwaj-ps/followers",
"following_url": "https://api.github.com/users/deepak-bhardwaj-ps/following{/other_user}",
"gists_url": "https://api.github.com/users/deepak-bhardwaj-ps/gists{/gist_id}",
"starred_url": "https://api.github.com/users/deepak-bhardwaj-ps/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/deepak-bhardwaj-ps/subscriptions",
"organizations_url": "https://api.github.com/users/deepak-bhardwaj-ps/orgs",
"repos_url": "https://api.github.com/users/deepak-bhardwaj-ps/repos",
"events_url": "https://api.github.com/users/deepak-bhardwaj-ps/events{/privacy}",
"received_events_url": "https://api.github.com/users/deepak-bhardwaj-ps/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-18T00:35:25Z",
"updated_at": "2026-06-18T00:35:25Z",
"body": "> Hello Andrei and the community. I’m building a Markdown/Obsidian-style knowledge wiki for teaching a health informatics course, using Codex to help ingest sources, maintain links, and later query the wiki for presentations and curriculum design.\r\n> \r\n> I ran into a token-efficiency problem that may be interesting: the token burn was not mainly from reasoning or output, but from repeated context loading. Codex kept re-reading files like AGENTS.md, wiki/index.md, manifests, handoffs, raw sources, and tool scripts across short sessions. Even small source-ingest tasks became expensive.\r\n> \r\n> I’ve started moving toward a split workflow: deterministic Python scripts handle source intake, route indexes, validation, and compact handoffs; Codex is reserved for higher-value graph curation, synthesis, and judgment. I’m also using compact routing files instead of asking the model to scan the whole wiki.\r\n> \r\n> I would be grateful for any advice on the right architecture for this kind of “wiki as working memory” setup. Specifically, how would you structure retrieval, summaries, graph edges, and agent instructions so Codex can reason over a rich knowledge base without repeatedly consuming the entire context?\r\n> \r\n> Even a few pointers or design principles would be very helpful.\r\n\r\nYou can try Smriti MCP I dhared above on the thread. Out of the box agents struggle to use wiki efficiently. I have built it for that purpose and you can configure same MCP with multiple agents to collaborate and share wiki. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6205516",
"id": 6205516,
"node_id": "GC_lADOBmn5pNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBesEw",
"user": {
"login": "LARIkoz",
"id": 107608484,
"node_id": "U_kgDOBmn5pA",
"avatar_url": "https://avatars.githubusercontent.com/u/107608484?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LARIkoz",
"html_url": "https://github.com/LARIkoz",
"followers_url": "https://api.github.com/users/LARIkoz/followers",
"following_url": "https://api.github.com/users/LARIkoz/following{/other_user}",
"gists_url": "https://api.github.com/users/LARIkoz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LARIkoz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LARIkoz/subscriptions",
"organizations_url": "https://api.github.com/users/LARIkoz/orgs",
"repos_url": "https://api.github.com/users/LARIkoz/repos",
"events_url": "https://api.github.com/users/LARIkoz/events{/privacy}",
"received_events_url": "https://api.github.com/users/LARIkoz/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-18T08:10:55Z",
"updated_at": "2026-06-18T08:10:55Z",
"body": "Implemented this end-to-end as **Eidetic** (memory for Claude Code): https://github.com/LARIkoz/eidetic — compounding pages (a good answer files back; a re-touch appends to a History/Update section instead of duplicating), an explicit schema as the maintenance contract, typed pages, and an op-log.\n\nTwo additions from running it on an ~1.8k-file / 16k-chunk store: (1) **auto-extraction** at session end so the wiki grows without manual ingest, and (2) **drift detection** — your \"note where new data contradicts old\", automated as stale-age / broken-link / confidence-escalation penalties; past ~day 60 the real failure mode is confident-but-stale memory making the agent _worse_, not better. The \"LLMs don't get bored\" framing nails the thesis — thanks for writing it up.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6206100",
"id": 6206100,
"node_id": "GC_lADOBkd7_doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBespQ",
"user": {
"login": "pumblus",
"id": 105348093,
"node_id": "U_kgDOBkd7_Q",
"avatar_url": "https://avatars.githubusercontent.com/u/105348093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pumblus",
"html_url": "https://github.com/pumblus",
"followers_url": "https://api.github.com/users/pumblus/followers",
"following_url": "https://api.github.com/users/pumblus/following{/other_user}",
"gists_url": "https://api.github.com/users/pumblus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pumblus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pumblus/subscriptions",
"organizations_url": "https://api.github.com/users/pumblus/orgs",
"repos_url": "https://api.github.com/users/pumblus/repos",
"events_url": "https://api.github.com/users/pumblus/events{/privacy}",
"received_events_url": "https://api.github.com/users/pumblus/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-18T13:26:05Z",
"updated_at": "2026-06-18T13:26:05Z",
"body": "Thank you Andrej for this write-up. I ended up exploring one specific piece of the pattern: how to make an LLM Wiki portable and agent-maintainable without turning it into a new app.\r\n\r\nI built OKF Harness around that idea: https://github.com/pumblus/okf-harness\r\n\r\nIt uses local folders, immutable raw sources, OKF-compatible markdown, an `okfh --json` CLI for Claude Code or Codex, bounded reads, validation, citations, and a local graph report. The goal is to keep the wiki as ordinary files while giving agents a stable contract for maintaining it.\r\n\r\nWould be interested to hear how others are handling portability, provenance, and validation across agent clients."
}
]
}
\r\n> RED: 北大做了一个“越做科研越聪明”的AI科学家 北大团队... http://xhslink.com/o/2clEkgugEPw 复制后打开【小红书】查看笔记!\r\n\r\nI dont think we need a whole app for something which is done via model itself by a single prompt this is simply over engineering and wastage"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6202181",
"id": 6202181,
"node_id": "GC_lADOADdOmNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeo0U",
"user": {
"login": "psinetron",
"id": 3624600,
"node_id": "MDQ6VXNlcjM2MjQ2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3624600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/psinetron",
"html_url": "https://github.com/psinetron",
"followers_url": "https://api.github.com/users/psinetron/followers",
"following_url": "https://api.github.com/users/psinetron/following{/other_user}",
"gists_url": "https://api.github.com/users/psinetron/gists{/gist_id}",
"starred_url": "https://api.github.com/users/psinetron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/psinetron/subscriptions",
"organizations_url": "https://api.github.com/users/psinetron/orgs",
"repos_url": "https://api.github.com/users/psinetron/repos",
"events_url": "https://api.github.com/users/psinetron/events{/privacy}",
"received_events_url": "https://api.github.com/users/psinetron/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-16T14:51:17Z",
"updated_at": "2026-06-16T14:51:17Z",
"body": "Hi Andrej, thank you for the brilliant write-up! This exact concept of flat-file agentic memory completely changes how we interact with coding assistants. \r\n\r\nInspired heavily by your thoughts here, I recently built and open-sourced **EchoesVault** — a persistent memory plugin for OpenCode that implements this pattern autonomously. \r\n\r\nWe took the \"memory-as-markdown\" idea and added a few strict engineering guardrails:\r\n* **Event-Driven Logging:** Instead of just dumping context at the end of the day, the AI uses background skills to autonomously log mid-session context switches and architectural decisions.\r\n* **Google OKF Compliance:** The memory structure enforces Google's Open Knowledge Format, ensuring the AI's memory is interoperable with standard parsers.\r\n* **Obsidian Native:** The vault renders perfectly in Obsidian, allowing developers to visually explore the AI's architectural graph.\r\n* **Surgical Index Updates:** To prevent token inflation, the agent uses array-based incremental updates for the `index.md` rather than rewriting the whole file.\r\n\r\nThank you for sparking the idea! If anyone in the thread is building similar agentic workflows or using OpenCode, I'd love your feedback on the implementation: https://github.com/psinetron/echoes-vault-opencode"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6202957",
"id": 6202957,
"node_id": "GC_lADOA7Wy4doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBepk0",
"user": {
"login": "deepak-bhardwaj-ps",
"id": 62239457,
"node_id": "MDQ6VXNlcjYyMjM5NDU3",
"avatar_url": "https://avatars.githubusercontent.com/u/62239457?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/deepak-bhardwaj-ps",
"html_url": "https://github.com/deepak-bhardwaj-ps",
"followers_url": "https://api.github.com/users/deepak-bhardwaj-ps/followers",
"following_url": "https://api.github.com/users/deepak-bhardwaj-ps/following{/other_user}",
"gists_url": "https://api.github.com/users/deepak-bhardwaj-ps/gists{/gist_id}",
"starred_url": "https://api.github.com/users/deepak-bhardwaj-ps/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/deepak-bhardwaj-ps/subscriptions",
"organizations_url": "https://api.github.com/users/deepak-bhardwaj-ps/orgs",
"repos_url": "https://api.github.com/users/deepak-bhardwaj-ps/repos",
"events_url": "https://api.github.com/users/deepak-bhardwaj-ps/events{/privacy}",
"received_events_url": "https://api.github.com/users/deepak-bhardwaj-ps/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-17T02:57:09Z",
"updated_at": "2026-06-17T02:57:09Z",
"body": "One pattern I've noticed across many of the projects in this thread is that they focus heavily on *what* the agent remembers.\r\n\r\nSmriti-MCP started from a slightly different question:\r\n\r\n**How does the agent remember consistently across sessions, tools, models, and runtimes?**\r\n\r\nInstead of treating memory as a feature inside a specific agent framework, Smriti exposes memory as an MCP-native service that any compatible agent can use.\r\n\r\nA few design principles that shaped it:\r\n\r\n* Memory is externalised from the agent lifecycle.\r\n* Context should survive model changes.\r\n* Knowledge should be reusable across multiple agents.\r\n* Memory must be queryable, governed, and inspectable.\r\n* The memory layer should remain useful even when the orchestration layer changes.\r\n\r\nWhat interests me most is that we're gradually moving from \"prompt engineering\" toward **memory architecture**.\r\n\r\nThe next generation of agent systems will not be differentiated by model choice alone.\r\n\r\nThey will be differentiated by:\r\n\r\n* what they know,\r\n* how they remember,\r\n* how they evolve knowledge over time,\r\n* and how reliably they can retrieve the right context at the right moment.\r\n\r\nSmriti-MCP is my attempt to explore that direction as a portable memory layer for agent ecosystems.\r\n\r\nProject:\r\n\r\n[Smriti MCP](https://github.com/deepak-bhardwaj-ps/smriti-mcp)"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6203805",
"id": 6203805,
"node_id": "GC_lADOBGxW3toAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeqZ0",
"user": {
"login": "Motya-cobol",
"id": 74208990,
"node_id": "MDQ6VXNlcjc0MjA4OTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/74208990?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Motya-cobol",
"html_url": "https://github.com/Motya-cobol",
"followers_url": "https://api.github.com/users/Motya-cobol/followers",
"following_url": "https://api.github.com/users/Motya-cobol/following{/other_user}",
"gists_url": "https://api.github.com/users/Motya-cobol/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Motya-cobol/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Motya-cobol/subscriptions",
"organizations_url": "https://api.github.com/users/Motya-cobol/orgs",
"repos_url": "https://api.github.com/users/Motya-cobol/repos",
"events_url": "https://api.github.com/users/Motya-cobol/events{/privacy}",
"received_events_url": "https://api.github.com/users/Motya-cobol/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-17T15:11:16Z",
"updated_at": "2026-06-17T15:11:16Z",
"body": "Hello Andrei and the community.\r\nI’m building a Markdown/Obsidian-style knowledge wiki for teaching a health informatics course, using Codex to help ingest sources, maintain links, and later query the wiki for presentations and curriculum design.\r\n\r\nI ran into a token-efficiency problem that may be interesting: the token burn was not mainly from reasoning or output, but from repeated context loading. Codex kept re-reading files like AGENTS.md, wiki/index.md, manifests, handoffs, raw sources, and tool scripts across short sessions. Even small source-ingest tasks became expensive.\r\n\r\nI’ve started moving toward a split workflow: deterministic Python scripts handle source intake, route indexes, validation, and compact handoffs; Codex is reserved for higher-value graph curation, synthesis, and judgment. I’m also using compact routing files instead of asking the model to scan the whole wiki.\r\n\r\nI would be grateful for any advice on the right architecture for this kind of “wiki as working memory” setup. Specifically, how would you structure retrieval, summaries, graph edges, and agent instructions so Codex can reason over a rich knowledge base without repeatedly consuming the entire context?\r\n\r\nEven a few pointers or design principles would be very helpful."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6204203",
"id": 6204203,
"node_id": "GC_lADOAPIx79oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeqys",
"user": {
"login": "yazanabuashour",
"id": 15872495,
"node_id": "MDQ6VXNlcjE1ODcyNDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/15872495?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yazanabuashour",
"html_url": "https://github.com/yazanabuashour",
"followers_url": "https://api.github.com/users/yazanabuashour/followers",
"following_url": "https://api.github.com/users/yazanabuashour/following{/other_user}",
"gists_url": "https://api.github.com/users/yazanabuashour/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yazanabuashour/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yazanabuashour/subscriptions",
"organizations_url": "https://api.github.com/users/yazanabuashour/orgs",
"repos_url": "https://api.github.com/users/yazanabuashour/repos",
"events_url": "https://api.github.com/users/yazanabuashour/events{/privacy}",
"received_events_url": "https://api.github.com/users/yazanabuashour/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-17T23:23:46Z",
"updated_at": "2026-06-17T23:23:46Z",
"body": "One thing I think the LLM-wiki pattern needs as it grows past toy scale is a\nhard boundary between:\n\n1. canonical human-readable Markdown\n2. derived recall/projection state\n3. agent write authority\n\nThe failure mode I kept running into was not \"can the agent write a wiki page?\"\nIt was:\n\n- stale synthesis pages that still looked authoritative\n- duplicate pages for the same concept\n- retrieval results with no stable citation contract\n- agents silently turning generated summaries into truth\n\nI have been building OpenClerk around that boundary:\n\n- Markdown remains canonical\n- SQLite/FTS/graph state is derived and auditable\n- every retrieval result carries `doc_id`, `chunk_id`, and citation path\n- duplicate/stale/freshness checks are explicit reports\n- writes go through planned/approved runner actions\n- semantic search/OCR are optional modules, not hidden defaults\n\nRepo: \n\nI would especially love criticism on the runner boundary: should freshness and\nduplicate signals be advisory reports, hard write gates, or retrieval-time\nranking inputs?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6204250",
"id": 6204250,
"node_id": "GC_lADOA7Wy4doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBeq1o",
"user": {
"login": "deepak-bhardwaj-ps",
"id": 62239457,
"node_id": "MDQ6VXNlcjYyMjM5NDU3",
"avatar_url": "https://avatars.githubusercontent.com/u/62239457?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/deepak-bhardwaj-ps",
"html_url": "https://github.com/deepak-bhardwaj-ps",
"followers_url": "https://api.github.com/users/deepak-bhardwaj-ps/followers",
"following_url": "https://api.github.com/users/deepak-bhardwaj-ps/following{/other_user}",
"gists_url": "https://api.github.com/users/deepak-bhardwaj-ps/gists{/gist_id}",
"starred_url": "https://api.github.com/users/deepak-bhardwaj-ps/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/deepak-bhardwaj-ps/subscriptions",
"organizations_url": "https://api.github.com/users/deepak-bhardwaj-ps/orgs",
"repos_url": "https://api.github.com/users/deepak-bhardwaj-ps/repos",
"events_url": "https://api.github.com/users/deepak-bhardwaj-ps/events{/privacy}",
"received_events_url": "https://api.github.com/users/deepak-bhardwaj-ps/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-18T00:35:25Z",
"updated_at": "2026-06-18T00:35:25Z",
"body": "> Hello Andrei and the community. I’m building a Markdown/Obsidian-style knowledge wiki for teaching a health informatics course, using Codex to help ingest sources, maintain links, and later query the wiki for presentations and curriculum design.\r\n> \r\n> I ran into a token-efficiency problem that may be interesting: the token burn was not mainly from reasoning or output, but from repeated context loading. Codex kept re-reading files like AGENTS.md, wiki/index.md, manifests, handoffs, raw sources, and tool scripts across short sessions. Even small source-ingest tasks became expensive.\r\n> \r\n> I’ve started moving toward a split workflow: deterministic Python scripts handle source intake, route indexes, validation, and compact handoffs; Codex is reserved for higher-value graph curation, synthesis, and judgment. I’m also using compact routing files instead of asking the model to scan the whole wiki.\r\n> \r\n> I would be grateful for any advice on the right architecture for this kind of “wiki as working memory” setup. Specifically, how would you structure retrieval, summaries, graph edges, and agent instructions so Codex can reason over a rich knowledge base without repeatedly consuming the entire context?\r\n> \r\n> Even a few pointers or design principles would be very helpful.\r\n\r\nYou can try Smriti MCP I dhared above on the thread. Out of the box agents struggle to use wiki efficiently. I have built it for that purpose and you can configure same MCP with multiple agents to collaborate and share wiki. "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6205516",
"id": 6205516,
"node_id": "GC_lADOBmn5pNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBesEw",
"user": {
"login": "LARIkoz",
"id": 107608484,
"node_id": "U_kgDOBmn5pA",
"avatar_url": "https://avatars.githubusercontent.com/u/107608484?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LARIkoz",
"html_url": "https://github.com/LARIkoz",
"followers_url": "https://api.github.com/users/LARIkoz/followers",
"following_url": "https://api.github.com/users/LARIkoz/following{/other_user}",
"gists_url": "https://api.github.com/users/LARIkoz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LARIkoz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LARIkoz/subscriptions",
"organizations_url": "https://api.github.com/users/LARIkoz/orgs",
"repos_url": "https://api.github.com/users/LARIkoz/repos",
"events_url": "https://api.github.com/users/LARIkoz/events{/privacy}",
"received_events_url": "https://api.github.com/users/LARIkoz/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-18T08:10:55Z",
"updated_at": "2026-06-18T08:10:55Z",
"body": "Implemented this end-to-end as **Eidetic** (memory for Claude Code): https://github.com/LARIkoz/eidetic — compounding pages (a good answer files back; a re-touch appends to a History/Update section instead of duplicating), an explicit schema as the maintenance contract, typed pages, and an op-log.\n\nTwo additions from running it on an ~1.8k-file / 16k-chunk store: (1) **auto-extraction** at session end so the wiki grows without manual ingest, and (2) **drift detection** — your \"note where new data contradicts old\", automated as stale-age / broken-link / confidence-escalation penalties; past ~day 60 the real failure mode is confident-but-stale memory making the agent _worse_, not better. The \"LLMs don't get bored\" framing nails the thesis — thanks for writing it up.\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6206100",
"id": 6206100,
"node_id": "GC_lADOBkd7_doAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBespQ",
"user": {
"login": "pumblus",
"id": 105348093,
"node_id": "U_kgDOBkd7_Q",
"avatar_url": "https://avatars.githubusercontent.com/u/105348093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pumblus",
"html_url": "https://github.com/pumblus",
"followers_url": "https://api.github.com/users/pumblus/followers",
"following_url": "https://api.github.com/users/pumblus/following{/other_user}",
"gists_url": "https://api.github.com/users/pumblus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pumblus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pumblus/subscriptions",
"organizations_url": "https://api.github.com/users/pumblus/orgs",
"repos_url": "https://api.github.com/users/pumblus/repos",
"events_url": "https://api.github.com/users/pumblus/events{/privacy}",
"received_events_url": "https://api.github.com/users/pumblus/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-06-18T13:26:05Z",
"updated_at": "2026-06-18T13:26:05Z",
"body": "Thank you Andrej for this write-up. I ended up exploring one specific piece of the pattern: how to make an LLM Wiki portable and agent-maintainable without turning it into a new app.\r\n\r\nI built OKF Harness around that idea: https://github.com/pumblus/okf-harness\r\n\r\nIt uses local folders, immutable raw sources, OKF-compatible markdown, an `okfh --json` CLI for Claude Code or Codex, bounded reads, validation, citations, and a local graph report. The goal is to keep the wiki as ordinary files while giving agents a stable contract for maintaining it.\r\n\r\nWould be interested to hear how others are handling portability, provenance, and validation across agent clients."
}
]
}
 \r\n\r\nThanks! I just used your repo to set up my claude\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084564",
"id": 6084564,
"node_id": "GC_lADOAXQtNNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc19Q",
"user": {
"login": "thomastron",
"id": 24390964,
"node_id": "MDQ6VXNlcjI0MzkwOTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/24390964?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomastron",
"html_url": "https://github.com/thomastron",
"followers_url": "https://api.github.com/users/thomastron/followers",
"following_url": "https://api.github.com/users/thomastron/following{/other_user}",
"gists_url": "https://api.github.com/users/thomastron/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomastron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomastron/subscriptions",
"organizations_url": "https://api.github.com/users/thomastron/orgs",
"repos_url": "https://api.github.com/users/thomastron/repos",
"events_url": "https://api.github.com/users/thomastron/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomastron/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:06:03Z",
"updated_at": "2026-04-06T16:06:03Z",
"body": "**Personal Constitution: Testing What Can't Be Automated**\r\n>_Most of what matters—judgment, integrity, belief coherence—can't be unit-tested. There's no CI/CD for honesty._\r\n\r\nThis system acknowledges that. A knowledge graph of your beliefs, structured so an AI can traverse and challenge it. Not because the structure proves you're right, but because it forces you to *stay* honest. Without automated testing, obligation becomes the entire load-bearing mechanism. State what you believe publicly. Map it precisely. Amendment it transparently. That's the whole security model.\r\n\r\nNo linting for human integrity. Just visibility. And visibility is what makes dishonesty expensive. \r\n[github.com/thomastron/Personal-Constitution](https://github.com/thomastron/personal-constitution/)\r\n[](https://github.com/thomastron/personal-constitution/)\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084572",
"id": 6084572,
"node_id": "GC_lADOAWRAg9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc19w",
"user": {
"login": "Lukaschub",
"id": 23347331,
"node_id": "MDQ6VXNlcjIzMzQ3MzMx",
"avatar_url": "https://avatars.githubusercontent.com/u/23347331?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Lukaschub",
"html_url": "https://github.com/Lukaschub",
"followers_url": "https://api.github.com/users/Lukaschub/followers",
"following_url": "https://api.github.com/users/Lukaschub/following{/other_user}",
"gists_url": "https://api.github.com/users/Lukaschub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Lukaschub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Lukaschub/subscriptions",
"organizations_url": "https://api.github.com/users/Lukaschub/orgs",
"repos_url": "https://api.github.com/users/Lukaschub/repos",
"events_url": "https://api.github.com/users/Lukaschub/events{/privacy}",
"received_events_url": "https://api.github.com/users/Lukaschub/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:15:33Z",
"updated_at": "2026-04-06T16:15:33Z",
"body": "thank you for sharing your knowledge Andrej! Something I'm wrestling with: Instead of one massive, single index file for an entire workspace, I setup a federated organization to keep things organized by project. Each major track has its own index.md. Curious on folks thoughts?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084578",
"id": 6084578,
"node_id": "GC_lADOB5L-M9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc1-I",
"user": {
"login": "LeonardoDaviti",
"id": 127073843,
"node_id": "U_kgDOB5L-Mw",
"avatar_url": "https://avatars.githubusercontent.com/u/127073843?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LeonardoDaviti",
"html_url": "https://github.com/LeonardoDaviti",
"followers_url": "https://api.github.com/users/LeonardoDaviti/followers",
"following_url": "https://api.github.com/users/LeonardoDaviti/following{/other_user}",
"gists_url": "https://api.github.com/users/LeonardoDaviti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LeonardoDaviti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LeonardoDaviti/subscriptions",
"organizations_url": "https://api.github.com/users/LeonardoDaviti/orgs",
"repos_url": "https://api.github.com/users/LeonardoDaviti/repos",
"events_url": "https://api.github.com/users/LeonardoDaviti/events{/privacy}",
"received_events_url": "https://api.github.com/users/LeonardoDaviti/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:23:42Z",
"updated_at": "2026-04-06T16:23:42Z",
"body": "Anyone tested with local models? "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084594",
"id": 6084594,
"node_id": "GC_lADOAAoSV9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc1_I",
"user": {
"login": "emory",
"id": 660055,
"node_id": "MDQ6VXNlcjY2MDA1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/660055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emory",
"html_url": "https://github.com/emory",
"followers_url": "https://api.github.com/users/emory/followers",
"following_url": "https://api.github.com/users/emory/following{/other_user}",
"gists_url": "https://api.github.com/users/emory/gists{/gist_id}",
"starred_url": "https://api.github.com/users/emory/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emory/subscriptions",
"organizations_url": "https://api.github.com/users/emory/orgs",
"repos_url": "https://api.github.com/users/emory/repos",
"events_url": "https://api.github.com/users/emory/events{/privacy}",
"received_events_url": "https://api.github.com/users/emory/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:40:54Z",
"updated_at": "2026-04-06T16:40:54Z",
"body": "> any alternative to obsidian for the command line?\r\n\r\nobsidian has a cli tool officially and various community approaches. but for a PKM in terminal setup i learned about `ekphos` via macOS Homebrew, I don't know how flexible or close to Obsidian it is capability-wise."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084601",
"id": 6084601,
"node_id": "GC_lADOAAoSV9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc1_k",
"user": {
"login": "emory",
"id": 660055,
"node_id": "MDQ6VXNlcjY2MDA1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/660055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emory",
"html_url": "https://github.com/emory",
"followers_url": "https://api.github.com/users/emory/followers",
"following_url": "https://api.github.com/users/emory/following{/other_user}",
"gists_url": "https://api.github.com/users/emory/gists{/gist_id}",
"starred_url": "https://api.github.com/users/emory/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emory/subscriptions",
"organizations_url": "https://api.github.com/users/emory/orgs",
"repos_url": "https://api.github.com/users/emory/repos",
"events_url": "https://api.github.com/users/emory/events{/privacy}",
"received_events_url": "https://api.github.com/users/emory/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:44:58Z",
"updated_at": "2026-04-06T16:44:58Z",
"body": "> Anyone tested with local models?\r\n\r\nbe more specific, many people use local inference with knowledge bases or Obsidian vaults, myself included. Which part of this are you curious about? Local or cloud frontiers, obviously a lot of variation in quality of model but I use sub-20b models locally and have been using Obsidian and Ollama/LMStudio for quite a while now! Whatever models you use for research purposes if suitable for synthesis in other use cases it could probably work, as to if you're going to get the same quality as opus-4-6? I don't have the hardware for anything like that."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084615",
"id": 6084615,
"node_id": "GC_lADOD5RPk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Ac",
"user": {
"login": "liamsysmind",
"id": 261377939,
"node_id": "U_kgDOD5RPkw",
"avatar_url": "https://avatars.githubusercontent.com/u/261377939?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liamsysmind",
"html_url": "https://github.com/liamsysmind",
"followers_url": "https://api.github.com/users/liamsysmind/followers",
"following_url": "https://api.github.com/users/liamsysmind/following{/other_user}",
"gists_url": "https://api.github.com/users/liamsysmind/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liamsysmind/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liamsysmind/subscriptions",
"organizations_url": "https://api.github.com/users/liamsysmind/orgs",
"repos_url": "https://api.github.com/users/liamsysmind/repos",
"events_url": "https://api.github.com/users/liamsysmind/events{/privacy}",
"received_events_url": "https://api.github.com/users/liamsysmind/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:51:36Z",
"updated_at": "2026-04-06T16:51:36Z",
"body": " I built WALI after reading @karpathy's LLM Knowledge Base gist and realizing I wanted something like it actually running at home. \r\n \r\n The problem it solves: I collect a lot — articles, voice memos, meeting notes, random files — but never go back to organize any of it. Most of it just disappears. \r\n \r\n WALI sits on my Mac Mini M4 and accepts anything I throw at it from my phone or browser. Text, files, audio recordings. It transcribes voice memos locally, stores everything in a raw inbox, and uses Claude to compile it into structured, cross-linked wiki articles in the background.\r\n \r\n I don't have to categorize, tag, or file anything. I just collect. The knowledge base builds itself over time. \r\n \r\n Everything stays on the machine — local ASR, local storage, local search. Claude handles the reasoning, but the data doesn't go anywhere. \r\n \r\n It's a proof of concept. But the question behind it feels worth exploring: what if AI handled the parts of knowledge work that people \r\n consistently don't do? \r\n \r\n Built with Claude Agent SDK + Open WebUI + WikiForge. \r\n \r\n github.com/liamsysmind/wali"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084622",
"id": 6084622,
"node_id": "GC_lADOCSWXaNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2A4",
"user": {
"login": "joshua-mike",
"id": 153458536,
"node_id": "U_kgDOCSWXaA",
"avatar_url": "https://avatars.githubusercontent.com/u/153458536?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/joshua-mike",
"html_url": "https://github.com/joshua-mike",
"followers_url": "https://api.github.com/users/joshua-mike/followers",
"following_url": "https://api.github.com/users/joshua-mike/following{/other_user}",
"gists_url": "https://api.github.com/users/joshua-mike/gists{/gist_id}",
"starred_url": "https://api.github.com/users/joshua-mike/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joshua-mike/subscriptions",
"organizations_url": "https://api.github.com/users/joshua-mike/orgs",
"repos_url": "https://api.github.com/users/joshua-mike/repos",
"events_url": "https://api.github.com/users/joshua-mike/events{/privacy}",
"received_events_url": "https://api.github.com/users/joshua-mike/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:56:50Z",
"updated_at": "2026-04-06T16:56:50Z",
"body": "THIS IS FUN."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084633",
"id": 6084633,
"node_id": "GC_lADOAAZZTNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Bk",
"user": {
"login": "wumborti",
"id": 416076,
"node_id": "MDQ6VXNlcjQxNjA3Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/416076?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wumborti",
"html_url": "https://github.com/wumborti",
"followers_url": "https://api.github.com/users/wumborti/followers",
"following_url": "https://api.github.com/users/wumborti/following{/other_user}",
"gists_url": "https://api.github.com/users/wumborti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wumborti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wumborti/subscriptions",
"organizations_url": "https://api.github.com/users/wumborti/orgs",
"repos_url": "https://api.github.com/users/wumborti/repos",
"events_url": "https://api.github.com/users/wumborti/events{/privacy}",
"received_events_url": "https://api.github.com/users/wumborti/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:01:31Z",
"updated_at": "2026-04-06T17:01:31Z",
"body": "This resonates a lot — I've been living this problem.\r\n\r\nI recently shipped a personal project called [[IdeasLake](https://ideaslake.com/)](https://ideaslake.com) — a \"data lake for ideas\" where long-running idea threads (notes, emails, analysis outputs) are treated as living artifacts, not one-off chats. I have 315+ ideas accumulated from 13 years of self-sent emails (yes, that kind of person), and this pain point showed up immediately when I tried to run AI analysis on one of my bigger ideas — a ~190-message Gmail thread, mostly with myself.\r\n\r\nThe key framing I keep returning to: **LLMs are stateless by default, but ideas are inherently stateful and cumulative.** Every conversation with an LLM about an idea is a one-off — nothing compounds. The wiki pattern you describe (persistent, compounding artifact between user and raw corpus) is the missing primitive for anyone with years of accumulated thinking spread across email, notes, and docs.\r\n\r\nWhat's been working better for me on the summarization side is an incremental pipeline:\r\n\r\n1. Keep raw source messages immutable\r\n2. Maintain a rolling `conversation_digest` for older history\r\n3. Keep a \"recent verbatim window\" of the latest messages untouched\r\n4. On each update, process only deltas and merge into the digest with explicit conflict/uncertainty notes\r\n5. Run downstream analysis against digest + recent verbatim + delta — not the full thread each time\r\n\r\nThis preserves continuity while staying within token budgets. I'm building toward a per-idea structured schema (I call it a CIIM layer — Canonical Idea decomposition + Incremental Meta-analysis) that also extracts hypotheses, open questions, and cross-idea links from this process — designed to be updated, not regenerated.\r\n\r\nStill actively working through:\r\n- Anti-drift checks across incremental summaries\r\n- Citation/traceability back to exact source messages\r\n- Contradiction tracking as new evidence arrives\r\n\r\nIf anyone else is building in this direction — especially fellow \"too many ideas, too little time\" people trying to manage a years-long personal corpus — I'd love to compare notes.\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084636",
"id": 6084636,
"node_id": "GC_lADOAcREBdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Bw",
"user": {
"login": "Ar9av",
"id": 29639685,
"node_id": "MDQ6VXNlcjI5NjM5Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/29639685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Ar9av",
"html_url": "https://github.com/Ar9av",
"followers_url": "https://api.github.com/users/Ar9av/followers",
"following_url": "https://api.github.com/users/Ar9av/following{/other_user}",
"gists_url": "https://api.github.com/users/Ar9av/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Ar9av/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Ar9av/subscriptions",
"organizations_url": "https://api.github.com/users/Ar9av/orgs",
"repos_url": "https://api.github.com/users/Ar9av/repos",
"events_url": "https://api.github.com/users/Ar9av/events{/privacy}",
"received_events_url": "https://api.github.com/users/Ar9av/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:02:32Z",
"updated_at": "2026-04-06T17:02:32Z",
"body": "> > Anyone tested with local models?\r\n> \r\n> be more specific, many people use local inference with knowledge bases or Obsidian vaults, myself included. Which part of this are you curious about? Local or cloud frontiers, obviously a lot of variation in quality of model but I use sub-20b models locally and have been using Obsidian and Ollama/LMStudio for quite a while now! Whatever models you use for research purposes if suitable for synthesis in other use cases it could probably work, as to if you're going to get the same quality as opus-4-6? I don't have the hardware for anything like that.\r\n\r\nThats what I tried to tackle with my [repo](https://github.com/Ar9av/obsidian-wiki) . I actually do it only through Gemma 4 with local obsidian vaults"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084663",
"id": 6084663,
"node_id": "GC_lADODatgn9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Dc",
"user": {
"login": "mmoustafa8108",
"id": 229335199,
"node_id": "U_kgDODatgnw",
"avatar_url": "https://avatars.githubusercontent.com/u/229335199?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mmoustafa8108",
"html_url": "https://github.com/mmoustafa8108",
"followers_url": "https://api.github.com/users/mmoustafa8108/followers",
"following_url": "https://api.github.com/users/mmoustafa8108/following{/other_user}",
"gists_url": "https://api.github.com/users/mmoustafa8108/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mmoustafa8108/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mmoustafa8108/subscriptions",
"organizations_url": "https://api.github.com/users/mmoustafa8108/orgs",
"repos_url": "https://api.github.com/users/mmoustafa8108/repos",
"events_url": "https://api.github.com/users/mmoustafa8108/events{/privacy}",
"received_events_url": "https://api.github.com/users/mmoustafa8108/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:17:26Z",
"updated_at": "2026-04-06T17:17:26Z",
"body": "haven't any one made an implementation for this?\r\nlike in python for example!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084707",
"id": 6084707,
"node_id": "GC_lADOAXQtNNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2GM",
"user": {
"login": "thomastron",
"id": 24390964,
"node_id": "MDQ6VXNlcjI0MzkwOTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/24390964?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomastron",
"html_url": "https://github.com/thomastron",
"followers_url": "https://api.github.com/users/thomastron/followers",
"following_url": "https://api.github.com/users/thomastron/following{/other_user}",
"gists_url": "https://api.github.com/users/thomastron/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomastron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomastron/subscriptions",
"organizations_url": "https://api.github.com/users/thomastron/orgs",
"repos_url": "https://api.github.com/users/thomastron/repos",
"events_url": "https://api.github.com/users/thomastron/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomastron/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:39:04Z",
"updated_at": "2026-04-06T17:39:04Z",
"body": "@wumborti \r\nDude, easy on the images! This thread is unusable now because everyone has to scroll through your long sequence of images. Use links or create small thumbnails or something... "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084720",
"id": 6084720,
"node_id": "GC_lADOAAWQfNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2HA",
"user": {
"login": "jmcastagnetto",
"id": 364668,
"node_id": "MDQ6VXNlcjM2NDY2OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/364668?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmcastagnetto",
"html_url": "https://github.com/jmcastagnetto",
"followers_url": "https://api.github.com/users/jmcastagnetto/followers",
"following_url": "https://api.github.com/users/jmcastagnetto/following{/other_user}",
"gists_url": "https://api.github.com/users/jmcastagnetto/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jmcastagnetto/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jmcastagnetto/subscriptions",
"organizations_url": "https://api.github.com/users/jmcastagnetto/orgs",
"repos_url": "https://api.github.com/users/jmcastagnetto/repos",
"events_url": "https://api.github.com/users/jmcastagnetto/events{/privacy}",
"received_events_url": "https://api.github.com/users/jmcastagnetto/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:42:47Z",
"updated_at": "2026-04-06T17:42:47Z",
"body": "Using an LLM as an assistant to organize one's digital mess is a good idea. Perhaps compounded with the ideas/framework from the Zettlekasten method (https://zettelkasten.de/introduction/) - I've tried to do this manually but never had the required time to organize all the digital minutiae that live in my computer."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084745",
"id": 6084745,
"node_id": "GC_lADOBzYORdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Ik",
"user": {
"login": "jurajskuska",
"id": 120983109,
"node_id": "U_kgDOBzYORQ",
"avatar_url": "https://avatars.githubusercontent.com/u/120983109?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jurajskuska",
"html_url": "https://github.com/jurajskuska",
"followers_url": "https://api.github.com/users/jurajskuska/followers",
"following_url": "https://api.github.com/users/jurajskuska/following{/other_user}",
"gists_url": "https://api.github.com/users/jurajskuska/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jurajskuska/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jurajskuska/subscriptions",
"organizations_url": "https://api.github.com/users/jurajskuska/orgs",
"repos_url": "https://api.github.com/users/jurajskuska/repos",
"events_url": "https://api.github.com/users/jurajskuska/events{/privacy}",
"received_events_url": "https://api.github.com/users/jurajskuska/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T18:06:44Z",
"updated_at": "2026-04-06T18:06:44Z",
"body": "Hi Andrej, here are some points we reached a bit earlier using OBSIDIAN. Greetings from bratislava to you.\r\n\r\nThe Destination: Self-Improving Multi-Agent System\r\n\r\n*What the architecture becomes when the loop matures:*\r\n\r\n🤖 **Specialised agents, not one generalist** — small agents each own a narrow task: research, audit, context update, safety check. Scoped context means fewer mistakes, faster execution, no overload.\r\n\r\n⚡ **Parallel execution** — agents run simultaneously. Research agent finds information while audit agent checks integrity while context agent updates gaps. Human is not the bottleneck.\r\n\r\n🔁 **Self-improving context loop** — agents report what was missing or wrong. Context is updated. Next run starts better than the last. The loop runs until context is sufficient — then agents operate with minimal human input.\r\n\r\n🛡️ **Human + safety agents as overseers** — human is not doing the work, human is treating: reviewing flagged weaknesses, approving context updates, watching for injection or drift. Specialised safety agents run the 4-eyes check automatically.\r\n\r\n🧠 **Autoresearch as natural output** — when context is rich enough and agents are specialised enough, research loops run autonomously. Human sets the question, agents find the answer, safety layer validates, context is updated with findings.\r\n\r\n📈 **Self-learning by design** — every session adds to the indexed layer. Every gap found improves the next run. The system learns from its own history without anyone explicitly teaching it.\r\n\r\n🎯 **Human role shifts** — from operator to architect. From doing to directing. From fixing gaps manually to reviewing what the system flagged and approving the fix.\r\n\r\n🐜 **Small models as executors, large models as architects** — bigger models are not always desired. With proper context equipment, smaller models execute reliably and cheaply — like ants working the same target in parallel. Larger models are reserved for what they do best: creating new solutions, designing better approaches, solving novel problems. The division is natural: architect once, execute many times.\r\n\r\n> 🔨 *\"You wouldn't nail pins with a big hammer.\"* — Juraj, 2026-04-05\r\n\r\n💡 **Human creativity is the multiplier** — the system amplifies what humans bring, it doesn't replace it. When the human is properly involved — setting direction, spotting what agents miss, injecting creative leaps — the synergy produces results none of the parts could reach alone. Agents execute with precision. Humans provide the spark.\r\n\r\n> 🌐 **End state:** a parallel, self-correcting, context-driven agent network — where MD files are the shared language, Obsidian is the human dashboard, SQLite is the speed layer, large models design, small models execute, human creativity drives the direction, and the loop never stops improving.\r\n "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084746",
"id": 6084746,
"node_id": "GC_lADOB6ZqO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Io",
"user": {
"login": "Nimo1987",
"id": 128346683,
"node_id": "U_kgDOB6ZqOw",
"avatar_url": "https://avatars.githubusercontent.com/u/128346683?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nimo1987",
"html_url": "https://github.com/Nimo1987",
"followers_url": "https://api.github.com/users/Nimo1987/followers",
"following_url": "https://api.github.com/users/Nimo1987/following{/other_user}",
"gists_url": "https://api.github.com/users/Nimo1987/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nimo1987/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nimo1987/subscriptions",
"organizations_url": "https://api.github.com/users/Nimo1987/orgs",
"repos_url": "https://api.github.com/users/Nimo1987/repos",
"events_url": "https://api.github.com/users/Nimo1987/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nimo1987/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T18:07:13Z",
"updated_at": "2026-04-06T18:07:13Z",
"body": "This note was a big inspiration. I ended up building an open-source implementation of the idea here:\n\nhttps://github.com/Nimo1987/atomic-knowledge\n\nI pushed it in the direction of a markdown-first work-memory protocol for existing agents: explicit ingest/query/writeback/maintenance flows, a provisional candidate buffer before durable pages, and a small example KB plus evals.\n\nThanks for the original framing."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084756",
"id": 6084756,
"node_id": "GC_lADOAFlvLtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2JQ",
"user": {
"login": "romgenie",
"id": 5861166,
"node_id": "MDQ6VXNlcjU4NjExNjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5861166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/romgenie",
"html_url": "https://github.com/romgenie",
"followers_url": "https://api.github.com/users/romgenie/followers",
"following_url": "https://api.github.com/users/romgenie/following{/other_user}",
"gists_url": "https://api.github.com/users/romgenie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/romgenie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/romgenie/subscriptions",
"organizations_url": "https://api.github.com/users/romgenie/orgs",
"repos_url": "https://api.github.com/users/romgenie/repos",
"events_url": "https://api.github.com/users/romgenie/events{/privacy}",
"received_events_url": "https://api.github.com/users/romgenie/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T18:11:45Z",
"updated_at": "2026-04-06T18:11:45Z",
"body": "@karpathy, WOW, this was such an amazing setup. I've revised it heavily from initial, but I'm deeply impressed with it. This would have taken me months to organize.\r\n\r\nhttps://github.com/CompleteTech-LLC-AI-Research/beyond-the-token-bottleneck\r\n\r\n
\r\n\r\nThanks! I just used your repo to set up my claude\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084564",
"id": 6084564,
"node_id": "GC_lADOAXQtNNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc19Q",
"user": {
"login": "thomastron",
"id": 24390964,
"node_id": "MDQ6VXNlcjI0MzkwOTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/24390964?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomastron",
"html_url": "https://github.com/thomastron",
"followers_url": "https://api.github.com/users/thomastron/followers",
"following_url": "https://api.github.com/users/thomastron/following{/other_user}",
"gists_url": "https://api.github.com/users/thomastron/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomastron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomastron/subscriptions",
"organizations_url": "https://api.github.com/users/thomastron/orgs",
"repos_url": "https://api.github.com/users/thomastron/repos",
"events_url": "https://api.github.com/users/thomastron/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomastron/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:06:03Z",
"updated_at": "2026-04-06T16:06:03Z",
"body": "**Personal Constitution: Testing What Can't Be Automated**\r\n>_Most of what matters—judgment, integrity, belief coherence—can't be unit-tested. There's no CI/CD for honesty._\r\n\r\nThis system acknowledges that. A knowledge graph of your beliefs, structured so an AI can traverse and challenge it. Not because the structure proves you're right, but because it forces you to *stay* honest. Without automated testing, obligation becomes the entire load-bearing mechanism. State what you believe publicly. Map it precisely. Amendment it transparently. That's the whole security model.\r\n\r\nNo linting for human integrity. Just visibility. And visibility is what makes dishonesty expensive. \r\n[github.com/thomastron/Personal-Constitution](https://github.com/thomastron/personal-constitution/)\r\n[](https://github.com/thomastron/personal-constitution/)\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084572",
"id": 6084572,
"node_id": "GC_lADOAWRAg9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc19w",
"user": {
"login": "Lukaschub",
"id": 23347331,
"node_id": "MDQ6VXNlcjIzMzQ3MzMx",
"avatar_url": "https://avatars.githubusercontent.com/u/23347331?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Lukaschub",
"html_url": "https://github.com/Lukaschub",
"followers_url": "https://api.github.com/users/Lukaschub/followers",
"following_url": "https://api.github.com/users/Lukaschub/following{/other_user}",
"gists_url": "https://api.github.com/users/Lukaschub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Lukaschub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Lukaschub/subscriptions",
"organizations_url": "https://api.github.com/users/Lukaschub/orgs",
"repos_url": "https://api.github.com/users/Lukaschub/repos",
"events_url": "https://api.github.com/users/Lukaschub/events{/privacy}",
"received_events_url": "https://api.github.com/users/Lukaschub/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:15:33Z",
"updated_at": "2026-04-06T16:15:33Z",
"body": "thank you for sharing your knowledge Andrej! Something I'm wrestling with: Instead of one massive, single index file for an entire workspace, I setup a federated organization to keep things organized by project. Each major track has its own index.md. Curious on folks thoughts?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084578",
"id": 6084578,
"node_id": "GC_lADOB5L-M9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc1-I",
"user": {
"login": "LeonardoDaviti",
"id": 127073843,
"node_id": "U_kgDOB5L-Mw",
"avatar_url": "https://avatars.githubusercontent.com/u/127073843?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LeonardoDaviti",
"html_url": "https://github.com/LeonardoDaviti",
"followers_url": "https://api.github.com/users/LeonardoDaviti/followers",
"following_url": "https://api.github.com/users/LeonardoDaviti/following{/other_user}",
"gists_url": "https://api.github.com/users/LeonardoDaviti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LeonardoDaviti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LeonardoDaviti/subscriptions",
"organizations_url": "https://api.github.com/users/LeonardoDaviti/orgs",
"repos_url": "https://api.github.com/users/LeonardoDaviti/repos",
"events_url": "https://api.github.com/users/LeonardoDaviti/events{/privacy}",
"received_events_url": "https://api.github.com/users/LeonardoDaviti/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:23:42Z",
"updated_at": "2026-04-06T16:23:42Z",
"body": "Anyone tested with local models? "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084594",
"id": 6084594,
"node_id": "GC_lADOAAoSV9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc1_I",
"user": {
"login": "emory",
"id": 660055,
"node_id": "MDQ6VXNlcjY2MDA1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/660055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emory",
"html_url": "https://github.com/emory",
"followers_url": "https://api.github.com/users/emory/followers",
"following_url": "https://api.github.com/users/emory/following{/other_user}",
"gists_url": "https://api.github.com/users/emory/gists{/gist_id}",
"starred_url": "https://api.github.com/users/emory/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emory/subscriptions",
"organizations_url": "https://api.github.com/users/emory/orgs",
"repos_url": "https://api.github.com/users/emory/repos",
"events_url": "https://api.github.com/users/emory/events{/privacy}",
"received_events_url": "https://api.github.com/users/emory/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:40:54Z",
"updated_at": "2026-04-06T16:40:54Z",
"body": "> any alternative to obsidian for the command line?\r\n\r\nobsidian has a cli tool officially and various community approaches. but for a PKM in terminal setup i learned about `ekphos` via macOS Homebrew, I don't know how flexible or close to Obsidian it is capability-wise."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084601",
"id": 6084601,
"node_id": "GC_lADOAAoSV9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc1_k",
"user": {
"login": "emory",
"id": 660055,
"node_id": "MDQ6VXNlcjY2MDA1NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/660055?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emory",
"html_url": "https://github.com/emory",
"followers_url": "https://api.github.com/users/emory/followers",
"following_url": "https://api.github.com/users/emory/following{/other_user}",
"gists_url": "https://api.github.com/users/emory/gists{/gist_id}",
"starred_url": "https://api.github.com/users/emory/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/emory/subscriptions",
"organizations_url": "https://api.github.com/users/emory/orgs",
"repos_url": "https://api.github.com/users/emory/repos",
"events_url": "https://api.github.com/users/emory/events{/privacy}",
"received_events_url": "https://api.github.com/users/emory/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:44:58Z",
"updated_at": "2026-04-06T16:44:58Z",
"body": "> Anyone tested with local models?\r\n\r\nbe more specific, many people use local inference with knowledge bases or Obsidian vaults, myself included. Which part of this are you curious about? Local or cloud frontiers, obviously a lot of variation in quality of model but I use sub-20b models locally and have been using Obsidian and Ollama/LMStudio for quite a while now! Whatever models you use for research purposes if suitable for synthesis in other use cases it could probably work, as to if you're going to get the same quality as opus-4-6? I don't have the hardware for anything like that."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084615",
"id": 6084615,
"node_id": "GC_lADOD5RPk9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Ac",
"user": {
"login": "liamsysmind",
"id": 261377939,
"node_id": "U_kgDOD5RPkw",
"avatar_url": "https://avatars.githubusercontent.com/u/261377939?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liamsysmind",
"html_url": "https://github.com/liamsysmind",
"followers_url": "https://api.github.com/users/liamsysmind/followers",
"following_url": "https://api.github.com/users/liamsysmind/following{/other_user}",
"gists_url": "https://api.github.com/users/liamsysmind/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liamsysmind/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liamsysmind/subscriptions",
"organizations_url": "https://api.github.com/users/liamsysmind/orgs",
"repos_url": "https://api.github.com/users/liamsysmind/repos",
"events_url": "https://api.github.com/users/liamsysmind/events{/privacy}",
"received_events_url": "https://api.github.com/users/liamsysmind/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:51:36Z",
"updated_at": "2026-04-06T16:51:36Z",
"body": " I built WALI after reading @karpathy's LLM Knowledge Base gist and realizing I wanted something like it actually running at home. \r\n \r\n The problem it solves: I collect a lot — articles, voice memos, meeting notes, random files — but never go back to organize any of it. Most of it just disappears. \r\n \r\n WALI sits on my Mac Mini M4 and accepts anything I throw at it from my phone or browser. Text, files, audio recordings. It transcribes voice memos locally, stores everything in a raw inbox, and uses Claude to compile it into structured, cross-linked wiki articles in the background.\r\n \r\n I don't have to categorize, tag, or file anything. I just collect. The knowledge base builds itself over time. \r\n \r\n Everything stays on the machine — local ASR, local storage, local search. Claude handles the reasoning, but the data doesn't go anywhere. \r\n \r\n It's a proof of concept. But the question behind it feels worth exploring: what if AI handled the parts of knowledge work that people \r\n consistently don't do? \r\n \r\n Built with Claude Agent SDK + Open WebUI + WikiForge. \r\n \r\n github.com/liamsysmind/wali"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084622",
"id": 6084622,
"node_id": "GC_lADOCSWXaNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2A4",
"user": {
"login": "joshua-mike",
"id": 153458536,
"node_id": "U_kgDOCSWXaA",
"avatar_url": "https://avatars.githubusercontent.com/u/153458536?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/joshua-mike",
"html_url": "https://github.com/joshua-mike",
"followers_url": "https://api.github.com/users/joshua-mike/followers",
"following_url": "https://api.github.com/users/joshua-mike/following{/other_user}",
"gists_url": "https://api.github.com/users/joshua-mike/gists{/gist_id}",
"starred_url": "https://api.github.com/users/joshua-mike/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/joshua-mike/subscriptions",
"organizations_url": "https://api.github.com/users/joshua-mike/orgs",
"repos_url": "https://api.github.com/users/joshua-mike/repos",
"events_url": "https://api.github.com/users/joshua-mike/events{/privacy}",
"received_events_url": "https://api.github.com/users/joshua-mike/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T16:56:50Z",
"updated_at": "2026-04-06T16:56:50Z",
"body": "THIS IS FUN."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084633",
"id": 6084633,
"node_id": "GC_lADOAAZZTNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Bk",
"user": {
"login": "wumborti",
"id": 416076,
"node_id": "MDQ6VXNlcjQxNjA3Ng==",
"avatar_url": "https://avatars.githubusercontent.com/u/416076?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wumborti",
"html_url": "https://github.com/wumborti",
"followers_url": "https://api.github.com/users/wumborti/followers",
"following_url": "https://api.github.com/users/wumborti/following{/other_user}",
"gists_url": "https://api.github.com/users/wumborti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wumborti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wumborti/subscriptions",
"organizations_url": "https://api.github.com/users/wumborti/orgs",
"repos_url": "https://api.github.com/users/wumborti/repos",
"events_url": "https://api.github.com/users/wumborti/events{/privacy}",
"received_events_url": "https://api.github.com/users/wumborti/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:01:31Z",
"updated_at": "2026-04-06T17:01:31Z",
"body": "This resonates a lot — I've been living this problem.\r\n\r\nI recently shipped a personal project called [[IdeasLake](https://ideaslake.com/)](https://ideaslake.com) — a \"data lake for ideas\" where long-running idea threads (notes, emails, analysis outputs) are treated as living artifacts, not one-off chats. I have 315+ ideas accumulated from 13 years of self-sent emails (yes, that kind of person), and this pain point showed up immediately when I tried to run AI analysis on one of my bigger ideas — a ~190-message Gmail thread, mostly with myself.\r\n\r\nThe key framing I keep returning to: **LLMs are stateless by default, but ideas are inherently stateful and cumulative.** Every conversation with an LLM about an idea is a one-off — nothing compounds. The wiki pattern you describe (persistent, compounding artifact between user and raw corpus) is the missing primitive for anyone with years of accumulated thinking spread across email, notes, and docs.\r\n\r\nWhat's been working better for me on the summarization side is an incremental pipeline:\r\n\r\n1. Keep raw source messages immutable\r\n2. Maintain a rolling `conversation_digest` for older history\r\n3. Keep a \"recent verbatim window\" of the latest messages untouched\r\n4. On each update, process only deltas and merge into the digest with explicit conflict/uncertainty notes\r\n5. Run downstream analysis against digest + recent verbatim + delta — not the full thread each time\r\n\r\nThis preserves continuity while staying within token budgets. I'm building toward a per-idea structured schema (I call it a CIIM layer — Canonical Idea decomposition + Incremental Meta-analysis) that also extracts hypotheses, open questions, and cross-idea links from this process — designed to be updated, not regenerated.\r\n\r\nStill actively working through:\r\n- Anti-drift checks across incremental summaries\r\n- Citation/traceability back to exact source messages\r\n- Contradiction tracking as new evidence arrives\r\n\r\nIf anyone else is building in this direction — especially fellow \"too many ideas, too little time\" people trying to manage a years-long personal corpus — I'd love to compare notes.\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084636",
"id": 6084636,
"node_id": "GC_lADOAcREBdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Bw",
"user": {
"login": "Ar9av",
"id": 29639685,
"node_id": "MDQ6VXNlcjI5NjM5Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/29639685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Ar9av",
"html_url": "https://github.com/Ar9av",
"followers_url": "https://api.github.com/users/Ar9av/followers",
"following_url": "https://api.github.com/users/Ar9av/following{/other_user}",
"gists_url": "https://api.github.com/users/Ar9av/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Ar9av/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Ar9av/subscriptions",
"organizations_url": "https://api.github.com/users/Ar9av/orgs",
"repos_url": "https://api.github.com/users/Ar9av/repos",
"events_url": "https://api.github.com/users/Ar9av/events{/privacy}",
"received_events_url": "https://api.github.com/users/Ar9av/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:02:32Z",
"updated_at": "2026-04-06T17:02:32Z",
"body": "> > Anyone tested with local models?\r\n> \r\n> be more specific, many people use local inference with knowledge bases or Obsidian vaults, myself included. Which part of this are you curious about? Local or cloud frontiers, obviously a lot of variation in quality of model but I use sub-20b models locally and have been using Obsidian and Ollama/LMStudio for quite a while now! Whatever models you use for research purposes if suitable for synthesis in other use cases it could probably work, as to if you're going to get the same quality as opus-4-6? I don't have the hardware for anything like that.\r\n\r\nThats what I tried to tackle with my [repo](https://github.com/Ar9av/obsidian-wiki) . I actually do it only through Gemma 4 with local obsidian vaults"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084663",
"id": 6084663,
"node_id": "GC_lADODatgn9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Dc",
"user": {
"login": "mmoustafa8108",
"id": 229335199,
"node_id": "U_kgDODatgnw",
"avatar_url": "https://avatars.githubusercontent.com/u/229335199?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mmoustafa8108",
"html_url": "https://github.com/mmoustafa8108",
"followers_url": "https://api.github.com/users/mmoustafa8108/followers",
"following_url": "https://api.github.com/users/mmoustafa8108/following{/other_user}",
"gists_url": "https://api.github.com/users/mmoustafa8108/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mmoustafa8108/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mmoustafa8108/subscriptions",
"organizations_url": "https://api.github.com/users/mmoustafa8108/orgs",
"repos_url": "https://api.github.com/users/mmoustafa8108/repos",
"events_url": "https://api.github.com/users/mmoustafa8108/events{/privacy}",
"received_events_url": "https://api.github.com/users/mmoustafa8108/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:17:26Z",
"updated_at": "2026-04-06T17:17:26Z",
"body": "haven't any one made an implementation for this?\r\nlike in python for example!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084707",
"id": 6084707,
"node_id": "GC_lADOAXQtNNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2GM",
"user": {
"login": "thomastron",
"id": 24390964,
"node_id": "MDQ6VXNlcjI0MzkwOTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/24390964?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomastron",
"html_url": "https://github.com/thomastron",
"followers_url": "https://api.github.com/users/thomastron/followers",
"following_url": "https://api.github.com/users/thomastron/following{/other_user}",
"gists_url": "https://api.github.com/users/thomastron/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomastron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomastron/subscriptions",
"organizations_url": "https://api.github.com/users/thomastron/orgs",
"repos_url": "https://api.github.com/users/thomastron/repos",
"events_url": "https://api.github.com/users/thomastron/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomastron/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:39:04Z",
"updated_at": "2026-04-06T17:39:04Z",
"body": "@wumborti \r\nDude, easy on the images! This thread is unusable now because everyone has to scroll through your long sequence of images. Use links or create small thumbnails or something... "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084720",
"id": 6084720,
"node_id": "GC_lADOAAWQfNoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2HA",
"user": {
"login": "jmcastagnetto",
"id": 364668,
"node_id": "MDQ6VXNlcjM2NDY2OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/364668?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmcastagnetto",
"html_url": "https://github.com/jmcastagnetto",
"followers_url": "https://api.github.com/users/jmcastagnetto/followers",
"following_url": "https://api.github.com/users/jmcastagnetto/following{/other_user}",
"gists_url": "https://api.github.com/users/jmcastagnetto/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jmcastagnetto/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jmcastagnetto/subscriptions",
"organizations_url": "https://api.github.com/users/jmcastagnetto/orgs",
"repos_url": "https://api.github.com/users/jmcastagnetto/repos",
"events_url": "https://api.github.com/users/jmcastagnetto/events{/privacy}",
"received_events_url": "https://api.github.com/users/jmcastagnetto/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T17:42:47Z",
"updated_at": "2026-04-06T17:42:47Z",
"body": "Using an LLM as an assistant to organize one's digital mess is a good idea. Perhaps compounded with the ideas/framework from the Zettlekasten method (https://zettelkasten.de/introduction/) - I've tried to do this manually but never had the required time to organize all the digital minutiae that live in my computer."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084745",
"id": 6084745,
"node_id": "GC_lADOBzYORdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Ik",
"user": {
"login": "jurajskuska",
"id": 120983109,
"node_id": "U_kgDOBzYORQ",
"avatar_url": "https://avatars.githubusercontent.com/u/120983109?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jurajskuska",
"html_url": "https://github.com/jurajskuska",
"followers_url": "https://api.github.com/users/jurajskuska/followers",
"following_url": "https://api.github.com/users/jurajskuska/following{/other_user}",
"gists_url": "https://api.github.com/users/jurajskuska/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jurajskuska/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jurajskuska/subscriptions",
"organizations_url": "https://api.github.com/users/jurajskuska/orgs",
"repos_url": "https://api.github.com/users/jurajskuska/repos",
"events_url": "https://api.github.com/users/jurajskuska/events{/privacy}",
"received_events_url": "https://api.github.com/users/jurajskuska/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T18:06:44Z",
"updated_at": "2026-04-06T18:06:44Z",
"body": "Hi Andrej, here are some points we reached a bit earlier using OBSIDIAN. Greetings from bratislava to you.\r\n\r\nThe Destination: Self-Improving Multi-Agent System\r\n\r\n*What the architecture becomes when the loop matures:*\r\n\r\n🤖 **Specialised agents, not one generalist** — small agents each own a narrow task: research, audit, context update, safety check. Scoped context means fewer mistakes, faster execution, no overload.\r\n\r\n⚡ **Parallel execution** — agents run simultaneously. Research agent finds information while audit agent checks integrity while context agent updates gaps. Human is not the bottleneck.\r\n\r\n🔁 **Self-improving context loop** — agents report what was missing or wrong. Context is updated. Next run starts better than the last. The loop runs until context is sufficient — then agents operate with minimal human input.\r\n\r\n🛡️ **Human + safety agents as overseers** — human is not doing the work, human is treating: reviewing flagged weaknesses, approving context updates, watching for injection or drift. Specialised safety agents run the 4-eyes check automatically.\r\n\r\n🧠 **Autoresearch as natural output** — when context is rich enough and agents are specialised enough, research loops run autonomously. Human sets the question, agents find the answer, safety layer validates, context is updated with findings.\r\n\r\n📈 **Self-learning by design** — every session adds to the indexed layer. Every gap found improves the next run. The system learns from its own history without anyone explicitly teaching it.\r\n\r\n🎯 **Human role shifts** — from operator to architect. From doing to directing. From fixing gaps manually to reviewing what the system flagged and approving the fix.\r\n\r\n🐜 **Small models as executors, large models as architects** — bigger models are not always desired. With proper context equipment, smaller models execute reliably and cheaply — like ants working the same target in parallel. Larger models are reserved for what they do best: creating new solutions, designing better approaches, solving novel problems. The division is natural: architect once, execute many times.\r\n\r\n> 🔨 *\"You wouldn't nail pins with a big hammer.\"* — Juraj, 2026-04-05\r\n\r\n💡 **Human creativity is the multiplier** — the system amplifies what humans bring, it doesn't replace it. When the human is properly involved — setting direction, spotting what agents miss, injecting creative leaps — the synergy produces results none of the parts could reach alone. Agents execute with precision. Humans provide the spark.\r\n\r\n> 🌐 **End state:** a parallel, self-correcting, context-driven agent network — where MD files are the shared language, Obsidian is the human dashboard, SQLite is the speed layer, large models design, small models execute, human creativity drives the direction, and the loop never stops improving.\r\n "
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084746",
"id": 6084746,
"node_id": "GC_lADOB6ZqO9oAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2Io",
"user": {
"login": "Nimo1987",
"id": 128346683,
"node_id": "U_kgDOB6ZqOw",
"avatar_url": "https://avatars.githubusercontent.com/u/128346683?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nimo1987",
"html_url": "https://github.com/Nimo1987",
"followers_url": "https://api.github.com/users/Nimo1987/followers",
"following_url": "https://api.github.com/users/Nimo1987/following{/other_user}",
"gists_url": "https://api.github.com/users/Nimo1987/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nimo1987/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nimo1987/subscriptions",
"organizations_url": "https://api.github.com/users/Nimo1987/orgs",
"repos_url": "https://api.github.com/users/Nimo1987/repos",
"events_url": "https://api.github.com/users/Nimo1987/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nimo1987/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T18:07:13Z",
"updated_at": "2026-04-06T18:07:13Z",
"body": "This note was a big inspiration. I ended up building an open-source implementation of the idea here:\n\nhttps://github.com/Nimo1987/atomic-knowledge\n\nI pushed it in the direction of a markdown-first work-memory protocol for existing agents: explicit ingest/query/writeback/maintenance flows, a provisional candidate buffer before durable pages, and a small example KB plus evals.\n\nThanks for the original framing."
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6084756",
"id": 6084756,
"node_id": "GC_lADOAFlvLtoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBc2JQ",
"user": {
"login": "romgenie",
"id": 5861166,
"node_id": "MDQ6VXNlcjU4NjExNjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5861166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/romgenie",
"html_url": "https://github.com/romgenie",
"followers_url": "https://api.github.com/users/romgenie/followers",
"following_url": "https://api.github.com/users/romgenie/following{/other_user}",
"gists_url": "https://api.github.com/users/romgenie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/romgenie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/romgenie/subscriptions",
"organizations_url": "https://api.github.com/users/romgenie/orgs",
"repos_url": "https://api.github.com/users/romgenie/repos",
"events_url": "https://api.github.com/users/romgenie/events{/privacy}",
"received_events_url": "https://api.github.com/users/romgenie/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-06T18:11:45Z",
"updated_at": "2026-04-06T18:11:45Z",
"body": "@karpathy, WOW, this was such an amazing setup. I've revised it heavily from initial, but I'm deeply impressed with it. This would have taken me months to organize.\r\n\r\nhttps://github.com/CompleteTech-LLC-AI-Research/beyond-the-token-bottleneck\r\n\r\n \r\n> The core idea: The original spec describes the \"Gardener\" (the LLM) and the \"Garden\" (the Wiki) beautifully, but it leaves the \"Visitor’s Intent\" relatively open. By wrapping every ingest or query in 5W1H, you prevent generic summaries.\r\n> \r\n> For example, a \"Summary\" of a medical paper is very different if the Who is a surgeon vs. a patient, or if the Why is \"emergency reference\" vs. \"long-term research.\"\r\n> \r\n> WikiZZ treats this context as a lightweight schema for human intent that sits on top of the wiki structure. It ensures the LLM doesn't just summarize info, but translates it into the specific situational utility the user needs.\r\n> \r\n> Currently building a small Node.js app to demo the side-by-side difference (Plain Query vs. WikiZZ-framed Query). Once developed this can start building a web/network of what , why, when, who , where and how for all the documents which can act as a structured llmwiki layer\r\n> \r\n>
\r\n> The core idea: The original spec describes the \"Gardener\" (the LLM) and the \"Garden\" (the Wiki) beautifully, but it leaves the \"Visitor’s Intent\" relatively open. By wrapping every ingest or query in 5W1H, you prevent generic summaries.\r\n> \r\n> For example, a \"Summary\" of a medical paper is very different if the Who is a surgeon vs. a patient, or if the Why is \"emergency reference\" vs. \"long-term research.\"\r\n> \r\n> WikiZZ treats this context as a lightweight schema for human intent that sits on top of the wiki structure. It ensures the LLM doesn't just summarize info, but translates it into the specific situational utility the user needs.\r\n> \r\n> Currently building a small Node.js app to demo the side-by-side difference (Plain Query vs. WikiZZ-framed Query). Once developed this can start building a web/network of what , why, when, who , where and how for all the documents which can act as a structured llmwiki layer\r\n> \r\n>  \r\n> https://vishalmysore.github.io/lllmwikiZZ/\r\n\r\nAre you willing to share how you build it?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6111565",
"id": 6111565,
"node_id": "GC_lADOAVI8cdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdQU0",
"user": {
"login": "manavgup",
"id": 22166641,
"node_id": "MDQ6VXNlcjIyMTY2NjQx",
"avatar_url": "https://avatars.githubusercontent.com/u/22166641?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manavgup",
"html_url": "https://github.com/manavgup",
"followers_url": "https://api.github.com/users/manavgup/followers",
"following_url": "https://api.github.com/users/manavgup/following{/other_user}",
"gists_url": "https://api.github.com/users/manavgup/gists{/gist_id}",
"starred_url": "https://api.github.com/users/manavgup/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manavgup/subscriptions",
"organizations_url": "https://api.github.com/users/manavgup/orgs",
"repos_url": "https://api.github.com/users/manavgup/repos",
"events_url": "https://api.github.com/users/manavgup/events{/privacy}",
"received_events_url": "https://api.github.com/users/manavgup/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-21T12:14:48Z",
"updated_at": "2026-04-21T12:14:48Z",
"body": "not to spam - and my final comment here I promise. Here it is https://wikimind.fly.dev/\r\n\r\nLooking for contributors as well!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6111662",
"id": 6111662,
"node_id": "GC_lADOBRZ5XdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdQa4",
"user": {
"login": "redmizt",
"id": 85358941,
"node_id": "MDQ6VXNlcjg1MzU4OTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/85358941?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/redmizt",
"html_url": "https://github.com/redmizt",
"followers_url": "https://api.github.com/users/redmizt/followers",
"following_url": "https://api.github.com/users/redmizt/following{/other_user}",
"gists_url": "https://api.github.com/users/redmizt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/redmizt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/redmizt/subscriptions",
"organizations_url": "https://api.github.com/users/redmizt/orgs",
"repos_url": "https://api.github.com/users/redmizt/repos",
"events_url": "https://api.github.com/users/redmizt/events{/privacy}",
"received_events_url": "https://api.github.com/users/redmizt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-21T13:21:55Z",
"updated_at": "2026-04-21T13:21:55Z",
"body": "You guys are pretty critical, so the question is, am I pursuing this correctly, what am I missing? Mildly technical operator here, and it likely shows. Would appreciate some help fine-tuning. https://gist.github.com/redmizt/3250f4b8ae15a25428e7fb09aba72223"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6111790",
"id": 6111790,
"node_id": "GC_lADOAB24EdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdQi4",
"user": {
"login": "agent-creativity",
"id": 1947665,
"node_id": "MDQ6VXNlcjE5NDc2NjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1947665?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/agent-creativity",
"html_url": "https://github.com/agent-creativity",
"followers_url": "https://api.github.com/users/agent-creativity/followers",
"following_url": "https://api.github.com/users/agent-creativity/following{/other_user}",
"gists_url": "https://api.github.com/users/agent-creativity/gists{/gist_id}",
"starred_url": "https://api.github.com/users/agent-creativity/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/agent-creativity/subscriptions",
"organizations_url": "https://api.github.com/users/agent-creativity/orgs",
"repos_url": "https://api.github.com/users/agent-creativity/repos",
"events_url": "https://api.github.com/users/agent-creativity/events{/privacy}",
"received_events_url": "https://api.github.com/users/agent-creativity/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-21T15:01:36Z",
"updated_at": "2026-04-21T15:04:12Z",
"body": "Discover [Agentic Local Brain](https://github.com/agent-creativity/agentic-local-brain)\r\n\r\nan open-source project that brings AI-powered personal knowledge management to your local machine. It automatically collects, organizes, and connects insights from files, webpages, emails, and more into a private, searchable knowledge graph. Running entirely offline, it keeps your data secure while enabling intelligent search and semantic retrieval. Perfect for researchers, developers, and anyone who wants to build a second brain that actually works for them.\r\n\r\n
\r\n> https://vishalmysore.github.io/lllmwikiZZ/\r\n\r\nAre you willing to share how you build it?"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6111565",
"id": 6111565,
"node_id": "GC_lADOAVI8cdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdQU0",
"user": {
"login": "manavgup",
"id": 22166641,
"node_id": "MDQ6VXNlcjIyMTY2NjQx",
"avatar_url": "https://avatars.githubusercontent.com/u/22166641?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manavgup",
"html_url": "https://github.com/manavgup",
"followers_url": "https://api.github.com/users/manavgup/followers",
"following_url": "https://api.github.com/users/manavgup/following{/other_user}",
"gists_url": "https://api.github.com/users/manavgup/gists{/gist_id}",
"starred_url": "https://api.github.com/users/manavgup/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manavgup/subscriptions",
"organizations_url": "https://api.github.com/users/manavgup/orgs",
"repos_url": "https://api.github.com/users/manavgup/repos",
"events_url": "https://api.github.com/users/manavgup/events{/privacy}",
"received_events_url": "https://api.github.com/users/manavgup/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-21T12:14:48Z",
"updated_at": "2026-04-21T12:14:48Z",
"body": "not to spam - and my final comment here I promise. Here it is https://wikimind.fly.dev/\r\n\r\nLooking for contributors as well!"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6111662",
"id": 6111662,
"node_id": "GC_lADOBRZ5XdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdQa4",
"user": {
"login": "redmizt",
"id": 85358941,
"node_id": "MDQ6VXNlcjg1MzU4OTQx",
"avatar_url": "https://avatars.githubusercontent.com/u/85358941?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/redmizt",
"html_url": "https://github.com/redmizt",
"followers_url": "https://api.github.com/users/redmizt/followers",
"following_url": "https://api.github.com/users/redmizt/following{/other_user}",
"gists_url": "https://api.github.com/users/redmizt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/redmizt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/redmizt/subscriptions",
"organizations_url": "https://api.github.com/users/redmizt/orgs",
"repos_url": "https://api.github.com/users/redmizt/repos",
"events_url": "https://api.github.com/users/redmizt/events{/privacy}",
"received_events_url": "https://api.github.com/users/redmizt/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-21T13:21:55Z",
"updated_at": "2026-04-21T13:21:55Z",
"body": "You guys are pretty critical, so the question is, am I pursuing this correctly, what am I missing? Mildly technical operator here, and it likely shows. Would appreciate some help fine-tuning. https://gist.github.com/redmizt/3250f4b8ae15a25428e7fb09aba72223"
},
{
"url": "https://api.github.com/gists/442a6bf555914893e9891c11519de94f/comments/6111790",
"id": 6111790,
"node_id": "GC_lADOAB24EdoAIDQ0MmE2YmY1NTU5MTQ4OTNlOTg5MWMxMTUxOWRlOTRmzgBdQi4",
"user": {
"login": "agent-creativity",
"id": 1947665,
"node_id": "MDQ6VXNlcjE5NDc2NjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1947665?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/agent-creativity",
"html_url": "https://github.com/agent-creativity",
"followers_url": "https://api.github.com/users/agent-creativity/followers",
"following_url": "https://api.github.com/users/agent-creativity/following{/other_user}",
"gists_url": "https://api.github.com/users/agent-creativity/gists{/gist_id}",
"starred_url": "https://api.github.com/users/agent-creativity/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/agent-creativity/subscriptions",
"organizations_url": "https://api.github.com/users/agent-creativity/orgs",
"repos_url": "https://api.github.com/users/agent-creativity/repos",
"events_url": "https://api.github.com/users/agent-creativity/events{/privacy}",
"received_events_url": "https://api.github.com/users/agent-creativity/received_events",
"type": "User",
"user_view_type": "public",
"site_admin": false
},
"author_association": "NONE",
"created_at": "2026-04-21T15:01:36Z",
"updated_at": "2026-04-21T15:04:12Z",
"body": "Discover [Agentic Local Brain](https://github.com/agent-creativity/agentic-local-brain)\r\n\r\nan open-source project that brings AI-powered personal knowledge management to your local machine. It automatically collects, organizes, and connects insights from files, webpages, emails, and more into a private, searchable knowledge graph. Running entirely offline, it keeps your data secure while enabling intelligent search and semantic retrieval. Perfect for researchers, developers, and anyone who wants to build a second brain that actually works for them.\r\n\r\n